流地址生成的制作方法
背景技术:
现代数字信号处理器(dsp)面临多重挑战。工作量不断增加,需要增加带宽。片上系统(soc)的大小和复杂性不断增长。存储系统延迟严重影响某些类别的算法。随着晶体管变小,存储器和寄存器的可靠性降低。随着软件堆栈变大,潜在的交互和错误的数量也随之变大。甚至电路板上的导电迹线和半导体管芯上的导电路径也成为越来越大的挑战。宽总线难以路由。通过导体的信号传播速度继续滞后于晶体管速度。路由拥塞是一个持续的挑战。
在诸如排序、快速傅立叶变换(fft)、视频压缩和计算机视觉的许多dsp算法中,数据是按块处理的。因此,在多个维度中生成读取和写入访问模式的能力有助于加速这些算法。但是,多维地址计算很复杂,并且通常需要几个指令和执行单元来执行。
技术实现要素:
本文描述的一个示例实施方式包括数字信号处理器。该数字信号处理器包括具有专用硬件的流地址生成器,该专用硬件被配置为生成多个偏移量以对包括多个元素的流数据进行寻址。多个偏移量中的每一个对应于多个元素中的相应一个。多个元素中的每一个的地址是与基地址组合的多个偏移量中的相应一个。本文描述的另一示例实施方式包括数字信号处理器系统。该数字信号处理器系统包括缓存器和数字信号处理器。该数字信号处理器包括中央处理单元(cpu)。该cpu包括具有专用硬件的流地址生成器,该专用硬件被配置为生成多个偏移量以对用于写入缓存器或从缓存器读取的流数据进行寻址。该流数据包括多个元素,并且多个偏移中的每一个对应于多个元素中的相应一个。
本文描述的另一示例实施方式包括一种操作数字信号处理器系统的方法,该数字信号处理器系统被配置用于对具有多个元素的流数据进行寻址。该方法包括使用第一组执行单元接收流数据并处理流数据。该方法进一步包括通过使用对于处理流数据的步骤不可用的执行单元,生成与多个元素相对应的多个偏移量。该方法进一步包括通过组合多个偏移中的每一个与基地址来确定地址。
附图说明
为了更详细地描述各种示例,现在将参考附图,其中:
图1示出单核dsp;
图2示出图1的单核dsp的更多细节;
图3示出具有流地址生成器的dsp;
图4示出流地址生成器所使用的示例性逻辑;
图5示出示例性4维存储器模式;
图6示出示例性流地址配置寄存器;
图7示出图7的流地址配置寄存器的标志字段的示例性子字段定义;
图8示出示例性流地址计数寄存器;
图9示出流地址生成器和相关电路系统的示例性硬件实施方式;和
图10a和图10b示出流地址生成逻辑的示例性硬件实施方式。
具体实施方式
表述方式“基于”是指“至少部分基于”。因此,如果x基于y,则x可以是y和任何数量的其他因子的函数。
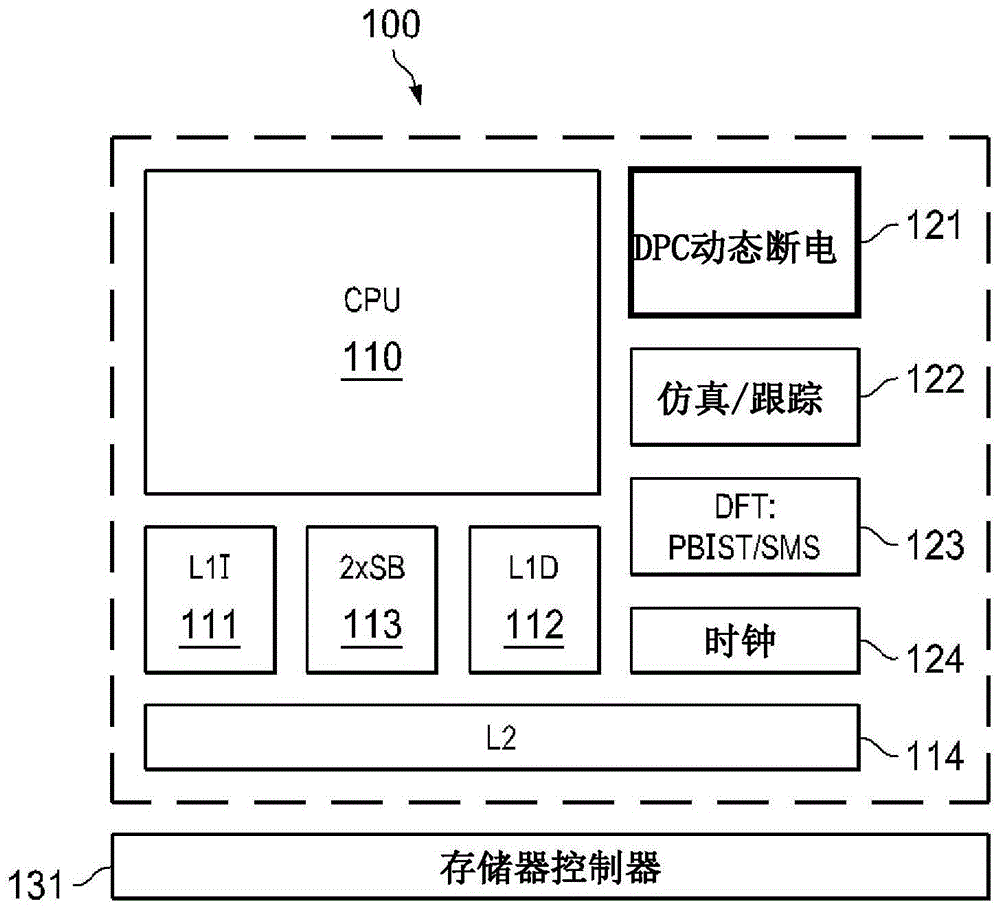
dsp通常具有64位总线。最近,一些dsp具有512位总线,例如texasinstrumentsc7x系列的dsp。示例性512位dsp是图1所示的单核dsp100,并且在美国专利第9,606,803号中被详细描述,该专利通过引用整体并入本文。dsp100包括矢量cpu110,该矢量cpu110耦合到单独的一级指令缓存器(l1i)111和一级数据缓存器(l1d)112。该dsp进一步包括二级缓存器(l2)114,该二级缓存器可以是随机存取存储器(ram)。矢量cpu110、一级指令缓存器(l1i)111、一级数据缓存器(l1d)112和二级组合式指令/数据缓存器(l2)114可以形成在单个集成电路上。
该单个集成电路还可以包括辅助电路,诸如功率控制电路121、仿真/跟踪电路122、测试设计(dft)可编程内置自测(pbist)电路123和时钟电路124。在cpu110外部并且可能集成在单个集成电路100中的是存储控制器131。
图2示出具有矢量cpu110的dsp100的至少一部分的框图。如图2所示,矢量cpu110包括指令提取单元141、指令分派单元142、指令解码单元143和控制寄存器144。矢量cpu110进一步包括用于接收和处理来自一级数据缓存器(l1d)112的64位标量数据的64位寄存器文件150和64位功能单元151。矢量cpu110还包括用于接收和处理来自一级数据缓存器(l1d)112和/或来自流引擎113的512位矢量数据的512位寄存器文件160和512位功能单元161。dsp100还包括二级组合式指令/数据缓存器(l2)114,该二级组合式指令/数据缓存器发送和接收来自一级数据缓存器(l1d)112的数据,并发送数据到流引擎113。矢量cpu110还可以包括调试单元171和中断逻辑单元172。
如美国专利第9,606,803号(该专利通过引用整体并入本文)中所述,诸如流引擎113的流引擎可以增加cpu的可用带宽,减少缓存器错失的数量,减少标量操作并且允许多维存储器访问。虽然矢量cpu110具有显著增加的带宽以用于消耗数据,并且至少部分由于流引擎113而可以适应多维存储器访问,但是矢量cpu110缺少类似增加的带宽以用于从cpu写入流数据,导致流操作的瓶颈。此外,写入流数据所需的地址计算数量消耗其他操作所需的大量执行单元。实际上,用于多维数据的地址生成可能针对每个维度需要一个功能单元,这可能是比cpu具有的功能单元更多的功能单元。
下面描述的示例通过具有专用硬件而至少部分地解决这些问题中的至少一些,该专用硬件自动生成流地址作为偏移量并且允许多维加载或存储访问被完全流水线化。
图3示出dsp300的至少一部分以及其与二级组合式指令/数据缓存器(l2)314的交互的框图。如图3所示,矢量cpu310包括指令提取单元341、指令分派单元342、指令解码单元343和控制寄存器344。矢量cpu310进一步包括用于接收和处理来自一级数据缓存器(l1d)312的64位标量数据的64位寄存器文件350和64位功能单元351。矢量cpu310还包括用于接收和处理来自一级数据缓存器(l1d)312和/或来自流引擎313的512位矢量数据的512位寄存器文件360和512位功能单元361。dsp300还包括二级组合式指令/数据缓存器(l2)314,该二级组合式指令/数据缓存器发送和接收来自一级数据缓存器(l1d)312的数据并发送数据到流引擎313。矢量cpu310还可以包括调试单元371和中断逻辑单元372。
dsp300与dsp100(图1和图2)的主要区别在于dsp300的cpu310包括流地址生成器sag0380、sag1381、sag2382、sag3383。尽管图3示出了cpu310具有四个流地址生成器(流地址生成器sag0380、sag1381、sag2382、sag3383),但cpu310可以包括一个、两个、三个或四个流地址生成器,并且在一些其他示例中可以包括多于四个流地址生成器。尽管流引擎313的地址计算逻辑执行多维地址计算以将流数据提供到cpu310中,但是流地址生成器sag0380、sag1381、sag2382、sag3383执行多维地址计算以用作用于将指令存储在cpu310中的地址的偏移量。可替代地,也可以使用sag0380、sag1381、sag2382、sag3383中的一个或多个代替流引擎313或与流引擎313结合以生成用于加载指令的地址。
由流地址生成器380、381、382、383生成的偏移量被分别存储在流地址偏移寄存器sa0390、sa1391、sa2392和sa3393中。每个流地址生成器sag0380、sag1381、sag2382、sag3383包括相应的流地址控制寄存器stracr0384、stracr1385、stracr2386、stracr3387和相应的流地址计数寄存器stracntr0394、stracntr1395、stracntr2396、stracntr3397。如下文更详细说明的,流地址控制寄存器stracr0384、stracr1385、stracr2386、stracr3387包含相应的流地址生成器的配置信息,并且流地址计数寄存器stracntr0394、stracntr1395、stracntr2396、stracntr3397存储由相应的流地址生成器使用的运行时间信息。
当使用流地址生成器时,例如通过将基值与由流地址生成器生成的偏移量相加来计算完整地址。流地址生成器sag0-sag3支持正向线性流的地址计算模式,并且从偏移0开始。本文描述的寻址示例使用多级嵌套循环,以使用少量参数来迭代地生成用于多维数据的偏移量。程序通过流地址偏移寄存器sa0390、sa1391、sa2392和sa3393访问这些偏移量。
表1列出多维流的参数。
表1
图4示出由流地址生成器使用的用于计算6级正向循环的偏移量的逻辑。veclen指定每次提取的元素的数目。循环级的迭代计数icnt0、icnt1、icnt2、icnt3、icnt4、icnt5指示该级重复的次数。维度dim0、dim1、dim2、dim3、dim4、dim5指示相应循环级的连续迭代的指针位置之间的距离。
在图4的示例逻辑中,最内部的循环40(被称为循环0)计算来自存储器的物理上相邻的元素的偏移量。因为元素是相邻的并且它们之间没有空格,所以循环0的维度始终是1个元素,因此没有为循环0定义维度(dim)参数。指针本身以连续的递增顺序从一个元素移动到另一个元素。在内部循环(41、42、43、44、45)之外的每个级中,基于该循环级维度(dim)的大小,循环将指针移动到新位置。最内部的循环40还包括用于矢量断言的逻辑,其在题为“systemandmethodforpredicationhandling”的美国专利申请(以下称为“predication申请”)中被详细描述,该申请与本申请同时提交并通过引用并入本文。
图5示出4维存储器地址模式的示例。在图5的示例中,寻址参数具有以下值:
icnt0=8
icnt1=4
icnt2=3
icnt3=3
dim1=0x080
dim2=0x400
dim3=0x230
如图5所示,最内部的循环(循环0)具有icnt0=8,并被示出为每一行具有8个元素。由于隐式维度是1个元素,因此每行中的字节是相邻的。下一个循环(循环1)的icnt1=4,并被示出为4组的循环0行,每行由dim1隔开。下一个循环(循环2)的icnt2=3,并被示出为来自循环0和循环1的4行的三组,每组由dim2隔开。最后一个循环(循环3)的icnt3=3,并被示出为循环0至循环2中的3个组,每组由dim3隔开。
cpu310通过少量指令和专用寄存器使流地址生成器暴露于程序。
流开启指令saopen为指定的流地址生成器380、381、382、383开始新的地址生成序列。如在题为“systemandmethodforaddressingdatainmemory”的美国专利申请中更详细地讨论的(该专利与此同时提交并通过引用并入本文),一旦执行saopen指令,具有正确寻址模式的任何加载或存储指令(下面讨论)和偏移寄存器字段值0-3将使用由相应的流地址生成器sag0、sag1、sag2、sag3计算的偏移值。
saopen指令的操作数例如是包含配置模板信息和流标识符的寄存器值。在执行saopen后,将寄存器值复制到相应的流地址控制寄存器中以用作寻址模板,相对应的strcntr寄存器的icnt字段被初始化。
流关闭指令saclose明显地关闭给定流的指定流地址生成操作。执行saclose将相应的stracr寄存器和stracntr寄存器重置为其默认值。流关闭后,流地址生成器不能用于寻址。
流断开指令sabrk允许从流内的循环嵌套级提早退出。发出流断开指令sabrk使流地址生成器跳过相应数量的循环级的所有剩余元素。“sabrk5,san”将结束流,但不关闭流,其中“5”表示从循环5断开,“san”表示流地址偏移寄存器。
流地址控制寄存器stracr0384、stracr1385、stracr2386、stracr3387包含诸如元素计数、循环维度、访问长度和其他标志的参数,以开始进行流地址计算。
图6示出示例性流地址配置寄存器。表2示出流地址配置寄存器的字段定义的示例。
表2
上面描述了表2中的字段。dec_dim1_width和decdim2_width帮助定义任何竖直条带挖掘,其在predication申请中被更详细地描述。在2019年5月23日提交的以下申请中也讨论了条带挖掘,每个申请通过引用整体并入本文:题为“insertingpredefinedpadvaluesintoastreamofvectors”的申请号16/420,480、题为“insertingnullvectorsintoastreamofvectors”的申请号16/420,467、题为“two-dimensionalzeropaddinginastreamofmatrixelements”的申请号16/420,457、题为“one-dimensionalzeropaddinginastreamofmatrixelements”的申请号16/420,447。
图7示出流地址配置寄存器的标志字段的子字段定义。
流地址计数寄存器stracntr0394、stracntr1395、stracntr2396、stracntr3397包含所有循环级的中间元素计数。当一个循环的元素计数cnt变为零时,使用下一个循环维度来计算下一个循环的元素的地址。图8示出示例性流地址计数寄存器。
执行straopen指令将stracntr中的cnt字段设置为stracr的icnt字段中包含的值。在流被开启时,不允许对关联的stracr寄存器和stracntr寄存器进行功能访问。
流加载指令或流存储指令是使用由流地址生成器生成的偏移量的常规加载指令或存储指令。该地址是偏移量与基地址的组合。与常规加载指令和存储指令相似,基地址可以来自全局标量寄存器或来自.d单元本地寄存器。可以与流加载指令或流存储指令一起使用的示例性寻址模式在题为“systemandmethodforaddressingdatainmemory”的美国专利申请中进行了详细描述,该申请与此同时提交并通过引用并入本文。在默认情况下,读取流地址偏移寄存器sa0390、sa1391、sa2392和sa3393不推进偏移计算,并且可以根据需要以相同的值多次重新读取该寄存器。但是,例如图4所示,可以使用编码方案,这些方案还将偏移计算推进一个元素长度,从而启动流地址生成逻辑。
图9示出流地址生成器sag0380和sag1381的示例性硬件实施方式。尽管由于空间限制在图9中未示出流地址生成器sag2382和sag3383,但是图9确实考虑了存在这些附加的流地址生成器。流地址生成器sag2382和sag3383可以以类似于图9所示的流地址生成器sag0380和sag1381的方式来实现。
如图9所示,包含在saopen指令中的配置信息被存储在寄存器文件160中,并且被提供给相应的流地址控制寄存器stracr0384、stracr1385,流地址控制寄存器stracr0384和stracr1385向相应的流地址生成逻辑70和71提供必要的信息,并且向相应的流地址计数寄存器stracntr0394、stracntr1395提供必要的信息。流地址生成逻辑70、71是例如图4所示的偏移生成逻辑的硬件实施方式。流地址计数寄存器stracntr0394、stracntr1395接收信息并将信息提供给流地址生成逻辑70、71。流地址生成器sag0380和sag1381中的每一个的输出是偏移量,该偏移量被存储在流地址偏移寄存器sa0390和sa1391中,然后被发送到复用器电路系统64以用于路由到功能单元351(图3)中的合适的功能单元d1、d2。取决于寻址模式框66、67的确定,可以将这些偏移量存储为相关指令62、63中的操作数。
如在predication申请中更详细地描述的,流地址生成器sag0380和sag1381中的每一个也可以生成一个断言(predicate),用于存储在相应的断言流地址寄存器60、61中,然后将其扩展为68、69中的字节使能。
图10a和图10b示出来自图9的流地址生成逻辑70和71的示例性硬件实施方式。在框801中,相应的流地址控制寄存器(例如stracr0384、stracr1385)向相应的流地址生成逻辑70和71(在809处)提供必要的信息,并且向相应的流地址计数寄存器(例如,stracntr0394、stracntr1395)(在808处)提供必要的信息。框802是最内部的循环40的示例性实施方式。框803迭代其他循环41、42、43、44、45(图4)。框805在每个循环41、42、43、44、45(图4)结束时计算当前偏移量。在806处生成偏移量,并且在框807中将偏移量存储在流地址偏移寄存器(例如,sa0390和sa1391)中。
为了启动流地址生成逻辑,加载指令或存储指令可以指示偏移量将被推进。例如,加载指令或存储指令可以包括“[sa0++]”作为操作数,其告诉流地址生成器使用流地址生成器寄存器sa0的值作为偏移量,然后将偏移量推进一个元素大小。在括号内放置“++”表示仅推进偏移量,而不推进基地址。因此,相同的基地址可以与推进的偏移量一起使用以对多维数据进行寻址。
元素大小基于使用偏移量的加载指令或存储指令中的数据的大小。被访问的元素的数量由流地址配置寄存器(stracr.veclen)的veclen字段指定,而与加载指令或存储指令所指定的访问大小无关。本文所述的示例性流地址生成器通过在专用硬件中执行流数据的地址生成来提高地址生成的性能和效率。地址生成与数据处理分开。本文描述的流地址生成器的示例还可以使用具有相同偏移量和不同元素大小的多个基地址。尽管本文描述的示例性流地址生成器包括用于存储由各个流地址生成器生成的偏移量的流地址偏移寄存器sa0390、sa1391、sa2392和sa3393,但是偏移量可以由流地址生成器输出。
在权利要求的范围内,可以对所描述的实施例进行修改,并且其他实施例也是可能的。
- 还没有人留言评论。精彩留言会获得点赞!