一种基于遗传模糊聚类的系统数据异常检测方法与流程
本发明涉及一种基于遗传模糊聚类的系统数据异常检测方法,属于数据异常检测技术领域。
背景技术:
随着信息技术的高速发展,基于服务的系统平台数据往往在传输过程中可能由于各种各样的原因而造成数据异常。fcm模糊聚类算法常常被应用于数据异常检测领域,然而传统的fcm模糊聚类算法容易陷入局部最优点的问题。为了解决此问题,本发明采用fcm模糊聚类算法与遗传算法结合的异常检测方法应用于系统平台数据异常检测领域,可以解决fcm算法易陷入局部最优点的问题。异常数据集往往是混合属性的特点,在处理这些具有混合属性特点的异常数据集过程中,计算量非常大,本发明针对这一特点,改进了距离测度的计算方法,将计算量大大减少。
技术实现要素:
本发明要解决的技术问题是提供一种基于遗传模糊聚类的系统数据异常检测方法,首先考虑到系统平台提供的数据集往往是具有混合属性的特点,改进了距离测度的计算,并结合遗传算法解决了模糊聚类算法易于陷入局部最优点的问题。
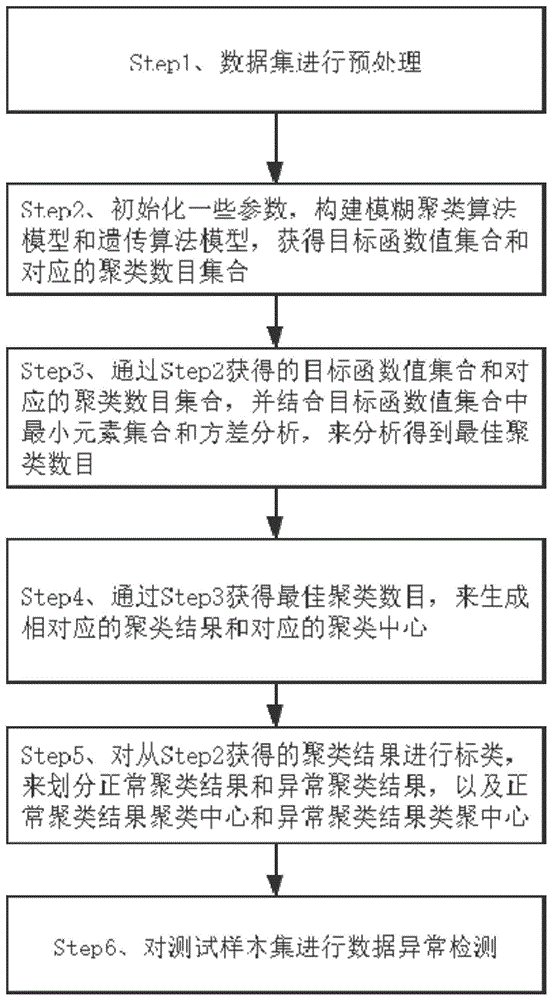
本发明的技术方案是:一种基于遗传模糊聚类的系统数据异常检测方法,具体步骤为:
step1:首先,对系统提供的数据集中所有数据进行标准化处理,然后对标准化处理后的所有数据分别进行随机化处理,再然后将随机化处理后的数据进行划分,最后得到训练样本集tr和测试样本集te。
step2:确定训练样本集tr的最大分类数cmax与最小分类数cmin,组成一个关于最大分类数cmax与最小分类数cmin的集合c={cmin,cmin+1,...,cmax},构建混合属性数据集的模糊聚类模型和遗传算法模型,将最大分类数cmax与最小分类数cmin的集合c传递给这些模型,得到一个关于目标函数值的集合ofv,集合中ofv的每一个值都对应一个聚类数目,将这些聚类数目组成一个集合,设为cn。
step3:通过step2获得的集合ofv和集合cn,结合集合ofv中最小元素集合和方差分析,来分析得到最佳分类数目c*。
step4:将step3中获得的最佳分类数目c*,生成相对应的聚类结果记为c,而ci,i=1,2,...,c*,其中ci表示第i类聚类结果集合,以及相对应的聚类中心pcc,而pcci,i=1,2,...,c*,其中pcci表示第i类中心。
step5:将step4获得的聚类结果c进行标类,标类的目的是在结果中区分出状态正常的聚类和异常的聚类;
区分原则为:
设定一个比例系数η,0<η<1,如果
其中,count(ci)表示聚类结果c中第i类聚类结果集合的数量,count(tr)表示训练样本集的数量。
最终得到的正常聚类结果类记为ncrc,而ncrci,i=1,2,...,in表示正常聚类结果中的第i类,相对应的正常聚类结果类聚类中心记为pncrc,而pncrci,i=1,2,...,in,表示正常聚类结果中的第i类中心。
异常聚类结果类记为acrc,而acrcj,j=1,2,...,jn表示异常聚类结果中的第j类,异常聚类结果类聚类中心pacrc,而pacrcj,j=1,2,...,jn表示异常聚类结果中的第j类中心,且in+jn=c*。
step6:从step6中获得了正常聚类结果类ncrc和异常聚类结果类记为acrc,以及相对应的正常聚类结果类聚类中心pncrc和异常聚类结果类聚类中心pacrc,从而进行数据集的异常检测。
对于按step1预处理后的测试样本集te={x1,x2,…,xn},假设xi为待检测数据,分别计算xi与step5中获得的pncrc和pacrc的距离测度,设与待检测数据xi具有最小距离测度的聚类中心相对应的子类即为其所属聚类。
当待检测数据xi所属聚类子类属于step5中获得的正常聚类结果类ncrc,则为正常数据。
当待检测数据xi所属聚类子类属于step5获得的异常聚类结果类acrc,则为异常数据。
所述step1的具体步骤为:
使用离散标准化,将系统提供的所有数据集中的所有数据x={x1,x2,…,xn}映射到[0,1]之间,
其中,min{x}是系统提供的数据集中最小值,max{x}是系统提供的数据集中最大值,xi'为对每个数据xi标准化后的数据值,然后再对标准化处理后的数据值进行随机化处理,最后将这些数划分成训练样本集tr和测试样本集te。
所述step2的具体步骤为:
通过step1预处理后的数据集tr={x1,x2,…,xi,…,xn}是一组具有混合属性的的数据集,
其中,xi,xj为tr数据集中第i个和第j个样本,dij表示tr数据集中第i个到第j个样本的闵科夫斯基距离,从step2中初始化获得的最大分类数cmax与最小分类数cmin的集合c,需要不断的将集合c中的每个元素传递给隶属度计算函数,以此来探索哪个分类数目最佳。
step2.1:计算隶属度,隶属度函数如下:
其中,uij是样本,xj属于第i类的隶属度矩阵,h为模糊系数;i和j的取值范围为[1,n],n为训练样本集tr的数量,最终可以获得一个隶属度集合u,c(k)表示集合c中的第k个元素。
step2.2:通过step2.1获得的隶属度uij,可以得到它的聚类中心,聚类中心为:
其中,pi为第i类的聚类中心,i的范围为[1,n],n为训练样本集tr的数量,最终可以获得一个聚类中心集合p。
step2.3:混通过step2.1和step2.2分别获得的隶属度uij和聚类中心pi,混合属性数据集的目标函数为:
其中,jh为目标函数值,i的取值范围为[1,n],n为训练样本集tr的数量,最终可以获得一个目标函数集合j。
step2.4:通过目标函数值jh,建立适应度函数,适应度函数如下:
其中,fi为适应度函数返回的值,i的取值范围为[1,n],n为训练样本集tr的数量,最终可以获得一个适应度函数值集合f,ε为足够小的正数,范围在(e-10,e-20)之间。
step2.5:通过step2.4获得的适应度函数值fi,确定选择算子公式如下:
其中,psei为选择算子,i和k的取值范围为[1,n],n为训练样本集tr的数量,最终可以获得一个选择算子集合pse。
step2.6:对从step2.2获得的聚类中心p按照多参数二进制编码方式进行编码。
step2.7:初始化交叉算子pc、变异算子pm以及种群数量pq和一个最大遗传代数mga,对由step2.6获得的已经编码的聚类中心p进行遗传运算,然后将进行过遗传运算的聚类中心p重新代入到step2.3中,然后在重新计算step2.4,获得一个新的适应度函数值集,然后继续通过选择算子pse、交叉算子pc和变异算子pm,进化出下一代新的适应度函数集值。
当这个适应度函数集中的每一个元素值变化不大时,或者遗传代数达到了mga,则停止遗传运算,将得到的最新适应度函数值集所对应的目标函数值集j,目标函数值集j中最小目标函数值添加到目标函数值的集合ofv中,并将对应的分类数目k添加到聚类数目集合cn中,令k=k+1,重复执行step2,直至k=cmax-cmin+1,即为最大分类数cmax与最小分类数cmin的集合c中最后一个元素时停止执行。
所述step3的具体步骤为:
step3.1:获得集合ofv中最小元素集合me=min{ofv},和最小元素集合min{ofv}对应的集合cn中的聚类数目集合scn。
step3.2:如果最小元素集合me的数量只有一个元素,则对应集合scn中的聚类数目也只有一个元素,这个元素即为最佳聚类数目c*;否则执行step3.3,进行方差分析。
step3.3:将集合me设为控制变量,集合scn设为观测变量,进行方差分析,对方差分析结果进行分析,找到显著性差异最大的那组所对应的集合scn元素,即为最佳聚类数目c*。
所述step5的具体步骤为:
step5.1:对从step4中获得的聚类结果c,而ci,i=1,2,3,...,c*,其中ci表示第i类聚类结果集合,按照每一类聚类结果集合数量的大小从进行从大到小排序。
step5.2:令i=1,k=n*η,其中n=count(tr),即为训练样本集总数,k为阈值,表示划分正常聚类和异常聚类的数量的临界点。
step5.3:如果count(ci)>k,则此ci为正常的聚类划分,将ci添加到集合ncrc,将其对应的聚类中心添加到集合pncrc;否则ci为异常的聚类划分,将ci添加到集合acrc,将其对应的聚类中心添加到集合pacrc,执行5.4。
step5.4:若i=i+1,且i≤c*,则执行5.3,否则退出循环。
6所述step6的具体步骤为:
step6.1:分别计算xi与step5中获得的pncrc和pacrc集合中每一个元素的距离测度。
step6.2:比较距离测度大小,可以认为与待检测数据xi具有最小距离测度的聚类中心相对应的子类即为其所属聚类。
step6.3:因此当待检测数据xi所属聚类子类属于step5中获得的正常聚类结果类ncrc,则为正常数据;
当待检测数据xi所属聚类子类属于step5获得的异常聚类结果类acrc,则为异常数据。
本发明的有益效果是:本发明对系统平台数据,使用模糊聚类方法进行分类,并针对系统数据集具有混合属性的特点,改进了距离测度的计算;本发明采用了遗传算法对聚类中心进行遗传运算,解决了模糊聚类算法易于陷入局部最优点的问题;本发明距离测度的数据异常检测算法简单明了,具有很高的检测效率。
附图说明
图1是本发明的步骤流程图;
图2是本发明分类数与适应度函数图。
具体实施方式
下面结合附图和具体实施方式,对本发明作进一步说明。
如图1所示,本发明的技术方案是:一种基于遗传模糊聚类的系统数据异常检测方法,具体步骤为:
step1:首先,对系统提供的数据集中所有数据进行标准化处理,然后对标准化处理后的所有数据分别进行随机化处理,再然后将随机化处理后的数据进行划分,最后得到训练样本集tr和测试样本集te。
step2:确定训练样本集tr的最大分类数cmax与最小分类数cmin,组成一个关于最大分类数cmax与最小分类数cmin的集合c={cmin,cmin+1,...,cmax},构建混合属性数据集的模糊聚类模型和遗传算法模型,将最大分类数cmax与最小分类数cmin的集合c传递给这些模型,得到一个关于目标函数值的集合ofv,集合中ofv的每一个值都对应一个聚类数目,将这些聚类数目组成一个集合,设为cn。
step3:通过step2获得的集合ofv和集合cn,结合集合ofv中最小元素集合和方差分析,来分析得到最佳分类数目c*。
step4:将step3中获得的最佳分类数目c*,生成相对应的聚类结果记为c,而ci,i=1,2,...,c*,其中ci表示第i类聚类结果集合,以及相对应的聚类中心pcc,而pcci,i=1,2,...,c*,其中pcci表示第i类中心。
step5:将step4获得的聚类结果c进行标类,标类的目的是在结果中区分出状态正常的聚类和异常的聚类;
区分原则为:
设定一个比例系数η,0<η<1,如果
其中,count(ci)表示聚类结果c中第i类聚类结果集合的数量,count(tr)表示训练样本集的数量。
最终得到的正常聚类结果类记为ncrc,而ncrci,i=1,2,...,in表示正常聚类结果中的第i类,相对应的正常聚类结果类聚类中心记为pncrc,而pncrci,i=1,2,...,in,表示正常聚类结果中的第i类中心。
异常聚类结果类记为acrc,而acrcj,j=1,2,...,jn表示异常聚类结果中的第j类,异常聚类结果类聚类中心pacrc,而pacrcj,j=1,2,...,jn表示异常聚类结果中的第j类中心,且in+jn=c*。
step6:从step6中获得了正常聚类结果类ncrc和异常聚类结果类记为acrc,以及相对应的正常聚类结果类聚类中心pncrc和异常聚类结果类聚类中心pacrc,从而进行数据集的异常检测。
对于按step1预处理后的测试样本集te={x1,x2,…,xn},假设xi为待检测数据,分别计算xi与step5中获得的pncrc和pacrc的距离测度,设与待检测数据xi具有最小距离测度的聚类中心相对应的子类即为其所属聚类。
当待检测数据xi所属聚类子类属于step5中获得的正常聚类结果类ncrc,则为正常数据。
当待检测数据xi所属聚类子类属于step5获得的异常聚类结果类acrc,则为异常数据。
所述step1的具体步骤为:
使用离散标准化,将系统提供的所有数据集中的所有数据x={x1,x2,…,xn}映射到[0,1]之间,
其中,min{x}是系统提供的数据集中最小值,max{x}是系统提供的数据集中最大值,xi'为对每个数据xi标准化后的数据值,然后再对标准化处理后的数据值进行随机化处理,最后将这些数划分成训练样本集tr和测试样本集te。
所述step2的具体步骤为:
通过step1预处理后的数据集tr={x1,x2,…,xi,…,xn}是一组具有混合属性的的数据集,
其中,xi,xj为tr数据集中第i个和第j个样本,dij表示tr数据集中第i个到第j个样本的闵科夫斯基距离,从step2中初始化获得的最大分类数cmax与最小分类数cmin的集合c,需要不断的将集合c中的每个元素传递给隶属度计算函数,以此来探索哪个分类数目最佳。
step2.1:计算隶属度,隶属度函数如下:
其中,uij是样本,xj属于第i类的隶属度矩阵,h为模糊系数;i和j的取值范围为[1,n],n为训练样本集tr的数量,最终可以获得一个隶属度集合u,c(k)表示集合c中的第k个元素,令k=1,则c(k)为集合c中第一个元素值。
step2.2:通过step2.1获得的隶属度uij,可以得到它的聚类中心,聚类中心为:
其中,pi为第i类的聚类中心,i的范围为[1,n],n为训练样本集tr的数量,最终可以获得一个聚类中心集合p。
step2.3:混通过step2.1和step2.2分别获得的隶属度uij和聚类中心pi,混合属性数据集的目标函数为:
其中,jh为目标函数值,i的取值范围为[1,n],n为训练样本集tr的数量,最终可以获得一个目标函数集合j。
step2.4:通过目标函数值jh,建立适应度函数,适应度函数如下:
其中,fi为适应度函数返回的值,i的取值范围为[1,n],n为训练样本集tr的数量,最终可以获得一个适应度函数值集合f,ε为足够小的正数,范围在(e-10,e-20)之间。
step2.5:通过step2.4获得的适应度函数值fi,确定选择算子公式如下:
其中,psei为选择算子,i和k的取值范围为[1,n],n为训练样本集tr的数量,最终可以获得一个选择算子集合pse。
step2.6:对从step2.2获得的聚类中心p按照多参数二进制编码方式进行编码。
step2.7:初始化交叉算子pc、变异算子pm以及种群数量pq和一个最大遗传代数mga,对由step2.6获得的已经编码的聚类中心p进行遗传运算,然后将进行过遗传运算的聚类中心p重新代入到step2.3中,然后在重新计算step2.4,获得一个新的适应度函数值集,然后继续通过选择算子pse、交叉算子pc和变异算子pm,进化出下一代新的适应度函数集值。
当这个适应度函数集中的每一个元素值变化不大时,或者遗传代数达到了mga,则停止遗传运算,将得到的最新适应度函数值集所对应的目标函数值集j,目标函数值集j中最小目标函数值添加到目标函数值的集合ofv中,并将对应的分类数目k添加到聚类数目集合cn中,令k=k+1,重复执行step2,直至k=cmax-cmin+1,即为最大分类数cmax与最小分类数cmin的集合c中最后一个元素时停止执行。
所述step3的具体步骤为:
step3.1:获得集合ofv中最小元素集合me=min{ofv},和最小元素集合min{ofv}对应的集合cn中的聚类数目集合scn。
step3.2:如果最小元素集合me的数量只有一个元素,则对应集合scn中的聚类数目也只有一个元素,这个元素即为最佳聚类数目c*;否则执行step3.3,进行方差分析。
step3.3:将集合me设为控制变量,集合scn设为观测变量,进行方差分析,对方差分析结果进行分析,找到显著性差异最大的那组所对应的集合scn元素,即为最佳聚类数目c*。
所述step4的具体步骤为:
将step3获得的最佳分类数目c*,传到到step2中的算法流程中去,可以获得它的隶属度,然后通过它的隶属度可以生成相对应的聚类结果,记为c,而ci,i=1,2,...,c*,其中ci表示第i类聚类结果集合,以及相对应的聚类中心pcc,而pcci,i=1,2,...,c*,其中pcci表示第i类中心。
所述step5的具体步骤为:
step5.1:对从step4中获得的聚类结果c,而ci,i=1,2,3,...,c*,其中ci表示第i类聚类结果集合,按照每一类聚类结果集合数量的大小从进行从大到小排序。
step5.2:令i=1,k=n*η,其中n=count(tr),即为训练样本集总数,k为阈值,表示划分正常聚类和异常聚类的数量的临界点。
step5.3:如果count(ci)>k,则此ci为正常的聚类划分,将ci添加到集合ncrc,将其对应的聚类中心添加到集合pncrc;否则ci为异常的聚类划分,将ci添加到集合acrc,将其对应的聚类中心添加到集合pacrc,执行5.4。
step5.4:若i=i+1,且i≤c*,则执行5.3,否则退出循环。
6所述step6的具体步骤为:
step6.1:分别计算xi与step5中获得的pncrc和pacrc集合中每一个元素的距离测度。
step6.2:比较距离测度大小,可以认为与待检测数据xi具有最小距离测度的聚类中心相对应的子类即为其所属聚类。
step6.3:因此当待检测数据xi所属聚类子类属于step5中获得的正常聚类结果类ncrc,则为正常数据;
当待检测数据xi所属聚类子类属于step5获得的异常聚类结果类acrc,则为异常数据。
进一步地,对本申请中的步骤作出如下实例说明:
本发明采用的数据集为谷歌平台提供的“californiahousingdataset”数据集,以下简称chd数据集,本发明先对chd数据集进行随机排序,从此数据集中提取了12000条记录作为训练样本集tr,其中11880条为正常数据包,120条为异常数据包。然后再在此数据集中提起来1200条作为测试样本集te。并选取了该数据集上的9个关键属性进行测试。
在实验开始之前,根据人的经验设定一些初始参数。设定pc取值0.7,pm取值0.1,种群大小pq取值55,最大遗传代数为180,聚类数c范围为[1,20]。在完成上述准备步骤后,按照基于遗传模糊聚类的系统数据异常检测方法步骤进行,得到了最佳分类数和聚类结果。由图2可知,该适应度函数确定的最佳分类数为8。
继续执行算法,保留具有最佳适应度的染色体,直至完成最大遗传代数,得到聚类结果如下:
表1:聚类表
此外,还得出了真正例(tp)、假正例(fp)、假负例(fn)、真负例(tn)。tp代表真实情况为异常数据,检测出来也为异常数据;fp代表真实情况为正常数据,检测出来却为异常数据;fn代表真实情况为异常数据,检测出来却为正常数据;tn代表真实情况为正常数据,检测出来也为正常数据。由tp、fp、fn、tn可以测得准确率(acc)和召回率(rec),acc是指预测正确的结果所占的百分比,rec代表能够正确识别所有异常数据的百分比。其计算公式如下:
acc=(tp+tn)/(tp+tn+fp+fn)
rec=tp/(tp+fn)
最后得到一张具有准确率和召回率的聚类表如下:
表2:具有准确率和召回率的聚类表
由表2可以看出,其准确率和召回率都很高,充分说明本发明可靠性非常高。
本发明的工作原理是:首先对系统平台采集到的数据集进行离散标准化处理,将离散标准化处理后的数据集随机化并划分成训练样本集和测试样本集。对测试样本集进行模糊聚类处理,对模糊处理后的得到的聚类中心进行遗传运算。然后得到一个最佳分类数目和对应的聚类结果集。然后对聚类结果集进行标类,获得正常数据集的各个聚类中心和异常数据集的各个聚类中心。再然后计算测试样本集中的每个样本与标类后的各个数据集聚类中心的距离,可以认为与测试样本集中的每个样本具有最小距离测度的子类即为其所属聚类,从而可以测试出测试样本集中的异常数据。
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!