一种基于特征模型的刷子检测方法与系统与流程
本发明涉及网络技术领域,特别是涉及一种基于特征模型的刷子检测方法与系统。
背景技术:
平台作为内容生产者的平台,当有大量的ugc(用户生成内容)产生时,为净化网络内容安全,需要内容进行对应的合法性审核,通过后才能在平台上流通。但是在黑产、羊毛党横行的前提下,大量的非重复但有一定规律性的内容产生,对平台内容审核造成了巨大的挑战,以至于当刷子来临时审核人手不够,造成任务积压。
前面的叙述在于提供一般的背景信息,并不一定构成现有技术。
技术实现要素:
本发明的目的在于提供一种能对刷子进行初步识别的基于特征模型的刷子检测方法与系统。
本发明提供一种基于特征模型的刷子检测方法,包括:类型检测,检测输入的数据类型,若为文本数据则进行文本检测;文本检测,获取文本数据,将文本数据去除无关信息,再将文本数据从中文、字母、数字维度上剖析,得出特征形式,将特征数据与模型库数据特征做匹配,匹配符合后输出uid数据。
进一步地,所述类型检测包括若为图片数据则进行图片检测;所述刷子检测方法还包括:图片检测,获得图片二进制数据,将数据下载到本地,使用感知算法生成特征hash值,将hash值与刷子hash库的hash对比,符合特征后输出uid数据。
进一步地,所述图片检测步骤中,设置hash阈值,当hash值与刷子hash库的hash对比的分数达到hash阈值,则认为符合特征。
进一步地,所述模型库的建构方法包括:获取文本特征,获取用户端提交的组样本数据;分析样本数据,得出样本的共同特征,将共同特征描述为刷子特征;将刷子特征存入模型库。
进一步地,所述将共同特征描述为刷子特征包括:当样本数据符合第一模型特征时,将第一模型特征作为刷子特征;当样本数据符合第二模型特征时,将第二模型特征作为刷子特征;所述第一模型特征是指对词组所有的词进行打散,分隔成单字,由此得出多个数组,随后取这多个数组中的共同交集,所得出的相同单字集合;所述第二模型特征是指对词组所有的词做字类型分析,通过对词组的中文个数、数组个数、字母个数所找到的共同特征点。
一种基于特征模型的刷子检测系统,包括:类型检测模块,用于检测输入的数据类型,若为文本数据则进行文本检测;文本检测模块,用于获取文本数据,将文本数据去除无关信息,再将文本数据从中文、字母、数字维度上剖析,得出特征形式,将特征数据与模型库数据特征做匹配,匹配符合后输出uid数据。
进一步地,所述类型检测模块若检测到数据类型为图片数据则进行图片检测;所述刷子检测方法还包括:图片检测模块,用于获得图片二进制数据,将数据下载到本地,使用感知算法生成特征hash值,将hash值与刷子hash库的hash对比,符合特征后输出uid数据。
进一步地,所述图片检测模块中,设置hash阈值,当hash值与刷子hash库的hash对比的分数达到hash阈值,则认为符合特征。
进一步地,所述模型库的建构方法包括:获取文本特征,获取用户端提交的组样本数据;分析样本数据,得出样本的共同特征,将共同特征描述为刷子特征;将刷子特征存入模型库。
进一步地,所述将共同特征描述为刷子特征包括:当样本数据符合第一模型特征时,将第一模型特征作为刷子特征;当样本数据符合第二模型特征时,将第二模型特征作为刷子特征;所述第一模型特征是指对词组所有的词进行打散,分隔成单字,由此得出多个数组,随后取这多个数组中的共同交集,所得出的相同单字集合;所述第二模型特征是指对词组所有的词做字类型分析,通过对词组的中文个数、数组个数、字母个数所找到的共同特征点。
本发明提供的基于特征模型的刷子检测方法与系统,通过将文本数据从中文、字母、数字维度上剖析,得出特征形式,将特征数据与模型库数据特征做匹配,以对刷子进行初步识别,从而能减少对刷子、羊毛党等所产生的内容的审核,加速审核效率。
附图说明
图1为本发明实施例刷子检测方法的流程图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
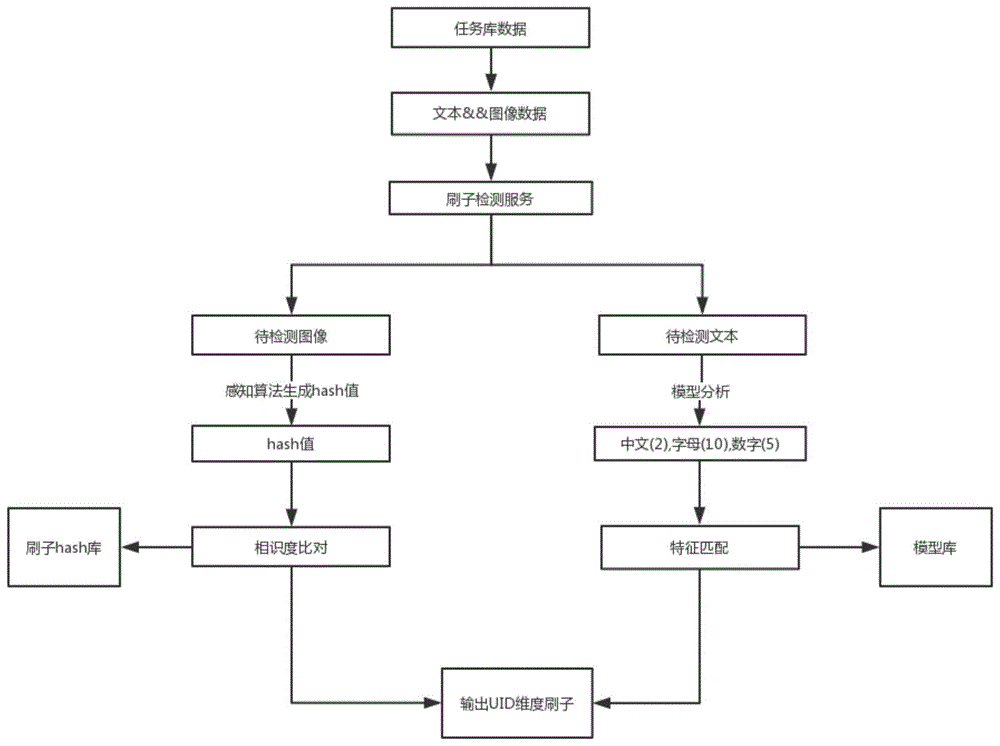
如图1所示,本实施例中,基于特征模型的刷子检测方法,包括如下步骤:
类型检测,检测输入的数据(如任务库数据)的类型,判断是文本数据还是图片数据。若为文本数据则进行文本检测,若为图片数据则进行图片检测;
文本检测,获取文本数据,将文本数据去除将表情、符号等跟字面意思无关的无关信息,再将文本数据从中文、字母、数字维度上剖析,得出特征形式,将特征数据与模型库数据特征做匹配,匹配符合后输出uid(用户身份识别)数据。
图片检测,获得图片二进制数据,将数据下载到本地,使用感知算法生成特征hash值,将hash值与刷子hash库的hash对比(相识度比对),符合特征后输出uid数据。是否符合特征的判断方式可为:设置hash阈值,当hash值与刷子hash库的hash对比的分数达到hash阈值,则认为符合特征。
当然,在其它实施例中,也可以只检测文本数据,这时就不需要设置图片检测步骤。
本实施例中,模型库的建构方法包括:获取文本特征,获取用户端提交的组样本数据;分析样本数据,得出样本的共同特征,将共同特征描述为刷子特征;将刷子特征存入模型库。
将共同特征描述为刷子特征可为:当样本数据符合第一模型特征时,将第一模型特征作为刷子特征;当样本数据符合第二模型特征时,将第二模型特征作为刷子特征。
所述第一模型特征是指对词组所有的词进行打散,分隔成单字,由此得出多个数组,随后取这多个数组中的共同交集,所得出的相同单字集合。如["用户3735145832","用户5747134863","用户5977056607"]通过文本的分析,他们具有{"0":"用","1":"户","3":"7","5":"5","8":"5"}等相同字符。
所述第二模型特征是指对词组所有的词做字类型分析,通过对词组的中文个数、数组个数、字母个数所找到的共同特征点。如["荷心雪乖乖沕_83648","爵士豪侠心揇_66450","嘷花天喜双喜_53721"]通过对文本的分析,它们具有中文(6)数字(5)的特征。
本实施例中,基于特征模型的刷子检测系统,包括:
类型检测模块,用于检测输入的数据类型,若为文本数据则进行文本检测,若为图片数据则进行图片检测;
文本检测模块,用于获取文本数据,将文本数据去除无关信息,再将文本数据从中文、字母、数字维度上剖析,得出特征形式,将特征数据与模型库数据特征做匹配,匹配符合后输出uid数据;
图片检测模块,用于获得图片二进制数据,将数据下载到本地,使用感知算法生成特征hash值,将hash值与刷子hash库的hash对比,符合特征后输出uid数据。
本实施例中,所述图片检测模块判断是否符合特征的方式为:设置hash阈值,当hash值与刷子hash库的hash对比的分数达到hash阈值,则认为符合特征。
同样,在其它实施例中,也可以只检测文本数据,这时就不需要包括图片检测模块。
本实施例中,所述模型库的建构方法包括:获取文本特征,获取用户端提交的组样本数据;分析样本数据,得出样本的共同特征,将共同特征描述为刷子特征;将刷子特征存入模型库。
本实施例中,所述将共同特征描述为刷子特征包括:当样本数据符合第一模型特征时,将第一模型特征作为刷子特征;当样本数据符合第二模型特征时,将第二模型特征作为刷子特征;所述第一模型特征是指对词组所有的词进行打散,分隔成单字,由此得出多个数组,随后取这多个数组中的共同交集,所得出的相同单字集合;所述第二模型特征是指对词组所有的词做字类型分析,通过对词组的中文个数、数组个数、字母个数所找到的共同特征点。
本实施例提供的基于特征模型的刷子检测方法与系统,通过将文本数据从中文、字母、数字维度上剖析,得出特征形式,将特征数据与模型库数据特征做匹配,以对刷子进行初步识别,从而能减少对刷子、羊毛党等所产生的内容的审核,加速审核效率。
实现时,本实施例采用了b/s架构来构建系统,模型库中,样本数据由一线审核人员发现并提交的形式完成,在模型匹配、任务隔离的方式上,均采用了异步处理方式,在不影响审核业务的情况下,由刷子检测系统对任务进行清洗,实现了刷子的检测与隔离。主要工作流程如下:任务库由app服务产生,审核系统将任务数据入库,一线人员在审核时,在样本递交端口,一线人员勾选3或3个以上的文本样本提交,提交后验证并生成模型库,刷子检测系统读取模型库并对任务库的数据进行比对,文字数据由文字检测模块处理,图片数据由图片检测模块处理,特征模型匹配后写入刷子库,刷子隔离模块将读取刷子库的数据,将任务库数据删除,写入到刷子分区,完成刷子检测与隔离。
在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,除了包含所列的那些要素,而且还可包含没有明确列出的其他要素。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!