标注异常行为的方法及装置与流程
本发明涉及行为分析技术领域,尤其涉及标注异常行为的方法及装置。
背景技术:
异常行为检测是人类行为识别的一个重要分支,是计算机视觉领域的一个重要研究任务。异常行为检测主要是指对特定行为进行类别分类及检测,特定行为可以是公共场所下的斗殴事件、踩踏事件等。异常行为检测过程主要包含目标特征提取和特征分类这两部分。目标特征提取是指从视频数据中提取能够表征异常行为动作的特征。特征分类是指对提取出的特征进行分类,例如,通过支持向量机(supportvectormachine,svm)对提取出的特征向量进行分类。
随着深度学习在计算机视觉领域的发展,将深度学习应用到异常行为检测中能够极大推动该领域的研究进程,使得目标特征提取和特征分类的准确率及实时性得到了大幅提高。
目前,可用于深度学习的异常行为数据包含以下三类:
第一类是针对人群异常进行研究的数据集。例如,uscd数据集是对马路场景下行人的异常行为进行研究,其包含98个视频和5个异常行为。cuhk数据集是对校园拥挤场景下的交通和行人的异常行为进行研究,两个子数据集分别包含90和30分钟的视频。virat数据集是对人和车辆这两个对象的活动进行研究,其包含12种不同类型的事件,通过11个摄像头获取不同场景下的事件,约8.5个小时的视频。
第二类是人类在公共场所下具有破坏性行为的数据集。例如,minnesota大学在7个场景下采集视频数据,对人类丢弃物体、跨越禁区等行为进行了研究并制作了数据集。
第三类是人类在公共场所下暴力行为的数据集。例如,vif(violentflow)数据库从youtube搜集了246个关于暴力行为的视频。ucf-crimedataset数据集研究了13个现实世界中的暴力行为,从网络上搜集相关视频并进行标注。
现有技术在标注异常行为数据集时,通常采用人工标注方式,这样不仅会花费大量时间,还会消耗大量人力。
技术实现要素:
鉴于上述问题,提出了本发明以便提供一种克服上述问题或者至少部分地解决上述问题的标注异常行为的方法及装置。
依据本发明的第一个方面,本发明提供一种标注异常行为的方法,所述方法包括:
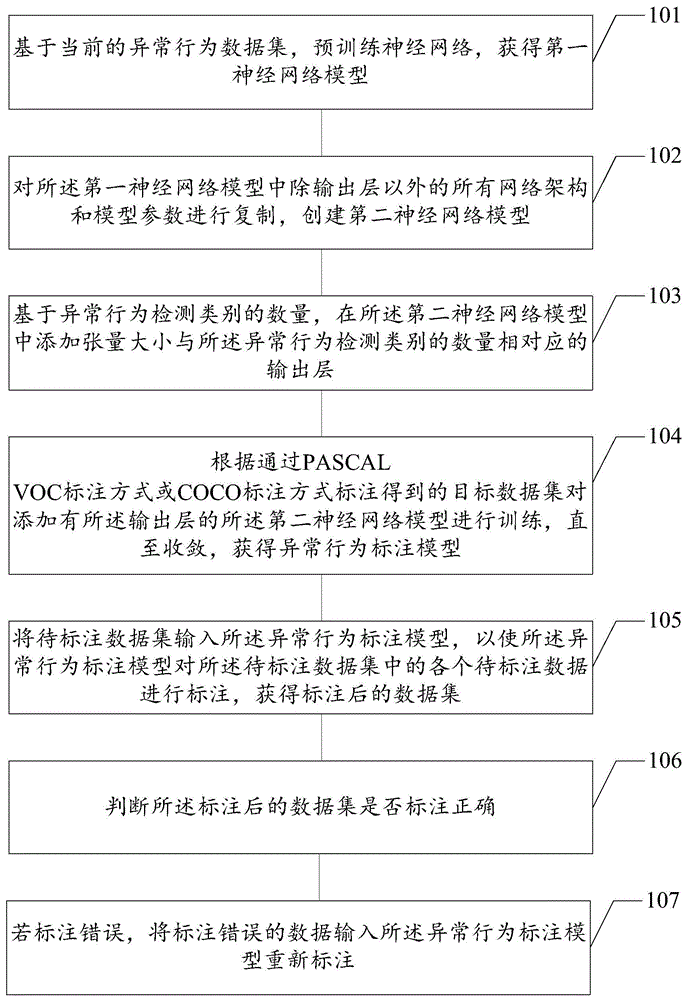
基于当前的异常行为数据集,预训练神经网络,获得第一神经网络模型;
对所述第一神经网络模型中除输出层以外的所有网络架构和模型参数进行复制,创建第二神经网络模型;
基于异常行为检测类别的数量,在所述第二神经网络模型中添加张量大小与所述异常行为检测类别的数量相对应的输出层;
根据通过pascalvoc标注方式或coco标注方式标注得到的目标数据集,对添加有所述输出层的所述第二神经网络模型进行训练,直至收敛,获得异常行为标注模型;
将待标注数据集输入所述异常行为标注模型,以使所述异常行为标注模型对所述待标注数据集中的各个待标注数据进行标注,获得标注后的数据集;
判断所述标注后的数据集是否标注正确;
若标注错误,将标注错误的数据输入所述异常行为标注模型重新标注。
优选的,通过pascalvoc标注方式标注得到所述目标数据集,包括:
对至少一个目标图片进行标注,获得与所述目标图片对应的标注文件,形成所述目标数据集;
其中,所述对至少一个目标图片进行标注,包括以下标注情况中的至少一种:不标注行为类型的情况、标注为bad的情况以及利用标注框标注的情况;
其中,所述不标注行为类型的情况包括:不确定的目标行为、尺寸小于预设尺寸的目标行为和遮挡范围大于预设遮挡范围的目标行为;
其中,所述标注为bad的情况包括:目标行为的数量大于预设数量的目标图片、图像质量低至无法识别出目标行为的目标图片以及包含多个子图像的目标图片;
其中,利用标注框标注的情况包括:利用标注框标注目标行为的可见区域;利用标注框标注所有可见像素;目标行为的15%以上被遮挡并且位于标注框外,标注为“truncated”;利用标注框将附属于目标行为的遮挡物与目标行为一同标注;利用标注框标注通过玻璃可见的目标行为;利用标注框标注出现在镜子中的目标行为;
其中,所述标注文件包含所述目标图片和可扩展标注语言子文件;
所述可扩展标注语言子文件包含所述目标图片的路径、所述目标图片的长和宽、经过所述标注框标注后的行为类别以及所述标注框在所述目标图片中的位置。
优选的,通过coco标注方式标注得到所述目标数据集,包括:
对与目标检测任务或语义分割任务对应的第一数据集中的各个目标图片进行标注,获得与所述目标图片对应的第一标注文件,形成所述第一目标数据集;其中,所述第一标注文件包含以下数据结构:第一注解和第一种类,所述第一注解包括目标行为id、目标行为所属图片、目标行为的类别和所述标注框在所述目标图片中的位置,所述第一种类包括标注针对的所有行为类别以及各行为类别的id;
对与关键点检测任务对应的第二数据集中的各个目标图片进行标注,获得与所述目标图片对应的第二标注文件,形成所述第二目标数据集;其中,所述第二标注文件包含以下数据结构:第二注解和第二种类,所述第二注解包括目标行为的关键点位置及关键点数目、目标行为的类别和所述标注框在所述目标图片中的位置,所述第二种类包括标注针对的所有关键点;
对与场景分割任务对应的第三数据集中的各个目标图片进行标注,获得与所述目标图片对应的第三标注文件,形成所述第三目标数据集;其中,所述第三标注文件包含以下数据结构:第三注解、段信息和第三种类,所述第三注解包括所述目标图片的id和所述目标图片的文件名,所述段信息包含像素段id、目标行为的id和所述标注框在所述目标图片中的位置,所述第三种类包括标注针对的所有像素段id、标注针对的所有行为类别和像素段颜色;
对与图片字幕任务对应的第四数据集中的各个目标图片进行标注,获得与所述目标图片对应的第四标注文件,形成所述第四目标数据集;其中,所述第四标注文件包含以下数据结构:第四注解,所述第四注解包括目标行为id、所述目标图片的id和字幕。
优选的,在所述将待标注数据集输入所述异常行为标注模型之前,所述方法还包括:
基于不同采集时间段、不同采集角度、不同采集距离、不同采集天气、不同采集地点类型,采集获得所述待标注数据集;
其中,所述待标注数据集的数据源包括以下数据源中的至少一种数据源:
将监控视频中的视频流作为所述数据源;
将用户预先录制的视频流作为所述数据源;
将网络中现实场景下的图片或视频作为所述数据源;
将在线视频、电影、电视剧、新闻中的图片或视频作为所述数据源;
将对当前的异常行为数据集整合得到图片或视频作为所述数据源。
优选的,在所述基于异常行为检测类别的数量,在所述第二神经网络模型中添加张量大小与所述异常行为检测类别的数量相对应的输出层之前,所述方法还包括:
对异常行为进行分类;
其中,所述对异常行为进行分类包括:
s={s1、s2、s3};
其中,s为所述异常行为,s1为暴力异常行为,s2为公共场所破坏性行为,s3为人群异常行为;
其中,s1={snormal,sdead};
snormal为一般暴力行为,snormal={sn1、sn2、sn3、sn4、sn5、sn6},sn1为拳打、sn2为脚踢、sn3为掐脖子、sn4为揪头发、sn5为扇耳光、sn6为扔东西;
sdead为致命暴力行为,sdead={sd1、sd2、sd3},sd1为刀捅、sd2为烧伤、sd3为射击;
其中,s2={sp1,sp2,sp3,sp4};
sp1为吸烟,sp2为吐痰,sp3扔垃圾,sp4为践踏绿化;
其中,s3={sviolence,snon-violence};
sviolence为暴力性质异常行为,sviolence={sv1,sv2,sv3},sv1为群殴,sv2为踩踏,sv3为骚乱;
snon-violence为非暴力性质异常行为,snon-violence={snv1,snv2,snv3},snv1为多人聚集跑向同一方向且相互间并无异常行为,snv2为多人向同一中心点聚集且相互间并无异常行为,snv3为多人从同一中心点向多个方向跑动且相互间并无异常行为。
优选的,在所述获得标注后的数据集之后,所述方法还包括:
对所述标注后的数据集进行基准测试和数据集交叉验证。
优选的,对所述标注后的数据集进行所述基准测试,包括:
将所述标注后的数据集应用到目标深度学习算法中,获得平均查全率、平均查准率和交并比;
基于所述平均查全率、平均查准率和交并比,对所述标注后的数据集进行评估。
优选的,对所述标注后的数据集进行所述数据集交叉验证,包括:
将所述标注后的数据集随机分为第一训练集和第一测试集,以及将所述当前的异常行为数据集随机分为第二训练集和第二测试集;
利用目标深度学习算法在第一训练集上训练得到第一模型,以及利用所述目标深度学习算法在第二训练集上训练得到第二模型;
将所述第一模型和所述第二模型分别在所述第一测试集上测试,计算各个异常行为类别的平均查准率,获得第一计算结果;
将所述第一模型和所述第二模型分别在所述第二测试集上测试,计算各个异常行为类别的平均查准率,获得第二计算结果;
基于所述第一计算结果和所述第二计算结果,对所述标注后的数据集和所述当前的异常行为数据集进行评估。
依据本发明的第二个方面,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如前述第一个方面所述的方法步骤。
依据本发明的第三个方面,本发明提供了一种计算机设备,包括存储,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如前述第一个方面所述的方法步骤。
本发明的标注异常行为的方法,首先,基于当前的异常行为数据集,预训练神经网络,获得第一神经网络模型。接着,对第一神经网络模型中除输出层以外的所有网络架构和模型参数进行复制,创建第二神经网络模型。然后,基于异常行为检测类别的数量,在第二神经网络模型中添加张量大小与异常行为检测类别的数量相对应的输出层。再根据通过pascalvoc标注方式或coco标注方式标注得到的目标数据集对添加有输出层的第二神经网络模型进行训练,直至收敛,获得异常行为标注模型。接着,将待标注数据集输入异常行为标注模型,以使异常行为标注模型对待标注数据集中的各个待标注数据进行标注,获得标注后的数据集。再判断标注后的数据集是否标注正确。若标注错误,将标注错误的数据输入异常行为标注模型重新标注。本发明通过上述过程实现了自动对异常行为数据进行标注的效果,缩短了标注时间,节省了人力。并且,本发明不仅简化了训练标注模型的训练过程,而且结合迁移学习缩短了训练时间。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考图形表示相同的部件。在附图中:
图1示出了本发明实施例中标注异常行为的方法的流程图。
图2示出了本发明实施例中迁移学习的过程的示意图。
图3示出了本发明实施例中暴力异常行为包含行为类型的示意图。
图4示出了本发明实施例中公共场所破坏性行为包含行为类型的示意图。
图5示出了本发明实施例中人群异常行为包含行为类型的示意图。
图6示出了本发明实施例中一实例下的交叉验证结果。
图7示出了本发明实施例中计算机设备的结构图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
本发明第一实施例提供一种标注异常行为的方法,如图1所示,所述方法包括:
步骤101:基于当前的异常行为数据集,预训练神经网络,获得第一神经网络模型。
步骤102:对第一神经网络模型中除输出层以外的所有网络架构和模型参数进行复制,创建第二神经网络模型。
步骤103:基于异常行为检测类别的数量,在第二神经网络模型中添加张量大小与异常行为检测类别的数量相对应的输出层。
步骤104:根据通过pascalvoc标注方式或coco标注方式标注得到的目标数据集,对添加有上述输出层的第二神经网络模型进行训练,直至收敛,获得异常行为标注模型。
步骤105:将待标注数据集输入异常行为标注模型,以使异常行为标注模型对待标注数据集中的各个待标注数据进行标注,获得标注后的数据集。
步骤106:判断标注后的数据集是否标注正确。
步骤107:若标注错误,将标注错误的数据输入所述异常行为标注模型重新标注。
对于步骤101而言,当前的异常行为数据集为已有的异常行为数据集。该异常行为数据集为已经标注好的数据集,同时,该异常行为数据集可以为现有的大型异常行为数据集,如imagenet大型数据集。预训练针对的神经网络可以为ssd网络。本申请通过在当前的异常行为数据集上预训练神经网络,能够获得第一神经网络模型。
接着,在步骤102中,创建第二神经网络模型。具体地,通过对第一神经网络模型中除输出层以外的所有网络架构和模型参数进行复制,得到第二神经网络模型。第二神经网络模型和第一神经网络模型除了输出层不同以外,其他部分均相同。
进一步,在步骤103中,首先确定需要标注的异常行为检测类别,需要标注的异常行为检测类别也可以被称为目标异常行为检测类别。进而,能够得到异常行为检测类别的数量。然后,向第二神经网络模型添加输出层,该输出层的特点是其张量大小与异常行为检测类别的数量相对应。该输出层的张量大小的通式为:(c+4+1)*m*n*k,c为异常行为检测类别的数量,4是指标注框(bbox)的坐标x、y、width和height,1为置信度(即类别概率大小),m*n是featuremap的大小,k是defaultbox的数目。
例如,如果当前需要训练一个用于标注拳打、脚踢、掐脖子、揪头发、扇耳光和扔东西这6个目标异常行为检测类型的模型。那么,在第二神经网络模型中添加张量大小与6相对应的输出层,具体的:第二神经网络模型输出层的张量大小为:(6+4+1)*m*n*k,其中,6为异常行为检测类别的数量。
进一步,对于每个输出层而言,随机初始化输出层的模型参数。
进一步,在步骤104中,根据目标数据集对添加完输出层的第二神经网络模型进行训练。目标数据集属于自制数据集。在本申请中,目标数据集通过pascalvoc标注方式或coco标注方式标注得到。下面对如何通过pascalvoc标注方式标注得到目标数据集,以及如何通过coco标注方式标注得到目标数据集进行详细说明:
首先需要说明的是,不同的深度学习算法所需的标注方式可能不同。coco标注方式对应五种任务类型,分别为目标检测任务、语义分割任务、关键点检测任务、场景分割任务和图片字幕任务。针对上述五种任务类型的数据采用coco标注方式进行标注,而对于其他任务类型的数据采用pascalvoc标注方式进行标注。
其中,通过pascalvoc标注方式对数据进行标注获得目标数据集,包括:对至少一个目标图片进行标注,获得与目标图片对应的标注文件,形成目标数据集。
具体来讲,首先获取大量目标图片。接着,分别对每个目标图片进行标注。在标注后,一个目标图片将会对应生成一个标注文件,最终由所有标注文件构成目标数据集。其中,标注文件包含目标图片和与目标图片对应的可扩展标注语言子文件。
进一步来讲,对于如何对一个目标图片进行标注,包括以下标注情况中的至少一种:不标注行为类型的情况、标注为bad的情况以及利用标注框标注的情况。其中,不标注行为类型的情况是指不标注目标图片中目标的行为类型,标注为bad的情况是指将目标图片标注为bad,利用标注框标注是指利用标注框对目标图片中目标的行为类型进行标注。
不标注行为类型的情况包括以下情况:
a)对不确定的目标行为。如果不确定目标图片中的目标行为是什么,则针对该目标行为,不标注其行为类型。
b)尺寸小于预设尺寸的目标行为。预设尺寸由用户设定,通常以肉眼是否可见为界限。当目标图片中目标行为的尺寸小于预设尺寸,表明目标行为非常小,这种情况下,不标注该目标行为的行为类别。
c)遮挡范围大于预设遮挡范围的目标行为。预设遮挡范围由用户设定,通常来说,预设遮挡范围可以为80%。若目标图片中目标行为被遮挡大于80%,只能看到目标行为的20%以下,这种情况下,不标注该目标行为的行为类别。
标注为bad的情况包括以下情况:
a)包含的目标行为的数量大于预设数量的目标图片。预设数量由用户设定,例如,可以将预设数量设定为100,如果目标图片中包含的目标行为的数量大于100,那么表明目标图片中包含过多的目标行为。在这种情况下,将该目标图片标注为bad。
b)图像质量低至无法识别出目标行为的目标图片。有些目标图片的质量较差,无法识别出目标行为,对这类目标图片标注为bad。
c)包含多个子图像的目标图片。如果目标图片中包含有多个图像,那么将这类目标图片标注为bad。
利用标注框标注的情况包括以下情况:
a)利用标注框标注目标行为的可见区域。具体地,如果目标行为包含有可见区域和不可见区域,那么,利用标注框对目标行为的可见区域进行标注,对于不可见区域不进行标注。例如,如果一个人被一个物体挡住了腿,那么利用标注框标注腿以上的部分,被挡住的腿不进行标注。
b)利用标注框标注所有可见像素。具体地,标注框应包含目标行为的所有可见像素,除非标注框必须过大以包括其他像素,其他像素的范围为小于5%。例如,在标注人物时,如果人物头部带了圣诞帽,圣诞帽即其他像素,这种情况下必须包含其他像素,则标注框可以包含圣诞帽。
c)目标行为的15%以上被遮挡并且位于标注框之外,标注为truncated。具体地,如果目标图片中目标行为的15%以上被遮挡并且位于标注框外,则将该目标图片标注为truncated。另外,如果目标行为的遮挡区域位于标注框内,则不会标注为truncated。
d)利用标注框将附属于目标行为的遮挡物与目标一同标注。例如,衣服和泥泞均属于附属于目标行为的遮挡物,这些遮挡物与目标行为一同标注在标注框内。
e)利用标注框标注通过玻璃可见的目标行为。具体地,通过玻璃可见的目标行为,本申请将会利用标注框对其进行标注。
f)利用标注框标注出现在镜子中的目标行为。具体地,在镜子中呈现的目标,本申请将会利用标注框对其进行标注。
g)海报、标志图等图片中的目标行为若具有真实感时,可以标注。
h)卡通图片和手绘图片不可标注。
进一步,标注文件中的目标图片与标注前的目标图片完全相同,而对于目标图片的标注信息将会存储在可扩展标注语言子文件中,通过可扩展标注语言子文件中的标注信息能够知晓对目标图片的标注情况,并不会破坏目标图片。
进一步来讲,可扩展标注语言子文件包含目标图片的路径、目标图片的长和宽、经过标注框标注后的行为类别以及标注框在目标图片中的位置。需要说明的是,标注框在目标图片中的位置为坐标位置,即,(xmin,ymin,xmax,ymax),实际上目标图片中并不存在标注框,而是通过可扩展标注语言子文件中的信息来对标注框的标注位置进行体现。经过标注框标注后的行为类别是指异常行为的类型,例如,拳打、脚踢等等。
其中,通过coco标注方式对数据进行标注获得目标数据集,包括:
a)对于目标检测任务或语义分割任务对应的第一数据集中的各个目标图片进行标注,获得与目标图片对应的第一标注文件,形成第一目标数据集;其中,第一标注文件包含以下数据结构:第一注解和第一种类,第一注解包括目标行为id、目标行为所属图片、目标行为的类别和标注框在目标图片中的位置,第一种类包括标注针对的所有行为类别以及各行为类别的id。
具体来讲,目标检测任务和语义分割任务对应的标注过程相同。对目标检测任务或语义分割任务而言,其具有对应的深度学习算法,该算法用于执行目标检测任务或语义分割任务。而用于供该算法学习的数据集就是本申请中与目标检测任务或语义分割任务对应的第一数据集。第一数据集中包含有至少一个目标图片。该目标图片可以是未经过标注的图片。接着,分别对第一数据集中的每个目标图片进行标注。在标注后,一个目标图片将会对应生成一个第一标注文件,最终由所有第一标注文件构成第一目标数据集。
b)对与关键点检测任务对应的第二数据集中的各个目标图片进行标注,获得与目标图片对应的第二标注文件,形成第二目标数据集。其中,第二标注文件包含以下数据结构:第二注解和第二种类,第二注解包括目标行为的关键点位置及关键点数目、目标行为的类别和标注框在目标图片中的位置,第二种类包括标注针对的所有关键点。
具体来讲,对关键点检测任务而言,其具有对应的深度学习算法,该算法用于执行关键点检测任务。而用于供该算法学习的数据集就是本申请中与关键点检测任务对应的第二数据集。第二数据集中包含有至少一个目标图片。该目标图片可以是未经过标注的图片。接着,分别对第二数据集中的每个目标图片进行标注。在标注后,一个目标图片将会对应生成一个第二标注文件,最终由所有第二标注文件构成第二目标数据集。
c)对与场景分割任务对应的第三数据集中的各个目标图片进行标注,获得与目标图片对应的第三标注文件,形成第三目标数据集;其中,第三标注文件包含以下数据结构:第三注解、段信息和第三种类,第三注解包括目标图片的id和目标图片的文件名,段信息包含像素段id、目标行为的id和标注框在目标图片中的位置,第三种类包括标注针对的所有像素段id、标注针对的所有行为类别和像素段颜色。
具体来讲,对场景分割任务而言,其具有对应的深度学习算法,该算法用于执行场景分割任务。而用于供该算法学习的数据集就是本申请中与场景分割任务对应的第三数据集。第三数据集中包含有至少一个目标图片。该目标图片可以是未经过标注的图片。接着,分别对第三数据集中的每个目标图片进行标注。在标注后,一个目标图片将会对应生成一个第三标注文件,最终由所有第三标注文件构成第三目标数据集。
d)对与图片字幕任务对应的第四数据集中的各个目标图片进行标注,获得与目标图片对应的第四标注文件,形成第四目标数据集;其中,第四标注文件包含以下数据结构:第四注解,第四注解包括目标行为id、目标图片的id和字幕。
具体来讲,对图片字幕任务而言,其具有对应的深度学习算法,该算法用于执行图片字幕任务。而用于供该算法学习的数据集就是本申请中与图片字幕任务对应的第四数据集。第四数据集中包含有至少一个目标图片。该目标图片可以是未经过标注的图片。接着,分别对第四数据集中的每个目标图片进行标注。在标注后,一个目标图片将会对应生成一个第四标注文件,最终由所有第四标注文件构成第四目标数据集。
在本申请中,注解为annotation,种类为categories,段信息为segment_info。
需要说明的是,在本申请中,标注文件以json格式保存。
进一步,在步骤104中,在获得目标数据集之后,利用目标数据集对添加有输出层的第二神经网络模型进行训练,直至其收敛,获得异常行为标注模型。具体地,由于第二神经网络模型中的输出层并未训练过,因此,需要从初始开始训练,而第二神经网络模型中除输出层以外的其他部分已经进行过预训练,因此,只需要通过训练更新微调即可。
在本申请中,通过步骤101-步骤104实现了一个迁移学习的过程,如图2所示。
进一步,在获得了异常行为标注模型之后,执行步骤105。将待标注数据集输入至异常行为标注模型,利用异常行为标注模型对待标注数据集中的各个数据进行标注。
对于如何采集获得待标注数据,包括以下方法:
基于不同采集时间段、不同采集角度、不同采集距离、不同采集天气、不同采集地点类型,采集获得待标注数据集。
其中,不同采集时间段包括:
t={t1,t2,t3}
t为采集时间段,t1为上午,t2为下午,t3为晚上。当然,还可以包含其他时间段。
其中,不同采集角度包括:
aagle={a1,a2,a3,a4,a5}
aagle为采集角度,a1为俯视,a2为平视,a3为正面,a4为侧面,a5为背面。
当然,还可以包含其他角度。
其中,不同采集距离包括:
f={f1=x,f2=x+e,f3=x+2e,f4=x+3e}
f为采集距离,x为距离目标的初始距离,e为距离增量。当然,还可以包含其他距离。
其中,不同采集天气包括:
w={w1,w2,w3,w4}
w为采集天气,w1为晴天,w2为雨天,w3为雪天,w4为阴天。当然,还可以包含其他天气。
其中,不同采集地点类型包括:
d={d1,d2,d3,d4,d5}
d为采集天气,d1为公园,d2为学校,d3为小区,d4为交通站,d5为商贸城。
其中,待标注数据集的数据源包括以下数据源中的至少一种数据源:
将监控视频中的视频流作为数据源;
将用户预先录制的视频流作为数据源;
将网络中现实场景下的图片或视频作为数据源;
将在线视频、电影、电视剧、新闻中的图片或视频作为数据源;
将对当前的异常行为数据集整合得到图片或视频作为数据源。
其中,在步骤103之前,所述方法还包括:
对异常行为进行分类;
其中,对异常行为进行分类包括:
s={s1、s2、s3};
其中,s为异常行为,s1为暴力异常行为,s2为公共场所破坏性行为,s3为人群异常行为;
其中,如图3所示,s1={snormal,sdead};
snormal为一般暴力行为,snormal={sn1、sn2、sn3、sn4、sn5、sn6},sn1为拳打、sn2为脚踢、sn3为掐脖子、sn4为揪头发、sn5为扇耳光、sn6为扔东西;
sdead为致命暴力行为,sdead={sd1、sd2、sd3},sd1为刀捅、sd2为烧伤、sd3为射击;
其中,如图4所示,s2={sp1,sp2,sp3,sp4};
sp1为吸烟,sp2为吐痰,sp3扔垃圾,sp4为践踏绿化;
其中,如图5所示,s3={sviolence,snon-violence};
sviolence为暴力性质异常行为,sviolence={sv1,sv2,sv3};
sv1为群殴,sv2为踩踏,sv3为骚乱;
snon-violence为非暴力性质异常行为,snon-violence={snv1,snv2,snv3};
snv1为人群单向跑动,即多人聚集跑向同一方向且相互间并无异常行为,snv2为人群聚拢,即多人向同一中心点聚集且相互间并无异常行为,snv3为人群四散跑动,即多人从同一中心点向多个方向跑动且相互间并无异常行为。
进一步来讲,通过步骤105能够标注出异常行为的位置以及异常行为的类别,将异常行为的位置以及异常行为的类别作为标注结果。在获得标注后的数据集之后,将标注后的数据集保存至memcached缓存中,以图片绝对路径为key值,以标注结果为value。存储完毕后,从memcached缓存中读取标注结果绘制到对应的数据中。
进一步,在步骤106中,判断标注后的数据集是否标注正确。如果所有标注数据均正确,则标注终止。如果标注后的数据集中存在数据标注错误,那么,将标注错误的数据重新输入至异常行为标注模型,以进行重新标注。
本申请通过上述过程实现了半自动化迭代标注。
在步骤105之后,本申请还会对标注后的数据集进行评估。具体地,评估过程包括对标注后的数据集进行基准测试,以及基于当前的异常行为数据集对标注后的数据集进行数据集交叉验证。
对于基准测试而言,包括:
将标注后的数据集应用到目标深度学习算法中,获得平均查全率、平均查准率和交并比。基于平均查全率、平均查准率和交并比,对标注后的数据集进行评估。需要说明的是,在本申请中,对标注后的数据集进行评估是指评估目标深度学习算法相对于标注后的数据集的准确性,即,如果目标深度学习算法相对于标注后的数据集的准确性差,则表明目标深度学习算法需要进行调整。
具体来讲,averagerecall(ar)是指平均查全率,计算方式如下:
n是要检测的异常行为类别,recall是指查全率,该指标的计算方式如下:
tp是指被模型预测为正的正样本,fn是指被模型预测为正的负样本。
进一步,averageprecision(ap)是指平均查准率,计算方式如下:
precision是指查准率,该指标的计算方式如下:
fp是指被模型预测为负的正样本。
进一步,iou是指交并比,计算公式如下:
overlap是指预测框与标注框的交集,union是指预测框与标注框的并集,可以通过该指标计算iou=0.5、iou=0.7下的averageprecision值,即ap0.5和ap0.7。
对于数据集交叉验证而言,包括:
s11:将标注后的数据集随机分为第一训练集和第一测试集,以及将当前的异常行为数据集随机分为第二训练集和第二测试集。
s12:利用目标深度学习算法在第一训练集上训练得到第一模型,以及利用目标深度学习算法在第二训练集上训练得到第二模型。
s13:将第一模型和第二模型分别在第一测试集上测试,计算各个异常行为类别的平均查准率,获得第一计算结果。
s14:将第一模型和第二模型分别在第二测试集上测试,计算各个异常行为类别的平均查准率,获得第二计算结果。
s15:基于第一计算结果和第二计算结果,对标注后的数据集和当前的异常行为数据集进行评估。
具体地,在交叉验证过程中,标注后的数据集为dataseta,当前的异常行为数据集为datasetb。选择的目标深度学习算法f(x),如yolov2算法。进一步,f(x)在dataseta上训练得到ma,f(x)在datasetb上训练得到mb。ma和mb分别在dataseta上进行测试,得到第一计算结果,ma和mb分别在datasetb上进行测试,得到第二计算结果,如图6所示。最后,根据第一计算结果和第二计算结果,对标注后的数据集和当前的异常行为数据集进行评估。如果yolov2-a在dataseta上测试ap值较在datasetb上高,yolov2-b在datasetb上测试ap值较在dataseta上低,则说明标注后的数据集具有比当前的异常行为数据集更强的挑战性,即,目标深度学习算法相对于标注后的数据集的准确性更低,目标深度学习算法需要进行调整。
在本申请中,制作数据集的方式明确、简洁、流程完善,能够生成大量的异常行为检测数据集。同时,丰富的数据集搜集方式,能够解决现有异常行为数据集研究场景不够广泛、数据集背景不够丰富、数据集数量不足的问题。同时,对异常行为进行了总结、划分、和定义,能够解决现有数据集中异常行为类别不够丰富的问题。同时,制定了规范的标注准则,使得生成的不同方向的异常异常行为数据集之间可以兼容使用。
基于同一发明构思,本发明第二实施例还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现前述第一实施例所述的方法步骤。
基于同一发明构思,本发明第三实施例还提供了一种计算机设备,如图7所示,为了便于说明,仅示出了与本发明实施例相关的部分,具体技术细节未揭示的,请参照本发明实施例方法部分。该计算机设备可以为包括手机、平板电脑、pda(personaldigitalassistant,个人数字助理)、pos(pointofsales,销售终端)、车载电脑等任意终端设备,以计算机设备为手机为例:
图7示出的是与本发明实施例提供的计算机设备相关的部分结构的框图。参考图7,该计算机设备包括:存储器701和处理器702。本领域技术人员可以理解,图7中示出的计算机设备结构并不构成对计算机设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
下面结合图7对计算机设备的各个构成部件进行具体的介绍:
存储器701可用于存储软件程序以及模块,处理器702通过运行存储在存储器701的软件程序以及模块,从而执行各种功能应用以及数据处理。存储器701可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储数据(比如音频数据、电话本等)等。此外,存储器701可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
处理器702是计算机设备的控制中心,通过运行或执行存储在存储器701内的软件程序和/或模块,以及调用存储在存储器701内的数据,执行各种功能和处理数据。可选的,处理器702可包括一个或多个处理单元;优选的,处理器702可集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。
在本发明实施例中,该计算机设备所包括的处理器702可以具有前述第一实施例中任一方法步骤所对应的功能。
应该注意的是上述实施例对本发明进行说明而不是对本发明进行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权利要求中的元件或步骤。位于元件之前的单词“一”或“一个”不排除存在多个这样的元件。本发明可以借助于包括有若干不同元件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。
- 还没有人留言评论。精彩留言会获得点赞!