一种基于分割的多尺度特征金字塔文本检测方法与流程
本发明属于图像文本分析领域,特别涉及一种基于分割的多尺度特征金字塔文本检测方法。
背景技术:
随着计算机视觉技术的发展,图像理解技术的应用越来越广泛。文本作为图像中重要的组成部分,蕴含了丰富的语义信息,是图像理解的关键,准确进行文本检测则是图像中提取关键信息的第一步。自然场景图像的文本检测由于背景的多样性,大小、方向的不确定性,面临着诸多挑战:(1)文本格式的多样性,以及文本行排列的多样性;(2)文本方向多样性(3)文本大小尺寸多样性(4)文本背景多样性。
目前利用深度学习进行文本框检测的方法主要有两种:
(1)利用基于anchor的目标检测框架(fasterr-cnn,ssd,yolo等),将文本视为一种特殊的物体目标进行检测定位;
(2)基于像素分割的思想,使用全卷积网络模型(fcn),maskr-cnn等,将文本检测任务转化为分割任务,通过预测像素得到检测结果。
其中,基于anchor的方法由于场景文本尺寸大小的多样性,不同于通用物体固定的长宽比,使得网络对于文本的尺寸不敏感,准确率较低;另外现有的基于anchor的文本检测大多是基于四边形或旋转矩形,针对任意形状的文本则不能进行很好的定位。基于像素分割的方法则容易受到感受野的限制,对小目标检测效果不好,并且对于一些比较接近的文本实例,不能很好地区分边界。
技术实现要素:
为了克服现有技术在自然场景下文本检测方法的不足,本发明利用深度网络模型的特征学习能力和分类性能,结合像素分割的思想,提出一种基于分割的多尺度特征金字塔文本检测方法。
本发明目的通过以下技术方案实现:
一种基于分割的多尺度特征金字塔文本检测方法,包括如下:
获取数据;
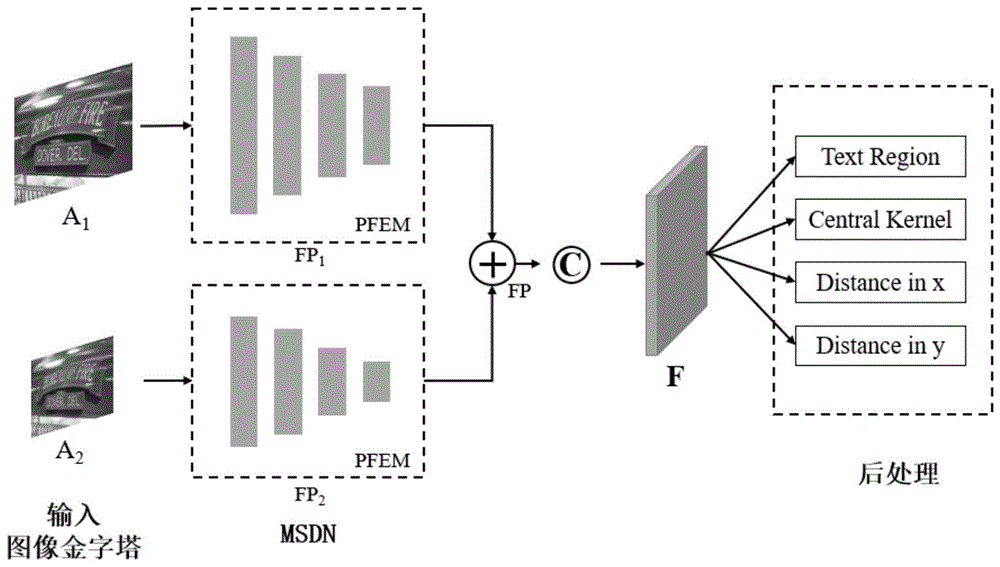
构建金字塔特征提取模型,从获取数据中提取特征;
对输入数据进行采样,得到不同尺度的输入图像,然后分别输入金字塔特征提取模型,提取文本特征,再通过多尺度检测网络对不同尺度输入图像的文本特征进行融合,处理后得到特征图,并进行预测;
对预测的结果进行处理,得到文本区域的轮廓边界线。
所述数据为文本检测数据集。
所述构建金字塔特征提取模型,从获取数据中提取特征,具体为:
输入图像经过backbone的数层卷积操作提取特征,得到特征金字塔;
特征金字塔依次通过自顶向下和自底向上两条路径,将回向传递的高层语义信息和经过数层卷积操作被丢失的低层位置信息进行融合,对文本特征进行增强,得到这一阶段的最后特征。
所述特征金字塔依次通过自顶向下和自底向上两条路径,将回向传递的高层语义信息和经过数层卷积操作被丢失的低层位置信息进行融合,对文本特征进行增强,得到这一阶段的最后特征,具体为:
在自顶向下路径中,首先对高层级的特征进行上采样,再通过横向连接获取同级的特征信息,最后进行融合,融合后的特征依次经过一个3*3的卷积核以及一个1*1的卷积核,得到原图大小1/4,1/8,1/16,1/32的特征图。
在自底向上路径中,首先对同一层级的特征即自顶向下路径增强生成进行上采样扩张,然后与低层级的特征进行像素相加,更好地保留低层位置信息,融合后的特征先后通过一个步长为2的3*3卷积核和一个1*1卷积核,进行卷积操作,得到这一阶段的最后特征。
金字塔特征提取模型通过具有横向连接的自顶向下路径,将高层的强语义特征回向传递,利用高层语义信息对文本特征进行补充增强;再通过自底向上的通道,将backbone中由于经过数十层卷积操作丢失比较厉害的低层强定位特征直接向上传递,提供文本的位置信息特征。通过对不同层次的多级信息进行融合,使得文本像素与边缘之间建立较强的关系,增强整个特征层次,提高网络的定位性能。
所述将不同尺度的图像分别输入金字塔特征提取模型,提取文本特征,再通过多尺度检测网络对不同尺度输入图像的文本特征进行融合,处理后得到特征图,并进行预测,具体为:
对输入图像进行下采样,得到不同尺度的输入图像a1,a2;
将不同尺度的输入图像a1,a2分别输入金字塔特征提取模型,提取到不同的特征fp1,fp2;
对较小尺度输入图像得到的特征金字塔fp2中每一层级的特征分别进行上采样扩张,然后将特征金字塔fp1,fp2中同一层级的特征连接起来,作为特征金字塔fp中同一层级的输出特征,通过多尺度检测网络对不同尺度输入图像的特征进行融合,将融合的特征进行处理得到特征图,并进行预测。
所述将融合的特征进行处理得到特征图,并进行预测,具体为:
将特征金字塔fp中每一层级的特征分别进行上采样得到四层同样大小的特征图,然后将这四层特征图拼接起来,再通过一个3*3的卷积和1*1的卷积消除上采样的混叠效应并改变通道数,最后得到一个维度为10的特征图f,用来预测文本区域、文本中心核和x、y距离,其中文本区域保持文本实例的完整形状;文本中心核则是文本区域中面积较小的文本骨架,能够较为清晰地分离相近的文本实例;x、y距离指文本区域内的文本像素点分别在x、y方向上和文本中心核的距离。
所述对预测的结果进行处理,得到文本区域的轮廓边界线,具体为:
以文本中心核为聚类中心,文本区域中的文本像素点为初始的集合;
对于每一个文本像素点,通过对它在x、y方向上和文本中心核的距离进行判断,若小于阈值,则认为此文本像素点属于当前文本实例;反之,则不属于;
对于文本区域中的所有文本像素点,重复上一个步骤,最后得到属于当前文本实例的文本像素点集;
利用alpha-shape算法从文本像素点集中提取文本区域的轮廓边界线。
本发明中,网络训练损失函数定义为:
l=lcls+αlker+βlreg
其中,α=0.5,β=0.25,lcls和lker分别是预测文本区域和文本中心核的分类损失;lreg是预测x、y距离的回归损失。
所述文本区域和文本中心核的预测实际上是像素级文本/非文本的二分类任务,采用diceloss来监督文本区域和文本中心核的预测结果:
其中,gcls、pcls和gker、pker分别是文本区域和文本中心核的ground-truth和预测结果;
预测文本像素点分别在x、y方向上和文本中心核的距离是一个回归问题,采用smoothl1损失函数进行计算:
其中,xk、
本发明有益效果:
本发明使用多尺度特征金字塔网络提取多尺度文本特征并进行融合,使得网络具有更大的感受野,能够更好地检测图像中的文本区域,并对相近的文本实例进行准确分割,具有更强的鲁棒性。与传统基于anchor回归的文本框检测方法相比,本发明不需要根据anchor设置提前生成候选文本框,减少了计算开销;而且针对任意形状的文本有更好的检测性能,具有较高的准确率,召回率和f值。
附图说明
图1是本发明的整体结构示意图;
图2是本发明的金字塔特征提取模型的结构示意图;
图3(a)及图3(b)是本发明的金字塔特征提取模型两条路径的连接方式示意图;
图4是本发明中多尺度检测网络融合的结构示意图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
一种基于分割的多尺度特征金字塔文本检测方法,网络整个框架如图1所示,主要包括如下步骤:
s1数据获取;本实施例采用icdar2015,ctw1500,rctw17等被学术界广泛使用的公开文本检测数据集进行训练测试。其中icdar2015数据集包含训练数据1000张,测试数据500张;ctw1500数据集包含训练数据1000张,测试数据500张;rctw17数据集包含训练数据8034张,测试数据4229张。
s2构建金字塔特征提取模型(pefm),网络结构如图2所示,从获取数据中提取特征,具体包括如下步骤:
s2.1输入图像经过backbone的数层卷积操作提取特征,得到特征金字塔;
本实施例中backbone采用resnet,网络层数在几十到一百多。输入图像经过逐层卷积操作提取特征,构造特征金字塔,其中深层特征主要反映物体类别等语义信息,低层特征主要反映边缘形状等位置信息。
s2.2特征金字塔通过自顶向下(top-down)和自底向上(bottom-up)两条路径,将回向传递的高层语义信息和经过数层卷积操作被丢失的低层位置信息进行融合,对文本特征进行增强;
在自顶向下(top-down)路径中,如图3(a)所示,首先对高层级的特征进行上采样,再通过横向连接获取同级的特征信息,最后进行融合。经过融合的特征先经过一个3*3的卷积核,目的是消除上采样的混叠效应;再通过一个1*1的卷积核,对特征图进行降维,减少通道数。在这一阶段,每一层级的特征图大小分别是原图大小的1/4,1/8,1/16,1/32。
在自底向上(bottom-up)路径中,如图3(b)所示,首先对同一层级的特征进行上采样扩张,然后与低层级的特征进行像素相加,更好地保留低层位置信息。融合后的特征先后通过一个步长为2(减小特征图尺寸)的3*3卷积核和一个1*1卷积核,进行卷积操作。这一阶段输出的特征金字塔即是金字塔特征提取模型(pfem)的最终输出结果。
金字塔特征提取模型(pfem)通过具有横向连接的自顶向下(top-down)路径,将高层的强语义特征回向传递,利用高层语义信息对文本特征进行补充增强;再通过自底向上(bottom-up)的通道,将backbone中由于经过数十层卷积操作丢失比较厉害的低层强定位特征直接向上传递,提供文本的位置信息特征。通过对不同层次的多级信息进行融合,使得文本像素与边缘之间建立较强的关系,增强整个特征层次,提高网络的定位性能。
具体的:高层级和同级都是相对融合标志(也就是图2示中的圆形加号)而言,例如第三级和第四级特征信息融合时,高层级就是从上边传递下来的第四级特征信息,同层级就是从左边传递过来的第三级特征信息,之所以称之为同层级,是因为这一步融合之后得到的特征信息也属于第三级。
本实施例中的融合就是指像素相加,自底向上路径中也有对特征信息进行融合,这里同层级的特征信息就是自顶向下路径中生成的,具体在图2中可以表示。
s2.3输出这一阶段最后的特征金字塔。
s3对输入数据进行采样,得到两张大小不同的图片,然后将两张大小不同的图片分别输入金字塔特征提取模型,提取文本特征,再通过多尺度检测网络对这两张图片的文本特征进行融合,处理后得到特征图,并进行预测;多尺度检测网络具体如图4所示,2x表示对特征进行2倍上采样,
s3.1对输入图像a进行下采样,得到不同尺度的输入图像a1,a2,构建图像金字塔;
s3.2图像金字塔中不同尺度的图像a1,a2分别输入相同结构的网络模型(金字塔特征提取模型pfem),因为输入图像大小的差异,以及网络自身的设计,会提取到不同的特征金字塔fp1,fp2;
s3.3通过多尺度检测网络(msdn)对上一步骤中生成的特征金字塔fp1,fp2进行融合,得到最终的特征金字塔fp;
具体为:首先对较小尺度输入图像得到的特征金字塔fp2中每一层级的特征分别进行上采样扩张,然后将特征金字塔fp1,fp2中同一层级的特征连接起来,作为特征金字塔fp中同一层级的输出特征。通过多尺度检测网络(msdn)对不同尺度输入图像的特征进行融合,能够增大网络的感受野,更好地结合全局和局部信息,从而得到信息更加丰富的特征图。
s3.4特征金字塔fp通过上采样、连接等操作,得到特征图f,用来预测文本区域、文本中心核和x、y距离
具体为:将特征金字塔fp中每一层级的特征分别进行上采样得到四层同样大小的特征图,然后将这四层特征图拼接起来,再通过一个3*3的卷积和1*1的卷积消除上采样的混叠效应并改变通道数,最后得到一个维度为10的特征图f,用来预测文本区域、文本中心核和x、y距离。其中文本区域保持了文本实例的完整形状;文本中心核则是文本区域中面积较小的文本骨架,能够较为清晰地分离相近的文本实例;x、y距离指文本区域内的文本像素点分别在x、y方向上和文本中心核的距离。
在特征融合阶段,采用分离卷积(3*3卷积和1*1卷积),而不是常规卷积(k*k*channel)去处理特征,可以减少训练过程中的参数数量,以较小的计算开销扩大网络感受野,增强特征。
s4对预测的结果进行处理,得到文本区域的轮廓边界线,具体为:
s4.1以文本中心核为聚类中心,文本区域中的文本像素点为初始的集合;
s4.2对于每一个文本像素点,通过对它在x、y方向上和文本中心核的距离进行判断,若小于阈值,则认为此文本像素点属于当前文本实例;反之,则不属于;
s4.3对于文本区域中的所有文本像素点,重复步骤s4.2,最后得到属于当前文本实例的文本像素点集;
s4.4利用alpha-shape算法从一堆无序的点集中提取文本区域的轮廓边界线。
本检测方法的网络训练损失函数定义为:
l=lcls+αlker+βlreg
其中,α=0.5,β=0.25。lcls和lker分别是预测文本区域和文本中心核的分类损失;lreg是预测x、y距离的回归损失。
文本区域和文本中心核的预测实际上是像素级文本/非文本的二分类任务,采用diceloss来监督文本区域和文本中心核的预测结果:
其中,gcls、pcls和gker、pker分别是文本区域和文本中心核的ground-truth和预测结果。
预测文本像素点分别在x、y方向上和文本中心核的距离是一个回归问题,采用smoothl1损失函数进行计算:
其中,xk、
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其它的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!