一种航班点评的细粒度情感分类系统的制作方法
本发明涉及自然语言处理领域,尤其涉及一种航班点评的细粒度情感分类系统。
背景技术:
情感分析是自然语言处理领域的重要问题之一,旨在利用自然语言处理和文本挖掘技术,对带有情感色彩的主观性文本进行分析、处理和抽取的过程。其中,文本的情感分类是情感分析的一项核心任务,其目标是对给定文本的情感极性进行正确分类。文本的情感分类任务主要可分为两大类,句子级别的情感分类和细粒度的情感分类。句子级别的情感分类旨在对一个句子的情感极性进行分类,而细粒度的情感分类旨在对一个句子中提及的不同对象的情感极性进行分类。例如:“这家餐厅的服务不好,但是菜做的不错。”这句话提及了两个对象,服务和餐食,他们具有相反的情感极性,细粒度的情感分类能够分别判断“服务”和“餐食”两个对象的情感极性,但是句子级别情感分类无法做到这一点。
显然,在实际场景下,一个文本或句子中包含多个评论对象,并且这些评论对象的情感极性各不相同,是十分常见的现象。尤其在航空领域的一些app中,海量的用户对自己乘坐的航班进行了点评,并且点评的内容一般涉及多个方面,包括飞行是否平稳,服务质量,餐食情况等。细粒度的情感分析能够有效、全面地捕捉用户对于航班各方面服务的满意度,对航空公司发现问题,针对性地提高自身的服务质量,有积极的导向作用。因此,自动地对海量点评数据进行细粒度的情感分类,提取出用户对航班各方面的满意度,日益成为各大航空公司的迫切需求。
随着大数据驱动下标注更完整的数据集涌现以及应用场景的丰富,深度学习相关技术得以迅速发展,日益成为自然语言处理任务中的主流方法。深度学习技术相较于传统的机器学习或情感词典方法,不需要复杂的特征工程,可以大大降低人工工作量和工作时间,同时具有准确率高、完成机械工作效果好、避免隐私泄露等优势。
但现实中,一方面,现存的情感分类工作大部分以文本或句子为单位,旨在对文本或句子的整体情感极性进行分类,这些工作已经无法满足航空领域最新需求。对于情感分类而言,航空领域的最新需求包括对航班点评数据进行自动地细粒度情感分类,但目前在航空领域还没有能进行细粒度情感分析的相关系统。另一方面,航空领域由于数据标注的成本较高,可获得标注数据较少,需要进行情感分析的对象较多,这造成了训练数据不足以及类别不平衡等问题。因此,开发一个航空领域的具有较高准确率的细粒度情感分类系统是一项迫切、具有挑战性的新工作。
技术实现要素:
本发明技术方案旨在实现一种航班点评的细粒度情感分类系统,系统逻辑架构上包括训练路径和测试路径两个逻辑路径,其中所述测试路径依次包括用户输入界面、数据预处理模块、情感分类模型、分类结果输出模块,所述训练路径包括数据增强模块和所述数据预处理模块;
所述训练路径输入数据为已经得到标注的语句数据,通过所述数据增强模块处理后,得到训练样本,所述训练样本经过所述数据预处理模块处理后,得到训练数据,进而输入所述情感分类模型进行训练;
所述测试路径为所述情感分类模型经过训练后的对外输入输出路径,具体地:用户输入界面将待测语句输入,经过所述数据预处理模块处理后得到待测数据,通过应用程序接口输入所述情感分类模型进行预测,之后通过所述分类结果输出模块输出分类结果。
所述数据预处理模块包括数据清洗步骤、分词处理和去停用词处理步骤,其中,所述数据清洗步骤处理方法包括:合并类别、清除表情符号、删除乱码符号、删除连续的重复标点、删除空白句子、将繁体字转化为简体字,其中,所述合并类别方法为对随机采样部分数据进行分析,将意思比较相近、没有细分必要的评论对象的类别进行合并;所述分词处理和去停用词处理步骤中,所述分词处理使用两种开源的分词工具,结巴分词器和bert中文分词器,并引入航空领域词典,用以辅助结巴分词器,所述去停用词处理步骤根据百度的停用词表,删除句子中的停用词。
所述情感分类模型首先对进行预处理后的句子在输入模型之前将句子中的词转化为对应的词向量表示,转化过程通过预训练的词向量模型和预训练的bert模型分别实现,进而利用bilstm模型获取与各个评论对象的情感要素相关的上下文信息,并设计一种基于评论对象的注意力机制,为每个预先定义的评论对象计算其对应的分类向量,最终,通过多个softmax分类器,根据分类向量,将每个评论对象分为积极、消极、中性、未提及四类。
所述预训练的词向量模型结构为:每个需要判断的类别设置embedding,所述类别包括:服务、餐食、准点、环境,通过所述bilstm模型获取embedding后的上下文信息输入所述基于评论对象的注意力机制,并将得到结果输入所述softmax分类器,得到分类结果,所述分类结果以-1代表消极、1代表积极、0代表一般、-2代表未提及。
所述预训练的bert模型实现结构为:每个需要判断的类别设置embedding,所述类别包括:服务、餐食、准点、环境,通过bert模型获取embedding后的上下文信息输入所述基于评论对象的注意力机制,并将得到结果输入所述softmax分类器,得到分类结果,所述分类结果以-1代表消极、1代表积极、0代表一般、-2代表未提及。
所述基于评论对象的注意力机制的具体实现方式为:接收bilstm模型的数据后,为每个预先定义的评论对象计算其对应的分类向量,对某类别的实现过程为通过每个词的embedding分别与每个需要判断的类别的embedding求张量点积后输入softmax函数,之后对函数的输出值分别与所述类别的embedding求张量积,之后对各个结果求和,得到输出结果,过程会对所有类别重复进行并分别输出其结果。
所述数据增强模块实现方法为参考eda算法并结合回译的数据增强策略,具体地,每次对每个句子随机采用5种策略中的一种,所述5种增强策略包括:同义词替换,从文本中随机选取出若干个非停用词的单词,利用同义词将其替换;随机插入,从文本中随机找出一个非停用词的单词,获取其同义词,并将该同义词插入到句子中的随机位置,重复若干次;随机交换,从文本中随机选择两个单词进行位置交换,重复若干次;随机删除,以某个固定概率从句中移除单词,考虑到数据集的文本中含有用标点符号隔开的分句,而跨分句进行的随机交换通常会对语义有较大改变,所以在进行随机交换时首先将文本按中英文全部标点符号分隔为分句列表,此后从分句列表中随机选取一个单词数大于1的分句进行随机交换,重复若干次;数据回译,即使用翻译接口将中文翻译为其他语言后,再将输出重新翻译为中文。数据回译可以在保证语义在最大限度一致的情况下更改用词和语言顺序,增加数据的多样性和数据量。
技术效果:
本发明旨在设计并实现一个能够应用于航空领域的点评数据的细粒度情感分类系统,基于深度学习模型的细粒度情感分析系统,其核心是一个基于注意力机制的深度分类模型,该模型可以自动抽取出航班点评数据中的评论对象,并对评论对象的情感极性进行分类。同时,本发明还实现了一种针对航班点评的数据扩充方法,可以有效地缓解训练数据不足以及数据不平衡的问题,提高了模型的分类准确率以及泛化性。基于上述的模型,使得系统能够最大程度地适应航空领域数据的特点,为用户提供较高准确率的分类输出。
附图说明
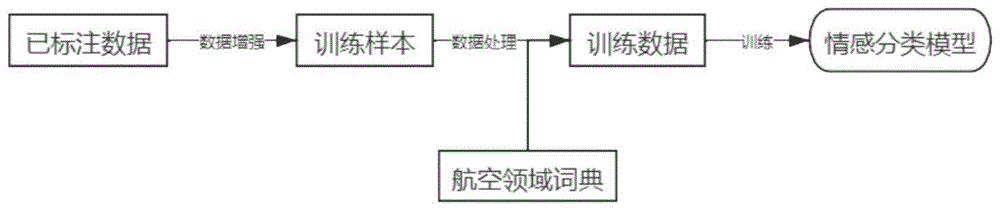
图1:模型的训练流程
图2:模型的测试流程
图3:细粒度情感分析系统整体流程
图4:预训练的词向量模型结构
图5:预训练的bert模型结构
图6:attentionpooling结构
具体实施方式
为了实现目标系统,本发明设计并实现了一个基于注意力机制的深度学习分类模型,用以满足能够对点评数据自动地进行细粒度情感分类的需求。在数据方面,为了解决数据量少、类别数不平衡的问题,本发明还实现一种数据增强的方法,利用已有的标注数据,对训练数据集进行了扩充。模型的训练和测试流程分别如图1和图2所示,模型的总流程如图3所示。
具体地,本发明实现了一种航班点评的细粒度情感分类系统,系统逻辑架构上包括训练路径和测试路径两个逻辑路径,其中所述测试路径依次包括用户输入界面、数据预处理模块、情感分类模型、分类结果输出模块,所述训练路径包括数据增强模块和所述数据预处理模块;
所述训练路径输入数据为已经得到标注的语句数据,通过所述数据增强模块处理后,得到训练样本,所述训练样本经过所述数据预处理模块处理后,得到训练数据,进而输入所述情感分类模型进行训练;
所述测试路径为所述情感分类模型经过训练后的对外输入输出路径,具体地:用户输入界面将待测语句输入,经过所述数据预处理模块处理后得到待测数据,通过应用程序接口输入所述情感分类模型进行预测,之后通过所述分类结果输出模块输出分类结果。
数据预处理模块
在数据输入到模型之前需要进行相关的数据预处理操作。首先进行数据清洗,该步骤的目的是修正数据集中存在的错误,删除无效字符,并提供数据一致性。在此,我们采取的主要处理包括:(1)合并类别;(2)清除表情符号;(3)删除乱码符号;(4)删除连续的重复标点;(5)删除空白句子;(6)将繁体字转化为简体字。值得一提的是,由于数据的标注一般由多人并行完成,每个人对于评论对象的理解不同,导致数据标注的“粗细”存在差异,因此,我们随机采样部分数据进行了分析,最终将意思比较相近、没有细分必要的评论对象的类别进行了合并(处理(1))。
数据清洗完毕后,我们对数据集中的句子进行了分词和去停用词的处理。对于分词处理,我们使用了两种开源的分词工具,结巴分词器和bert中文分词器。由于航班点评数据中存在一些航空领域的专业名词,默认的结巴分词器无法正确解析这些词语,因此,我们引入了一个常用的航空领域词典,用以辅助结巴分词器。对于去停用词处理,我们直接根据百度的停用词表,删除句子中的停用词。
情感分类模型
进行预处理后的句子在输入模型之前,需要将句子中的词转化为对应的词向量表示,这里我们主要采用两种常用的方法,预训练的词向量模型和预训练的bert模型,两个模型分开进行,作为两种不同的路径尝试。对于预训练的词向量方法,我们利用bilstm模型获取与各个评论对象的情感要素相关的上下文信息,将wordembedding输入双向lstm模型,得到上下文相关的embedding。对于预训练的bert模型,将文本信息通过bert得到bertembedding。为了实现细粒度情感分类,我们设计并实现了一种基于评论对象的注意力机制,为每个预先定义的评论对象计算其对应的分类向量,最终,分类器根据分类向量,将每个评论对象分为积极、消极、中性、未提及四类。预训练的词向量模型和预训练的bert模型的工作流程如图4和图5所示。其中a1,a2…为每个需要判断的类别(如飞行平稳、航班准点、空乘服务等)的embedding;a1_v,a2_v…为attentionpooling输出结果;y1,y2…为每个类别的分类结果,-1代表消极,1代表积极,0代表一般,-2代表未提及。
基于评论对象的注意力机制
为了实现细粒度情感分类,我们设计并实现了一种基于评论对象的注意力机制,该注意力机制在bilstm后接入,为每个预先定义的评论对象计算其对应的分类向量,注意力集中到整段文本中比较重要的信息。attentionpooling机制对某类a1的实现过程如图6所示,接收bilstm模型的数据后,为每个预先定义的评论对象计算其对应的分类向量,对某类别的实现过程为通过每个词的embedding分别与每个需要判断的类别的embedding求张量的点积,得到两者的相似度分数。后将其输入softmax函数,得到归一化后attention的概率权重。最后把每个词的embedding对此概率权重进行加权求和,得到某类别(如航班准点)的极性概率分布。该过程会对所有类别a1,a2…重复进行,并分别输出a1_v,a2_v…。其中e1,e2…为每个词的embedding;a1,a2…为每个需要判断的类别的embedding,输出的a1_v,a2_v…是attentionpooling的输出结果。
数据增强
点评数据中的评论对象的种类较多,因此标注航空领域的细粒度情感分类数据集人工成本较大,导致训练数据集规模受到限制。另外,各个评论对象在数据集中的数量差距较大,这导致训练数据存在类别不平衡问题。因此,我们针对航空领域的点评数据,设计并实现了一种数据扩充的方法。我们参考了emnlp2019会议上提出的eda(easydataaugmentation)算法并结合回译的数据增强策略,最终将6791个样本的训练集扩充到了37924个样本。
我们主要采取了5种增强策略:(1)同义词替换,该方法从文本中随机选取出若干个非停用词的单词,利用同义词将其替换;(2)随机插入,该方法从文本中随机找出一个非停用词的单词,获取其同义词,并将该同义词插入到句子中的随机位置,重复若干次;(3)随机交换,该方法从文本中随机选择两个单词进行位置交换,重复若干次;(4)随机删除,以某个固定概率从句中移除单词,考虑到数据集的文本中含有用标点符号隔开的分句,而跨分句进行的随机交换通常会对语义有较大改变,所以在进行随机交换时首先将文本按中英文全部标点符号分隔为分句列表,此后从分句列表中随机选取一个单词数大于1的分句进行随机交换,重复若干次;(5)数据回译,即使用翻译接口将中文翻译为其他语言后,再将输出重新翻译为中文。数据回译可以在保证语义在最大限度一致的情况下更改用词和语言顺序,增加数据的多样性和数据量。这里,我们直接调用谷歌翻译接口实现数据回译。
为避免改动较多,造成的句子语义变化较大,我们每次对每个句子只随机采用以上5种策略中的一种。
- 还没有人留言评论。精彩留言会获得点赞!