一种电力信息系统海量日志数据实时处理系统的制作方法
本发明涉及电力信息系统日志数据处理领域,具体涉及一种电力信息系统海量日志数据实时处理系统。
背景技术:
随着电力网络信息化的发展,信息技术已经深入到电力生产的各个环节。电力信息系统在运行过程中会产生大量的日志数据,包括系统网络连接状态、数据库状态等系统运行日志以及设备运行参数等业务相关日志。如果对这些海量日志的分析与评价不及时,信息挖掘不准确,可能会造成严重的电力安全事故,因此在电力信息系统运维过程中,针对海量日志数据进行实时有效分析显得尤为必要,数据处理速度不及时和效率低下等问题,严重影响了日志数据的处理和分析。
技术实现要素:
针对上述现有技术存在的问题,本发明提供了一种电力信息系统海量日志数据实时处理系统,通过数据挖掘、大数据分析等相关技术对信息系统多个指标日志数据进行关联分析,实现对系统故障可进行迅速定位,方便查到系统故障根因,提升信息系统运维效率。包括:
接收数据模块,用于接收采集到的海量日志数据;
融合存储模块,用于将海量日志数据存储到hbase数据库中;
数据加载模块,用于数据存储和数据查询过程的实时加载;
实时分析处理模块,采用storm框架技术实时计算海量数据;
数据快速查询检索模块,包括查询请求获取模块,关联规则建立模块和查询结果显示模块,所述查询请求获取模块用于获取用户输入的查询关键字;所述关联规则建立模块基于storm框架技术并行处理数据,建立数据之间的关联;所述查询结果显示模块将查询结果输出到用户端。
作为上述方案的进一步优化,所述融合存储模块,基于storm分布式流式处理技术将海量日志数据存储到hbase数据库中。
作为上述方案的进一步优化,所述融合存储模块中包括内存映射文件,用于存储数据文件到数据文件所在内存地址的映射关系。
作为上述方案的进一步优化,所述数据加载模块,在数据存储过程采用kafka消息队列技术将海量数据实时存储到hbase数据库中,在数据查询过程中采用impala技术从hbase数据库快速获取查询结果。
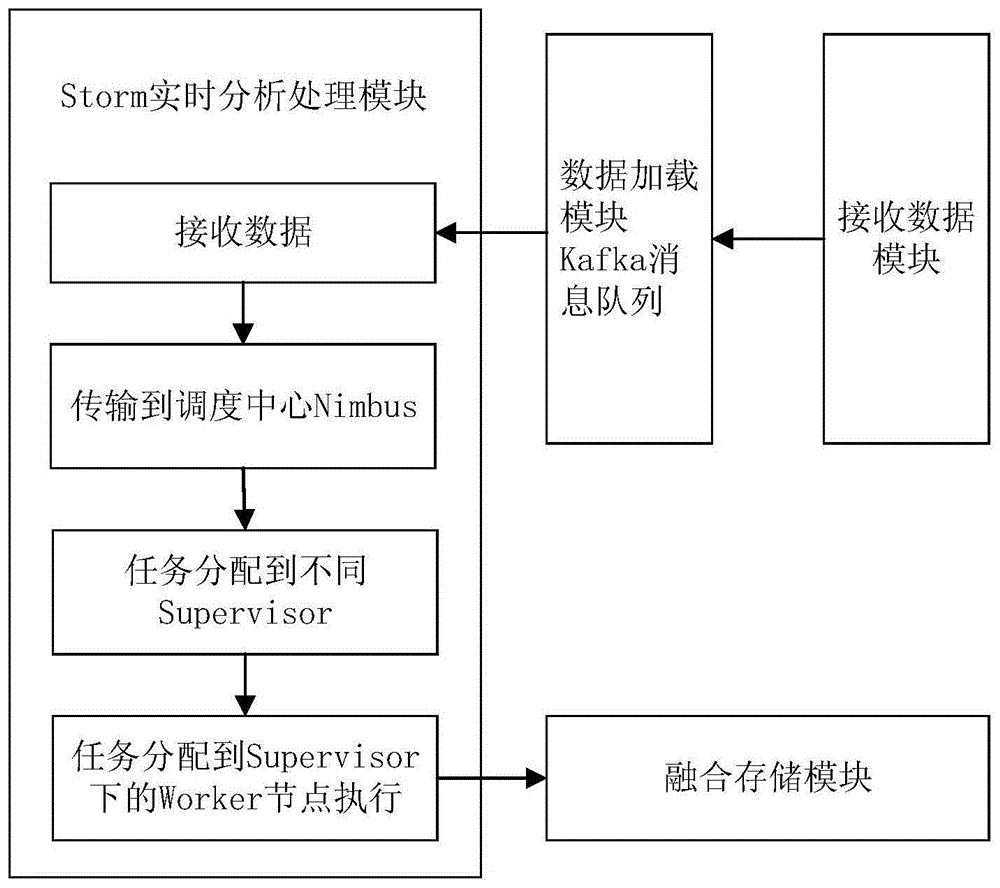
作为上述方案的进一步优化,所述实时分析处理模块,基于storm框架技术从数据加载模块中获取加载的数据,转换成storm中的topology对象,storm中的调度中心nimbus接收topology对象,并将topology对象分配到不同supervisor的不同worker并行执行任务。
作为上述方案的进一步优化,所述关联规则建立模块,具体为:
6.1、对于原始数据库d和新增数据库d中的日志数据经过预处理后,按照日志事件发生时间排列,并通过预设时间间隔的滑动时间窗口,将所有日志事件划分成多项;
6.2、对于原始数据库和新增数据库中的每一项遍历,过滤掉出现次数小于预设值的项,得到原始数据库的所有频繁项组成的频繁项集fd和新增数据库中的所有频繁项组成的频繁项集fd;
6.3、对于集合fd和fd取交集,得到集合c1为原始数据库和新增数据库中都频繁出现的项,取fd和c1的差集,得到在原始数据库中频繁发生,而在新增数据库中不频繁发生的频繁项集合c21,取fd和c1的差集,得到在原始数据库中不频繁发生,而在新增数据库中频繁发生的频繁项集合c31;
6.4、针对频繁项集合c2,在新增数据库中遍历获取每项出现的次数,结合集合c2中的每一项在原始数据库中出现的次数,得到每项出现的总次数;
针对频繁项集合c3,在原始数据库中遍历获取每项出现的次数,结合集合c3中的每一项在新增数据库中出现的次数,得到每项出现的总次数;
6.5、针对频繁项集合c2,过滤掉出现总次数小于预设值的项,得到新的频繁项集合c22;针对频繁项集合c3,过滤掉出现总次数小于预设值的项,得到新的频繁项集合c32;
6.6、合并集合c1、c22和c32得到原始数据库和新增数据库形成的更新数据库的频繁项集合fdd,集合fdd中的每一项中包含的日志事件即为有关联的事件;
作为上述方案的进一步优化,所述查询结果显示模块,通过获取到的查询关键字,在频繁项集合fdd中遍历获取包含关键字的日志事件及其关联事件,得到所查询的日志事件的前因后果事件。
本发明的一种电力信息系统海量日志数据实时处理系统,具备如下有益效果:
1.本发明的一种电力信息系统海量日志数据实时处理系统,采用storm框架技术实现数据的快速处理,在存储方面采用hbase数据库,实现实时存储日志数据,在查询方面,采用基于storm技术的关联规则建立方法,实现快速建立不断更新的数据库中的事件关联规则,从而,快速获取所查询的事件的前因后果,实现对系统故障可进行迅速定位,方便查到系统故障根因,提升信息系统运维效率。
2.本发明的一种电力信息系统海量日志数据实时处理系统,关联规则建立模块中对原始数据库和新增数据库分别进行频繁项挖掘,并通过获取频繁出现在其中一个数据库中的项在另一个数据库出现的次数,得到不断更新的数据库的关联规则,省去了每次有新数据产生时对所有数据进行多次遍历的繁琐过程。
附图说明
图1为本发明的一种电力信息系统海量日志数据实时处理系统,存储数据时的流程框图;
图2为本发明的一种电力信息系统海量日志数据实时处理系统,查询检索时的流程框图;
图3为本发明的一种电力信息系统海量日志数据实时处理系统,关联规则建立模块的流程框图;
实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。
参照附图1-3,本发明提供一种电力信息系统海量日志数据实时处理系统,包括:
接收数据模块,用于接收采集到的海量日志数据;
融合存储模块,用于将海量日志数据存储到hbase数据库中;
数据加载模块,用于数据存储和数据查询过程的实时加载;
实时分析处理模块,采用storm框架技术实时计算海量数据;
数据快速查询检索模块,包括查询请求获取模块,关联规则建立模块和查询结果显示模块,所述查询请求获取模块用于获取用户输入的查询关键字;所述关联规则建立模块基于storm框架技术并行处理数据,建立数据之间的关联;所述查询结果显示模块将查询结果输出到用户端。
整个系统基于storm框架技术实现数据存储和数据查询检索的快速处理,利用大数据技术hbase数据库和kafka消息队列技术,实现海量日志数据的实时动态处理。
在融合存储模块,基于storm分布式流式处理技术将海量日志数据存储到hbase数据库中。
实时分析处理模块,基于storm框架技术从数据加载模块中获取加载的数据,转换成storm中的topology对象,storm中的调度中心nimbus接收topology对象,并将topology对象分配到不同supervisor的不同worker并行执行任务。
接收到采集的数据后,数据缓存到kafka消息队列,storm从kafka消息队列获取稳定的数据流,数据流通过storm的流式处理计算模式,将数据转换成storm中的topology对象,storm中的调度中心nimbus接收topology对象,并将topology对象分配到不同supervisor的不同worker并行执行任务,实现数据的分布式处理,保证消息能够得到快速的处理。
为了实现高速存取数据,采用了内存映射文件方法,在融合存储模块中包括内存映射文件,用于存储数据文件到数据文件所在内存地址的映射关系,使用内存映射文件后,在需要操作数据库中的数据时,不需要直接对数据库中的文件执行i/o操作,节省了将文件数据加载到内存、数据从内存到文件的回写以及释放内存块等时间。
在数据加载模块,在数据存储过程采用kafka消息队列技术将海量数据实时存储到hbase数据库中,在数据查询过程中采用impala技术从hbase数据库快速获取查询结果。
在查询检索数据库数据时,为了快速获取数据库中的数据,采用impala技术从hbase数据库快速获取数据,之后基于storm流式处理数据方法,遍历原始数据库和新增数据库的所有数据,快速获取不断更新的数据之间的关联规则,获取日志事件发生的前因后果,实现对系统故障的迅速定位,方便查到系统故障根因,提升信息系统运维效率。
在关联规则建立模块中,具体过程为:
6.1、对于原始数据库d和新增数据库d中的日志数据经过预处理后,按照日志事件发生时间排列,并通过预设时间间隔的滑动时间窗口,将所有日志事件划分成多项;
6.2、对于原始数据库和新增数据库中的每一项遍历,过滤掉出现次数小于预设值的项,得到原始数据库的所有频繁项组成的频繁项集fd和新增数据库中的所有频繁项组成的频繁项集fd;
6.3、对于集合fd和fd取交集,得到集合c1为原始数据库和新增数据库中都频繁出现的项,取fd和c1的差集,得到在原始数据库中频繁发生,而在新增数据库中不频繁发生的频繁项集合c21,取fd和c1的差集,得到在原始数据库中不频繁发生,而在新增数据库中频繁发生的频繁项集合c31;
6.4、针对频繁项集合c2,在新增数据库中遍历获取每项出现的次数,结合集合c2中的每一项在原始数据库中出现的次数,得到每项出现的总次数;
针对频繁项集合c3,在原始数据库中遍历获取每项出现的次数,结合集合c3中的每一项在新增数据库中出现的次数,得到每项出现的总次数;
6.5、针对频繁项集合c2,过滤掉出现总次数小于预设值的项,得到新的频繁项集合c22;针对频繁项集合c3,过滤掉出现总次数小于预设值的项,得到新的频繁项集合c32;
6.6、合并集合c1、c22和c32得到原始数据库和新增数据库形成的更新数据库的频繁项集合fdd,集合fdd中的每一项中包含的日志事件即为有关联的事件;
在查询结果显示模块,通过获取到的查询关键字,在频繁项集合fdd中遍历获取包含关键字的日志事件及其关联事件,得到所查询的日志事件的前因后果事件。
本发明不局限于上述具体的实施方式,本领域的普通技术人员从上述构思出发,不经过创造性的劳动,所做出的种种变换,均落在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!