一种基于大数据挖掘的群体发现算法模型及分析模块的制作方法
本发明涉及大数据挖掘领域,更具体地说,是一种基于大数据挖掘的群体发现算法模型。
背景技术:
社团发现已经有很长的研究历史,并且在不同的学科有不同的形式。它与图论和计算机学科中的图分割和社会网络中的层次聚类的思想联系密切。
图分割是并行计算领域研究的重要问题。假设有n个能够通信的计算处理器(处理区并不是要与其他所有的处理器相互通信)。据此可以建立一个网络,其中节点代表处理器,节点之间的边把相互通信的两个节点链接在一起。并行计算要解决的问题是为每个节点分配数量相同的任务,并且使得节点之间的通信最少,也就是使边数数量尽可能少的问题。
分层聚类是寻找社会网络中的社团结构的一类传统算法,这种算法是社会科学家在研究社会网络时提出的发现社会网络中社团结构的方法。它是基于各个节点之间连接的相似性或者强度,把网络自然的分为若干个子群。根据向网络中新增边还是删减边,该算法又分为两类:凝聚算法(agglomerativemethod)和分裂算法(divisivemethod)。
giran和newman提出了一种新的基于边移除的算法称为gn算法。gn算法寻找处于社团之间的边,然后移除这些边,从而找出网络中的社团。
上述的gn算法,每移除一条边后都要重新计算边的介,这就使得此算法的复杂度较高。为此,出现了很多基于gn算法的优化。这些算法很多都是从改进边的度量以高算法的执行速度。例如tyler算法和radicchi算法。并且还引出了一类优化模块度q的算法。
除了上述的算法,还有一些基于其他思想的算法。例如,在已知社团数目的前提下,wu和huberman提出了一种基于电阻网络电压谱的快速分割算法,这种算法不但可以发现网络中的社团,而且还能在不考虑社团结构的前提下,寻找一个节点所在的整个社团,这是很多算法无法实现的。
考虑到本场景的特殊性,在社团成员出现的分布未知,而且存在大量缺失数据,导致不同研究个体之间数据量严重失衡的前提下,利用时间序列中数据时间和站点的特点,只考虑碰面的情形,大胆的将时间序列数据进行切片,利用概率论中的贝叶斯和极大似然的思想,通过相关系数这一统计量,来刻画与已知的目标之间联系紧密程度。如果两个人共同参与集体活动,则他们有可能在某些时间出现在共同的地点;如果两个人频繁同时出现在共同的场所,则可以认为他们的关系紧密。
技术实现要素:
本发明的目的是为了解决现有技术中存在的缺点,而提出的一种基于大数据挖掘的群体发现算法模型。
为了实现上述目的,本发明的技术方案如下:
一种基于大数据挖掘的群体发现算法模型,包括以下步骤:
s1:获取目标的每一条轨迹数据,并作预处理;
s2:以目标的每一条有效轨迹数据为起点,以指定时长δ截取预处理后的轨迹数据;记录所截得的切片中其他人出现的次数(去重);
s3:利用这些切片,初步确定同行的人;
s4:获取目标和同行的人的时间序列轨迹数据,按时间排序和预处理;
s5:以每一条有效足迹为起点,以已知定长截取该时间序列轨迹数据;计算所有目标和同行的人出现的次数;
s6:在s5的基础上对切片后的数据进行二次切片,形成一组关于目标和同行足迹的有序事务;
s7:在s6的基础上,计算2-群体,3-群体…直到n-群体;并对最终的结果进行反向删除。
优选的,所述步骤s1,获取目标的每一条轨迹数据,并且按站点分组,各组按时间排序后,以定长interval对分组后的数据进行去重,即如果一个人在某个站点短时间(interval)内连续出现多次,只保留第一条记录。
优选的,所述步骤s2中,以目标的每一条有效轨迹数据为中心,以指定时长δ截取预处理后的轨迹数据,记录所截得的切片中其他人出现的次数,如果目标的同一个切片中出现多次某个人的记录,只记1次。
优选的,所述步骤s3中,利用s2中的这些切片,利用apriori关联分析中的支持度的思想,初步确定同行的人:如果对于目标a,如果在s2中找到的所有的以a为中心的切片中出现的所有人的集合为x,则对于任意一个不是目标的人b∈(x-a),如果b在所有以a为中心的切片中累计出现的次数count(b)>阈值s,则认为b是a同行。
优选的,所述步骤s5,s6中,以每一条有效足迹为起点,以已知定长δ/2截取该时间序列轨迹数据,同时计算所有目标和同行的人出现的次数;在s5的基础上对切片后的数据进行二次切片,形成一组关于目标和同行足迹的有序事务;对时间序列数据的切分分成两步,主要是这样有利于计算所有目标和同行的人出现的次数。完成计算目标和同行的人各自出现的次数后,在s5的切片进行二次切片,具体来说,对于s5中的每一个切片,求它的不只包含首个元素的子集;即如果这个切片是[a,b,c,d],则二次切分后的结果是[a,b],[a,c],[a,d],[a,b,c],[a,b,d],[a,c,d],[a,b,c,d]。
优选的,所述步骤s7中,依次计算2-群体,3-群体,…n-群体;利用相关系数计算2-群体,计算任意的b与c的相关系数ρ(b,c∈t,t是目标a和所有同行的人的集合):
其中
如果
本发明同时提出一种基于大数据挖掘的群体发现分析系统,包括目标存储模块、站点基本信息存储模块、站点数据存储模块、数据预处理模块、数据切片模块、群体计算模块和群体存储模块;
所述目标存储模块,记录着已经确认的关注对象的信息;
所述站点基本信息存储模块,记录着各站点的经纬度和站点名称信息;
所述站点数据存储模块,保存着实时身份的数据,一条数据包括如下属性,身份,时间,站点经纬度,一条记录意味着某人在该时间该站点附近出现;
所述数据预处理模块,包括以下两部分:
(1)对目标的轨迹的预处理,获取目标的每一条轨迹数据,并且按站点分组,各组按时间排序后,以定长interval对分组后的数据进行去重,即如果一个人在某个站点短时间(interval)内连续出现多次,只保留第一条记录;
(2)在初步确定同行的范围后,获取目标和同行的人的时间序列轨迹数据,按地点分组,各组按时间排序后;对同一个人的连续重复数据做去重;
所述的数据切片模块,包含以下部分:
(1)目标数据切片:以目标的每一条有效轨迹数据为中心,以指定时长δ截取预处理后的轨迹数据,截取相应的切片,用来初步确定同行的人;
(2)初步切片:以目标和同行的每一条有效足迹为起点,以已知定长δ/2截取该时间序列轨迹数据;初步切片的每一条结果描述的是在某一时刻某一地点相继出现人,称之为共站数据,在整理共站数据切片的同时,计算所有目标和同行的人出现的次数;
(3)共站数据的二次切片:是对初步切片的的结果的进一步切片,即对每一个初步切片的数据,求它的不只包含首个元素的子集;即如果这个切片是[a,b,c,d],则二次切分后的结果是[a,b],[a,c],[a,d],[a,b,c],[a,b,d],[a,c,d],[a,b,c,d];
所述的群体计算模块:利用相关系数来刻画两个人的相关性,如果两者的相关性大于0,则可以认为两者有关联;
所述的群体存储模块:用于存储和更新最终的群体关系。
与现有技术相比,齿轮箱盖固定护罩,设置有利于安装稳固的固定安装机构,且装置本体在具备基本防护性能的前提下,具备良好的通风散热功能,此外设置有主动导风散热机构,整体散热性能较好,利于齿轮箱长时间运作,整体装置实际应用价值高。
附图说明
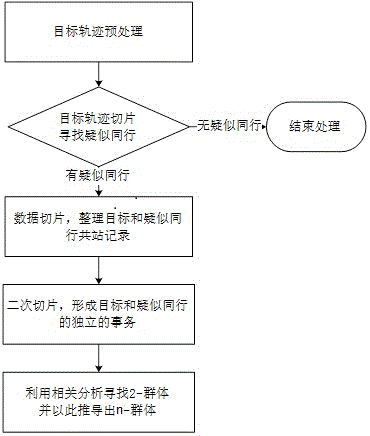
图1是本发明实施例1中方法的流程框图。
具体实施方式
下下面结合实例对本发明所述的一种基于大数据挖掘的群体发现算法模型作进一步说明。
以下是本发明所述的最佳实施例,并不因此限定本发明的保护范围。
实施例1
如图1所示,本发明所述的一种基于大数据挖掘的群体发现算法模型,包括以下步骤:
s1:获取目标的每一条轨迹数据,并作预处理;
对于目标a,对于a的在指定时间范围内所有记录,并且按站点分组,各组按时间排序后,以定长interval对分组后的数据进行去重,即如果一个人在某个站点短时间(interval)内连续出现多次,只保留第一条记录;另外,如果重复数据持续的时间超过△t,则每隔△t,保留一条就近的记录(若相等,则保留时间早的那一条记录),后面保留数据的时间依据上一条保留数据的时间。
s2:以目标的每一条有效轨迹数据为起点,以指定时长δ截取预处理后的轨迹数据,并对所截得的每一个切片数据进行预处理。
s3:利用这些切片,初步确定同行的人。
s4:获取目标和同行的人的时间序列轨迹数据,并作预处理。
s5:以每一条有效足迹为起点,以已知定长δ/2截取该时间序列轨迹数据;计算所有目标和同行的人出现的次数。
s6:在s5的基础上对切片后的数据进行二次切片,形成一组关于目标和同行足迹的有序事务。
s7:在s6的基础上,利用相关系数计算2-群体,并进一步推到处3-群体…直到n-群体;并对最终的结果进行反向删除。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!