一种基于实用鲁棒PCA的图像表示方法与流程
本发明属于模式识别领域,具体涉及一种基于pca的图像表示方法。
背景技术:
实际情况中经常会遇到各种高维数据,例如图像和文本,如何有效地表示这类数据一直是模式分类中最重要的问题之一。特征提取(或降维)作为一种有用的数据分析工具,已被广泛用于解决这一问题。主成分分析(principalcomponentanalysis,pca)是最具代表性的技术之一,pca通过寻找最优投影向量,使其方差最大化或者重构误差最小化,进行特征提取和图像重建。
在计算机读取图像得到数据矩阵时,由于很多原因(比如原始图像存在光照、遮挡等因素或者硬件原因)导致野值或噪声的存在非常普遍,那么对于图像的特征提取或重建就会造成影响。传统pca技术在建模的过程中,由于在目标函数中使用平方l2范数距离度量,对异常值具有很强的敏感性,因此很容易放大离群点的影响,这可能使投影向量从期望的方向偏移,从而不能得到准确的低维图像表示。为了解决这一问题,研究者们已经开发了越来越多的用于提取特征的鲁棒pca技术,如低秩pca和l1-范数距离度量的相关pca方法。低秩pca用低秩结构重建图像数据,但是其面对高维图像处理的缺点是不能获得数据的低维表示,因此不适用于高维数据维数的缩减。而之前的研究工作显示,l1范数距离度量能够抑制异常值的影响,因此l1-范数距离度量比平方l2-范数距离度量更稳健。最近,有许多关于鲁棒特征提取技术的研究,它们以l1-范数作为技术模型中的距离度量,而l1-pca、pca-l1和r1-pca则是最具代表性的三种。其中,l1-pca通过最小化以l1范数为度量的图像像素矩阵的重构误差模型,得到鲁棒的投影向量。与l1-pca不同的是,pca-l1通过最大化图像像素投影矩阵方差来解决问题。在此基础上,kawk等人引入基于lp范数(p>0)的投影方差最大化,从而将pca-l1推广到pca-lp。显然,传统的pca和pca-l1都是pca-lp的特殊情况。此外,pca-l2,p也是最近提出的基于重构误差最小化的特征提取方法。
针对图像或者文本等高维数据,传统pca的模型优化目标是数据方差最大化或重构误差最小化问题,理论上显示,这两种形式在平方l2范数距离度量下是等价的,但是缺点是面对图像数据集中普遍存在的野值点或噪声,特征提取效果不好。虽然在鲁棒范数度量下,如l1范数提升了模型在处理野值点时的鲁棒性,但是其数据方差最小化和重构误差却无法保证等价,然而两者对特征有效提取都起着至关重要的作用。
技术实现要素:
发明目的:为了克服现存方法的不足,本发明提出了一种新的、更有效的基于鲁棒pca(prpca-practicalrobustprincipalcomponentanalysis,实用鲁棒pca)特征提取的图像表示方法,协同考虑了优化目标中的两种优化原则。
技术方案:本发明提供一种图像表示方法,包括以下步骤:
s1、读取图像数据集,根据像素值建立样本矩阵;
s2、将样本矩阵输入预先构建的目标模型,所述目标模型为基于鲁棒重建误差最小化和鲁棒数据差最大化的联合学习模型,其依据转换矩阵w将数据投影到低维子空间,并利用恢复矩阵w来恢复数据,并以l2,p范数作为距离度量;
s3、通过基于改进pca技术的迭代算法对目标模型进行求解,得到转换矩阵w;
s4、根据转换矩阵w完成图像重建。
进一步地,所述目标模型如下:
其中xi表示样本数据,w表示转换矩阵,u表示恢复矩阵,n为样本数目。
有益效果:
1、不同于现有的鲁棒pca方法,本发明的方法同时考虑到重构误差的最小化和数据方差的最大化,在统一的框架中充分利用它们在投影学习中的作用,得到更好的特征提取效果。
2、本发明的方法建立了原空间和转换空间特征的联系,即考虑投影后的重构误差,使之最小化,对于找到一个合适的投影空间具有重要的意义。
3、本发明利用l2,p范数距离度量,具有比l1范数更强的鲁棒性和灵活性。
4、针对构建的非凸问题,本发明设计了一种新的有效的迭代算法来求解该模型,算法具有良好的收敛性。
附图说明
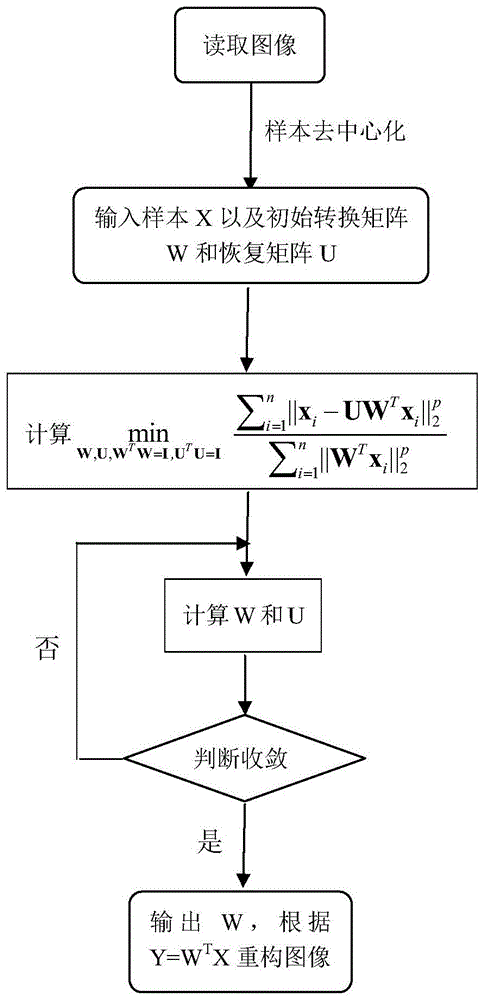
图1是本发明的基于实用鲁棒pca的图像表示方法流程图;
图2是本发明方法与其他方法在四个图像数据集上的识别率随维度尺寸的变化而变化的趋势图;
图3是本发明方法与其他方法的最小重建误差比较示意图;
图4是本发明方法在四个图像数据集上的收敛速度示意图。
具体实施方式
下面结合附图对本发明的技术方案作进一步说明。
本发明提出的图像表示方法,基于实用鲁棒pca(prpca)进行特征提取从而重建图像,在建立prpca模型时,主要目标是建立一个鲁棒重建误差最小化和鲁棒数据差最大化的联合学习模型,其寻找两个转换矩阵,一种是将数据投影到低维子空间,另一种是恢复数据,从而能够构造转换后的特征与原始特征之间的关系。此外,本发明以l2,p范数作为距离度量,因为l2,p范数距离度量削弱了对异常值的敏感性,可以很好地提高pca的鲁棒性。正是因为引入了l2,p范数,使得目标函数非凸,求解变得具有挑战性。为了解决这个难题,本发明设计了一种新的迭代算法去优化基于l2,p范数的极小化问题。理论分析和试验均表明该算法具有较好的收敛性。
如图1所示,基于实用鲁棒pca的图像表示方法包括以下步骤:
步骤s1,读取图像数据集,建立样本矩阵。
概括而言,本步骤首先读取一幅图像得到其初始像素值矩阵,然后转换成d×1的向量,记为xi,d是初始像素值矩阵中的元素个数,转换后表示维度;通过读取图像数据集中的多个图像则得到样本矩阵x=[x1,x2,...,xn]∈rd×n,r代表实空间。
具体地,本发明用matlab读取一张图像,则会得到图像的像素矩阵,其中矩阵元素值为0到255。以20×20的图像为例,为了计算方便,将20×20的矩阵从第二行开始每一行的元素都放在前一行的后面,这样就会得到一个400×1的向量,以此代表这幅图片。如一个数据集有500张图片,依次读取经过处理就会得到一个400×500的矩阵。
步骤s2,构建鲁棒重建误差最小化和鲁棒数据差最大化的联合学习模型,其目标函数如下:
该模型分子部分体现了最小化重构误差的思想,即原始样本xi与其转换到低维并恢复后的新样本的差,涉及两个转换矩阵w和u,转换矩阵w的作用是将数据投影到低维空间中,转换矩阵u的作用是恢复数据到原始维度,下文也称为恢复矩阵。分母部分体现了投影向量方差最大化思想。l2,p范数的引入旨在提升模型的鲁棒性。
步骤s3,将样本矩阵输入所构建的学习模型,通过以下迭代步骤进行求解。
s31、初始化:为u和w赋初值,设置初始迭代次数t=1;
本发明通过原始pca方法求解得到初始的u和w。这样选择的目的是考虑到其可能和最终得到的解比较接近,可以加快迭代速度。在原始pca计算时,转换矩阵w的维度是可选的,可以设置不同的维度跨度以进行性能分析。如针对400×500的样本矩阵,w的维度应低于400,假设为120,根据目标模型的分子部分可知uwtx和x的维度是一致的,因为它们能作差,则w的维度为400×120,此时u的维度为400×120。
s32、重复执行以下步骤不断更新u和w,直到收敛。
步骤a:计算第t次迭代的目标函数值
步骤b:计算矩阵
步骤c:计算矩阵
步骤b和c的目的是为了分别将分子和分母的l2,p范数转换成l2范数,方便计算;
步骤d:计算矩阵
这一步求解k,因为此时目标模型经过前两步的转换可以写为
步骤e:求解w(t+1)=(2xd(t)xt)-1(2xd(t)xtu(t)+α(t)k(t));
步骤e为求解w,通过对上式对w求导所得;求得w之后通过步骤f和g求得u。
步骤f:进行奇异值分解sλpt=xd(t)xtw(t+1),s和p分别表示左奇异矩阵和右奇异矩阵;
步骤g:求解u(t+1)=spt;
步骤h:设置t=t+1,返回步骤a;
当满足收敛条件时,输出:w=w(t+1)。
其中参数p的取值范围为0到2,(t)表示第t次迭代。当迭代过程收敛时,得到最终的w即是所求的解。本发明收敛条件为:当两次迭代的目标值的差小于指定阈值的时候就判断收敛;或者达到指定的迭代次数时停止迭代,输出w。以上的求解过程是基于训练样本的,用测试样本计算则可得到识别精度等实验结果。
步骤s4,根据求解得到的转换矩阵w进行图像重建。
得到w实际上图像的特征提取过程已经完成了,降维后的样本是y=wtx,在matlab中,对y加上去中心化的样本均值,并进行reshape操作得到图像,此时的图像是重建后的图像。
下面通过对四个图像数据库进行不同的实验,来评估本发明所提方法的有效性。四个图像数据库为人脸数据库cmupie和orl、对象数据库aloi和交通标志数据库gtsdb。采用四种方法与本方法进行比较,即pca、ripca、pca-lp和pca-l2p。随机选择每个数据库的每个类的k个图像作为训练集,其余的作为测试集。根据样本的大小,为每个数据集设置不同的k值,对于四个图像数据集则分别设为为k={5,7},k={9,12},k={3,5},k={15,20}。此外,为了方便实验,将p值分别设为0.5和1。在做不同维度的相关分析时,设置范围为5到120,步长为5的维度变化区间。
表1显示了五种方法分别在四个图像数据集上的识别精度,图2显示了识别率随维度尺寸的变化而变化的趋势。从表1和图2中可以看出,本发明方法prpca的识别精度要明显优于其他方法。其次,prpca和pca-l2p采用l2,p范数距离度量,比传统的pca具有更好的识别率,这证明了l2,p范数距离度量在抑制异常值负效应方面的有效性。
表1:五种方法在四个图像数据集上的识别精度
为了评价prpca的有效性,本发明将其重建误差与其他方法的重建误差进行了比较。图3给出了pca、ripca、pca-lp、pca-l2p和prpca的最小重建误差。表2显示了在数据集aloi(5)上每种方法的最小重建误差与维数的关系。如图3所示,prpca在重建误差方面明显优于pca、ripca、pca-lp和pca-l2p。此外,它的优越性在每个维度都是非常明显的。并且与p=1相比,在大多数情况下,当p=0.5时,每种方法的重建误差都较低,说明当p取较小的值时有利于提高鲁棒性。
表2:五种方法在数据集aloi(5)上的最小重建误差与维数
最后图4示出了本发明方法在四个图像数据集上的收敛速度示意图,从图中可以看出,不管在哪一类图像上,本发明的方法均只需10次左右的迭代就能达到收敛,速度表现优异。本发明在精度和速度上所展现的优势,对于高维数据的高效特征提取具有重要指导意义。
- 还没有人留言评论。精彩留言会获得点赞!