计算装置以及计算方法与流程
本申请属于神经网络运算领域,尤其涉及一种计算装置以及计算方法。
背景技术:
数据处理是大部分算法需要经过的步骤或阶段,在计算机引入数据处理领域后,越来越多的数据处理通过计算机来实现,现有的算法中有计算设备在进行神经网络的数据计算时速度慢,效率低。
申请内容
有鉴于此,本申请提供一种计算装置以及计算方法,能够提高计算速度,并且运算性能高效。
本申请提供一种计算装置,所述计算装置包括:存储器、寄存器单元、互联模块、粗粒度选数单元,运算单元、控制单元和数据访问单元;其中,
寄存器单元,用于存储运算指令、数据块的在存储介质的地址,运算指令对应的计算拓扑结构;
控制单元,用于从寄存器单元内提取运算指令,该运算指令对应的操作域以及该运算指令对应的第一计算拓扑结构,将该运算指令译码成执行指令,该执行指令用于控制运算单元执行运算操作,将该操作域传输至数据访问单元;
数据访问单元,用于提取该操作域对应的数据块,并将该数据块通过粗粒度选数单元传输至互联模块;
粗粒度选数单元,用于接收输入神经元和非零权值位置信息,使用滑动窗口选取神经网络的一组权值,将选取的权值都置为零,并选取出非零权值对应的神经元;
互联模块、用于输入被选择的神经元和非零权值,将输入被选择的神经元和非零权值发送至运算单元;
运算单元,用于接收输入被选择的神经元和非零权值,通过乘加运算单元完成神经网络运算并将输出神经元传输给存储器。
附图说明
图1-1是本申请实施例提供的计算装置的另一种结构示意图。
图1-2是本申请实施例提供的卷积计算指令的流程示意图。
图2-1是本公开实施例的处理方法的流程图。
图2-2是本公开实施例的处理方法的另一流程图。
图2-3是本公开实施例神经网络的全连接层的剪枝方法。
图2-4是本公开实施例神经网络的卷积层粗粒度剪枝方法。
图2-5是本公开实施例的处理装置的结构示意图。
图2-6是本公开实施例的加速装置的结构示意图。
图2-7是本公开实施例的另一种加速装置的结构示意图。
图2-8是本公开以处理方法的一具体实施例。
具体实施方式
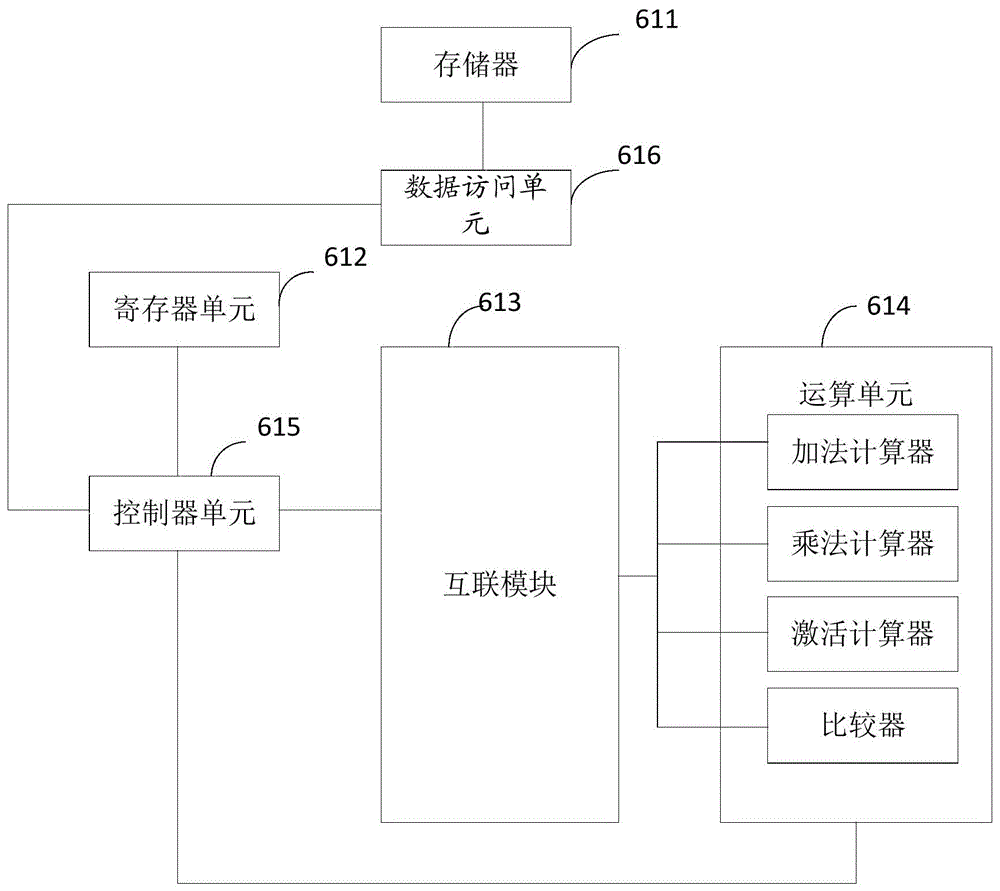
参阅图1-1,图1-1提供了一种计算装置,该计算装置包括:存储器611(可选的)、寄存器单元612、互联模块613、运算单元614、控制单元615和数据访问单元616;
其中,运算单元614包括:加法计算器、乘法计算器、比较器、激活运算器中至少二种。
互联模块613,用于控制运算单元614中计算器的连接关系使得该至少二种计算器组成不同的计算拓扑结构。
指令存储单元(可以是寄存器单元,指令缓存,高速暂存存储器)612,用于存储该运算指令、数据块的在存储介质的地址、运算指令对应的计算拓扑结构。
该运算指令可以包括:操作域以及操作码,以卷积计算指令为例,如下表所示,其中,寄存器0、寄存器1、寄存器堆2、寄存器3、寄存器4可以为操作域。其中,每个寄存器0、寄存器1、寄存器2、寄存器3、寄存器4可以是一个或者多个寄存器。
存储器611可以为片外存储器,当然在实际应用中,参见图1-1,当为片内存储器时,该片内存储器可以为缓存,具体的,可以为高速暂存缓存,用于存储数据块,该数据块具体可以为n维数据,n为大于等于1的整数,例如,n=1时,为1维数据,即向量,如n=2时,为2维数据,即矩阵,如n=3或3以上时,为多维数据。
控制单元615,用于从寄存器单元612内提取运算指令、该运算指令对应的操作域以及该运算指令对应的第一计算拓扑结构,将该运算指令译码成执行指令,该执行指令用于控制运算单元执行运算操作,将该操作域传输至数据访问单元616,。
数据访问单元616,用于从存储器611中提取该操作域对应的数据块,并将该数据块传输至互联模块613。
互联模块613、用于接收数据块,将该数据块发送至运算单元614。
运算单元614,用于该执行指令调用运算单元614的计算器对该数据块执行运算操作得到运算结果,将该运算结果传输至数据访问单元存储在存储器内。一个实施例里,运算单元614,用于按第一计算拓扑结构以及该执行指令调用计算器对数据块执行运算操作得到运算结果,将该运算结果传输至数据访问单元存储在存储器内。
在一种可选的实施例中,上述第一计算拓扑结构可以为:乘法运算器-加法运算器-加法运算器-激活运算器。
下面通过不同的运算指令来说明如图1-1所示的计算装置的具体计算方法,这里的运算指令以卷积计算指令为例,该卷积计算指令可以应用在神经网络中,所以该卷积计算指令也可以称为卷积神经网络。对于卷积计算指令来说,其实际需要执行的公式可以为:s=s(∑wxi+b),其中,即将卷积核w乘以输入数据xi,进行求和,然后加上偏置b后做激活运算,得到最终的输出结果s。依据该公式即可以得到该计算拓扑结构为,乘法运算器-加法运算器-(可选的)激活运算器。
上述运算指令可以包括指令集,该指令集包括:卷积神经网络指令,有不同功能的卷积神经网络compute指令以及config指令、io指令、nop指令、jump指令和move指令。在一种实施例中,compute指令包括:
卷积神经网络指令,根据该指令,装置分别从存储器(优选的高速暂存存储器或者标量寄存器堆)的指定地址取出指定大小的输入数据和卷积核,在卷积运算部件中做卷积运算直接得到输出结果。即该指令不执行后续的操作,直接做卷积运算得到输出结果。
卷积神经网络sigmoid指令,根据该指令,装置分别从存储器(优选的高速暂存存储器或者标量寄存器堆)的指定地址取出指定大小的输入数据和卷积核,在卷积运算部件中做卷积操作,优选的,然后将输出结果做sigmoid激活;
卷积神经网络tanh指令,根据该指令,装置分别从存储器(优选的高速暂存存储器)的指定地址取出指定大小的输入数据和卷积核,在卷积运算部件中做卷积操作,优选的,然后将输出结果做tanh激活;
卷积神经网络relu指令,根据该指令,装置分别从存储器(优选的高速暂存存储器)的指定地址取出指定大小的输入数据和卷积核,在卷积运算部件中做卷积操作,优选的,然后将输出结果做relu激活;以及
卷积神经网络group指令,根据该指令,装置分别从存储器(优选的高速暂存存储器)的指定地址取出指定大小的输入数据和卷积核,划分group之后,在卷积运算部件中做卷积操作,优选的,然后将输出结果做激活。
config指令在每层人工神经网络计算开始前配置当前层计算需要的各种常数。
io指令实现从外部存储空间读入计算需要的输入数据以及在计算完成后将数据存回至外部空间。
nop指令负责清空当前装置内部所有控制信号缓存队列中的控制信号,保证nop指令之前的所有指令全部指令完毕。nop指令本身不包含任何计算操作;
jump指令负责控制将要从指令存储单元读取的下一条指令地址的跳转,用来实现控制流的跳转;
move指令负责将装置内部地址空间某一地址的数据搬运至装置内部地址空间的另一地址,该过程独立于运算单元,在执行过程中不占用运算单元的资源。
如图1-1所示的计算装置执行卷积计算指令的方法具体可以为:
控制单元615从寄存器单元612内提取卷积计算指令、卷积计算指令对应的操作域,控制单元将该操作域传输至数据访问单元。
数据访问单元从存储器内提取该操作域对应的卷积核w和偏置b(当b为0时,不需要提取偏置b),将卷积核w和偏置b传输至运算单元。
运算单元的乘法运算器将卷积核w与输入数据xi执行乘法运算以后得到第一结果,将第一结果输入到加法运算器执行加法运算得到第二结果,将第二结果和偏置b执行加法运算得到第三结果,将第三结果输到激活运算器执行激活运算得到输出结果s,将输出结果s传输至数据访问单元存储至存储器内。其中,每个步骤后都可以直接输出结果传输到数据访问存储至存储器内。另外,将第二结果和偏置b执行加法运算得到第三结果这一步骤为可选步骤,即当b为0时,不需要这个步骤。
本申请提供的技术方案通过一个指令即卷积计算指令即实现了卷积的计算,在卷积计算的中间数据(例如第一结果、第二结果、第三结果)均无需存储或提取,减少了中间数据的存储以及提取操作,所以其具有减少对应的操作步骤,提高卷积的计算效果的优点。
图1-2是本申请实施例提供的卷积神经网络运算装置执行卷积神经网络的流程图,如图1-2所示,执行卷积神经网络指令的过程包括:
在步骤s6b1,在指令存储单元的首地址处预先存入一条io指令。
在步骤s6b2,控制器单元从指令存储单元的首地址读取该条io指令,根据译出的控制信号,数据访问单元从存储器读取相应的所有卷积神经网络运算指令,并将其缓存在指令存储单元中。
在步骤s6b3,控制器单元接着从指令存储单元读入下一条io指令,根据译出的控制信号,数据访问单元从存储器读取运算单元需要的所有数据块(例如,包括输入数据、用于作快速的激活函数运算的插值表、用于配置运算器件参数的常数表、偏置数据等)。
在步骤s6b4,控制器单元接着从指令存储单元读入下一条config指令,根据译出的控制信号,装置配置该层神经网络计算需要的各种常数。例如,运算单元根据控制信号里的参数配置单元内部寄存器的值,所述参数包括例如激活函数需要的数据。
在步骤s6b5,控制器单元接着从指令存储单元读入下一条compute指令,根据译出的控制信号,互连模块将卷积窗口内的输入数据发给计算单元内的各计算器。
在步骤s6b6,根据compute指令译出的控制信号,互联模块将乘法计算器、加法计算器和激活计算器连接形成第一计算拓扑结构。
在步骤s6b7,乘法运算器将卷积核w与输入数据xi执行乘法运算以后得到第一结果,将第一结果输入到加法运算器执行加法运算得到第二结果,将第二结果和偏置b执行加法运算得到第三结果,将第三结果输入到激活运算器执行激活运算得到输出结果s,将输出结果s传输至数据访问单元存储至存储介质内。其中,将第二结果和偏置b执行加法运算得到第三结果这一步骤可选,即当b为0时,不需要这个步骤。
图2-1是本公开实施例的处理方法的流程图。在本公开一些实施例中,提供了一种处理方法,用于机器学习的稀疏化,例如神经网络的稀疏化,如图2-1所示,处理方法在如图1-1所示的计算装置中实现,包括:
s101:使用滑动窗口从神经网络选取出一组权值,将选取的权值都置为零;
s102:对神经网络进行训练,训练过程中已经被置为零的权值保持为零。
步骤s101实际为对神经网路进行剪枝的过程;步骤s1022中是将剪枝后的神经网络使用反向传播算法(backpropagation)进行重新训练,训练过程中已经被置为0的权值将一直保持0。
其中,选取神经网络的一组权值的方法可以有以下几种,组内所有权值绝对值的算术平均值小于第一阈值;或者组内所有权值绝对值的几何平均值小于第二阈值;或者组内所有权值绝对值的最大值小于第三阈值。上述第一阈值、第二阈值和第三阈值中各自的选择可以本领域技术人员可以根据情况进行预先设定,本公开并不以此为限。
图2-2是本公开实施例的处理方法的另一流程图。除包括与步骤s1和s2对于的步骤s201和s202外,还可以包括步骤s203:不断重复s201和s2022直至在保证精度不损失x%的前提下没有权值能被置为0,x为大于0小于100的数,x根据不同的神经网络以及不同的应用可以有不同的选择。在一个实施例里,x的值为0-5。
本公开实施例中,对神经网络进行剪枝可包括:对神经网络的全连接层、卷积层或lstm层的权值进行剪枝。
图2-3是本公开实施例神经网络的全连接层的剪枝方法。如图2-3所示,神经网络的全连接层可以看成是一个二维矩阵(nin,nout),其中nin表示输入神经元的个数,nout表示输出神经元的个数,共有nin*nout个权值。在粗粒度剪枝时,我们先设定一个大小为bin*bout的滑动窗口,其中bin为大于等于1小于等于nin正整数,bout为大于等于1小于等于nout的正整数。滑动窗口可以沿着bin的方向按照sin的步长(stride)进行滑动,也可以沿着bout方向按照sout的步长进行滑动,其中sin为大于等于1小于等于bin的正整数,sout为大于等于1小于等于bout的正整数。当滑动窗口内的一组权值被选取时,这组权值将全部被置为0,即bin*bout个权值将同时置为0。
图2-4是本公开实施例神经网络的卷积层粗粒度剪枝方法。如图2-4所示,神经网络的卷积层可以看成是一个四维矩阵(nfin,nfout,kx,ky),其中nfin表示输入特征图像(featuremap)数量,nout表示输出特征图像数量,(kx,ky)表示卷积核(kernel)的大小。在粗粒度剪枝时,我们先设定一个大小为bfin*bfout*bx*by的滑动窗口,其中bfin为大于等于1小于等于nfin的正整数,bfout为大于等于1小于等于nfout的正整数,bx为大于等于1小于等于kx的正整数,by为大于等于1小于等于ky的正整数。滑动窗口可以沿着bfin的方向按照sfin的步长(stride)进行滑动,或者沿着bfout方向按照sfout的步长进行滑动,或者沿着bx方向按照sx的步长进行滑动,或沿着by方向按照sy的步长进行滑动,其中sfin为大于等于1小于等于bfin的正整数,sfout为大于等于1小于等于bfout的正整数,sx为大于等于1小于等于bx的正整数,sy为大于等于1小于等于by的正整数。当某个滑动窗口内的一组权值被选取时,这组权值将全部被置为0,即bfin*bfout*bx*by个权值将同时置为0。
lstm层的权值由多个全连接层权值组成,假设lstm层的权值由m个全连接层权值组成,其中m为大于0的正整数。第i个全连接层权值为(nin_i,nout_i,),其中i是大于0小于等于m的正整数,nin_i表示第i个全连接层权值输入神经元个数,nout_i表示第i个全连接层权值输出神经元个数,在粗粒度剪枝时,对于第i个全连接层,我们先设定一个大小为bin_i*bout_i的滑动窗口,其中bin_i为大于等于1小于等于nin_i的正整数,bout_i为大于等于1小于等于nout_i的正整数。滑动窗口可以沿着bin_i的方向按照sin_i的步长进行滑动,也可以沿着bout_i方向按照sout_i的步长进行滑动,其中sin_i为大于等于1小于等于bin_i的正整数,sout_i为大于等于1小于等于bout_i的正整数。当滑动窗口内的一组权值被选取时,这组权值将全部被置为0,即bin_i*bout_i个权值将同时置为0。
本申请实施例还提供一种处理装置,在一种可选实施例中,该处理装置可以为图1-1所示的计算装置,需要说明的是,上述如图1-1所示的计算装置可以添加粗粒度剪枝单元和神经网络训练单元,在实际应用中,上述如图1-1所示的计算装置也可以添加或扩展如图2-5所示的处理装置的模块或单元。在另一种可选实施例中,该处理装置如图2-5所示,用于对神经网络进行。
粗粒度剪枝包括存储器:用于存储可执行指令;包括存储器:用于存储可执行指令;减少运算时间。
粗粒度剪枝单元:用于对神经网络进行剪枝,包括使用滑动窗口从神经网络选取出一组权值,将选取的权值都置为零;
神经网络训练单元:用于将剪枝后的神经网络进行训练:训练过程中已经被置为零的权值保持为零。
训练单元集成了神经网络反向训练算法,接收粗粒度剪枝后的神经网络,采用反向训练算法进行训练,在训练过程中被剪枝的权值始终保持为0。训练单元将训练后的神经网络或者传输给粗粒度剪枝单元进行进一步剪枝操作,或者直接输出。
进一步的,粗粒度剪枝单元还包括全连接层粗粒度剪枝单元,实现对神经网络的全连接层进行粗粒度剪枝操作。
进一步的,粗粒度剪枝单元还包括卷积层粗粒度剪枝单元,实现对神经网络的卷积层进行粗粒度剪枝操作。
进一步的,粗粒度剪枝单元还包括lstm层粗粒度剪枝单元,实现对神经网络的lstm层进行粗粒度剪枝操作。
本公开提供了一处理装置,该加速装置可以添加在如图1-1所示计算装置内。图2-6是本公开实施例的处理装置的结构示意图。如图2-6所示的处理装置,能够处理粗粒度稀疏后的神经网络,充分挖掘粗粒度稀疏的特性,减少访存同时减少运算量,从而减少运算时间并降低能耗。
处理装置包括存储单元,指令控制单元,粗粒度选数单元和运算单元。处理装置可以是用于神经网络处理。
存储单元可用来存储神经网络的神经元,权值以及指令。
指令控制单元用于接收存储部分中的指令,经过译码后生成控制信息控制粗粒度选数单元进行选数操作和运算单元进行计算操作
综上所述,本申请中的运算单元,可以用于执行神经网络专用指令。本申请中的神经网络专用指令,包括但不限于所有专用于完成人工神经网络运算的指令。神经网络专用指令包括但不限于控制指令,数据传输指令,运算指令和逻辑指令。其中控制指令控制神经网络执行过程。数据传输指令完成不同存储介质之间的数据传输,数据格式包括但不仅限于矩阵,向量和标量。运算指令完成神经网络的算术运算,包括但不仅限于矩阵运算指令,向量运算指令,标量运算指令,卷积神经网络运算指令,全连接神经网络运算指令,池化神经网络运算指令,rbm神经网络运算指令,lrn神经网络运算指令,lcn神经网络运算指令,lstm神经网络运算指令,rnn神经网络运算指令,relu神经网络运算指令,prelu神经网络运算指令,sigmoid神经网络运算指令,tanh神经网络运算指令,maxout神经网络运算指令。逻辑指令完成神经网络的逻辑运算,包括但不仅限于向量逻辑运算指令和标量逻辑运算指令。
其中,rbm神经网络运算指令用于实现restrictedboltzmannmachine(rbm)神经网络运算。
其中,lrn神经网络运算指令用于实现localresponsenormalization(lrn)神经网络运算。
其中,lstm神经网络运算指令用于实现longshort-termmemory(lstm)神经网络运算。
其中,rnn神经网络运算指令用于实现recurrentneuralnetworks(rnn)神经网络运算。
其中,relu神经网络运算指令用于实现rectifiedlinearunit(relu)神经网络运算。
神经网络运算指令用于实现s型生长曲线(sigmoid)神经网络运算。y=sigmoid(x)=1/1+e-x,其中x,y是实数。
其中,tanh神经网络运算指令用于实现双曲正切函数(tanh)神经网络运算。
其中,maxout神经网络运算指令用于实现(maxout)神经网络运算使用maxout激活函数输出一个节点的表达式为maxouti(x)=maxj∈[1,k](xtw…ij+bij)
其中,w为权重,b为偏置。
更具体的,它包括cambricon指令集。
所述cambricon指令集的特征在于,指令集中每一条指令长度为设定长度(例如64bit或128bit),指令由操作码和操作数组成。指令集包含四种类型的指令,分别是控制指令(controlinstructions),数据传输指令(datatransferinstructions),运算指令(computationalinstructions),逻辑指令(logicalinstructions)。
进一步的,控制指令用于控制执行过程。控制指令包括跳转(jump)指令和条件分支(conditionalbranch)指令。
进一步的,数据传输指令用于完成不同存储介质之间的数据传输。数据传输指令包括加载(load)指令,存储(store)指令,搬运(move)指令。load指令用于将数据从主存加载到缓存,store指令用于将数据从缓存存储到主存,move指令用于在缓存与缓存或者缓存与寄存器或者寄存器与寄存器之间搬运数据。数据传输指令支持三种不同的数据组织方式,包括矩阵,向量和标量。
进一步的,运算指令用于完成神经网络算术运算。运算指令包括矩阵运算指令,向量运算指令和标量运算指令。
更进一步的,矩阵运算指令完成神经网络中的矩阵运算,包括矩阵乘向量(matrixmultiplyvector),向量乘矩阵(vectormultiplymatrix),矩阵乘标量(matrixmultiplyscalar),外积(outerproduct),矩阵加矩阵(matrixaddmatrix),矩阵减矩阵(matrixsubtractmatrix)。
更进一步的,向量运算指令完成神经网络中的向量运算,包括向量基本运算(vectorelementaryarithmetics),向量超越函数运算(vectortranscendentalfunctions),内积(dotproduct),向量随机生成(randomvectorgenerator),向量中最大/最小值(maximum/minimumofavector)。其中向量基本运算包括向量加,减,乘,除(add,subtract,multiply,divide),向量超越函数是指那些不满足任何以多项式作系数的多项式方程的函数,包括但不仅限于指数函数,对数函数,三角函数,反三角函数。
更进一步的,标量运算指令完成神经网络中的标量运算,包括标量基本运算(scalarelementaryarithmetics)和标量超越函数运算(scalartranscendentalfunctions)。其中标量基本运算包括标量加,减,乘,除(add,subtract,multiply,divide),标量超越函数是指那些不满足任何以多项式作系数的多项式方程的函数,包括但不仅限于指数函数,对数函数,三角函数,反三角函数。
进一步的,逻辑指令用于神经网络的逻辑运算。逻辑运算包括向量逻辑运算指令和标量逻辑运算指令。
更进一步的,向量逻辑运算指令包括向量比较(vectorcompare),向量逻辑运算(vectorlogicaloperations)和向量大于合并(vectorgreaterthanmerge)。其中向量比较包括但大于,小于,等于,大于等于,小于等于和不等于。向量逻辑运算包括与,或,非。
更进一步的,标量逻辑运算包括标量比较(scalarcompare),标量逻辑运算(scalarlogicaloperations)。其中标量比较包括但大于,小于,等于,大于等于,小于等于和不等于。标量逻辑运算包括与,或,非。
粗粒度选数单元用于接收输入神经元和非零权值位置信息,使用滑动窗口选取神经网络的一组权值,将选取的权值都置为零,并选取出非零权值对应的神经元。
运算单元用于接收输入被选择的神经元和非零权值,通过乘加运算单元完成神经网络运算并将输出神经元重新传输给存储部分。
更进一步的,存储单元存放权值时只存放非零权值以及非零权值的位置信息。
更进一步的,粗粒度选数单元只会选择出非零权值对应的神经元并传输给运算单元。
更进一步的,加速装置还可包括预处理模块。如图2-7所示,该模块对原始数据进行预处理,包括切分、高斯滤波、二值化、正则化、归一化等等。
更进一步的,加速装置还可包括直接数据存取单元dma(directmemoryaccess)。
更进一步的,加速装置还可包括指令缓存,输入神经元缓存,非零权值缓存,非零权值位置缓存,输出神经元缓存。
特别的,存储单元主要用来存储神经网络的神经元,权值以及指令。其中存放权值时只存放非零权值以及非零权值的位置信息。
特别的,dma用于在所述存储单元、指令缓存、非零权值缓存、非零权值位置缓存,输入神经元缓存和输出神经元缓存中进行数据或者指令读写。
指令缓存,用于存储专用指令;
非零权值缓存,用于缓存非零权值数据;
非零权值位置缓存,用于缓存非零权值位置数据;
非零权值位置缓存将输入数据中每个连接权值一一对应到相应的输入神经元。
一种情形下非零权值位置缓存一一对应的方法为采用1表示有连接,0表示无连接,每组输出与所有输入的连接状态组成一个0和1的字符串来表示该输出的连接关系。另一种情形下非零权值位置缓存一一对应的方法为采用1表示有连接,0表示无连接,每组输入与所有输出的连接状态组成一个0和1的字符串来表示该输入的连接关系。另一种情形下非零权值位置缓存一一对应的方法为将一组输出第一个连接所在的输入神经元位置距离第一个输入神经元的距离、所述输出第二组输入神经元距离上一个输入神经元的距离,所述输出第三组输入神经元距离上一个输入神经元的距离,……,依次类推,直到穷举所述输出的所有输入,来表示所述输出的连接关系。
输入神经元缓存单元,用于缓存输入到粗粒度选数单元的输入神经元;
输出神经元缓存单元,用于缓存运算单元输出的输出神经元。
控制单元,用于接收指令缓存中的指令,经过译码后生成控制信息控制运算单元进行计算操作。
粗粒度选数单元,用于接收输入神经元和非零权值位置信息,选择出需要进行运算的神经元。粗粒度选数单元只会选择出非零权值对应的神经元并传输给运算单元。
运算单元,用于根据存储单元中存储的指令对所述数据执行相应运算。
运算单元包括但不仅限于三个部分,第一部分一个或多个乘法器,第二部分一个或多个加法器,优选的,第二部分包括多个加法器,多个加法器组成加法树。第三部分为激活函数单元。第一部分将第一输入数据(in1)和第二输入数据(in2)相乘得到相乘之后的输出(out1),过程为:out=in1*in2;第二部分将第三输入数据in3通过加法树逐级相加得到第二输出数据(out2),其中in3是一个长度为n的向量,n大于1,过称为:out2=in3[1]+in3[2]+...+in3[n],和/或将第三输入数据(in3)通过加法数累加之后和第四输入数据(in4)相加得到第二输出数据(out2),过程为:out=in3[1]+in3[2]+...+in3[n]+in4,或者将第三输入数据(in3)和第四输入数据(in4)相加得到第二输出数据(out2),过称为:out2=in3+in4;第三部分将第五输入数据(in5)通过激活函数(active)运算得到激活输出数据(out),过程为:out3=active(in5),激活函数active可以是sigmoid、tanh、relu、softmax等,除了做激活操作,第三部分可以实现其他的非线性函数,可将将输入数据(in)通过运算(f)得到输出数据(out),过程为:out=f(in)。
运算单元还可以包池化单元,池化单元将输入数据(in)通过池化运算得到池化操作之后的输出数据(out),过程为out=pool(in),其中pool为池化操作,池化操作包括但不限于:平均值池化,最大值池化,中值池化,输入数据in是和输出out相关的一个池化核中的数据。
所述运算单元执行运算包括几个部分,第一部分是将所述第一输入数据和第二输入数据相乘,得到相乘之后的数据;第二部分执行加法树运算,用于将第三输入数据通过加法树逐级相加,或者将所述第三输入数据通过和第四输入数据相加得到输出数据;第三部分执行激活函数运算,对第五输入数据通过激活函数(active)运算得到输出数据。以上几个部分的运算可以自由组合,从而实现各种不同功能的运算。
以下,列举神经网络处理器实施例,对本公开的处理方法进行具体说明,但应理解的是其并非因此限制本公开,凡是利用本具体实施例所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本公开的保护范围内。
图2-8是本公开以处理方法的一具体实施例。如图2-8所示,其是神经网络的一个全连接层经过粗粒度剪枝后的结果,全连接层共有8个输入神经元为n1~n8和3个输出神经元为o1~o3。其中n3,n4,n7,n8四个输入神经元与o1,o2,o3三个输出神经元之间的权值通过粗粒度稀疏被置为零;n1与o1,o2,o3之间通过s11,s12,s13三个权值连接,n2与o1,o2,o3之间通过s21,s22,s23三个权值连接,n5与o1,o2,o3之间通过s31,s32,s33三个权值连接,n6与o1,o2,o3之间通过s41,s42,s43三个权值连接;我们用11001100这个比特串表示输入神经元与输出神经元之间的连接情况,即第一种表示非零权值位置信息的情况,1表示输入神经元与三个输出神经元都连接,0表示输入神经元与三个输出神经元都不连接。表1描述了实施例中神经元与权值的信息,公式1描述了o1,o2,o3三个输出神经元的运算公式。从公式1中可以看出o1,o2,o3将接收到相同的神经元进行运算。
表1
公式1--输出神经元运算公式:
o1=n1*s11+n2*s12+n5*s13+n6*s14
o2=n1*s21+n2*s22+n5*s23+n6*s24
o3=n1*s31+n7*s32+n5*s33+n6*s34
在处理装置进行运算时,8个输入神经元,12个权值和8比特的位置信息以及相应的指令被传输到存储单元。粗粒度选数单元接收8个输入神经元和非零权值位置,选出n1,n2,n5,n6四个需要参与运算的神经元。运算单元接收四个被选择的神经元与权值,通过公式1完成输出神经元的运算,然后将输出神经元传输回存储部分。
应该理解到,所揭露的相关装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。
通过本公开的实施例,提供了神经网络的粗粒度稀疏化的处理方法和对应的处理装置,以及芯片、芯片封装结构、板卡和电子装置。其中,粗粒度稀疏化处理方法能够使稀疏神经网络更加规则化,利于用硬件进行加速,同时减少非零权值位置的存储空间。神经网络处理器能够充分挖掘粗粒度稀疏的特性,减少访存同时减少运算量,从而获得加速比并降低能耗在一些实施例里,公开了一种芯片,其包括了上述神经网络处理器。
在一些实施例里,公开了一种芯片封装结构,其包括了上述芯片。
在一些实施例里,公开了一种板卡,其包括了上述芯片封装结构。
在一些实施例里,公开了一种电子装置,其包括了上述板卡。
电子装置包括数据处理装置、机器人、电脑、打印机、扫描仪、平板电脑、智能终端、手机、行车记录仪、导航仪、传感器、摄像头、云端服务器、相机、摄像机、投影仪、手表、耳机、移动存储、可穿戴设备交通工具、家用电器、和/或医疗设备。
所述交通工具包括飞机、轮船和/或车辆;所述家用电器包括电视、空调、微波炉、冰箱、电饭煲、加湿器、洗衣机、电灯、燃气灶、油烟机;所述医疗设备包括核磁共振仪、b超仪和/或心电图仪。
以上所述的具体实施例,对本申请的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本申请的具体实施例而已,并不用于限制本申请,凡在本申请的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!