一种基于LSTM-AON的齿轮剩余寿命的预测方法与流程
本发明属于大数据和智能制造领域,涉及一种基于lstm-aon的齿轮剩余寿命的预测方法。
背景技术:
齿轮广泛应用于机械设备中,是应用最广泛的机械零件之一。齿轮具有传动效率高、结构紧凑、传动平顺性好、承载能力大、使用寿命长等独特的优点,使其具有强大而持久的生命力。在复杂的工作条件和环境下,齿轮容易发生故障,可能导致机器运行的灾难,甚至危及人身安全。对于大型或超大型设备,如水轮发电机、矿山输送机械、直升机动力传动系统、重型机床等,更是如此。进行在役齿轮的寿命预测,能够有效地确定设备的维护时间,提高生产效率,保证生产的连续高效进行,降低事故发生率,防止突发性事故发生,对于工程生产意义重大。
常用的机械设备寿命预测方法主要分为以下三类:1)基于模型的预测方法;2)数据驱动;3)前两种方法的混合。基于模型的方法构建描述组件退化过程的物理模型。这种方法需要特定的力学知识,因此适用性较低。数据驱动方法从常规收集的监测数据中派生出预测模型。它主要基于统计和机器学习方法,目的是发现系统的行为。因此,这些方法在精确性、复杂性和适用性之间提供了一种折衷。混合方法结合了基于模型和数据驱动技术。利用监测系统的物理知识建立模型,利用数据驱动技术对参数进行学习和更新。基于模型和数据驱动技术的结合使该方法准确,但仍然需要特定的物理知识而且计算上很昂贵。数据驱动方法中基于机器学习的方法能够克服退化模型未知的问题,同时构建模型的输入也不仅局限于状态监测数据,可以是多种不同类型的数据。其中基于rnn的剩余寿命预测方法能够融合原有学习样本与新的学习模式实现样本的重新训练,不仅能够提高剩余寿命预测的准确性,而且具有收敛速度快和稳定性高等特点,在可靠性评估和剩余寿命预测领域发挥着重要作用。但处理长期依赖型退化数据时,传统rnn方法会面临梯度消失或爆炸问题,剩余寿命预测精度会受到严重影响。
为解决这个问题长短期记忆(longshort-termmemory,ltsm)网络应运而生,然而lstm虽然具有处理长期依赖型退化数据的能力,当其能力也有不足的时候。实测的退化信号含有丰富的有用信息。齿轮振动信号的时域和频域特征在一定程度上反映了齿轮振动信号的状态、健康状况的下降趋势。为了全面、准确地表达齿轮的退化过程,需计算齿轮的所有特性。但是传统的ltsm网络对齿轮退化数据的分析不够全面,并没有对神经网络的序信息进行挖掘使用,因此寿命预测能力欠佳。因此为了提高网络对齿轮退化数据的分析能力,在考虑到序信息影响的同时,对序信息进行合理且充分的挖掘使用,从而达到对数据进行全面分析的目的,所以有必要设计一种新的神经网络来替换传统ltsm神经网络来预测齿轮的剩余寿命。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于lstm-aon的齿轮剩余寿命的预测方法,将自然语言与振动信号结合在一起,通过注意的引导来划分层次结构,从而提升预测速度并降低网络的计算量。
为达到上述目的,本发明提供如下技术方案:
一种基于lstm-aon的齿轮剩余寿命的预测方法,具体包括以下步骤:
s1:隔δt时间采集时间长度为t的齿轮振动信号,直到齿轮失效,其采样的齿轮振动信号段数为n;
s2:分别计算采集的n段齿轮振动信号降噪之后的21种时频特征,则得到n×21维的特征值矩阵x;
s3:选取前面n1个采样点组成的特征值矩阵x1作为训练矩阵;
s4:通过isomap算法处理训练矩阵x1和特征值矩阵x,分别选取利用最大特征值计算的结果v1=(v11,v12,…,v1n1)t和v=(v1,v2,...,vn)t作为其主要成分;
s5:使用最小二乘法使目标函数
s6:将向量v1归一化,得到归一化之后的向量w=(w1,w2,...,wn1)t;
s7:重构矩阵
s8:将矩阵u前面p行作为注意力引导有序神经元的长短期记忆网络(lstm-aon)的输入,最后一行作为lstm-aon神经网络的输出来训练网络;
s9:矩阵u训练好后,将倒数p个输出作为lstm-aon网络输入,得到下一时刻的输出;
s10:重复步骤s9一定次数,将这些输出反归一化之后与实际特征值v'=(v'p+1,v'p+2,...,v'n)t比较,当输出反归一化之后超过设定的阈值时,这时预测的采样点数乘以齿轮振动信号间隔时间与采样时间之和δt+t即为齿轮的剩余寿命。
进一步,所述lstm-aon神经网络的结构为:假设整个时间维度的输入信息为xt=[x1x2…xt],其中xt=[xt,1xt,2…xt,n]代表t时刻输入数据,ht-1=[ht-1,1ht-1,2…ht-1,m]代表t-1时刻神经网络的递归数据;首先定义注意力引导的层级划分器,对输入信息xt′通过构造器f1确定其层级位置dt′,i,同样对于历史信息ht′-1通过构造器f2确定其层级位置dt′,f,值得注意的是,他们都受到注意力标签qm的引导;
it=σ(wixxt+wihht-1+bi)
ft=σ(wfxxt+wfhht-1+bf)
ot=σ(woxxt+worht-1+bo)
ht=ot⊙tanh(ct)
yt′=g(wt′,yhht′+by)
其中,σ表示sigmod激活函数,wix表示输入数据与隐藏层中输入门之间的权重,wfx表示输入数据与隐藏层中遗忘门之间的权重,wcx表示输入数据与隐藏层中细胞存储单元间的权重,wox表示输入数据与隐藏层中输出门之间的权重,wih表示历史数据与隐藏层中输入门之间的权重,wfh表示历史数据与隐藏层中遗忘门之间的权重,wch表示历史数据与隐藏层中细胞存储单元之间的权重,woh表示历史数据与隐藏层中输出门之间的权重,wt′,yh表示隐藏层输出与输出层之间的权重,bi表示隐含层输入门阈值,bf表示隐含层遗忘门阈值,bc表示隐含层细胞存储单元阈值,bo表示隐含层输出门阈值,by表示输出层阈值,⊙表示点积运算,ct-1表示t-1时刻存储细胞记忆单元输出;
进一步,所述lstm-aon神经网络中,对输入信息xt′通过构造器f1确定其层级位置dt′,i,同样对于历史信息ht′-1通过构造器f2确定其层级位置dt′,f,其表达式如下:
dt′,i=f1(xt,ht-1,qm)
dt′,f=f2(xt,ht-1,qm)
其中,f1和f2被定义为:
dt′,i=index[max(αt′,i)]
dt′,f=index[max(λt′,i)]
输出分别为输入数据与历史数据与注意力标签的注意力系数的最大值元素在层间所在位置的值,αt′,i为输入数据注意力系数,λt′,i为历史数据注意力系数;在神经网络训练过程中,xt+1,n被设为查询向量qm;在预测阶段,将xt,n设为qm。
进一步,所述lstm-aon神经网络中,注意力系数计算公式如下:
为使输入数据与历史数据与注意力非线性相关对输入数据xt′及历史数据ht′-1进行如下操作:
其中,softmax为softmax激活函数,
注意力系数打分函数分别如下:
其中,
进一步,所述lstm-aon神经网络中,通过所求dt′,i和dt′,f排序细胞单元,划分神经网络层级,具体为:
当dt′,f≤dt′,i时,历史数据层级低于当前输入层级,细胞记忆单元ct通过如下规则更新:
当dt′,i≤dt′,f时,当前输入层级低于历史数据层级,细胞记忆单元ct通过如下规则更新:
本发明的有益效果在于:本发明采用的基于注意引导的层级划分方法受到注意标签的影响,通过计算相关元素和标签的注意系数,选取注意系数最大的元素所在层间位置作为层级位置。这样,层级结构的划分由注意力引导,层级结构不再由最大元素决定,而是由与标签最相似的元素决定。最后,通过信息的注意程度将树状层级结构嵌入递归神经网络。从而使得低层级注意力信息代表短期记忆,更容易被遗忘,中注意层级信息和传统的lstm一样,是一种长短时记忆;而高注意力层级信息代表了长期记忆,不易被替代。通过划分的层级结构实现对网络同层信息的分层更新,达到对层间序信息的挖掘的目的,使改进的神经网络能够使用到传统神经网络所不能使用到的序信息,对输入数据的退化信息达到充分的分析与精准的预测,以此来提高齿轮剩余寿命预测精度。
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
图1为lstm-aon神经网络结构图;
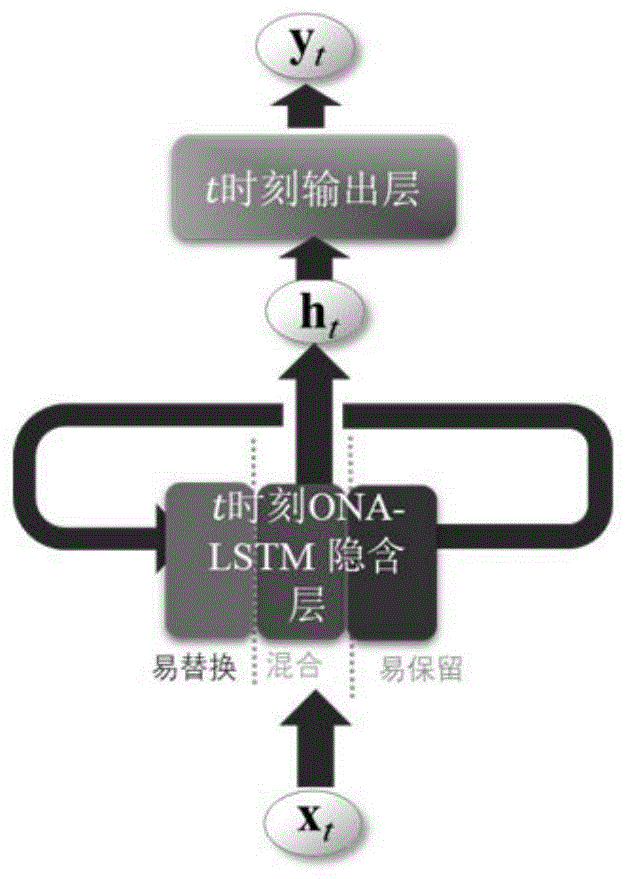
图2为lstm-aon神经网络隐含层结构图;
图3为输入信息层级低于历史信息层级时,注意力引导有序神经元过程图;
图4为输入信息层级高于历史信息层级时,注意力引导有序神经元过程图;
图5为本发明所述齿轮剩余寿命预测方法流程图;
图6为不同数量采样点时的失效阈值、训练值、预测值与实际值仿真图;其中,(a)的采样点数为310,(b)的采样点数为350,(c)的采样点数为380;
图7为本发明所述lstm-aon网络的预测能力效果示意图;
图8为不同模型在已知380个融合特征值时的预测能力对比图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
请参阅图1~图8,图5为一种基于lstm-aon的齿轮剩余寿命的预测方法流程图,具体包括以下步骤:
s1:隔δt时间采集时间长度为t的齿轮振动信号,直到齿轮失效,其采样的齿轮振动信号段数为n;
s2:分别计算采集的n段齿轮振动信号降噪之后的21种时频特征,则得到n×21维的特征值矩阵x;
s3:选取前面n1个采样点组成的特征值矩阵x1作为训练矩阵;
s4:通过isomap算法处理训练矩阵x1和特征值矩阵x,分别选取利用最大特征值计算的结果v1=(v11,v12,…,v1n1)t和v=(v1,v2,...,vn)t作为其主要成分;
s5:使用最小二乘法使目标函数
s6:将向量v1归一化,得到归一化之后的向量w=(w1,w2,...,wn1)t;
s7:重构矩阵
s8:将矩阵u前面p行作为注意力引导有序神经元的长短期记忆网络(lstm-aon)的输入,最后一行作为lstm-aon神经网络的输出来训练网络;
s9:矩阵u训练好后,将倒数p个输出作为lstm-aon网络输入,得到下一时刻的输出;
s10:重复步骤s9一定次数,将这些输出反归一化之后与实际特征值v'=(v'p+1,v'p+2,...,v'n)t比较,当输出反归一化之后超过设定的阈值时,这时预测的采样点数乘以齿轮振动信号间隔时间与采样时间之和δt+t即为齿轮的剩余寿命。
如图1~4所示,lstm-aon神经网络的结构为:假设整个时间维度的输入信息为xt=[x1x2…xt],其中xt=[xt,1xt,2…xt,n]代表t时刻输入数据,ht-1=[ht-1,1ht-1,2…ht-1,m]代表t-1时刻神经网络的递归数据;首先定义注意力引导的层级划分器,对输入信息xt′通过构造器f1确定其层级位置dt′,i,同样对于历史信息ht′-1通过构造器f2确定其层级位置dt′,f,他们都受到注意力标签qm的引导。
dt′,i=f1(xt,ht-1,qm)
dt′,f=f2(xt,ht-1,qm)
其中,f1和f2被定义为:
dt′,i=index[max(αt′,i)]
dt′,f=index[max(λt′,i)]
输出分别为输入数据与历史数据与注意力标签的注意力系数的最大值元素在层间所在位置的值,αt′,i为输入数据注意力系数,λt′,i为历史数据注意力系数。注意力系数计算公式如下:
为使输入数据与历史数据与注意力非线性相关进行如下操作:
其中,softmax为softmax激活函数,
注意力系数打分函数分别如下:
其中,其中,
通过所求dt′,i和dt′,f排序细胞单元,划分神经网络层级。当dt′,f≤dt′,i时,历史数据层级低于当前输入层级,细胞记忆单元ct通过如下规则更新:
当dt′,i≤dt′,f时,当前输入层级低于历史数据层级,细胞记忆单元ct通过如下规则更新:
随着注意力引导的层级信息的划分,lstm-aon神经网络结构的推导公式如下:
it=σ(wixxt+wihht-1+bi)
ft=σ(wfxxt+wfhht-1+bf)
ot=σ(woxxt+worht-1+bo)
ht=ot⊙tanh(ct)
yt′=g(wt′,yhht′+by)
其中,σ表示sigmod激活函数,wix表示输入数据与隐藏层中输入门之间的权重,wfx表示输入数据与隐藏层中遗忘门之间的权重,wcx表示输入数据与隐藏层中细胞存储单元间的权重,wox表示输入数据与隐藏层中输出门之间的权重,wih表示历史数据与隐藏层中输入门之间的权重,wfh表示历史数据与隐藏层中遗忘门之间的权重,wch表示历史数据与隐藏层中细胞存储单元之间的权重,woh表示历史数据与隐藏层中输出门之间的权重,wt′,yh表示隐藏层输出与输出层之间的权重,bi表示隐含层输入门阈值,bf表示隐含层遗忘门阈值,bc表示隐含层细胞存储单元阈值,bo表示隐含层输出门阈值,by表示输出层阈值,⊙表示点积运算,ct-1表示t-1时刻存储细胞记忆单元输出;
实验验证:
本次实验采取第一级传动加速而第二级传动减速的模式,正好使实验齿轮箱的传动比为1:1。实验齿轮使用的材料为40cr,加工精度为5级,表面硬度为55hrc,模数为5。特别地,大齿轮齿数为31,小齿轮齿数为25,第一级传动齿轮宽度为21mm。在本次实验之中,扭矩为1400n.m,大齿轮转速为500r/min,实验齿轮箱润滑油量为4l/h,冷却温度为70度。采集数据的模式选择采集过程中所有数据。由于扭矩很大,第一级传动大齿轮在运行814分钟之后就发生了断齿故障,由于前期信号平稳,不具有劣化信息,故本次实验只采取最后400点进行方法效果验证。
对实验数据在已知不同个融合特征点下进行齿轮剩余寿命预测,预测结果图6所示。本实施例用α-λ性能指标用于评估该方法的预测能力,其中α代表rul预测误差容忍程度,而λ表示预测点与齿轮失效点之间的时间上的相对距离。由图7可知,本发明采用lstm-aon网络的预测精度非常高。
此外,为充分证明本发明设计的mmalstm神经网络的优越性,从mae(平均绝对误差)、nrmse(标准均方根误差)、score(美国电气和电子工程师协会关于寿命预测性能的打分函数)三个评价标准出发,分别与传统lstm及其变体模型进行比较。如图8所示,本发明所述方法比传统lstms具有更高的预测精度。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!