一种肺炎检测装置的制作方法
本发明涉及深度学习领域,具体来说是基于改进的retinanet神经网络肺炎检测装置。
背景技术:
肺炎是一种严重的肺部疾病,是由细菌、病毒、真菌等引起的肺泡的炎症,不及时诊断医治会迅速恶化导致如心功能衰竭、脓胸、肺脓肿、心肌炎或中毒性脑炎等其他疾病。全球每年有4.5亿人感染肺炎,400万人死于肺炎。感染率和死亡率之间的数值差异表明早期诊断十分重要。
目前,诊断肺炎主要通过放射科医师观察胸部x光片来诊断肺炎。然而人工观察胸部x光片耗时费力,放射科医师对日渐增长的数据量不堪重负,且容易受主观因素影响导致误诊、漏诊。因此急需一种自动检测肺炎病灶区域的装置,不仅可以减轻医生的工作量,还可以使患者及时了解自己的病情。
技术实现要素:
本发明的目的是基于医学图像处理,提供一种基于改进的retinanet神经网络肺炎检测装置,用以更精确地检测肺炎病灶。本发明通过如下技术方案进行实施:
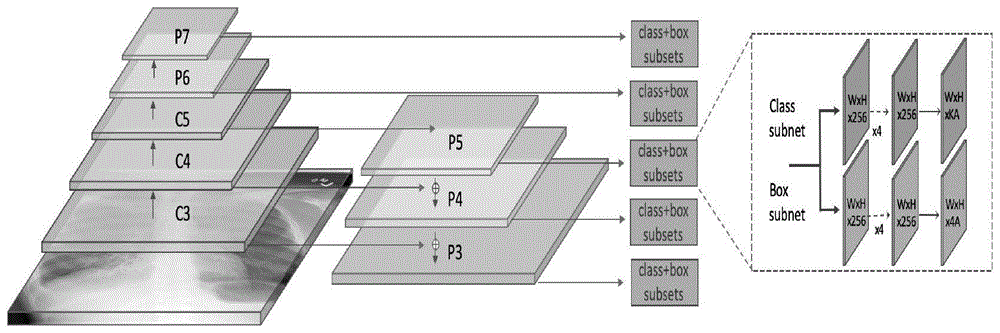
一种肺炎检测装置,基于改进的retinanet神经网络实现,包括限制对比度自适应直方图均衡化模块、特征提取模块、建立特征金字塔模块、先验框选取模块、分类子分支模块、回归子分支模块,其中,
限制对比度自适应直方图均衡化模块,用于对胸部x光图像进行对比度增强;
特征提取模块,用于从经限制对比度自适应直方图均衡化处理后的图像中提取特征信息,使用densenet201作为特征提取网络,其中的每一层都与之前所有层相关联,通过特征在通道上的连接来实现特征重用。
建立特征金字塔模块,是在densenet121的block3,block4,block5输出的特征图c3,c4,c5上建立特征金字塔模块fpn,用于将densenet201中低层级的特征图和高层级的特征图结合起来,通过从上而下的路径和横向连接建立金字塔结构,高层级的特征经过上采样得以和低层级的特征图相加,输出五个不同不同尺度的特征图;
先验框选取模块,用于在特征金字塔模块输出的五个不同尺度的特征图上选取先验框,以特征图上每一个特征点为中心产生九种先验框,对应三种不同的宽高比和三种不同的尺寸变化{22/3,21/3,20},五个特征图上对应先验框面积分别为32、64、128、256、512,使用优化的k均值聚类算法,即k-means++算法产生适合自己的数据集的先验框宽高比;
分类子分支模块,用于预测先验框选取模块产生的某一个先验框是肺炎病灶区域的可能性,预测每个像素点上肺炎存在的可能性,是一个小的全连接神经网络fcn,连接在fpn输出的每个特征图上,这个子网络的参数是所有的金字塔层共享的,它的结构为,应用4个3×3的卷积层,每个卷积都有256个通道,而且每个都跟有relu激活函数;每个金字塔层经子分支输出为一个9维的线性输出,输出的是某点对应的九个先验框的分数,分数越高是病灶的可能性越大,得分较高的将会输入到下面的回归子分支模块进行定位;
回归子分支模块,用于精确肺炎病灶区域的位置,分类子分支模块中得分较高的先验框将会输入此回归子分支模块进行微调,目的是回归先验框和最近的目标框之间的差距,不断更新左上角点和右下角点四个坐标的值,最终产生4×9个数的一维线性输出。
建立特征金字塔模块,是在densenet121的block3,block4,block5输出的特征图c3,c4,c5上建立特征金字塔模块fpn,步骤如下:
a)c5经过1×1的卷积降维,维数变为256,经过上采样变成和c4同样大小的p5_upsampled,再经过一个3×3的卷积成为p5;
b)c4经过1×1的卷积降维,维数变为256,再与p4逐元素相加,然后上采样,变成和c3同样大小的p4_upsampled,再经过3×3的卷积成为p4;
c)c3经过1×1的卷积降维,维数变为256,然后与p4_upsampled逐元素相加,再经一个3×3的卷积变为p3;
d)c5经过一个大小为3×3,步长为2的卷积成为p6;
e)p6经过relu激活函数和一个大小为3×3,步长为2的卷积操作后成为p7;
因此最终得到p3~p7五个特征图。
使用k-means++算法产生适合自己的数据集的先验框宽高比,输入数据集中所有目标框的宽高值,步骤如下:
步骤1在数据集的所有目标框中随机选取一个作为第一个聚类中心(w1,h1),
其中w1为目标框的宽度,h1为目标框的高度;
步骤2计算其他目标框和之前选取的聚类中心的距离:
dis(box,centroid)=1-iou(box,centroid)
其中iou为某一目标框和聚类中心的交并比(intersection-over-union),即两者交集的面积比并集的面积,计算公式为:
a代表目标框,b代表聚类中心,计算交并比时忽略目标框的位置,当某一目标框和之前的聚类中心的距离都大于距离阈值时就成为下一个聚类中心,得到其他两个初始聚类中心(w2,h2),(w3,h3);
步骤3计算剩余的目标框和各个聚类中心的距离,和哪个聚类中心距离最小即成为它的簇;
步骤4更新各个簇的聚类中心,更新方法为:
其中j代表第j簇,z代表第z个目标框,(w′j,h′j)为更新后的聚类中心,nj为第j簇中病灶标注框的数量,(wjz,hjz)为第j簇中第z个目标框的宽度和高度;
步骤5计算聚类中心变化量:
其中(wj,hj)为更新前的聚类中心,(w′j,h′j)为更新后的聚类中心;
步骤6重复步骤3,4,5,当各个簇的聚类中心变化量小于某个距离阈值时,停止迭代,得到最终的聚类中心。
附图说明
图1神经网络检测框架。
具体实施方式
为了对本发明进行详细阐述,现结合附图实施案例对本发明的具体实施过程作进一步描述分析,从而突出本发明相较于常规医生查验医学影像的优势。
本发明提供了一种针对肺炎胸部x光片图像病灶快速智能检测装置,具体模块包括:
步骤1:限制对比度自适应直方图均衡化模块。
胸部x光片中肺炎病灶表现为模糊区域,特征信息不明显,有用的数据对比度相当接近,这一图像特点使得图像在输入神经网络检测时难以提取到明显的有效特征。因此要采用clahe增强图像的对比度,突出微弱病灶信息。clahe算法与普通的直方图均衡化相比,又能有效地限制噪声过分放大。
步骤2:特征提取模块
本模块中使用densenet201作为特征提取网络,代替原retinanet中的resnet50。resnet50和densenet201网络结构如表1所示。resnet在输入、输出之间建立了一条直接的关联通道,允许原始输入信息直接传到后面的层中,从而使得其集中精力学习输入、输出之间的残差。而densenet中的每一层都与之前所有层相关联,通过特征在通道上的连接来实现特征重用,densenet201比resnet50的参数量减少了5377020,但可以达到相当的性能。
步骤3:建立特征金字塔模块
在densenet121的block3,block4,block5输出的特征图c3,c4,c5上建立特征金字塔模块fpn。建立步骤如下:
f)c5经过1×1的卷积降维,维数变为256。经过上采样变成和c4同样大小的p5_upsampled,再经过一个3×3的卷积成为p5。
g)c4经过1×1的卷积降维,维数变为256,再与p4逐元素相加,然后上采样,变成和c3同样大小的p4_upsampled,再经过3×3的卷积成为p4
h)c3经过1×1的卷积降维,维数变为256,然后与p4_upsampled逐元素相加,再经一个3×3的卷积变为p3
i)c5经过一个大小为3×3,步长为2的卷积成为p6
j)p6经过relu激活函数和一个大小为3×3,步长为2的卷积操作后成为p7
因此此模块输出为p3~p7五个特征图。
步骤4:先验框选取模块
此模块的先验框选取算法不采用原retinanet中的固定比例的先验框,而是采用k-means++算法产生先验框。在retinanet网络中,在p3到p7上分别选取面积为32^2到512^2的先验框,先验框有三个不同的宽高比(aspectratio){1/2,2/1,1/1}和三个不同的尺寸
为减轻结果的不稳定性问题和提高先验框的有效性,我们使用k-means++。k-means++原理是分开初始聚类中心,使得产生的宽高比更具有代表性。k-means++中初始聚类中心选取方法的步骤如下:
a)在数据集所有的目标框中随机选取一个作为第一个聚类中心。
b)其他两个聚类中心的选取规则为:
计算其他目标框和之前选取的聚类中心的距离,这里距离的计算公式不采用标准的欧氏距离,我们采用的距离指标为:
dis(box,centroid)=1-iou(box,centroid)
其中iou为某一目标框和聚类中心的交并比(intersection-over-union),即两者交集的面积比并集的面积,计算公式为:
a代表目标框,b代表聚类中心,计算交并比时我们忽略框的位置,假定它们的中心是重合的。
当某一目标框和之前的聚类中心的距离都大于距离阈值时就成为下一个聚类中心。
选出初始聚类中心后再使用标准的k-means算法迭代出三个聚类中心。步骤为:
a)记三个初始聚类中心为(wj,hj),其中j=1,2,3;
b)计算剩余的病灶标注框与各个聚类中心的距离,并将病灶标注框归类为距离最小聚类中心的簇。其中第i个病灶标注框与第j个聚类中心的距离为xij=1-iou(boxi,centroidj),(i≠j)
其中i=1,2,…,n,j=1,2,3;
c)重新计算并更新各个簇的聚类中心,更新方法为
其中j代表第j簇,z代表第z个目标框,(w′j,h′j)为更新后的聚类中心,nj为第j簇中病灶标注框的数量,(wjz,hjz)为第j簇中第z病灶的宽度和高度;
d)计算聚类中心变化量
δx=iou(centroidj,centroid′j)
e)重复执行b,c,d步骤,当各个簇的聚类中心变化量δx小于预设定的阈值时,停止循环并返回最新的聚类中心,同时计算各个聚类中心的宽高比。在我们的数据集中产生的三个聚类中心为(271,538),(223,315),(168,169),因此在我们的数据集中采用k-means++算法产生的宽高比为0.505,0.709,0.989。每个像素点产生9个先验框。
步骤5:分类子分支模块
用于预测先验框选取模块产生的某一个先验框是肺炎病灶区域的可能性,预测每个像素点上肺炎存在的可能性,是一个小的全连接神经网络(fcn),连接在fpn输出的每个特征图上,这个子网络的参数是所有的金字塔层共享的,它的结构为,应用4个3×3的卷积层,每个卷积都有256个通道,而且每个都跟有relu激活函数。每个金字塔层经子分支输出为一个9维的线性输出,输出的是某点对应的九个先验框的分数,分数越高是病灶的可能性越大,得分较高的将会输入到下面的回归子分支模块进行定位。
步骤6:回归子分支模块
用于精确肺炎病灶区域的位置,分类子分支模块中得分较高的先验框将会输入此回归子分支模块进行微调,目的是回归先验框和最近的目标框之间的差距,不断更新左上角点和右下角点四个坐标的值,最终产生4×9个数的一维线性输出。
图1为本肺炎检测装置采用的网络的主体框架,densenet201与fpn结合为骨干网络,p3~p7为尺度大小不同的特征图,同时利用低层特征和高层特征,分别都连接分类、回归两个子网络。然后在每层根据k-means++产生的anchor信息进行候选框提取,最后将候选框同时输入到分类子网络与回归子网络,得出某anchor是病灶区域的分数,并调整这个anchor的位置,两个子网络不共享权重。
表1resnet50和densenet201网络结构
表2各类算法的精度结果
表1为resnet50和densenet201网络结构,resnet在输入、输出之间建立了一条直接的关联通道,允许原始输入信息直接传到后面的层中,从而使得其集中精力学习输入、输出之间的残差。而densenet中的每一层都与之前所有层相关联,通过特征在通道上的连接来实现特征重用,densenet201比resnet50的参数量减少了5377020,但达到了相当的性能。实验结果见表2。
- 还没有人留言评论。精彩留言会获得点赞!