目标特征的确定方法及装置与流程
本说明书一个或多个实施例涉及计算机处理
技术领域:
,尤其涉及计算机执行的、目标特征的确定方法及装置。
背景技术:
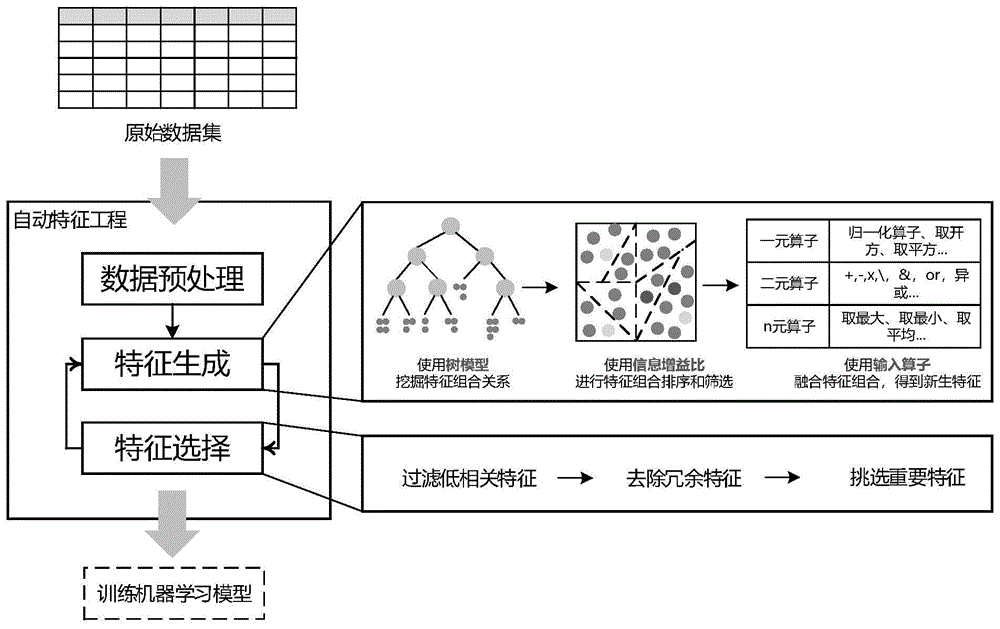
:如今,机器学习技术已在多数行业中得到了广泛的探索和应用,并且已成为处理多种不同领域任务的重要组成部分,例如推荐系统,欺诈检测,广告和人脸识别等。一般而言,要构建机器学习系统,需要经过非常专业且复杂的流程,这通常包括数据准备,特征工程,模型生成和模型评估等。对于其中的特征工程,业界普遍认为,机器学习方法的性能在很大程度上取决于特征的质量,生成良好的特征集已成为寻求算法高性能的关键步骤。因此,大多数机器学习工程师在构建机器学习系统时都会花很大的精力来获得有用的特征。但是,由于特征工程非常依赖于机器学习工程师的直觉和经验,因此需要大量的人工干预。另一方面,随着工业任务中对机器学习技术的需求不断增长,在所有这些任务中人工地进行特征工程变得不切实际,这促进了自动特征工程的诞生。自动特征工程的发展不仅可以节省机器学习工程师的时间、精力,还可以使机器学习技术得到越来越广泛的应用。然而,目前实现自动特征工程的方法较为单一,无法满足实际场景下的多种需求,例如,高可扩展性、更低程度的人工干预等。因此,迫切需要一种自动特征工程方案,可以更好地满足实际场景中的多种需求。技术实现要素:本说明书一个或多个实施例描述了一种目标特征的确定方法,通过建立树模型,挖掘原始特征之间的关系,以缩小特征组合的搜索空间,然后按照信息增益比或其他预测性能评估指标对特征组合进行筛选过滤,从而极大地降低了算法的时间复杂度和空间复杂度。根据第一方面,提供一种目标特征的确定方法。该方法包括:获取原始样本集,其中每个原始样本包括业务对象的样本标签和多个原始特征。基于所述原始样本集,进行多轮迭代,将迭代结束得到的多个当前特征,确定为所述业务对象的目标特征,用于训练针对所述业务对象的机器学习模型;所述多个当前特征初始为所述多个原始特征。其中,所述多轮迭代中任意一轮的迭代包括:基于当前样本集,建立树模型,每个当前样本包括所述样本标签和多个当前特征,所述树模型中包括多条预测路径;针对单条预测路径,获取其中包含的多个父节点所对应的多个分裂特征,其中父节点为所述树模型的根节点和叶子节点之间的节点;基于所述多个分裂特征中任意数量的分裂特征的组合,确定与该条预测路径对应的多个特征组合;所述多条预测路径各自对应的多个特征组合构成特征组合集;根据针对预测能力预设的评估指标,从所述特征组合集中,选取多个优选特征组合;利用预先定义的算子,对各个优选特征组合中包含的特征进行融合处理,得到多个新生特征;基于所述多个新生特征,更新所述多个当前特征。在一个实施例中,所述业务对象为用户,所述多个原始特征包括用户的原始属性特征和/或原始业务特征,所述针对业务对象的机器学习模型为用户分类模型或用户评分模型。在一个实施例中,根据针对预测能力预设的评估指标,从所述特征组合集中,选取多个优选特征组合,包括:根据所述评估指标,计算所述特征组合集中各个特征组合对应的指标值,得到多个指标值;基于所述多个指标值,对所述特征组合集中的特征组合进行排序;将排名在预定范围内的特征组合,确定为所述多个优选特征组合。在一个具体的实施例中,所述特征组合集中包括第一特征组合;根据所述评估指标,计算所述特征组合集中各个特征组合对应的指标值,包括:基于所述第一特征组合中的分裂特征和对应的分裂值,将所述当前样本集划分为多个样本子集;基于所述各个样本子集中分属于不同样本标签的样本数量,计算针对所述评估指标的指标值,作为所述第一特征组合对应的指标值。在一个实施例中,所述评估指标为信息增益比或基尼系数。在一个实施例中,所述多个优选特征组合中包括任意的第一优选组合;利用预先定义的算子,对各个优选特征组合中包含的特征进行处理,得到多个新生特征,包括:确定出所述第一优选组合中所包含特征的数量为n,n为正整数;分别利用所述算子中的若干n元算子,对所述第一优选组合中包含的n个特征进行处理,得到若干新生特征,归入所述多个新生特征。在一个实施例中,所述算子包括以下中的一种或多种:逻辑运算符、归一化运算符、算术运算符。在一个实施例中,基于所述多个新生特征,更新所述多个当前特征,包括:根据信息价值iv指标,从所述多个新生特征和多个当前特征中,选取多个优选特征;利用所述多个优选特征,更新所述多个当前特征。在一个具体的实施例中,根据信息价值iv指标,从所述多个新生特征和多个当前特征中,选取多个优选特征,包括:计算所述多个新生特征和所述多个当前特征的集合对应的多个iv值;从所述多个iv值中,确定出大于预设指标阈值的多个达标值;将所述多个达标值对应的特征,确定为所述多个优选特征。在一个更具体的实施例中,所述多个优选特征中包括第一特征和第二特征;利用所述多个优选特征,更新所述多个当前特征,包括:确定所述第一特征和第二特征之间的相关度;在所述相关度大于预定相关度阈值的情况下,获取所述第一特征和第二特征对应于所述iv指标的两个iv值,并对其中更小的iv值所对应的特征进行去除。在一个实施例中,基于所述多个新生特征,更新所述多个当前特征,包括:基于重构样本集,建立重构树模型;其中,每个重构样本中包括所述样本标签,以及所述多个新生特征和多个当前特征;获取所述重构树模型中的多个父节点对应的多个分裂特征和多个分裂增益;基于所述多个分裂增益,对所述多个分裂特征进行排序;利用排名在预设范围内的分裂特征,更新所述多个当前特征。根据第二方面,提供一种目标特征的确定装置,该装置包括:获取模块,配置为获取原始样本集,其中每个原始样本包括业务对象的样本标签和多个原始特征;迭代模块,配置为基于所述原始样本集,进行多轮迭代,将迭代结束得到的多个当前特征,确定为所述业务对象的目标特征,用于训练针对所述业务对象的机器学习模型;所述多个当前特征初始为所述多个原始特征。其中,所述迭代模块通过其中包括的以下单元进行所述多轮迭代中任意一轮的迭代:树模型建立单元,配置为基于当前样本集,建立树模型;其中,每个当前样本包括所述样本标签和多个当前特征,所述树模型中包括多条预测路径;分裂特征获取单元,配置为针对单条预测路径,获取其中包含的多个父节点所对应的多个分裂特征,其中父节点为所述树模型的根节点和叶子节点之间的节点;特征组合确定单元,配置为基于所述多个分裂特征中任意数量的分裂特征的组合,确定与该条预测路径对应的多个特征组合;所述多条预测路径各自对应的多个特征组合构成特征组合集;优选组合选取单元,配置为根据针对预测能力预设的评估指标,从所述特征组合集中,选取多个优选特征组合;特征生成单元,配置为利用预先定义的算子,对各个优选特征组合中包含的特征进行融合处理,得到多个新生特征;当前特征更新单元,配置为基于所述多个新生特征,更新所述多个当前特征。根据第三方面,提供了一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行第一方面的方法。根据第四方面,提供了一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现第一方面的方法。综上,在本说明书实施例披露的目标特征的确定方法中,通过多轮迭代的方式确定目标特征,具体在每轮迭代中,先通过建立树模型来挖掘多个当前特征之间的关系以缩小特征组合的搜索空间,然后按照预测能力评估指标对特征组合进行筛选过滤,然后将预定义的算子作用于筛选出的优选特征组合,以得到多个新生特征,从而极大地降低了算法的时间复杂度和空间复杂度。进一步地,还可以将新生特征和当前特征作为候选特征进行进一步筛选,从而高效地挑选出重要特征,剔除冗余特征。此外,所述方法对于机器学习工程师而言,使用简单,具体地,需要其预先设置的超参数仅用于控制算法的复杂度,例如迭代次数或迭代时间、树的数量以及每棵树的深度等,而这些超参数的设置并不复杂,如此可以将节省机器学习工程师在特征工程中花费的时间和精力。附图说明为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。图1示出根据一个实施例的自动特征工程的实施流程图;图2示出根据一个实施例的目标特征的确定方法流程图;图3示出根据一个实施例的树模型中包括的决策树;图4示出根据一个实施例的目标特征的确定装置结构图。具体实施方式下面结合附图,对本说明书提供的方案进行描述。如前所述,自动特征工程的发展不仅可以节省机器学习工程师的时间、精力,还可以使机器学习技术得到越来越广泛的应用。目前,有些方法使用基于强化学习的策略来执行自动特征工程,但是,这些方法在工业任务落地应用非常困难。也有些方法使用基于迁移学习或元学习的策略来进行自动特征工程,但是,这些方法需要事先在多种数据集上进行大量实验来训练元模型,同时在这些方法中引入新的算子或增加父特征的数量是很困难的。另外,还有一些方法按照“特征生成->特征选择”的过程进行自动特征工程,然而,现有的这些方法通常需要在特征生成阶段生成所有合法特征,然后对其进行特征选择,因此时间复杂度和空间复杂度都极高,不适用于大数据量或大特征尺寸的任务。基于此,发明人提出一种进行自动特征工程的方法,基于原始数据集进行多轮迭代,最终得到用于训练机器学习模型的目标特征。其中多轮迭代中的每轮迭代包括特征生成阶段和特征选择阶段,具体地,图1示出根据一个实施例的自动特征工程的实施流程图,其中特征生成阶段包括:首先基于当前数据集建立树模型,进而根据树模型中的预测路径确定特征组合,如此通过建立树模型可以挖掘单个特征之间的关系,以缩小特征组合的搜索空间;然后按照信息增益比或其他预测能力评估指标对确定出的特征组合进行筛选过滤,从而极大地降低算法的时间复杂度和空间复杂度;接着将预先定义的算子(如逻辑运算符,取最大值运算符等)作用于过滤后保留的特征组合,得到新生成的特征,如此实现特征的生成。接下来,特征选择阶段包括:将新生成的特征和上述当前数据集中的特征都作为候选特征,并对这些候选特征进行筛选(如去除冗余特征等),得到的特征用于更新当前数据集并进行下一轮迭代。需要理解,在最后一轮迭代中,对候选特征进行筛选得到的特征即为上述目标特征。如此可以实现低人工干预、高拓展性的自动特征工程。下面结合具体的实施例,描述本说明书实施例中披露的自动特征工程方法,也就是确定上述目标特征的方法。具体地,图2示出根据一个实施例的目标特征的确定方法流程图,所述方法的执行主体可以为任何具有计算、处理能力的装置或设备或平台或设备集群。如图2所示,所述方法包括以下步骤:步骤s21,获取原始样本集,其中每个原始样本包括业务对象的样本标签和多个原始特征。步骤s22,基于所述原始样本集,进行多轮迭代,将迭代结束得到的多个当前特征,确定为所述业务对象的目标特征,用于训练针对所述业务对象的机器学习模型;所述多个当前特征初始为所述多个原始特征;其中,所述多轮迭代中任意一轮的迭代包括:步骤s221,基于当前样本集,建立树模型;其中,每个当前样本包括所述样本标签和多个当前特征,所述树模型中包括多条预测路径;步骤s222,针对单条预测路径,获取其中包含的多个父节点所对应的多个分裂特征,其中父节点为所述树模型的根节点和叶子节点之间的节点;步骤s223,基于所述多个分裂特征中任意数量的分裂特征的组合,确定与该条预测路径对应的多个特征组合;所述多条预测路径各自对应的多个特征组合构成特征组合集;步骤s224,根据针对预测能力预设的评估指标,从所述特征组合集中,选取多个优选特征组合;步骤s225,利用预先定义的算子,对各个优选特征组合中包含的特征进行融合处理,得到多个新生特征;步骤s226,基于所述多个新生特征,更新所述多个当前特征。以上步骤具体如下:首先,在步骤s21,获取原始样本集,其中每个原始样本包括业务对象的样本标签和多个原始特征。需要理解,上述原始样本集可以由工作人员根据实际需要,通过多种渠道采集,包括从系统后台或系统数据库中采集、利用网络爬虫从网站中爬取、发放调查问卷、在应用程序app中埋点采集,等等。在一个实施例中,上述业务对象可以为用户,上述多个原始特征可以包括用户的原始属性特征和原始业务特征。在一个具体的实施例中,其中原始属性特征可以包括用户的静态画像方面的特征,例如性别、年龄、职业、收入和教育程度等。在一个具体的实施例中,其中原始业务特征可以包括用户的操作行为方面的特征,例如最近一次操作的类型、操作的页面和停留的时间等等。在另一个具体的实施例中,其中原始业务特征还可以包括用户的金融资产方面的特征,例如余额宝余额、近期消费次数和消费金额等等。在又一个具体的实施例中,其中原始业务特征还可以包括用户的信用记录方面的特征,例如借款次数、借款金额和还款金额等等。在还一个具体的实施例中,其中原始业务特征还可以包括用户的社交方面的特征,例如好友数目、与好友的沟通频次,沟通类别等等。在另一个实施例中,上述业务对象可以为商品,需要理解,该商品可以为实体商品,如电器、纸质书籍、水果等,也可以为虚拟商品,如网络游戏、新闻资讯、视频课程等。在一个具体的实施例中,其中原始属性特征可以包括商品的产地、生产商、种类、价格、售卖平台和上市日期等。在一个具体的实施例中,其中原始业务特征可以包括商品的销售情况方面的特征,如日均销售量、销售淡季、销售旺季、回购次数、热销时间段。在另一个具体的实施例中,其中原始业务特征可以包括商品的购买人群特征,如购买者的年龄段、职业等。在又一个实施例中,上述业务对象可以为文本或图片或音频。另一方面,在一个实施例中,上述样本标签可以指示业务对象的类别,换言之,上述样本标签可以为类别标签。具体地,对于业务对象为用户的情况,在一个具体的实施例中,其中类别标签可以为指示用户账户风险的风险类别标签。在一个例子中,其中风险类别标签可以为风险等级标签,具体如高风险、中等风险和低风险等。在另一个例子中,其中风险类别标签可以包括普通用户或高风险用户(如涉嫌欺诈、盗号的用户账户)。在另一个具体的实施例中,其中类别标签还可以为指示用户营销敏感度的类别标签,如营销敏感度等级。此外,对于业务对象为商品的情况,在一个具体的实施例中,其中类别标签可以为指示商品热门程度的类别标签,如热门等级。在另一个具体的实施例中,其中类别标签可以为指示商品受众所属人群的人群类别标签。在一个例子中,其中人群类别标签可以包括男性或女性。在另一个例子中,其中人群类别标签可以包括儿童、青少年、中年和老年。再者,对于业务对象为文本或图片或音频的情况,在一个具体的实施例中,其中类别标签可以为学科类别,如语文、数学、英语、化学和物理等。以上,对获取的原始样本集进行介绍。在获取原始样本集后,接着在步骤s22,基于所述原始样本集,进行多轮迭代,将迭代结束得到的多个当前特征,确定为所述业务对象的目标特征,用于训练针对所述业务对象的机器学习模型,所述多个当前特征初始为上述多个原始特征。在一个实施例中,上述业务对象为用户,相应地,上述机器学习模型可以为用户分类模型或用户打分模型。在一个具体的实施例中,其中用户分类模型可以为风险等级预测模型或人群类别预测模型。在一个具体的实施例中,其中用户打分模型可以为账户安全分数预测模型或用户营销价值预测模型。在另一个实施例中,上述业务对象为商品,相应地,上述机器学习模型可以为商品分类模型或商品打分模型。在一个具体的实施例中,其中商品分类模型可以为商品受众预测模型或商品热门等级预测模型。在一个具体的实施例中,其中商品打分模型可以为商品热度预测模型。在又一个实施例中,上述业务对象为文本或图片或音频,相应地,上述机器学习模型可以为文本处理模型或图片处理模型或音频处理模型。具体地,上述多轮迭代中任意一轮的迭代包括以下步骤s221-步骤s226:首先,在步骤s221,基于当前样本集,建立树模型。具体地,当前样本集中的每个当前样本包括上述样本标签和多个当前特征。需要说明,其中多个当前特征初始为上述多个原始特征,这也意味着,当前样本集初始为上述原始样本集。上述树模型是根据当前样本集进行训练得到的。在一个实施例中,上述树模型基于的算法可以为gbdt(gradientboostingdeisiontree,梯度提升决策树)算法、xgboost(extremegradientboosting)算法、cart(classificationandregressiontree,分类和回归树)算法等。为便于理解,下面对建立的树模型进行介绍,树模型中可以包括多棵决策树,在一个实施例中,图3示出根据一个实施例的树模型中包括的决策树,其中包括根节点31和多个叶子节点(如叶子节点35),在根节点和各个叶子节点之间包括多个父节点(如父节点32)。进一步地,根节点31对应上述当前样本集,当前样本集中的样本经过决策树中的预测路径,可以被划分到某个叶子节点中,其中预测路径是指从对应叶子节点至其所在决策树的根节点之间的节点连接路径(图3中通过加粗示出一条预测路径),并且,各个父节点具有对应的分裂特征、分裂值,其中分裂特征为上述多个当前特征中的某一个特征。以父节点32为例,其对应的分裂特征和分裂值分别表示为x(1)和v1,对于某个当前样本,其对应于分裂特征x(1)的特征值若小于v1(此时判断结果为y),则被划分到左子树,若不小于v1(此时判断结果为n),则被划分到右子树。需要说明,图3中特征x的上标中均未画出括号。由上可知,建立的树模型中包括多条预测路径,对于各条预测路径,在其根节点至叶子节点之间存在多个父节点,而各个父节点具有对应的分裂特征和分裂值。需要说明,不同父节点对应的分裂特征可能相同。基于以上建立的树模型,在步骤s222,针对单条预测路径,获取其中包含的多个父节点所对应的多个分裂特征。在一个实施例中,参见图3,针对加粗显示的预测路径,可以获取其中包括的3个父节点(父节点32、父节点33和父节点34对应的3个分裂特征:x(1)、x(2)和x(3)。进一步地,在步骤s223,基于所述多个分裂特征中任意数量的分裂特征的组合,确定与该条预测路径对应的多个特征组合。由此,所述多条预测路径各自对应的多个特征组合构成特征组合集。在一个实施例中,可以通过穷举的方法,对多个分裂特征进行组合。具体地,假定多个分裂特征的数量为k(为正整数),则基于多个分裂特征,依次确定由1至k个分裂特征组成的特征组合,归入上述多个特征组合。在一个具体的实施例中,对于分裂特征x(1)、x(2)和x(3),可以确定出多个特征组合:{x(1)}、{x(2)}、{x(3)}、{x(1),x(2)}、{x(1),x(3)}、{x(2),x(3)}和{x(1),x(2),x(3)}。进一步地,对确定出的多条预测路径各自对应的多个特征组合进行汇总,可以构成特征组合集。在一个实施例中,基于不同预测路径确定的多个特征组合中,可能存在相同的特征组合,在汇总时可以进行去重处理。在一个具体的实施例中,特征组合中还包括分裂特征对应的分裂值,由此在进行去重处理时,只有两个特征组合中的分裂特征和对应的分裂值都相同时,才去除掉其中一个,否则两个都予以保留。在一个例子中,假定两条预测路径对应的特征组合中分别包括{x(1),v11;x(2),v21},和{x(1),v12;x(2),v22},若其中v11=v12,并且,v21=v22,则将其中任一个特征组合进行去除,否则对两个都予以保留。如此,实现对特征组合的汇总、去除,进而得到特征组合集。以上,通过建立的树模型挖掘当前特征之间的关系,实现缩小特征组合的搜索空间。在确定出特征组合集后,在步骤s224,根据针对预测能力预设的评估指标,从所述特征组合集中,选取多个优选特征组合。如此,可以进一步缩小特征组合的搜索空间。具体地,根据所述评估指标,计算所述特征组合集中各个特征组合对应的指标值,得到多个指标值;然后,基于多个指标值,选取多个优选特征组合。在一个实施例中,对于特征组合集中任意的第一特征组合的指标值的计算,可以包括以下步骤:先基于所述第一特征组合中的分裂特征和对应的分裂值,将所述当前样本集划分为多个样本子集;再基于所述各个样本子集中分属于不同样本标签的样本数量,计算针对所述评估指标的指标值,作为所述第一特征组合对应的指标值。在一个具体的实施例中,对于其中将当前样本集划分为多个样本子集,以具有q个特征的特征组合{x(1),…,x(q)}为例,已知他们的分割值为{v1,…,vq},其中vi(1≤i≤q)是一个集合,因为同一个分割特征可能在单个路径中出现多次,这些分裂特征和分裂值可以将当前样本集划分为个样本子集,其中|vi|表示集合vi中元素(此处为分裂值)的个数。如此,可以实现对当前样本集的划分。基于划分出的多个样本子集,计算针对评估指标的指标值。在一个具体的实施例中,评估指标可以为信息增益,信息增益的计算公式如下:i(d,a)=h(d)-h(d|a)(1)在公式(1)-公式(3)中,d表示当前样本集,a表示某个特征组合,i(d,a)表示信息增益,k表示d中样本标签的类别总数,dk表示由当前样本集中样本标签为第k类的样本组成的集合,|dk|表示dk中样本的数量,|d|表示d中样本的数量,h(d)表示d中存在k个类别的样本所产生的信息熵,h(d|a)表示在已知d中特征组合a的分布情况的条件熵,t表示基于特征组合a对d进行划分所得到的多个样本子集的数量,dt表示该多个样本子集中的第t个样本子集,|dt|表示dt中样本的数量,h(dt)表示dt中存在k个类别的样本所产生的信息熵。由此可以计算出信息增益,作为特征组合的指标值。在另一个具体的实施例中,评估指标可以为信息增益比,信息增益比的计算公式如下:在公式(4)和(5)中,ir(d,a)表示信息增益比,i(d,a)表示信息增益,ha(d)表示特征熵,也就是d被特征组合划分为t个子集而产生的信息熵,具体还可参见对上述公式(1)-(3)的描述。由此可以计算出信息增益比,作为特征组合的指标值。在又一个具体的实施例中,评估指标可以为基尼系数,基尼系数的计算公式如下:在公式(6)-(7)中,d表示当前样本集,a表示某个特征组合,gini(d,a)表示已知d中特征组合a的分布情况的基尼系数,t表示基于特征组合a对d进行划分所得到的多个样本子集的数量,dt表示该多个样本子集中的第t个样本子集,|dt|表示dt中样本的数量,|d|表示d中样本的数量,gini(dt)表示dt中存在k个类别而得到的基尼系数,k表示d中样本标签的类别数量,表示dt中第k个类别的样本组合的集合,表示中样本的数量。由此可以计算出基尼系数,作为特征组合的指标值。以上,可以计算出特征组合集对应的多个指标值。进一步地,基于多个指标值,选取多个优选特征组合。在一个实施例中,可以基于多个指标值,对所述特征组合集中的特征组合进行排序;然后将排名在预定范围内的特征组合,确定为所述多个优选特征组合。需要理解,指标值指示出特征组合的预测能力越强,则特征组合的排名越搞钱。在一个具体的实施例中,其中预定范围内可以为预定名次内,如前50或前100个特征组合。在另一个具体的实施例中,其中预定范围内可以为百分比(如前10%或5%)等。如此可以选取在预定范围内的特征组合,作为多个优选特征组合。在另一个实施例中,可以基于预先设定的针对评估指标的评估阈值,确定多个指标值中大于评估阈值的指标值,并将对应的特征组合归入优选特征组合。如此,可以实现对多个优选特征组合的选取。然后,在步骤s225,利用预先定义的算子,对各个优选特征组合中包含的特征进行融合处理,得到多个新生特征。由此可知,在本说明书实施例披露的方法中,不限制特征生成算子,并且可以选择合适的算子送入算法。在一个实施例中,其中算子可以为多个,具体可以包括n元算子,其中n可以为任意的正整数。在一个具体的实施例中,1元算子可以包括用于实现特征离散化的算子,如chimerge、聚类分箱(clusteringbinning)等。在另一个具体的实施例中,1元算子可以包括用于实现归一化的归一化运算符,如z-score,线性函数归一化(min-maxscaling)等。在又一个具体的实施例中,1元算子还可以包括四舍五入算子、开方算子、tanh、sigmoid、log等等。在一个具体的实施例中,2元算子可以包括算数运算符,如基本四则运算符:+、-、x、÷。在另一个具体的实施例中,2元算子还可以包括逻辑运算符,例如:和、或、异或、非,等等。在又一个具体的实施例中,2元运算子可以包括脊回归运算符(ridgeregression)和核回归运算符(kernelregression)。在一个具体的实施例中,n元算子还可以包括求取最大值算子、求取最小值算子、求取平均值算子,等等。基于这些算子,对特征组合中包含的特征进行融合。在一个实施例中,本步骤中可以包括:针对多个优选特征组合中任意的第一优选特征组合,确定出其中所包含特征的数量为n(为正整数);分别利用所述算子中的若干n元算子,对所述第一优选组合中包含的n个特征进行处理,得到若干新生特征,归入所述多个新生特征。在一个例子中,假定第一优选特征组合为{x(1),x(3)},由此可以确定出其中包含的特征数量为2;再分别利用多个1元算子(如归一化算子、四舍五入算子),对当前样本中对应于这些特征的特征值进行计算,得到新生特征。由此,对多个优选特征组合中各个特征组合所包含的特征进行融合处理,可以得到多个新生特征。接着在步骤s226,基于上述多个新生特征,更新多个当前特征。需要说明,在一种实施方式中,可以直接将多个新生特征归入多个当前特征中,由此实现对当前特征的更新。在另一种实施方式中,可以将多个新生特征和多个当前特征对应的集合作为候选特征集,或者说对应的全量特征作为多个候选特征,然后对候选特征进行筛选,并将多个当前特征更新为该筛选后保留的特征。此外,其中的筛选可以包括一种筛选方式或者多种筛选方式的组合,具体涉及的筛选方式可以包括去除预测价值低的特征,去除冗余特征、去除利用特征评估模型进行打分后得到的低分特征。在一个实施例中,本步骤中可以包括:根据信息价值iv(informationvalue,信息价值或信息量)指标,从上述多个候选特征中选取多个优选特征;再利用多个优选特征,更新多个当前特征。在一个具体的实施例中,其中根据信息价值iv指标,从上述多个候选特征中选取多个优选特征,可以包括:先计算多个候选特征对应的多个iv值;接着从多个iv值中,确定出大于预设指标阈值的多个达标值,进而将所述多个达标值对应的特征,确定为所述多个优选特征。在一个更具体的实施例中,对于多个候选特征中任意的第一候选特征,先基于当前样本集中各个当前样本对应于第一候选特征的特征值,对当前样本进行排序,进而进行分箱处理,其中分箱的数量为超参,可以有工作人员预先设定,如2或5等等,每个分箱对应一个特征值区段。在一个例子中,计算iv指标的公式如下:其中,β表示分箱的总数量,为超参,np和nn分别表示当前样本集中正样本(如样本标签为0)和负样本(如样本标签为1)的数量,和分别表示第i(1≤i≤β)个分箱中正样本和负样本的数量。如此可以计算出第一候选特征对应的iv值,由此类推,可以计算出多个候选特征对应的多个iv值。进一步地,基于多个iv值,选取多个优选特征。在一个具体的实施例中,可以将多个iv值中大于预设指标阈值的指标值,所对应的特征予以保留,归入多个优选特征,并舍弃其余候选特征。在一个例子中,对于其中预设指标阈值的设定,可以参考表1(业内经验表)中的数据进行,表1中包括iv值的区段和对应的预测能力。表1iv值预测能力或预测价值[0,0.02]几乎没有(0.02-0.1]较弱(0.1-0.3]中等(0.3-0.5]较强>0.5极强(可能存在异常)基于表1中的经验数据,可以将预设指标阈值设定为0.1。如此,基于预设指标阈值和上述计算出的多个iv值,可以去除多个候选特征中预测能力较差的特征,而保留预测能力较强的多个优选特征。进一步地,在一个实施例中,可以直接将上述多个当前特征更新为所述多个优选特征。在另一个实施例中,可以对多个优选特征进行进一步筛选。在一个具体的实施例中,可以进一步去除冗余特征。具体地,对于多个优选特征中包括的任意的第一特征和第二特征,确定这两个特征之间的相关度,然后,在所述相关度大于预定相关度阈值的情况下,获取所述第一特征和第二特征对应于上述第二评估指标的两个指标值,并对其中更小的指标值所对应的特征进行去除,在上述相关度小于预定相关度阈值的情况下,保留这两个特征。在一个更具体的实施例中,其中相关度的确定,可以通过计算以下相关系数中的任意一种而实现,包括pearson、spearman、kendall、mic(maximalinformationcoefficient,最大互信息系数)。在另一个具体的实施例中,其中预定相关度阈值可以由工作人员根据经验或实际需求进行设定,如设定为0.7或0.8等。由此,可以对上述优选特征进行冗余特征的去除,对于保留的特征,可以直接用于更新多个当前特征,也可以经过其他筛选后,再用于多个当前特征的更新。以上,对利用预测能力指标(可以包括上述iv值、还可以包括信息增益等指标)和相关系数,去除多个候选特征中的低预测能力特征和冗余特征进行介绍。在另一个实施例中,本步骤中可以包括:首先,基于重构样本集,建立重构树模型,其中每个重构样本中包括上述样本标签,以及上述多个候选特征;接着,获取所述重构树模型中的多个父节点对应的多个分裂特征和多个分裂增益;然后,基于所述多个分裂增益,对所述多个分裂特征进行排序;再接着,利用排名在预设范围内的分裂特征,更新所述多个当前特征。需要说明,分裂增益是在重构树模型的训练过程中,从多个候选特征中选取分裂特征及选取对应的分裂值时确定的。在一个具体的实施例中,上述重构树模型为cart分类树模型,则其中父节点对应的分裂增益通常是通过计算信息增益比而得到。另一个具体的实施例中,上述重构树模型为gbdt或xgboost树模型,则其中父节点对应的分裂增益通常是通过计算基尼系数而得到。在一个具体的实施例中,其中预设范围可以根据实际需要进行设定,如设定为前100或前50%等。如此,可以通过训练模型,实现对候选特征的评分,再根据评分结果进行候选特征的筛选。根据一个具体的例子,对于上述多个候选特征的筛选,可以采用以下筛选流程:先计算iv值以去除预测能力低的特征;再计算皮尔森相关系数以去除冗余特征;最后建立重构树模型实现对特征的打分,并去除低分特征。基于此,可以将上述多个当前特征更新为通过筛选后最终保留的特征,进而实现对多个当前特征的更新。以上,通过执行步骤s221-步骤s226,可以实现任一轮迭代,由此,重复执行步骤s221-步骤s226,可以实现上述多轮迭代,并将最后一轮迭代后得到的多个当前特征确定为上述目标特征,用于训练针对业务对象的机器学习模型。综上,在本说明书实施例披露的目标特征的确定方法中,通过多轮迭代的方式确定目标特征,具体在每轮迭代中,先通过建立树模型来挖掘多个当前特征之间的关系以缩小特征组合的搜索空间,然后按照预测能力评估指标对特征组合进行筛选过滤,然后将预定义的算子作用于筛选出的优选特征组合,以得到多个新生特征,从而极大地降低了算法的时间复杂度和空间复杂度。进一步地,还可以将新生特征和当前特征作为候选特征进行进一步筛选,从而高效地挑选出重要特征,剔除冗余特征。此外,所述方法对于机器学习工程师而言,使用简单,具体地,需要其预先设置的超参数仅用于控制算法的复杂度,例如迭代次数或迭代时间、树的数量以及每棵树的深度等,而这些超参数的设置并不复杂,如此可以将节省机器学习工程师在特征工程中花费的时间和精力。根据另一方面的实施例,提供了一种确定装置。具体地,图4示出根据一个实施例的目标特征的确定装置结构图,所述装置可以通过任何具有计算能力的设备或计算平台或服务器或服务器集群等实现。如图4所示,所述装置40包括:获取模块41,配置为获取原始样本集,其中每个原始样本包括业务对象的样本标签和多个原始特征。迭代模块42,配置为基于所述原始样本集,进行多轮迭代,将迭代结束得到的多个当前特征,确定为所述业务对象的目标特征,用于训练针对所述业务对象的机器学习模型;所述多个当前特征初始为所述多个原始特征。其中,所述迭代模块42通过其中包括的以下单元进行所述多轮迭代中任意一轮的迭代:树模型建立单元421,配置为基于当前样本集,建立树模型;其中,每个当前样本包括所述样本标签和多个当前特征,所述树模型中包括多条预测路径。分裂特征获取单元422,配置为针对单条预测路径,获取其中包含的多个父节点所对应的多个分裂特征,其中父节点为所述树模型的根节点和叶子节点之间的节点。特征组合确定单元423,配置为基于所述多个分裂特征中任意数量的分裂特征的组合,确定与该条预测路径对应的多个特征组合;所述多条预测路径各自对应的多个特征组合构成特征组合集。优选组合选取单元424,配置为根据针对预测能力预设的评估指标,从所述特征组合集中,选取多个优选特征组合。特征生成单元425,配置为利用预先定义的算子,对各个优选特征组合中包含的特征进行融合处理,得到多个新生特征。当前特征更新单元426,配置为基于所述多个新生特征,更新所述多个当前特征。在一个实施例中,所述业务对象为用户,所述多个原始特征包括用户的原始属性特征和/或原始业务特征,所述针对业务对象的机器学习模型为用户分类模型或用户评分模型。在一个实施例中,优选组合选取单元424具体包括:计算子单元4241,配置为根据所述评估指标,计算所述特征组合集中各个特征组合对应的指标值,得到多个指标值;排序子单元4242,配置为基于所述多个指标值,对所述特征组合集中的特征组合进行排序;确定子单元4243,配置为将排名在预定范围内的特征组合,确定为所述多个优选特征组合。在一个具体的实施例中,所述特征组合集中包括第一特征组合;所述计算子单元4241具体配置为:基于所述第一特征组合中的分裂特征和对应的分裂值,将所述当前样本集划分为多个样本子集;基于所述各个样本子集中分属于不同样本标签的样本数量,计算针对所述评估指标的指标值,作为所述第一特征组合对应的指标值。在一个实施例中,所述评估指标为信息增益比或基尼系数。在一个实施例中,所述多个优选特征组合中包括任意的第一优选组合;所述特征生成单元425具体配置为:确定出所述第一优选组合中所包含特征的数量为n,n为正整数;分别利用所述算子中的若干n元算子,对所述第一优选组合中包含的n个特征进行处理,得到若干新生特征,归入所述多个新生特征。在一个实施例中,所述算子包括以下中的一种或多种:逻辑运算符、归一化运算符、算术运算符。在一个实施例中,所述当前特征更新单元426具体包括:选取子单元4261,配置为根据信息价值iv指标,从所述多个新生特征和多个当前特征中,选取多个优选特征;更新子单元4262,配置为利用所述多个优选特征,更新所述多个当前特征。在一个具体的实施例中,所述选取子单元4261具体配置为:计算所述多个新生特征和所述多个当前特征的集合对应的多个iv值;从所述多个iv值中,确定出大于预设指标阈值的多个达标值;将所述多个达标值对应的特征,确定为所述多个优选特征。在一个更具体的实施例中,所述多个优选特征中包括第一特征和第二特征;所述更新子单元4262具体配置为:确定所述第一特征和第二特征之间的相关度;在所述相关度大于预定相关度阈值的情况下,获取所述第一特征和第二特征对应于所述iv指标的两个iv值,并对其中更小的iv值所对应的特征进行去除。在一个实施例中,所述当前特征更新单元426具体配置为:基于重构样本集,建立重构树模型;其中,每个重构样本中包括所述样本标签,以及所述多个新生特征和多个当前特征;获取所述重构树模型中的多个父节点对应的多个分裂特征和多个分裂增益;基于所述多个分裂增益,对所述多个分裂特征进行排序;利用排名在预设范围内的分裂特征,更新所述多个当前特征。综上,在本说明书实施例披露的目标特征的确定装置中,通过多轮迭代的方式确定目标特征,具体在每轮迭代中,先通过建立树模型来挖掘多个当前特征之间的关系以缩小特征组合的搜索空间,然后按照预测能力评估指标对特征组合进行筛选过滤,然后将预定义的算子作用于筛选出的优选特征组合,以得到多个新生特征,从而极大地降低了算法的时间复杂度和空间复杂度。进一步地,还可以将新生特征和当前特征作为候选特征进行进一步筛选,从而高效地挑选出重要特征,剔除冗余特征。此外,所述方法对于机器学习工程师而言,使用简单,具体地,需要其预先设置的超参数仅用于控制算法的复杂度,例如迭代次数或迭代时间、树的数量以及每棵树的深度等,而这些超参数的设置并不复杂,如此可以将节省机器学习工程师在特征工程中花费的时间和精力。根据又一方面的实施例,还提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行结合图2所描述的方法。根据再一方面的实施例,还提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现结合图2所描述的方法。本领域技术人员应该可以意识到,在上述一个或多个示例中,本发明所描述的功能可以用硬件、软件、固件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1