一种基于深度卷积神经网络的实时车牌检测方法与流程
本发明涉及计算机视觉领域和深度学习领域,具体而言,涉及一种基于深度卷积神经网络的实时车牌检测方法。
背景技术:
近年来,随着我国经济实力的迅速提升,我国的机动车保有量逐年上升。机动车数量的持续增长在服务社会生产生活时,对机动车的管理工作也提出了更高的要求,为了有效地管理机动车辆,机动车号牌需要在交通管理部门申请登记,在这种情形下,需要一种高效、精确的车牌识别系统,用以对车牌号码等车牌信息进行快速采集获取,由此产生了车牌识别系统。
车牌检测是车辆识别系统的重要组成部分,车牌检测的精度可以直接影响车牌识别的准确率。早期的车牌检测方法是利用人工提取特征,训练分类器,进行车牌检测,但这类方法在环境变化强烈的时候检测效果不理想。
近年来,利用faster-rcnn,ssd,yolo来检测车牌,效果不错,可以轻微适应环境变化和车牌不全等问题,但是时间消耗、计算能力和设备存储消耗非常高。
而最近公开了《cn106709486a-基于深度卷积神经网络的自动车牌识别方法》,主要采用常规卷积神经网络提取特征,并使用滑动窗口法定位车牌。过深的卷积神经网络会导致过大网络参数,降低模型速度,滑动窗口法会产生大量待预测候选框,极大的影响了模型速度。
技术实现要素:
本发明提供了一种基于深度卷积神经网络的实时车牌检测方法,采用端到端的非级联结构,不仅能更好的兼具时间和性能两个优势,而且对光照等环境变化有更好的适应性,有效地提高了车牌检测的鲁棒性和网络的泛化能力,极大地降低了车牌检测的误检和漏检,并且在复杂场景下达到实时检测效果。
本发明提供了一种基于深度卷积神经网络的实时车牌检测方法,所述方法包括:
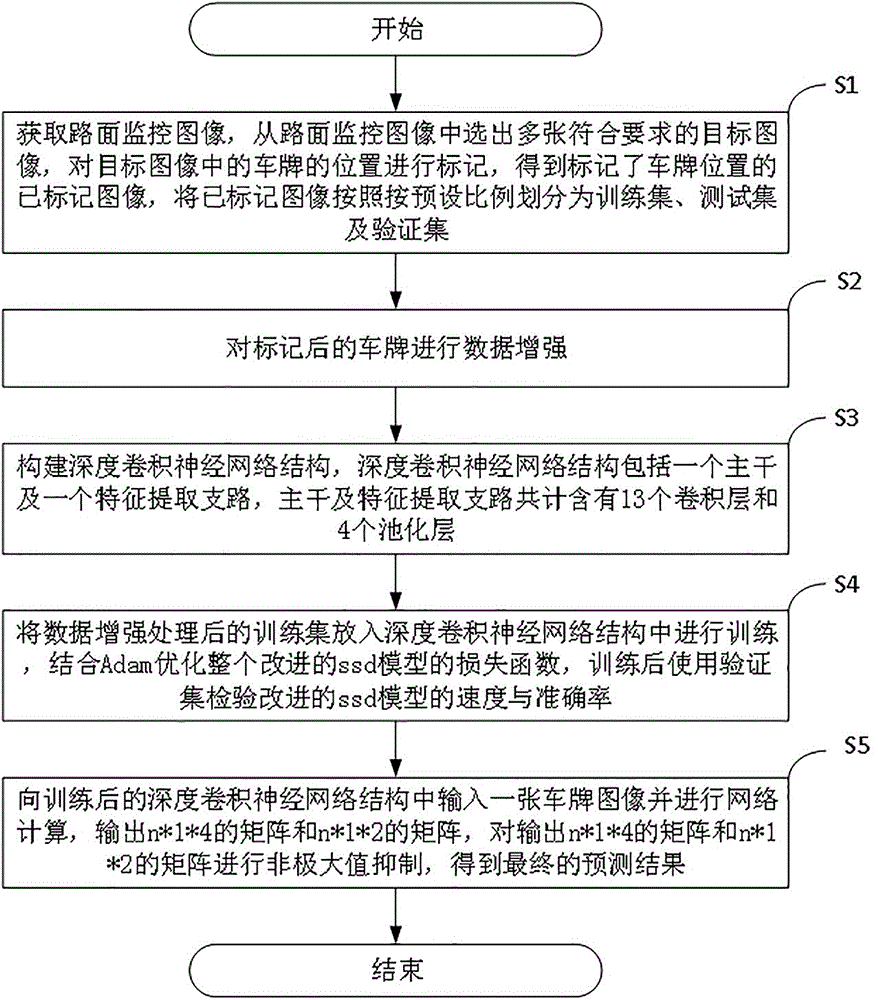
s1,获取路面监控图像,从所述路面监控图像中选出多张符合要求的目标图像,对所述目标图像中的车牌的位置进行标记,得到标记了车牌位置的已标记图像,将所述已标记图像按照按预设比例划分为训练集、测试集及验证集;
s2,对标记后的车牌进行数据增强;
s3,构建深度卷积神经网络结构,所述深度卷积神经网络结构包括一个主干及一个特征提取支路,所述主干及特征提取支路共计含有13个卷积层和4个池化层;
s4,将数据增强处理后的训练集放入深度卷积神经网络结构中进行训练,结合adam优化整个改进的ssd模型的损失函数,训练后使用验证集检验改进的ssd模型的速度与准确率;
s5,向训练后的所述深度卷积神经网络结构中输入一张车牌图像并进行网络计算,输出n*1*4的矩阵和n*1*2的矩阵,所述输出n*1*4的矩阵和n*1*2的矩阵通过非极大值抑制,得到最终的预测结果。
可选地,所述训练集、所述测试集和所述验证集的预设比例为:50%:40%:10%。
可选地,所述数据增强方法包括:
s21,颜色的数据增强,包括饱和度、亮度、曝光度、色调和对比度;
s22,尺度变换,将每一轮送入改进的ssd模型进行训练的图片尺寸随机更改成32倍整倍数大小;
s23,角度变换,图片每次随机旋转0~10度或者水平翻转或者垂直翻转;
s24,随机噪声干扰,在原来的图片的基础上,随机叠加一些高斯噪声;
s25,随机模糊干扰,在原来的图片的基础上,减少各像素值的差异实现图片模糊,实现像素的平滑化。
可选地,所述将数据增强处理后放入深度卷积神经网络结构中进行训练的过程,包括:
将输入图片resize到300*300,相当于输入维度为b*3*300*300的矩阵,b为batch_size,b*3*300*300的矩阵经过基础网络vggnet进行部分计算,记录结果为x;
x经过basicrfb_s处理,记录结果为s;
x经过basicrfb,记录结果为x1;
x1经过basicrfb,记录结果为x2;
x2经过basicrfb,记录结果为x3;
x3经过两个basiconv,记录结果为x4;
x4经过两个basicconv,记录结果为x5。
可选地,所述将数据增强处理后放入深度卷积神经网络结构中进行训练的过程还包括:
所述s,所述x1,所述x2,所述x3,所述x4,所述x5分别经过loc_layer得到六个向量,并对每个向量做cat操作,并view为n*1*4的矩阵;
所述s,所述x1,所述x2,所述x3,所述x4,所述x5分别经过conf_layer得到六个向量,并向每个向量做cat操作,并view为n*1*2的矩阵。
可选地,所述损失函数为:
本发明与现有技术相比,具有的有益效果为:
本发明提供了一种基于深度卷积神经网络的实时车牌检测方法,采用端到端的非级联结构,不仅能更好的兼具时间和性能两个优势,而且对光照等环境变化有更好的适应性,有效地提高了车牌检测的鲁棒性和网络的泛化能力,极大地降低了车牌检测的误检和漏检,并且在复杂场景下达到实时检测效果。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1为本发明实施例所提供的一种基于深度卷积神经网络的实时车牌检测方法的流程图。
图2为本发明实施例所提供的深度卷积神经网络模型结构图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例只是本发明的一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
实施例:
图1本发明实施例所提供的一种基于深度卷积神经网络的实时车牌检测方法的流程图,下面将对图1所示的具体流程进行详细阐述:
s1,获取路面监控图像,从路面监控图像中选出多张符合要求的目标图像,对目标图像中的车牌的位置进行标记,得到标记了车牌位置的已标记图像,将已标记图像按照按预设比例划分为训练集、测试集及验证集。
s2,对标记后的车牌进行数据增强。
s3,构建深度卷积神经网络结构,深度卷积神经网络结构为一种端到端的非级联结构,深度卷积神经网络结构包括一个主干及一个特征提取支路,主干及特征提取支路共计含有13个卷积层和4个池化层。
s4,将数据增强处理后的训练集放入深度卷积神经网络结构中进行训练,结合adam优化整个改进的ssd模型的损失函数,训练后使用验证集检验改进的ssd模型的速度与准确率。其中,ssd模型是一个经典的目标检测算法,本实施例是在ssd模型的基础上完成的。
s5,向训练后的深度卷积神经网络结构中输入一张车牌图像并进行网络计算,输出n*1*4的矩阵和n*1*2的矩阵,输出n*1*4的矩阵和n*1*2的矩阵通过非极大值抑制,得到最终的预测结果。
通过s1-s5,采用端到端的非级联结构,不仅能更好的兼具时间和性能两个优势,而且对光照等环境变化有更好的适应性,有效地提高了车牌检测的鲁棒性和网络的泛化能力,极大地降低了车牌检测的误检和漏检,并且在复杂场景下达到实时检测效果。
在具体实施例时,在s1中,为了对已标记图像按预设比例划分为训练集、测试集及验证集,还可以包括以下内容:搜集各省市路面监控照片,并筛选出10000张符合要求的目标图像,其中,符合要求的目标图像是:无大量重叠车辆,车牌遮挡比例低于10%,得到标记了车牌位置的已标记图像,将已标记图像按照按预设比例划分为训练集、测试集及验证集,在本实施例中,训练集可以为50%,测试集可以为40%,验证集可以为10%。其中,训练集用来训练模型,测试集用于测试训练好后的模型的性能,验证集用于控制训练过程中模型的参数,防止模型过拟合。
在s2中,首先,在具体实施过程中,标签数据是很珍贵的,数量可能根本没有达到能够让训练出一个满足要求的模型,此时对数据增强是非常重要的一步,而对数据增强能有效提高模型的泛化能力,同时还可提升模型的鲁棒性,还能让模型的性能更加稳定。为了对标记后的车牌进行数据增强,还可以包括以下内容:
在本实施例中,数据增强一共有5类方法:
s21、对颜色的数据增强,包括饱和度、亮度、曝光度、色调、对比度等方面。增强颜色变换,能让模型更好的适应真实场景下的天气、光照等不可抗力因素。
s22、对尺度的变换,每一轮送入改进的ssd模型进行训练的图片尺寸都会随便改成32整倍数大小,共计10种尺寸选择,分别是384,416,448,512,544,576,608,640,672。增加尺度的变换,能使改进的ssd模型更好的适应不同分辨率的视频、图片以及不同尺寸的车牌。
s23、对角度的变换,图片每次随机旋转0~10度或者水平翻转或者垂直翻转。增加角度变换,能更好的让改进的ssd模型适应真实的环境。
s24、随机噪声干扰,在原来的图片的基础上,随机叠加一些高斯噪声。
s25、随机模糊干扰,在原来的图片的基础上,减少各像素点值的差异实现图片模糊,实现像素的平滑化,随机添加干扰,有助于增强改进的ssd模型对外界环境的抗干扰性。
在s4中,将数据增强处理后放入深度卷积神经网络结构中进行训练的过程,包括:
将输入图片resize到300*300,相当于输入维度为b*3*300*300的矩阵,b为batch_size,b*3*300*300的矩阵经过基础网络vggnet进行部分计算,记录结果为x,其中,vggnet包含13个3*3的卷积层和4个池化层。
x经过basicrfb_s处理,记录结果为s。x经过basicrfb,记录结果为x1。x1经过basicrfb,记录结果为x2。x2经过basicrfb,记录结果为x3。x3经过两个basiconv,记录结果为x4。x4经过两个basicconv,记录结果为x5。[s,x1,x2,x3,x4,x5]将被用于loc_layer计算车牌的位置,通过conf_layer计算此处为车牌的可能性,其中,resize表示缩放,例如:图像的大小为900*900等比例放大到1800*1800或者等比例缩小到300*300。batch_size表示每批次送入ssd模型进行训练的图像数量。vggnet表示基础网络。basicrfb_s表示归一化膨胀卷积层,是经改进后的一个卷积神经网络模块。basicrfb、basicconv均表示为基础膨胀卷积层。
进一步地,loc_layer为6个卷积核大小为1*1的卷积层,s,x1,x2,x3,x4,x5分别经过loc_layer得到六个向量,在对这六个向量做cat操作(直接合并,比如两个[[1,1]]的cat结果为[[1,1,1,1]]),并view为n*1*4的向量,相当于预测了n个预测框,维度4代表预测框的中心点坐标偏差为x,y,以及预测框的长宽信息,其中,view表示维度变换,cat表示通道融合。
进一步地,conf_layer为6个卷积核大小为1*1的卷积层,s,x1,x2,x3,x4,x5分别经过1*1的卷积层得到六个向量,并对这六个向量做cat操作(直接合并,比如两个[[1,1]]的cat结果为[[1,1,1,1]]),并view为n*1*2的向量,相当于对应上面的n个预测框,每个预测框的没有目标的置信度和有车牌的置信度。
在本实施例中,s,x1,x2,x3,x4,x5相当于6个特征图,loc_layer从这6个特征图中提取位置信息,从而得到六个向量,也就是六个结果。
同理,conf_layer也同样从s,x1,x2,x3,x4,x5这6个特征图中提取位置信息,从而得到六个向量,也就是六个结果。
进一步地,一个batch的图片经过上述过程得到n*1*4的矩阵和n*1*2的矩阵,同时可以根据车牌的位置信息计算出相同维度的真实信息,由此根据损失函数计算出每次训练的loss值,通过梯度下降法调整网络参数,使预测值无限接近真实值,其中,batch表示训练批次,一个batch代表一个训练批次。batch_size为是一个批次图像的大小。
在具体实施例中,在不加深网络模型深度的同时在ssd模型上做出改进,在使用vgg16作为基础网络的同时,使用特殊的卷积层替代ssd中部分参数量过大的卷积层,如此可以提升模型的的精度。
详细地,输入300*300的图片经过的深度卷积神经网络中,使用具有rfb模块结构的卷积神经网络代替ssd中部分卷积神经网络。其中,rfb模块结构为:先使用1×1的卷积层,降低featuremap通道数,在每个分支上形成bottleneck结构,再接膨胀卷积层,最后接常规n×n卷积层。使用膨胀卷积层,不仅降低了参数量,而且增加了ssd模型的非线性能力,同时设计了一个类似残差网络的shortcut。
进一步地,模型的loss函数使用了传统的ssd算法中的loss函数,包含用于分类的logloss和用于回归的smoothl1loss,并对正负样本进行了控制,如此,可以提高优化速度和训练结果的稳定性。其中,smoothl1loss表示“直连”或“捷径”,是cnn模型发展中出现的一种非常有效的结构,将相邻的卷积层连接,用于缓解梯度发散。
在具体实施例中,使用上述的训练、验证数据集和改进的ssd模型,结合adam来优化整个模型的损失函数,adam是一种可以替代传统随机度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。随机梯度下降保持单一的学习率更新所有的权重,学习率在训练过程中并不会改变。而adam通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率,而且每次迭代参数的学习步长都有一个确定的范围,不会因为很大的梯度导致很大的学习步长,参数的值比较稳定。
其中,进行训练的一共有两类loss,他们分配的权重不同,分别是定位部分loss与分类部分,在经过9.3万次(batchsize=32)的迭代后,模型的loss几乎不再下降,进一步停止训练。
在s5中,为了得到最终的测试,还可以包括以下内容:输入一张目标图像到深度卷积神经网络中,图片被读取为1*3*300*300的矩阵,经过训练完毕的网络计算,输出n*1*4的矩阵和n*1*2的矩阵,其中,n表示n个预测框和置信度,对输出n*1*4的矩阵和n*1*2的矩阵进行非极大值抑制,可以得到最终的预测框,例如:将两百张带有车牌的图像输入到深度卷积神经网络中,基于该深度卷积神经网络测试出这些图像中的车牌框的位置,进而确定出这些图像中测试正确的图像数量以及测试每张图像所需要的时间。如此,能够确定出测试图像中的车牌的速率和准确率。
在本实施例中,预测框是根据计算的结果得到的多个用于预测车牌位置的车牌框,每个预测框对应有确定该预测框(车牌框)是车牌的概率,相应地,置信度可以根据预测框对应的概率得到。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!