基于DBSCAN算法的互联网金融欺诈行为检测方法与流程
基于dbscan算法的互联网金融欺诈行为检测方法
技术领域
[0001]
本发明涉及互联网金融行业的风控技术领域,特别涉及基于dbscan算法的互联网金融欺诈行为检测方法。
背景技术:
[0002]
传统反欺诈检测方法主要是依赖先验知识的制定基于预先定义的反欺诈规则,面对日益变化的欺诈方式,该做法无法及时检测出规则外的欺诈行为,而造成高达数千亿的损失。针对该问题,基于聚类算法构建正常行为模型的异常检测技术被广泛采用。
[0003]
现有技术中,不同的聚类算法具有不同的特点,基于划分的k-means算法需要知道正常样本构成的类数,事先人为指定聚簇数目和初始质心,而基于层次的birch算法虽然不用指定正常样本的类数,但仅识别球形簇,并且k-means, birch聚类算法一般只适用于凸样本集。
[0004]
相比k-means,birch算法对于簇的数量及形状的要求,基于密度的dbscan (density-based spatial clustering of applications with noise),具有噪声的基于密度的聚类方法不需要指定簇的数目,能够发现任意数量和形状的簇,解决了异常检测中正常行为模型的类数及所构成的簇形状不确定问题,且适用于非凸样本集。鉴于真实互联网金融的申请正常行为数据具有多样化即类数不易确定且不同行为规律及其构成簇的形状不同的特点,dbscan算法成为互联网金融申请的异常检测的优先选择算法。
技术实现要素:
[0005]
为了解决上述技术问题,本发明中披露了基于dbscan算法的互联网金融欺诈行为检测方法,本发明的技术方案是这样实施的:
[0006]
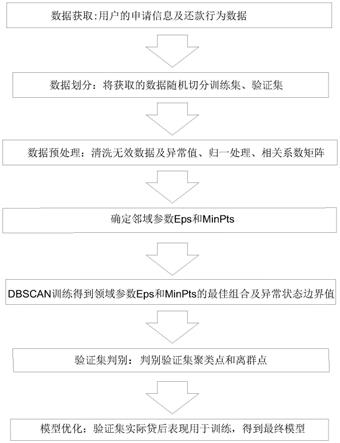
基于dbscan算法的互联网金融欺诈行为检测方法,其特征在于,包括以下步骤:步骤一:数据获取及划分:采集已成功放款的用户的申请信息及还款行为数据,包括客户端上客户申请提现操作埋点数据及贷后表现行为数据,并随机切分训练集及验证集;步骤二:数据预处理:对采集到的数据进行预处理,包括清洗无效数据及异常值、归一化处理、生成相关系数矩阵的数据集;步骤三,确定邻域参数:确定聚类半径eps和每一个聚类中样本的最小数目minpts;步骤四:dbscan训练及验证机判别:将经过数据预处理的训练集放入到 dbscan聚类算法中训练,遍历样本最大集,统计正常运行数据簇的数据量k 和分类个数m,通过观察k和m值对minpts的敏感性,确定参数eps和minpts 数值的可选范围,并进一步将该区域网格细化,最终确定邻域参数eps和minpts 最佳组合;根据最佳组合的领域参数eps和minpts求解正常数据样本的相对误差最大值作为异常状态边界的判定值,利用异常状态边界值来判别验证集的聚类点和离群点;步骤五:模型优化:根据上述对验证集判别的离群程度及实际贷后表现对比分析,基于分析结果,重复步骤三、步骤四再次迭代得到dbscan 模型。
[0007]
优选地,步骤二中所述的归一化处理是采用离差标准化的方法,使得数据均落在
[0,1]区间内。
[0008]
优选地,步骤三中所述的确定聚类半径eps包括计算得到每个数据的k-距离并对k-距离进行统计得到曲线图,根据所述曲线图明显变化的位置对应的距离做为聚类半径eps的取值;所述k-距离是指数据中的每个坐标点到数据中除这个点以外的所有点的距离。
[0009]
优选地,在步骤三中,所述每一个聚类中样本的最小数目minpts确定包括:其中,p
i
为点i的eps区域内的点的个数,n为数据集中的点的个数,所述minpts≥dim+1,所述dim表示待聚类数据的维度。
[0010]
优选地,步骤四中所述dbscan聚类算法包括:以相关系数作为距离度量方式,对样本数据中的每个点p的eps邻域进行搜索并形成簇,当样本数据中的点p的eps邻域包含的样本数据点个数满足|n
ε
(x
p
)|≥minpts,则建立以对象点p为核心对象的簇,否则按照离群或边缘点处理,之后基于dbscan算法不断的迭代聚集核心对象直接密度可达的所有对象点,当没有新对象点添加到任何簇时,聚类过程结束。
[0011]
实施本发明技术方案,有以下有益效果:
[0012]
(1)本发明将dbscan算法用于互联网金融欺诈行为检测,dbscan算法能够把数据集的高密度与低密度区域进行区分,根据聚类结果判断异常点,从而提高了本发明了互联网金融申请欺诈行为的检测识别的通用性和准确性。
[0013]
(2)本发明对采集到的数据进行了标准化处理,使聚类结果更加准确,提高了互联网金融申请欺诈行为的检测识别的准确性。
[0014]
(3)本发明采用相关系数代替欧式距离作为dbscan算法中的距离度量方式,由于相关系数被限定在-1与1之间,聚类密度对聚类半径eps的敏感性大大降低,能够更好的区分出正常行为和可疑行为,解决了传统的采用欧氏距离作为距离度量方式的传统dbscan算法难以有效区分出申请贷款正常行为与可疑行为的问题。
附图说明
[0015]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一种实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0016]
图1为本发明流程图。
具体实施方式
[0017]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0018]
基于dbscan算法的互联网金融欺诈行为检测方法,结合图1所示,包括以下步骤:步骤一:数据获取及划分:采集已成功放款的用户的申请信息及还款行为数据,包括客户端上客户申请提现操作埋点数据及贷后表现行为数据,并随机切分训练集及验证集;步骤二:
数据预处理:对采集到的数据进行预处理,包括清洗无效数据及异常值、归一化处理、生成相关系数矩阵的数据集;步骤三,确定邻域参数:确定聚类半径eps和每一个聚类中样本的最小数目minpts;步骤四:dbscan训练及验证机判别:将经过数据预处理的训练集放入到dbscan聚类算法中训练,遍历样本最大集,统计正常运行数据簇的数据量k和分类个数m,通过观察k和m值对minpts的敏感性,确定参数eps和 minpts数值的可选范围,并进一步将该区域网格细化,最终确定邻域参数eps 和minpts最佳组合;根据最佳组合的领域参数eps和minpts求解正常数据样本的相对误差最大值作为异常状态边界的判定值,利用异常状态边界值来判别验证集的聚类点和离群点;步骤五:模型优化:根据上述对验证集判别的离群程度及实际贷后表现对比分析,基于分析结果,重复步骤三、步骤四再次迭代得到dbscan模型
[0019]
在该实施方式中,所述归一化处理公式如下:设数据集x
i
={x
i1
,x
i2
....,x
in
},共有n个属性,则归一化后的值为:
[0020][0021]
式中,和分别为x
i
中的最大值和最小值。
[0022]
所述生成相关系数矩阵的数据集公式如下:设x1,x2,x3...x
n
是一个n维随机变量,则任意x
i
与x
j
的相关系数为:
[0023][0024]
式中:i=1,2,...n;j=1,2,...n;则以ρ
ij
为元素的n阶矩阵称为该维随机向量的相关系数矩阵r为:
[0025][0026]
在该实施方式中,步骤一中采集到的数据特征要能够反映申请用户还款能力与还款意愿,包括在申请页面上填写的个人及家庭状态、工作及收入水平等传统数据,在政策和条件允许下,可获取经过客户授权的第三方数据,包括身份核验、app行为特征、第三方支付等数据。
[0027]
在该实施方式中,步骤四中所述dbscan聚类算法包括:以相关系数作为距离度量方式,对样本数据中的每个点p的eps邻域进行搜索并形成簇,当样本数据中的点p的eps邻域包含的样本数据点个数满足|n
ε
(x
p
)|≥minpts,则建立以对象点p为核心对象的簇,否则按照离群或边缘点处理,之后基于dbscan 算法不断的迭代聚集核心对象直接密度可达的所有对象点,当没有新对象点添加到任何簇时,聚类过程结束。
[0028]
在一种优选的实施方式中,结合图1所示,步骤二中所述的归一化处理是采用离差标准化的方法,使得数据均落在[0,1]区间内,避免了放大某些数量级较大的值的影响,从
而使聚类结果更加准确。
[0029]
在一种优选的实施方式中,结合图1所示,步骤三中所述的确定聚类半径 eps包括计算得到每个数据的k-距离并对k-距离进行统计得到曲线图,根据所述曲线图明显变化的位置对应的距离做为聚类半径eps的取值;所述k-距离是指数据中的每个坐标点到数据中除这个点以外的所有点的距离;步骤三中所述每一个聚类中样本的最小数目minpts确定包括:其中,p
i
为点i 的eps区域内的点的个数,n为数据集中的点的个数,所述minpts≥dim+1,所述dim表示待聚类数据的维度。
[0030]
需要指出的是,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1