用于PM2.5浓度分布的时空估算和预测的方法与流程
本发明涉及环境领域,具体地,涉及用于pm2.5浓度分布的时空估算和预测的方法。
背景技术:
pm,颗粒物的缩写,指空气中运动当量直径小于等于2.5微米的颗粒物。大量的观测研究表明,pm2.5的质量浓度主要受各种污染源和气象条件的影响。以pm2.5为主要污染物的大气重污染事件,对人们的日常出行和社会活动产生重大影响。已经证实,细颗粒物的浓度与心肺疾病和呼吸系统的发病率和死亡率呈正相关。如果人们生活在空气污染物浓度过高的环境中,会因吸入污染物过多而产生急性健康风险,如慢性呼吸道疾病、心血管疾病等。研究表明,pm2.5可渗透到肺和支气管,长期接触pm2.5可增加呼吸系统疾病和心血管疾病的发病率和死亡率;pm2.5直径小,质量好,在大气中停留时间长,传输距离长,因此,它会严重影响大气能见度,对人们的日常生活和社会活动产生不良影响。因此,快速准确地预测pm2.5浓度已成为大气污染防治领域的研究热点。
技术实现要素:
本发明提供了一种用于pm2.5浓度分布的时空估算和预测的方法,包括:
细粒度气溶胶光学厚度(aod)的采集与校正,包括:
处理mcd19a2、geosfp和地面气象观测数据的原始数据集,选择并定义从mcd19a2中提取的aod为aod-0数据集,在geos-fp数据的基础上,利用自然邻域插值方法将pblh转换成与aod数据集相同的栅格格式文件,便于aod的校正;
使用相对湿度分布数据集修正aod-0。校正方程如下,
其中rh表示相对湿度,aod0表示aod-0,aod1表示aod-1,对于每一个对应的单元,使用函数来修正aod-0,然后得到aod-1分布;基于aod-1和pblh数据集,使用下面的公式第二次修正aod:
其中aod1是aod-1,aod2是aod-2。最后得到了aod-2分布,即修正后的精细时空aod分布;
计算细粒度pm2.5的回归模型:
对空气质量观测数据进行预处理,提取16个空气质量站点的pm2.5小时浓度值,再利用地面气象观测资料提取风速和降水值;
计算151天内16个站点pm2.5浓度、风速和降水的日平均值,对aod-2光栅图像进行相同的预处理;
从151天和16个站共得到151×16=2416组变量,利用回归模型和机器学习方法,建立pm2.5浓度与其他自变量之间的估计模型,并进行精度比较,其中,回归模型包括线性模型、脊模型、最小绝对收缩和选择算子(lasso)模型、立体模型和极端梯度增强(xgboost)模型;
建立pm2.5浓度与aod之间的模型,并利用该模型估计整个研究区pm2.5的空间连续分布,使用块统计和缺失值填充(bsmp)方法使aod成为完整的空间连续分布;
细颗粒pm2.5浓度分布预测:
在数据集上应用两个预测模型:sarima和convlstm,在预测部分,建立一个类似鱼网的网格,将整个研究区域按不同时间的每个分布划分为正方形单元,研究区域为165×165km2,为使数据结构更适合预测模型,该区域网格由50×50=2500个单元组成,每个单元为3300×3300m2;
将pm2.5网格输入到convlstm模型中进行10次预测,使用从原始数据集中提取的10个不同的数据组,每组由151-9=142天的数据组成,每训练一次142×20%≈114天的模型,并对接下来28天的数据进行测试;
经过10次的训练和预测,通过计算测试数据和预测数据的均方根误差(rmse)和决定系数r2回归得分函数来评估结果。
通过对几种回归模型和机器学习模型的比较,确定了xgboost模型作为该框架下的估计模型,其均方根误差(rmse)最低为32.86μg/m3,r2最高为0.71。经过10次验证和与传统时间序列预测模型——季节自回归差分移动平均sarima)模型的时空对比,convlstm的预测精度更高,总平均预测rmse为14.94μg/m3,而sarima的预测精度为17.41μg/m3。此外,convlstm在时间上的波动较小,稳定性较好,在空间上也能较好地消除预测精度的空间差异。
附图说明
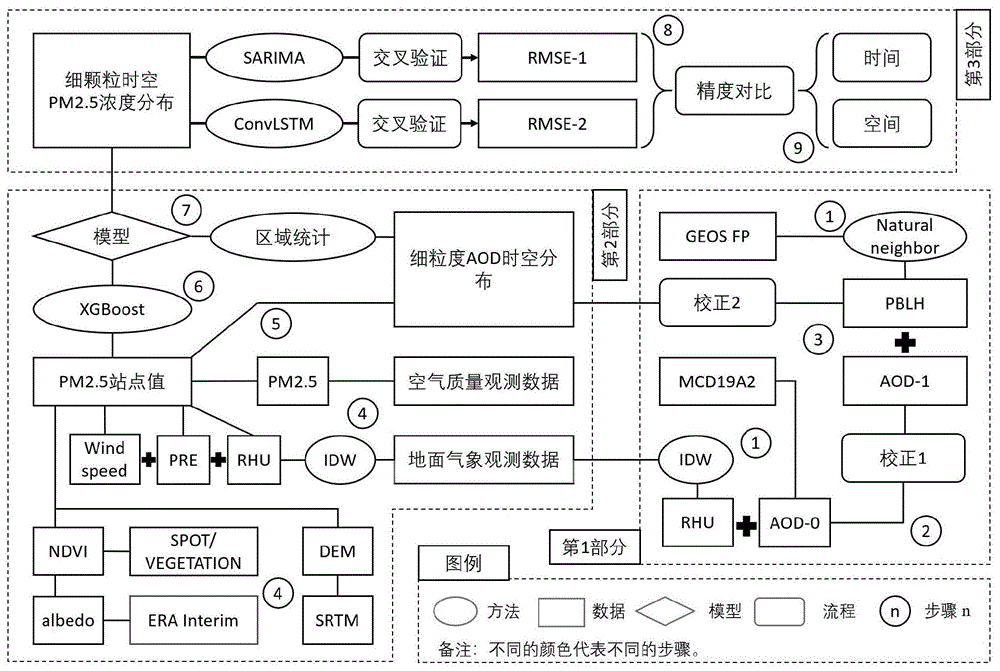
图1示出了预测pm2.5浓度框架的工作流程。
图2示出了研究区域(石家庄市)空气质量站点分布情况。
图3示出了bsmp方法的工作流程,其中,(a)示出了原始栅格(originalraster),(b)示出了块统计栅格(blockstatisticraster),(c)示出了缺失值插值(missing-valuepadding)。
图4示出了pm2.5浓度分布时间序列的验证策略。
图5示出了aod和pm2.5浓度与xgboost回归结果的关系:(a)aod和pm2.5的线性回归结果;(b)显示了观测和估算pm2.5浓度的预测和比较结果;(c)是训练后的xgboost模型中特征重要性排序的重要性分析结果。
图6示出了预测10组pm2.5浓度损失与历元数的关系。
图7示出了测试、convlstm预测和sarima预测pm2.5浓度。(a)到(i)分别说明10组比较结果。
图8示出了sarima和convlstm模型的rmses。所有组的数据共享相同的x轴,而在y轴上,有10个箱子,每个箱子跨越rmse从0到50,其中50个也可能是下一个箱子的开始。
图9示出了空间上sarima和convlstm模型rmses的频率分布直方图。所有子块的x轴显示rmse值,而y轴表示频率。(a)至(t)交替表示srima和convlstm的rmse频率分布。
图10示出了sarima和convlstm模型rmses的空间分布。(a)至(t)交替显示石家庄srima和convlstm的rmse图。
具体实施方式
下面的实施例可以使本领域技术人员更全面地理解本公开,但不以任何方式限制本公开。
pm2.5浓度受研究区地形、排放位置、排放速率和气象因素的影响,具有很强的非线性特征,同时,同一分布区的pm2.5观测值之间存在潜在的相互依赖关系,因此pm2.5变量之间存在一定的空间自相关。为了提高pm2.5的预测精度,保证算法的可靠性,本文采用卷积长短期记忆(convlstm)模型和改进的长短期记忆(lstm)模型,在lstm模型中加入卷积运算,提取空间特征,对pm2.5的时空分布进行预测第二天或第二天的pm2.5。
在研究和预测pm2.5时,获取整个研究区域的pm2.5数据对提高整个研究的精度是非常重要的。目前,pm2.5浓度数据主要分布在地面监测站和卫星数据上。在获取pm2.5数据时,地面监测站的数据是按点分布的,很难利用有限的监测设施获取全局的pm2.5数据,因此,空间插值(一种基于同一区域已知数据推断未知数据的方法)可以弥补这一不足,常用的方法有距离加权反插值、趋势面插值、普通kriging插值、协同kriging插值、径向基函数插值等。考虑到获得pm10和tsp数据比获得pm2.5数据和丢失pm2.5数据更容易,hwalung等人提出计算台北市pm2.5/pm10与pm2.5/tsp比值的bme算法,结合pm10与tsp对pm2.5数据进行插值,并回顾性估计历年pm2.5的时空分布。在此基础上,解释研究区排放格局的潜在和暂时变化。结果表明,该算法能较准确地估算出历年的pm2.5浓度,但仍不能适应只有pm2.5数据的情况,pm2.5/pm10和pm2.5/tsp比值的稳定性是以年时段为基础的,而不是以月、周、日等较短时段为基础;在没有监测的地区设施中,最常用的辅助数据是aod(气溶胶光学厚度),即大气垂直方向气溶胶消光系数的积分,它与辐射波长、垂直剖面、粒径分布和气溶胶粒径有关。研究发现,在可见光和近红外波段,颗粒物的粒径特别是pm2.5的粒径范围与aod从0.1-2nm的倒转密切相关,pm2.5与aod的相关性受气象因素(aod垂直剖面、温度、湿度、风速等)的影响地理因素(区域类别、道路分布、森林覆盖等)对建立pm2.5与aod的关系具有重要意义。因此,基于这些辅助因子和aod数据建立相应的预测模型,可以有效地获得pm2.5数据,从而对pm2.5浓度进行监测和预测;考虑到监测站的局限性和分布的不均匀性,rui等利用aod数据,引入多元线性回归模型,发现了pm2.5、aod、气象因子和理化因子之间的相互作用,最后建立了北京市pm2.5浓度的定量插值模型。结果表明,该模型能较准确地分析研究区pm2.5的时空分布,但不考虑时间和区域的变化,不考虑提供aod数据的卫星数据的分辨率,不考虑pm2.5的详细组成,对提高研究区pm2.5的精度具有重要意义模型。本文采用convlstm模型对北京市pm2.5浓度进行预测,在已有的地面监测站pm2.5数据的基础上,利用距离反比权(idw)得到综合历史pm2.5数据。该模型在一定程度上具有较高的时间分辨率,能够有效地预测未来每小时的pm2.5浓度,从而为人们的出行和社会活动提供准确的预警信息。
随着雾霾等对人们产生不良影响的大气污染事件的发生,国内外许多学者开始对pm2.5浓度进行研究和预测。元华等采用bp人工神经网络对北京市pm2.5浓度进行预测,发现它能很好地反映pm2.5浓度的变化,在此基础上对pm2.5浓度进行了预测,但该模型对结构和算法的合理性要求较高,参数设置复杂;洪福等利用历史pm2.5数据,建立了基于gm(1,1)理论的长春市未来2天pm2.5浓度预测模型,结果表明,该模型预测效果良好,可用于霾事件的预测,但时间分辨率较低,不是1天或2天,而是1天或2天1小时或2小时;bingyue采用极端梯度boosting(xgboost)算法对天津市空气质量数据进行监测,并预测了pm2.5浓度,该算法在数值计算方面具有较高的精度、较低的过拟合概率和较好的性能,但该研究只使用一个监测站的数据(数据不是多变量的,没有综合性),xgboost算法有限;健平等发现noaa-naqfc(国家空气质量预报能力)提供的预报指导具有明显的季节性偏差,冬季出现预报超差现象,夏季出现预报超差现象。为了减少偏差,研究人员将模拟集合偏差相关方法与naqfc相结合,预测了美国中部偏下、中部偏上、东南部和东北部、太平洋沿岸、落基山脉的pm2.5浓度,结果表明,与传统的预测模型相比,这种模拟集成偏差相关方法可以提高预测精度和预测能力,但当有特殊事件发生时,pm2.5浓度会很高,从而限制了预测精度的提高。考虑到空间数据对时间预测模型也很重要,lei等人提出了空间数据辅助增量支持向量回归(saincsvr)模型,用于预测新西兰奥克兰13个监测站的pm2.5浓度,结果表明,与单纯的时间incsvr预测模型相比,加入空间域数据的模型更能较好地处理许多预测模型中存在的短期和缺失数据问题,但该模型没有考虑监测站的地理特征,这对监测站的预测能力至关重要模型;rh-zong等人引入rnn(递归神经网络)模型,利用北京、成都、沈阳的气象资料和pm2.5浓度资料,尝试建立一个通用的预测模型,发现基于其中一个城市的数据的预测模型可以推广到另外两个城市,表明两者之间存在着密切的关系pm2.5源汇与环境驱动因子之间存在内在的相关性,而且这种相关性在城市中普遍存在;机器学习算法在处理非线性数据时具有较强的表达能力,但不同算法在使用相同数据时具有相似的预测精度,以提高预测精度,叶刚基于自适应bp神经网络算法建立了重庆涪陵pm2.5浓度与aod、气象因子小时预报值的关系。该算法具有自适应训练和调整的能力,能很好地抑制过拟合现象,但pm2.5浓度时间序列预测受多种因素影响,历史数据量不足,降低了模型的精度;wei等人提出了利用主成分分析(pca)算法和lssvm算法对支持向量机算法进行改进,并用cs算法进行优化,其中pca算法准确地提取有用信息,降低了输入层的维数,lssvm降低了计算复杂度,这种混合策略不仅提高了预测精度,同时也大大提高了预测速度。
目前,研究、分析和预测pm2.5浓度的算法很多,但很少考虑空间自相关,而且大多数算法的时间精度较低,无法预测未来几小时甚至几天的pm2.5浓度,对未来大气污染的建立意义不大。r、a.bahari等人提出了mlp人工神经网络,并将温度反演作为参数加入到算法中,对德黑兰地区未来3天pm2.5浓度进行预测,结果表明,温度反演能很好地改进算法,预测精度大大提高。该算法以12小时为研究单元,绘制温度、风向、风速等图,并进行温度反演,最后预测未来小时pm2.5浓度。但预测周期达12小时,不能适应1小时等较短周期,因此可以适当缩短预测周期,提高精度,满足准确预报霾的要求。ping等人提出了基于hdar算法、maf算法、lvq算法和afnn算法的hml-afnn混合策略,对京津冀地区和珠三角地区pm2.5浓度进行分析预测,(1)hdar算法选择与研究区pm2.5浓度有较强相关性的城市;(2)maf算法从上述城市中选择影响研究区中心pm2.5浓度的时空因素和地理因素;(3)lvq算法根据数据集的大小将所有数据集划分为若干数据集pm2.5浓度;(4)afnn算法基于上述数据集对pm2.5浓度进行分析和预测。结果表明,该混合策略比单一算法具有更好的性能,但不考虑变量间的空间自相关,预测精度不高。为了提高预测精度,yun等人引入基于混沌理论的多元混沌时间序列模型对北京市pm2.5浓度进行预测。首先将混沌时间序列的相空间单元扩展为多时间序列相空间单元,在此基础上构造了多时间序列相空间矩阵,最后引入rbf神经网络从状态点预测pm2.5浓度,在一定程度上实现了对pm2.5浓度的预测,该模型虽然考虑了气压、温度、风向、风速、露点等指标,具有较高的时间精度,但不考虑变量间的空间自相关,对提高预测精度也至关重要;海明等认为,由于pm2.5数据具有很强的非线性特性,监测和获取pm2.5数据存在许多困难。引入rbf神经网络算法,对经典bp神经网络进行改进,使算法具有局部学习能力。研究者选取了常规大气污染监测数据和气象因子作为变量对pm2.5浓度进行预测,结果表明,rbf模型比bp模型具有更强的预测能力,但由于缺乏样本,部分样本的预测精度降低,给算法带来困难为了适应复杂的天气,气象环境数据中存在着大量的冗余信息,因此在预测pm2.5浓度之前,有必要对数据进行滤波,消除冗余信息,陈等提出了mfd+abc+svr混合策略,mfd+abc选择最优的特征数据集,其中mfd(多分形维数)作为数据集选择的评价标准,abc(人工蜂群)提供搜索策略,最后用svr算法预测广州、上海第二天pm2.5浓度。该混合策略优化了输入层的处理过程,提高了预测精度,但时间精度不高,不考虑变量间的空间自相关。
convlstm模型是一种改进的lstm模型,具有良好的时空特性,它不仅具有lstm的时间建模能力,而且可以刻画cnn等局部特征。
总之,许多预测pm2.5浓度的算法关注于输入数据的去冗余和增加相关影响变量以提高预测精度,但是考虑到时间精度和空间自相关的算法并不流行。因此,本文采用考虑变量间空间自相关的convlstm模型对pm2.5浓度进行预测,具有很高的时间精度(小时),预测时间可以延长到24小时甚至几天,从而有效地提高了预测精度。lstm模型具有递归神经网络节点的结构,能够很好地处理具有时间自相关特性的时间序列数据,而convltm模型对lstm模型进行了改进,在lstm单元的基本结构中加入了卷积运算,使得它不仅能建立时间关系,而且能很好地处理具有时间自相关特性的时间序列数据lstm还可以提取出cnn等时空特征,并能很好地处理时空序列变量。本文收集历史上的pm2.5数据,输入convlstm模型,对未来一天或几天内pm2.5浓度的时空分布进行预测,可以有效地提高预测的稳定性和准确性。
目前,pm2.5浓度分布在公共卫生、政府管理和学术研究等方面发挥着重要的作用,而对pm2.5浓度在细粒度时空分布的预测对于控制未来形势具有重要意义。然而,目前的研究大多集中在对空间pm2.5分布的预测上,即利用监测站得到的某些pm2.5值来估计没有监测站得到数据的pm2.5值(为了减小偏差,称这种空间预测为估计)。已有研究考虑了pm2.5浓度的相关影响变量,对未来的pm2.5浓度分布进行了预测,但很少考虑变量间的空间自相关,这会造成较大的误差。同时,预测的pm2.5浓度分布的时空分辨率不够精细。此外,很少有研究将空间估计和时间预测结合起来,形成一个完整的框架,这给希望利用原始数据集预测整个研究区域内pm2.5浓度分布的工作人员提供了很大的便利。
因此,在本申请中,基于原始数据集,包括2019年1月1日和2019年5月31日(151天)的气溶胶光学厚度(aod)、监测点的pm2.5浓度等,建立了一个完整的框架来预测中国石家庄市的pm2.5浓度日分布。预测的空间分辨率为3300米。
材料与方法
本申请总共使用了7种原始数据集,包括mcd19a2、geosfp、空气质量观测数据、地面气象观测数据、spot/植被、era中期和srtm数据集(这些数据集将在下面详细介绍)。框架的方法由3个主要部分组成,共9个步骤,如图1所示。阐述了获得精细时空aod分布的过程,并在此基础上建立回归模型计算pm2.5浓度分布的过程。最后,在训练细颗粒时空pm2.5浓度分布的基础上,利用convlstm对测试分布进行了预测,并与sarima模型进行了比较,验证了模型的准确性。
1.1材料
1.1.1研究区域和时间
本研究区域以石家庄市为研究对象,主要研究区域为165公里长的正方形区域,涵盖了石家庄市境内的所有区域。城市和行政单位的位置如图2所示。研究时间为2019年1月1日至2019年5月31日,共5个月151天。接下来的两个小节分别介绍了数据的细节和框架的方法。
1.1.2数据源
mcd19a2是基于大气校正(maiac)算法的陆面二级网格化(l2g)气溶胶光学厚度产品的多角度实现的缩写,它由terra和aquamodis两个数据源导出。该l2g产品每天以1km像素分辨率生产。以下科学数据集(sds)层:0.47μm蓝色波段aod,0.55μm绿色波段aod,水上精细模式分数,aod不确定度,烟雾注入高度(地上m),陆地和云层柱状水汽(cm),aodqa,太阳天顶角余弦,1kmaod模型,视天顶角余弦,散射角,相对mcd19a2aod数据产品包括方位角和5公里处的闪烁角。本产品还包括一个低分辨率浏览图像,显示0.47μm处蓝色波段的aod,该aod是使用所有可用轨道的组合创建的。从产品中,可以得到空间细粒度的aod数据集。aod是每日数据集,它包含卫星在一天内通过图像区域时收集的数据,因此每日数据包含不同数量的数据(取决于一天中的传输次数)。为了统一研究期间aod之间的时间间隔,本申请计算了日平均aod并将其转换为图像格式。2019年1月1日至5月31日共有151张aod图像。
geosfp文件由网络通用数据格式(netcdf-4)库生成,该库的底层格式为分层数据格式版本5(hdf-5)。获取的geos-fp文件的标准是tavg1_2d_flx_nx(2d时间平均表面通量诊断)。该文件包含行星边界层高度(pblh)、表层高度(hlml)、总降水量(prectot)等。利用全球模式同化办公室(gmao)的geo-fp资料,可以获得石家庄地区2019年1月至2019年5月的逐时行星边界层高度(pblh)资料。
本申请中的国家空气质量观测数据来源于中国环境监测点的国家城市空气质量实时发布平台,包括pm2.5、pm10、so2、no、co等小时值。在本申请的研究区域,有16个空气质量站点,提取了这些站点上的pm2.5值作为回归模型的因变量。数据集的时间分辨率为1小时,空气质量站点的分布如图2所示。
地面气象观测数据来自中国国家气象科学数据中心,包括气压、气温、相对湿度、风速、水汽压降水等因素的逐时观测。所有这些数据都是由地面气象站获得的。在本申请的研究区域,共有31个观测站,根据之前的研究,提取了风速(m/s)、降雨量(mm)和相对湿度(百分比)作为回归模型中的关键自变量。数据集的时间分辨率为1小时,气象站的分布如图2所示。
ndvi(normalizeddifferencevegetureindex,归一化差分植被指数)能够准确反映地表植被覆盖情况。该数据集来源于spot卫星平台上的植被传感器。可见光和红外区域的地表反射率测量可从spot4(1998年4月发射)上的植被仪器和spot5(2003年2月以来)上的植被仪器获得。目前,ndvi时间序列数据已广泛应用于土地利用/覆盖变化检测、植被动态变化监测、宏观植被覆盖分类和净初级生产力估算等研究。该数据集有效地反映了我国不同地区植被覆盖的时空分布和多样性。对监测植被变化、合理利用植被资源等与生态环境有关的研究领域具有十分重要的参考意义。本申请使用了中国2018年1km2空间分辨率的年度ndvi数据。
在本申请中,需要覆盖研究区域和时期的每日反照率数据。该数据可从欧洲中期天气预报中心(ecmwf)获得,该中心以0.25°×0.25°的水平分辨率重新分析中期(era中期)每日数据。这些覆盖全球的数据适合在世界不同地区进行气候研究,因为它们是长期可用的。era中期月平均全球网格气象数据(完全由berrisford等人描述)。从2018年1月1日到2018年5月31日,用于提取相应的每日反照率栅格数据集。
航天飞机雷达地形任务(srtm)是国家地理空间情报局(nga)和美国国家航空航天局(nasa)的一个联合项目,为数字高程模型(dem)srtm数据的生成提供了重要的一步。本申请从科学出版社2009年出版的1:100万中国地貌图中提取高程数据作为估算pm2.5的重要特征,数据的空间分辨率为90米。
1.2方法
该框架由3个部分组成,包括9个步骤,本节将介绍使用方法和过程,如图1所示。
1.2.1第一部分:细粒度aod采集与校正
第一部分的目的是计算具有修正过程的时空精细aod分布。计算修正的aod分布有三个步骤。
空气湿度对气溶胶光学厚度(aod)有影响,随着湿度的增加,气溶胶的吸湿性和溶解性粒子的大小也相应增大。空气湿度和气溶胶光学厚度之间存在正相关。此外,pblh对表面pm2.5与aod的关系也有影响。pblh越大,aod越大,但表面pm2.5浓度可能较低。考虑到这种影响,本申请使用相对湿度和pblh来校正aod。
因此,首先,本申请重新处理mcd19a2、geosfp和地面气象观测数据的原始数据集。本申请选择并定义从mcd19a2中提取的aod为aod-0数据集。然后在geos-fp数据的基础上,利用自然邻域插值方法将pblh转换成与aod数据集相同的栅格格式文件,便于aod的校正。在地面气象观测数据方面,只提取31个站的小时相对湿度数据,然后计算每个站每天的相对湿度平均值。对于日平均相对湿度,使用逆距离加权(idw)方法将点数据空间插值到整个研究区域。最终的相对湿度分布是图像文件,其中单元表示1km平方的空间面积,这与aod-0图像相同。
第二步,使用相对湿度分布数据集首次修正aod-0。校正方程如下,
其中rh表示相对湿度,aod0表示aod-0,aod1表示aod-1。对于每一个对应的单元,使用函数来修正aod-0,然后得到aod-1分布。
第三步,基于aod-1和pblh数据集,使用下面的公式第二次修正aod:
其中aod-1是aod1,aod2是aod-2。最后得到了aod-2分布,即修正后的精细时空aod分布。
1.2.2第2部分:计算细粒度pm2.5的回归模型
pm2.5与aod有很高的相关性,而其他气象因素也影响pm2.5的浓度。然而,只能在特定的空气质量点上获得准确的pm2.5浓度值,如果想要得到pm2.5的空间连续分布,则需要根据aod和其他关键因素来估计浓度。因此,本部分的目的是根据现场点的地面真实pm2.5浓度数据建立一个回归模型,然后利用该模型对研究区的整个分布进行估计。本部分共有4个步骤,步骤的索引将继续遵循上一部分的索引。
第四步,对空气质量观测数据进行预处理,提取16个空气质量站点的pm2.5小时浓度值。再利用地面气象观测资料提取风速和降水值。在研究期间,仍然使用idw获取这两种天气状况的栅格格式图像。
第五步,计算151天内16个站点pm2.5浓度、风速和降水的日平均值。对aod-2光栅图像进行了相同的预处理。研究表明,pm2.5-aod关系可以建立一个多变量函数,它与许多影响因素有关。根据文献资料,以下参数可能有助于pm2.5的估算:湿度、反照率、降水、ndvi、风速和海拔,这些参数是为建模而构建的,其中pm2.5为因变量,其他参数为独立变量。
第六步,最终从151天和16个站共得到151×16=2416组变量。我们需要建立一个估计模型来估计整个研究区域的pm2.5。立体主义回归模型是估算地面pm2.5浓度的最佳选择,同时,其他一些研究也验证了立体主义模型在类似情况下的良好性能。然而,由于每种情况都有其不同的情况,本申请选择了一些传统的回归模型和机器学习方法,建立了pm2.5浓度与其他自变量之间的估计模型,并进行了精度比较。
在这一步骤中,使用回归模型并进行比较,包括1)线性模型,2)脊模型,3)最小绝对收缩和选择算子(lasso)模型,4)立体模型和5)极端梯度增强(xgboost)模型。套索是一种变量选择和正则化方法,它可以强制一些二次系数为零,以便收缩系数。它可以提高模型的解释能力,减少过拟合。cubist是一个基于规则的树模型,它使用m5理论在树的末端节点生成多个线性回归模型。在对终端节点进行预测时,可以采用相应的线性回归模型进行预测,并将终端节点的预测与树中最近邻节点的预测相结合进行平滑,从而提高预测精度。此外,cubist还构建了几个树模型(称为committees),其中基于规则的模型被构建到每个树模型中。最后的预测可以通过平均所有委员会的预测得到。xgboost是一种基于梯度提升框架原理的集成树方法,它可以通过正则化技术控制模型的拟合和复杂度。
第七步,建立了pm2.5浓度、aod与其它必要气象条件之间的模型,并利用该模型估计了整个研究区pm2.5的空间连续分布。由于aod在空间上有许多缺失值,因此需要在已有数据的基础上对缺失数据进行插值。在这里,使用块统计和缺失值填充(bsmp)方法使aod成为完整的空间连续分布。bsmp方法适用于栅格或图像,由两部分组成。块统计工具进行邻域运算,输入像素计算统计信息,这些像素属于一组固定的不重叠窗口或邻域。这些统计信息(例如,最大值、平均值或和)适用于每个邻域中包含的所有输入像素。在得到单个邻域或块的计算结果值后,指定一个邻域,并将计算结果分配给邻域内最小边界矩形中包含的所有像素位置。缺失值填充是将原始栅格与块统计后生成的新栅格合并。已具有值的单元格将保留原始值,而缺少值的单元格将从块统计中获取新值。bsmp的工作流程如图3所示。
1.2.3第三部分:细颗粒pm2.5浓度分布预测
最后一部分是预测框架的核心部分,分为两个步骤来预测细粒度时空pm2.5浓度。继续呈现第八步和第九步。
第八步,在数据集上应用两个预测模型,sarima和convlstm。在预测部分,本申请建立了一个类似鱼网的网格,将整个研究区域按不同时间的每个分布划分为正方形单元。由于研究区域为165×165km2,为使数据结构更适合预测模型,该区域网格由50×50=2500个单元组成,每个单元为3300×3300m2。
数据输入为151幅pm2.5浓度分布图。然而,将数据输入到这两个模型的方法是不同的。在sarima模型中,把每个单元看作一个单一的输入,这意味着每个单元都有一个由151个浓度值组成的时间序列,而这个模型将被建立2500次,因为有2500个单元。
本申请中使用的sarima模型是一类单变量模型,将此模型应用于pm2.5浓度时间序列的预测。
由于pm2.5浓度分布在特定的空间区域(如一个城市或省份)随时间变化,需要确定它们在数据集中是否具有趋势分量。初始过程是zt级数的一阶差由wt给出,单位间距上级数中点之间的差,计算为wt=zt-zt-1。也可以用后移算子b来写wt,即wt=(1-b)zt,从而得到dth阶差分为(1-b)dzt。
除了对潮流的判断,季节性也需要表现出来。因此,通过形成季节性差异wt=zt-zt-1=(1-bs)zt,其中s是数据的季节性周期,扩展了上述普通差分的概念。因此,季节自回归综合移动平均(sarima)是最普遍的box-jenkins模型,其形式如下:
φ(b)φ(bs)(1-bs)d(1-b)dzt=θ(b)θ(bs)at,(3)
φ(b)=1-φ1b-…-φpbp,(4)
θ(b)=1-θ1b-…-θqbq,
θ(b)=1-θ1b-…-θqbq,
θ(bs)=1-θ1bs-…-θqbsq,
其中p表示自回归阶,q表示移动平均阶,d表示差分运算次数,p、d和q表示相应的季节阶。
在剔除趋势和季节性因素后,模型拟合过程包括识别、参数估计和诊断验证。基于估计自相关函数(acf)和估计部分自相关函数(pacf),在识别阶段提出了一种尝试性的自回归滑动平均(arma)过程。将pm2.5浓度时间序列的acf和pacf形状与理论模型的形状进行比较。在这个比较中,可以定义p和q以及arma模型的阶数。
值得一提的是,在本申请中,每验证一次(总共10次),因为需要用sarima对2500个单元的pm2.5浓度时间序列进行2500次建模,将需要大量的计算工作,耗费大量的计算机时间和功率。为了简化这个过程,对于每一个由2500个单元组成的分布,计算出pm2.5的平均浓度。将151个pm2.5浓度平均值作为最后一个时间序列来计算sarima的参数,然后仍然对每个单元2500个时间序列中的2500个时间序列进行建模,但是使用的参数与最后一个平均时间序列计算的参数相同。
长短期记忆(lstm)是一种递归神经网络(rnn)节点结构,它能很好地处理时间序列数据,且通常具有时间自相关性。各种互连门对单元状态的影响是lstm的核心概念。单元状态作为传输通道,相关信息作为网络的“存储器”沿序列链向下传输。在序列处理的整个过程中,单元状态可以携带相关信息。因此,即使来自较早时间步的信息也可以进入较晚时间步,从而将短期记忆的影响降至最低。随着单元状态的发展,信息通过门被添加或移除,就像一种神经网络,它通过学习相关信息来决定哪些信息可以在单元状态(训练期间)存在。在lstm网络中,在每个时间步骤t,隐藏状态hút由当前数据更新,即,同时步骤xt、上一时间步骤ht-1、输入门it、输出门ot和存储单元cút也被更新。该模型的基本原理与convlstm模型相同。因此,这里不再重复这个方程,稍后将在convlstm模型的介绍中描述。
convlstm模型是lstm的一个变种,用于处理时空预测。它最初是由shi等人提出的。首先,它被用于降水的实时预报,其中实时预报是一种利用速度和运动方向的估计值进行预报的极短距离预报技术。在本文中,遵循convlstm的公式,它包括输入x1,...,xt,s单元输出c1,...,ct,隐藏状态h1,...,ht和门it,ft,ot,并使用三维(3d)张量结构。在convlstm网络输入元素的三维时空张量中,前两个维度是空间维度,第三个维度是时间维度。与原始lstm模型一样,从输入到状态和从状态到状态的转换涉及到三维输出张量的卷积。下式可用于进一步建立模型,其中,‘*’表示卷积运算,
在上述方程中,it、ft和ot是输入门、遗忘门和时间步t的输出。ct是时间步t的单元输出。ht是时间步t的单元的隐藏状态。sigmoid(σ)被用作三个门的门函数,因为它输出的值介于0和1之间。它要么不允许信息流通过门,要么允许完整的信息流通过门。另一方面,为了克服梯度消失的问题(即用基于梯度的学习方法和反向传播来训练人工神经网络的问题),需要一个函数(tanh),该函数的二阶导数在归零之前可以保持较长的范围。w和b是训练过程中需要学习的权值矩阵和偏差向量参数。然后将pm2.5网格输入到convlstm模型中进行10次预测,验证策略如下。
由于本申请中的数据集是时间序列,提出了一种交叉验证策略,如图4所示。对预测模型进行了10次验证,使用了从原始数据集中提取的10个不同的数据组。每组由151-9=142天的数据组成,每训练一次142×20%≈114天的模型,并准备接下来28天的数据进行测试。
第九步是最后一步。
经过10次的训练和预测,本申请通过计算测试数据和预测数据的均方根误差(rmse)和r2(决定系数)回归得分函数来评估结果。rmse表示模型与数据之间的绝对拟合,以及观测数据点与模型预测值的接近程度,而r2表示相对拟合结果。计算这两个指标的结果作为每个单元格在一个时间间隔(一小时)的平均结果。然而,为了在不同尺度上对两种模型进行评价比较,本申请只使用反映绝对值的rmse,在时间和空间上分别对两种结果进行图形化和评价,便于区分。
在时间尺度上,每一个由2500个单元组成的鱼网(网格)有三个特征:原始pm2.5浓度值(f1)、sarima预测pm2.5浓度值(f2)和convlstm预测pm2.5浓度值(f3)。计算了2500f1和2500f2之间的rmse,结果定义为r1。然后计算2500f1和25000f3之间的rmse,结果被定义为r2。因为每个验证组有28天需要测试,所以有28个r1和28个r2可以按时间流安排。当验证建模10次时,有10组结果。每组有28个r1和28个r2。反映两种预测结果准确性的r1和r2可以在时间尺度上进行评估和比较。
在空间尺度上,根据上述讨论,每个鱼网中的每个单元都有三个特征,对于不同鱼网中的同一个单元,分别提取了28f1、28f2和28f3。然后计算28f1和28f2之间的rmse,将结果命名为r3,并计算28f1和28f3之间的rmse,将结果命名为r4。平均有2500r3和2500r4。因为本申请对模型进行了10次验证,所以会有10组结果。r3和r4反映了两种预测结果的准确性,可以在空间尺度上对两种预测模型进行评价和比较。
2.结果
首先对各种估算方法的结果和比较进行说明和讨论,然后用最精确的方法建立模型,对整个研究区域和研究期间的时空细颗粒pm2.5浓度进行估算。然后用sarima模型和convlstm模型对预测结果进行交叉验证,最后报告两种模型的精度比较。
2.1pm2.5估算模型
2.1.1模型性能与比较
按照第二部分第5步的工作流程,使用5种方法根据6个特征估计pm2.5浓度。由于modis卫星轨道间距、云层覆盖问题以及反演算法的局限性,aod数据集上存在多个空值,本申请从2416个数据阵列中提取1159个空值输入到模型中。在这里,使用5倍验证策略来测试模型。具体过程是,首先,将数据集划分为5个子集,前4个子集有232个数组,而最后一个子集有231个数组(总共1159个)。然后将其中一个子集作为验证数据集,其余子集作为训练数据集。重复训练10次,直到所有子集都作为验证数据集使用一次。
在验证数据与训练数据比较的基础上,采用均方根误差(cv-rmse)和确定系数(cv-r2)对各估计模型的精度进行评价。在确定基于精度的pm2.5估计最佳模型的同时,还进行了变重要度分析,以评价各预测因子在pm2.5预测中的贡献,该方法基于f-score测度,该测度简单地总结了每个特征在树中分割的次数。
利用auto过程对机器学习模型的参数进行优化,即为每个模型设置一个参数范围,然后进行交叉验证,得到估计结果最准确的参数集作为确定的参数。在此报告以下模型的确定参数:
·ridge:alpha=0.001(alphaistheregularizationstrength)
·lasso:alpha=0.001(alphaistheconstantthatmultipliesthel1term)
·cubist:committees=1000
·xgboost:max_depth=8;subsample=0.8;colsample_bytree=0.8;eta=0.3;num_boost_round=1000.(max_depthisthemaximumdepthofatree,subsampleisthesubsampleratioofthetraininginstances,colsample_bytreeisthesubsampleratioofcolumnswhenconstructingeachtree,andnum_boost_roundisthenumberofboostingiterations).
根据优化模型的结果,cv-rmse的范围为32.86μg/m3至52.23μg/m3,cv-r2的范围为0.17至0.71(表1)。其中,xgboost的性能最好,而cubist则是由cvrmse确定的性能最差的模型。这一结果与现有的研究有很大不同,现在研究认为后者立体模型的表现最好。之所以会发生这种情况,是因为回归或机器学习方法的性能是基于不同的地理和环境情况,在某些情况下现有研究中的结果无法使用,这验证了本申请的比较是必要的和决定性的。在最优参数下,xgboost的cv-rmse和cv-r2分别为32.86μg/m3和0.71,本文最后选择xgboost建立了估计模型。表1示出了用5种估计方法对预测结果进行交叉验证。
表1
2.1.2xgboost估算
在评价观测到的pm2.5与卫星衍生aod之间的经验关系(参见图5的(a))的基础上,观察到一个正相关但中等相关,相关系数(r)为0.58(p值<0.01),这为使用aod估计pm2.5浓度提供了证据。对于最佳模型,预测值和观测值与最佳拟合线(参见图5的(b))很好地吻合,表明xgboost估计pm2.5的精度很高。最终估算的rmse为13.31μg/m3,r2高达0.96,说明xgboost在这种情况下确实是一个性能优良的模型。
基于变量重要度分析,对xgboost模型贡献最大的预测因子是每日aod和反照率(参见图5的(c))。在本申请中,基于f得分,aod和反照率是排名前两位的特征。第三至第六个影响因子是风速、海拔、ndvi和降水。ndvi对两项研究的估计影响均不高。前3个特征对估计的影响最大,约占76%,但这3个特征之间的差异不明显。
其次,由于aod在空间上有许多缺失值,本申请使用bsmp方法使aod成为一个完整的空间连续分布,需要按照2.2.2节的说明,在现有数据的基础上对缺失数据进行插值,然后使用训练后的模型来估计pm2.5在空间上的分布整个石家庄市历时151天。
2.2预测
2.2.1sarima
按照第2.2.3节中描述的方法,为10个验证建立了10个sarima模型。在每一个模型中,都使用acf来测试时间序列是否具有空间平均pm2.5浓度的趋势性。然而,在10个验证过程中,所有时间序列组都是平稳的。同时,正常的趋势将存在于年或十年的数据期间,这意味着不需要用差异来建模数据。因此,所有验证中的参数d都设置为0。此外,由acf工艺确定的其他参数如表2所示。然后为每2500个单元的时间序列构建sarmia,并重复10次。由于预测结果包括时间和空间两个维度,将在第3.3节中报告最终预测结果,并对两个模型进行比较。表2示出了10个验证组的sarima模型参数。
表2
2.2.2convlstm
对于每一轮的预测,模型的参数包括核大小,设置核大小为3×3,40个卷积滤波器可以从卷积层中提取重要特征,每个滤波器有5个单位。为了提高泛化能力和防止过度拟合(这是一种与特定数据集过于接近或完全对应的分析结果,因此可能无法在机器学习或深度学习模型中可靠地拟合额外数据或预测未来的观察结果),在模型中,经常性体重下降被设置为0.2;训练次数(历次)被设置为500,而使用adam优化器,学习率为0.001,衰减率为0.9。
图6显示了结果的训练时间和平均绝对误差(mae),在机器学习或深度学习中称为损失函数。结果表明,当epoch小于30时,损失迅速下降,但当epoch大于30小于200时,10组损失的平均值开始缓慢下降。经过200个时期后,平均损耗下降很慢,在100左右基本稳定。在下一节中,将分析这两个模型的预测结果的准确性。
2.3精度分析
预测结果的总体精度可以用实测值和预测值的rmse来反映。表3列出了10个验证中2500个单元格的两个预测结果的总平均rmse。结果表明,convlstm模型的预测精度明显高于sarima模型,其中convlstm模型的rmse总平均值为14.94,而sarima模型的rmse预测值为17.41。由于本申请的整体过程在空间和时间尺度上都是多层的,为了比较两种预测结果,采用第2.2.3节的方法计算了rmse结果。表3示出了10个验证组所有细胞预测结果的平均rmse。
表3
注意:s是指sarima模型,而c是指convlstm模型。
2.3.1时间上的对比
图7显示了10个不同组28天内的测试、convlstm预测和sarima预测pm2.5浓度。可以看到,在每一组中,原始浓度随时间而变化,这是2500个单元浓度的平均值。另外两条测线与原始测线的拟合程度反映了两种模型预测的准确性。然而,这不明显地反映了预测结果的准确性,也很难看出两种模型的预测结果之间的差异。
因此,本申请计算2500f1和2500f2之间的rmse,然后得到r1。然后计算2500f1和2500f3之间的rmse,得到r2。图8显示了10次验证中每28天的28r1和28r2。
在图8中,可以很容易地了解到,在所有10个验证中,在28天内,convlstm的预测结果的rmse总体上高于sarima,这意味着convlstm的预测精度在时间尺度上总体上高于sarima。其中g0、g1、g4、g5表现明显。在大多数日子里,convlstm模型的rmses都低于sarima-one并保持在10左右,特别是在2019年5月10日至12日,sarima模型的预测精度低于其自身的平均水平。但在某些时期恰恰相反。例如,在2019年5月23日,sarima的rmse低于convlstm在第6、7、8组的rmse。然而,总体结果显示,convlstm比sarima具有更高的预测能力。波动较小的曲线表明convlstm比sarima更能及时预测。
2.3.2空间上的对比
在空间尺度上,计算了168f1、168f2和168f3。然后计算28f1和2f2之间的rmse得到r3,计算28f1和28f3之间的rmse得到r4。在10次验证中平均有2500r3和2500r4。绘制了如图9所示的10组r3和r4的频率分布直方图,以比较两个模型在空间尺度上的预测精度。就sarima结果而言,所有组的rmses范围为0-60,而convlstm范围为0-30。在所有的sarima模型组中,rmse在0~10之间的范围最大,频率约为1150,其次是rmse10~20,平均频率约为1100。就convlst而言,rmse在10~20之间的频率范围最大,频率约为1250,其次是rmse0~10,平均频率约为1150。虽然sarima的rmses比convlstm低,但其rmses也较多,从20到60占10%,而convlstm的rmses在该范围内的分布不到5%。
然后将rmse输出为石家庄市的地图,其中,用单元格中的不同色度表示预测的rmse值。结果如图10所示。图中较白的区域对应于用户密度预测的较高误差(rmse)。相反,较暗的区域表示错误较低。因此,错误扫描的分布表明了预测模型在空间中的作用。
直观地说,在sarima的所有预测rmse图中,有大量的白色单元格代表了预测的最高误差,这些单元格被颜色更黑的单元格包围。直观地看,sarima的rmse总体分布结果中白细胞较多,预测误差较大,但分布不均匀,尤其是g1、g4和g5。然而,当我们使用convlstm来预测pm2.5浓度分布时,由于在训练模型时使用了卷积,它可以考虑被包围的细胞的值,因此不存在sarima这样的情况,即rmse的地图具有更黑的细胞并且相对均匀地分布。由于convlstm模型考虑了空间自相关,因此更适合于pm2.5浓度分布的预测,这证明了convlstm模型在空间尺度上比sarima模型更准确。
以上结果表明,本申请的框架能够有效地预测基于原始多资源数据库的细粒度pm2.5浓度分布。为了更好地理解我们框架的能力,本部分从两个角度来考察方法:第一,预测框架的特点;第二,框架对现有pm2.5预测理论或方法的贡献。
本申请的框架的一个重要特点是通过比较不同模型在特定场景下的估计或预测效果,选择或证明了最合适的方法,因此该方法可以被描述为相对客观和高精度的方法。第二个特点是该框架在时间预测部分不需要任何其他辅助数据集,因为本申请中的convlstm模型的预测机制是基于时间自相关和空间自相关的内在机制,通过训练历史时空pm2.5分布。第三个特点是框架从多源原始数据集出发,经过数据融合、预测模型参数估计或自动选取等过程,最终得到可直接用于其他研究的预测产品。在这个过程中,框架考虑并解决了大部分可能存在的问题:例如,pm2.5浓度值只有站场数据,本申请以aod为基础,其他气象因子为辅助,输入xgboost模型,建立估计模型,得到空间上连续的pm2.5分布来求解;根据aod空间缺失值问题,采用bsss方法来弥补或填补aod的缺失值,使aod能够覆盖整个研究区域,进而转化为pm2.5的空间分布。
本申请不仅从数据科学理论的角度,而且从高效、高精度预测pm2.5浓度时空分布的角度,对实际问题的研究具有重要意义。
本申请提出了一个框架,不仅可以估计空间上连续的pm2.5浓度分布,而且还可以预测未来的分布。时间和空间的分辨率都是细粒度的。另外,在估计过程中,比较了一些流行的回归模型和机器学习方法,选择最准确的模型作为框架中的确定算法。在预测过程中,采用了convlstm模型,并将其与传统的时间序列预测模型季节自回归综合移动平均(sarima)进行了比较,证明了该模型是一种精确的深度学习模型。
本文的预测框架与以往的单一预测研究有着明显的不同,因为它是基于底层的原始数据。将空间pm2.5浓度估计与机器学习方法进行比较,得到了pm2.5浓度的空间连续分布,最后用深度学习方法预测了细颗粒pm2.5浓度的时空分布。在此之前,还没有一个完整的空间估计和时间估计相结合的预测框架,也没有很多研究能够在更精确的空间分辨率和时间分辨率水平上进行时间和空间的同步预测。此外,从模型应用的角度,首次将convlstm模型应用于pm2.5浓度时空分布的预测,结果也表明了该算法在该领域的有效性。因此,本研究为pm2.5浓度的时空预测方法和过程开辟了新的视角。
在当今时代,高精度、细粒度的pm2.5浓度时空预测在公共安全和环境保护决策中越来越重要。同时,pm2.5浓度数据的多源异质性和处理流程的不一致性,使得越来越多的学者和组织没有一个统一的研究框架。在这种情况下,一个完整、统一、高效、高精度的预测框架就显得尤为重要。因此,本文的研究框架使得基于原始多源数据的pm2.5浓度预测成为可能。
本文以石家庄市为例,利用气溶胶光学厚度(aod)数据和其他补充原始数据,提出了一个完整的pm2.5浓度日分布预测框架。框架由3个主要部分和9个步骤组成。在第一部分中,框架得到了精细的时空aod分布,然后在第二部分中建立了一个机器学习模型来估计pm2.5浓度的空间分布。最后,在训练细粒度pm2.5时空分布的基础上,利用convlstm对空间分辨率为3300×3300m的测试分布进行了预测,并与sarima模型进行了比较,验证了模型的准确性。
第二部分比较了几种常用的回归模型和机器学习模型,包括线性回归、岭回归、套索回归、立体主义回归和xgboost回归,建立了pm2.5监测值与aod、湿度、降水、反照率、ndvi、风速和海拔的关系。通过优化参数和交叉验证,确定了xgboost作为该框架下的估算模型,其rmse最低为32.86μg/m3,r2最高为0.71。同时,针对aod在空间上存在多个缺失值的问题,提出了一种块统计和缺失值填充(bsmp)方法,使aod成为整体空间连续分布。在第三部分中,convlstm有望成为一种适用于时空细颗粒pm2.5浓度预测的深度学习方法。经过10次时间和空间上的验证和与sarima的比较,convlstm的预测结果更为准确,总平均预测rmse为14.94μg/m3,而sarima为17.41μg/m3。具体来说,在时间尺度上,convlstm比sarima更稳定,预测波动较小,而在空间比较上,convlstm比sarima更能消除预测精度的空间差异。
该框架将空间估计和时间预测相结合,形成一个完整的框架,为希望利用原始数据集预测整个研究区域内pm2.5浓度分布的工作人员提供了很大的方便。
本领域技术人员应理解,以上实施例仅是示例性实施例,在不背离本申请的精神和范围的情况下,可以进行多种变化、替换以及改变。
- 还没有人留言评论。精彩留言会获得点赞!