一种适用于端子排的自底向上光学字符识别方法与流程
本发明属于图像识别技术领域,涉及对电子设备的文字识别,用于对变电站二次回路接线进行智能识别,为一种适用于端子排的自底向上光学字符识别方法。
技术背景
智能变电站数字化设计与建设目前正在进行中,相关的二次系统设计软件侧重点比较分散,缺乏系统性和标准化,尚未形成全面的数字化正向设计流程和方法。基于物联感知的识别技术可对变电站二次回路接线进行智能识别,与cad图纸进行智能对比,可以快速发现变电站现场与竣工图纸不一致的潜在风险。
光学字符识别(opticalcharacterrecognition)简称ocr,属于模式识别的分支。ocr是一个获取文字及版面信息的过程,在这个过程中,输入图像进行文字识别,并以文本的形式返回。其工作原理是通过扫描仪、数码相机等光学输入设备获取纸张上的文字图片信息,采用光学方式将文档资料转换成由黑白点阵构成的图像文件,再利用模式识别算法分析文字体态特征,判断识别出字符文字,进而通过识别软件将图片中的文字转换成文本格式。
ocr技术具有准确性高、稳定性强、适用性高、简单易用、应用广泛等特点。经过几十余年的信息技术发展,ocr文字识别技术也得到了深度开发研究,主要应用于身份证、银行卡、名片等卡证类识别以及票据等印刷体识别,可以有效代替人工信息录入,并支持定制开发。
目前,ocr技术大多采用人工设计的特征(hog)对图像进行特征提取,然而hog对于图像模糊、扭曲等问题鲁棒性很差,对复杂场景的泛化能力不佳。传统技术中的文本识别采用模版匹配的方式进行分类,对于文本行,要么识别每一个字符来确定最终文字行的内容,要么通过滑动窗口对每一个可能的字符进行匹配。前者方法会造成字符的分割破碎,而后者的准确率依赖于滑动窗口的尺寸,滑动过大会造成信息丢失,滑动过小则会造成计算量增加。
在识别场景上,大致可以分为特定场景的专用ocr和多种场景的通用ocr。证件识别、车牌识别等就是专用ocr的典型案例,通用ocr也可以用在更复杂的场景上。而对于智能变电站数字化设计与建设来说,当前的主要问题是,尚未存在针对变电站端子排特定场景的专用ocr技术,又因为通用场景中图片不固定且文字布局多样,通用ocr方法亦不能为智能变电站中的端子排提供高识别率的效果。所以,研究适用于端子排的光学字符识别技术具有重要意义。
针对自然场景中的文字识别,现有技术也有提出对场景文本检测技术。从实际应用场景的角度而言,现有的场景文本检测技术主要关注开放场景下的显著文本区域检测,例如横幅、广告牌等。这些文本信息具有集中性、显著性等特征;而在变电站端子排场景下,需要识别的目标区域为大量细小标签,空间分布离散,文字细小,光照偏弱,容易出现遮挡,而且精密零件比开放场景中的物体更容易被误认为是文字,例如螺孔被误认为0或o。因此一方面需要调整热力图生成模式,增强图像边缘标签区域的召回率,另一方面需要增强深度模型的鲁棒性,引入大量负样本学习数据,减少端子排零件被误认为字符的概率。
技术实现要素:
本发明要解决的问题是:解决传统光学字符识别技术在变电站端子排的实际应用场景中可能产生的识别准确率不高的问题,目的是对变电站端子排电缆套管标号快速并准确的识别。
本发明的技术方案为:一种适用于端子排的自底向上光学字符识别方法,采集变电站端子排内容图像并进行预处理,对预处理之后的图像,采用自底向上的方法,检测细粒度字符文本后将其连接成粗粒度的文本区域,最后训练一个文本识别网络,识别粗粒度的文本区域,输出端子排识别结果。
进一步的,所述预处理包括几何变换、畸形矫正、去除模糊和图像增强。
进一步的,自底向上的方法具体为:
1)采用高斯热力图的vgg16网络将每一个字符为检测目标替代传统的将文本框作为检测目标,使用小感受野来预测文本,只关注字符级别,获得每个字符的坐标框,得到细粒度文本;
2)根据字符的中心点(x,y)、欧式距离d、角度θ信息,判断两字符是否处于同一文本区域;
3)根据步骤2)的判断结果,将属于同一文本区域的字符合并成为文本行区域,并通过双向长短期记忆网络,即双向lstm(longshort-termmemory),保留提取文本的上下文特征,输出每个文本行区域的坐标框,即粗粒度的文本区域;
4)训练识别网络,对粗粒度的文本区域进行文字识别,将字符坐标框信息、文本行区域的坐标框信息以及文本上下文特征输入到文字识别程序中,输出文本信息;所述文字识别程序为一个resnet识别网络,训练resnet识别网络时,损失函数采用ctcloss,在损失值达到最低时,即认为识别成功;
5)对识别出的文本信息进行贪心编码greedydecoder,贪心策略为:选择的词有最高的可能性;
6)生成并输出最终的文本结果。
本发明方法提供了一种针对变电站端子排的实际应用场景,研究变电站端子排电缆套管标号的深度识别技术。从深度学习的ocr角度出发,将检测与识别统一到同一个工作流中,一方面利用卷积特征进行检测,另一方面提取定向文本的算符进行识别。由于采用自底向上的方法,检测细粒度字符文本后将其连接成粗粒度的文本区域,相比现有技术的模板匹配或滑窗检测,更能适应端子排的检测场景,具有更好的精度。由于简化了工作流,实现了端到端处理,网络的运算开销大幅降低,近乎达到了实时速度,可实现对电缆套管标号快速并准确的识别。
本发明的有效利益是:提出了一种适用于端子排的自底向上光学字符识别技术,有助于解决传统光学字符识别技术在变电站端子排的实际应用场景中可能产生的识别准确率不高的问题,实现对变电站端子排电缆套管标号快速并准确的识别。本发明方法具有良好的广泛性与实用性。
附图说明
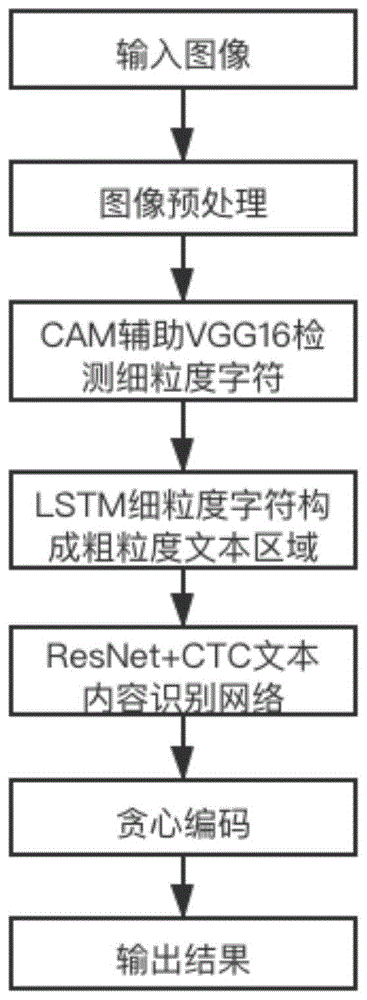
图1为本发明的实施流程图。
图2为本发明端子排字符识别过程中的相关结果:2a为原图、2b为热力图字符检测结果、2c为最终识别结果。
图3为对比实验效果图,作为对比的是cnocr方法。
图4为对比实验效果图,作为对比的是tesseractocr方法。
具体实施方式
本发明提出了一种适用于端子排的自底向上光学字符识别技术,如图1所示,包括以下步骤:
1)对输入的内容图像进行图像预处理,包括:几何变换(透视、扭曲、旋转等)、畸形矫正、去除模糊、图像增强。
2)对输入的内容图进行文字检测。一方面,考虑到变电站端子排内容图像的文字具有密集性与微小性的特点,使用传统的像素级分割方法会因分割破碎而导致大量信息遗失。另一方面,ocr技术并不是简单的字符识别,ocr技术发展趋势中的一个关键步骤是将字符划分为文本,以文本为单位进行输出。综合以上两方面考虑,本发明提出的适用于端子排的光学字符识别技术,利用了单个字符相较于文本行更容易被检测到的特性、以及ocr技术输出以文本为单位的重要指标,通过自底向上的方法,检测细粒度文本后将其连接成粗粒度的文本区域。
2.1)采用高斯热力图将每一个字符为检测目标替代传统的将文本框作为检测目标。使用小感受野来预测文本,只需要关注字符级别,而不需要关注整个文本。在这个过程中,可以获得每个字符的坐标框,得到细粒度文本。
由于没有端子排实用场景字符级别的标签,所以需要进行人工标注数据集,整体网络的骨干采用经典卷积神经网络vgg16进行模型训练。由于数据集不大,尽管模型收敛很好,也还是会担心过拟合。因此本发明采用高斯热力图cam可视化网络,指导分类的高相应区是否落在目标的核心部位上。使用grad-cam对卷积网络中的特征图进行加权求和,可获得卷积conv5的热力图。对conv5梯度进行平均求和等降维操作,得到每个通道权重,则该权重与conv5的乘积即是热力图。
之后便可以用训练好的模型进行字符预测,预测出的结果为字符的坐标框。
2.2)在得到字符坐标框信息之后,需要考虑到两个字符间的紧密程度,本发明采用以下策略判断两字符是否处于同一个文本区域:设字符m的坐标框左上,右上,右下,左下的坐标值为[(x1,y1),(x2,y2),(x3,y3),(x4,y4)],则字符m的中心点坐标值(xm,ym)为:
同理得到字符n的中心点坐标值(xn,yn),计算两个字符间的欧式距离d及两个字符间的角度θ可。
如果两个字符欧式距离d不超过任一字符长度的k倍,k=1.5~2,并且相对位置的角度θ在三十度以内,则将两字符判断为同一个文本区域内,所述字符的长度由字符坐标框求得。
2.3)在细粒度文本形成的序列中提取文本的位置特征、大小特征、距离特征等,将多个字符合并成为文本行区域。同时,在检测网络中加入双向长短期记忆网络,即双向lstm(longshort-termmemory),保留提取文本的上下文特征。输出每个文本行区域的坐标框,即粗粒度的文本区域。
3)对粗粒度的文本区域进行文字识别。考虑到变电站端子排的内容由中文、数字、字母构成,而现有的文字识别方法中大多只针对字母,并且现有库函数cnocr、tesseractocr等方法在电网端子排上的识别成功率与查全率非常低。因此,为变电站端子排的应用场景设计专用的文字识别方法端到端ocr显得尤为重要。
3.1)将步骤2得到的字符坐标信息、文本行区域的坐标框信息以及文本上下文特征输入到文字识别程序中。
3.2)对文本行区域信息进行识别解读。训练一个resnet识别网络,以端子排的字符信息为正样本,遮盖字符信息后的端子排零件和机体为负样本,正样本的重点在中文和英文字母的识别上,以大量正负样本提高识别效果,并通过fine-tune来提高网络的召回率,识别模型的损失函数采用ctcloss,在损失值达到最低时,即可认为识别成功。
4)对识别出的文本进行贪心编码greedydecoder。输入为步骤3的文本字符识别结果。贪心策略为:选择的词有最高的可能性。
5)生成并输出最终的文本结果。
本发明通过grad-cam卷积网络调整热力图的生成模式,通过fine-tune增强图像边缘标签区域的召回率,通用ocr的识别模型召回率偏低的原因是需要考虑multi-scale的目标特征,而在本发明的特殊场景下,目标文字区域在视觉特征上具有较高相似性,因此能够通过大量正样本提高检测效果。同时,本发明通过负样本学习增强识别网络的鲁棒性,即增强识别网络对形似文字的端子排零件的抗干扰能力,通过引入大量负样本学习数据,减少端子排零件被误认为字符的概率。
下面通过一个实施例来说明本发明的实施效果。如图2,为本发明端子排字符识别过程中的相关结果:2a原图、2b热力图字符检测结果、2c最终识别结果。根据图2a中字符位置对端子排标号字符识别,分行分组显示端子标号,输出内容有:字符检测结果、文本区域组合结果、文本坐标框、损失值、ocr识别结果等。
对于图2a,本发明提出的ocr最终识别结果为:
[([[1185,0],[2097,0],[2097,1170],[1185,1170]],'噩',0.04774947464466095),([[2293.073760108954,36.6958881416402],[2825.2697736977034,-37.295655177868014],[2835.926239891046,70.3041118583598],[2303.7302263022966,145.295655177868]],'{{31-700',0.013211743906140327),([[794.9729724270165,308.52432279564647],[1172.6591405368385,277.5465768478958],[1173.0270275729833,353.47567720435353],[795.3408594631616,384.4534231521042]],'2-11!-02',0.17125189304351807),([[2155,638],[2735,638],[2735,813],[2155,813]],']9/37-130',0.2961055636405945),([[2081,653],[2131,653],[2131,731],[2081,731]],'`',0.15301477909088135),([[781,693],[1107,693],[1107,767],[781,767]],'<-11~-2',0.00875504408031702),([[2152,749],[2747,749],[2747,932],[2152,932]],'71737-130',0.13049180805683136),([[757,848],[1117,848],[1117,914],[757,914]],'2-1711-32',0.19352556765079498),([[754,983],[1029,983],[1029,1063],[754,1063]],'2-1011-',0.29757118225097656),([[2132,994],[2698,994],[2698,1122],[2132,1122]],'13/31-130',0.2559000253677368),([[1405,1151],[1739,1151],[1739,1297],[1405,1297]],'17yd',0.828555166721344),([[983,1177],[2000,1177],[2000,3022],[983,3022]],'-',0.014384046196937561),([[837,1352],[1027,1352],[1027,1414],[837,1414]],'17r-{',0.10394155234098434),([[2068,1406],[2671,1406],[2671,1558],[2068,1558]],'}01/6y-139',0.09370764344930649),([[812,1516],[1017,1516],[1017,1593],[812,1593]],'17n-7',0.5051735043525696),([[800,1763],[1005,1763],[1005,1828],[800,1828]],'17n-2',0.9220134615898132),([[2052.400748596673,1849.0149719334659],[2581.9786713894946,1976.2848554394332],[2551.599251403327,2072.985028066534],[2022.0213286105056,1945.7151445605668]],'37(67-739',0.1972402036190033),([[803,1883],[999,1883],[999,1948],[803,1948]],'17n-8',0.7876468300819397),([[2038.2641763362813,2014.019350389345],[2584.9999071014317,2121.948998516935],[2554.7358236637187,2231.9806496106553],[2008.000092898568,2124.051001483065]],'5({&y-139',0.049937840551137924),([[1910,2070],[1951,2070],[1951,2136],[1910,2136]],'5',0.15687693655490875),([[1845,2641],[1883,2641],[1883,2705],[1845,2705]],'9',0.9823218584060669),([[1826,2782],[1889,2782],[1889,2851],[1826,2851]],'i',0.5894415974617004),([[1373.9745072926244,2963.052720738457],[1519.4072414306354,2991.608273497798],[1499.0254927073756,3079.947279261543],[1353.5927585693646,3051.391726502202]],'td',0.9926967024803162),([[1004,2997],[1408,2997],[1408,3922],[1004,3922]],'自',0.04060424491763115),([[1610,3554],[2236,3554],[2236,3692],[1610,3692]],'2020[05[27',0.6145601868629456),([[2279,3557],[2598,3557],[2598,3692],[2279,3692]],'19:30',0.9293652176856995),([[839.5137993254474,3763.0197317030033],[963.7226795396045,3851.1969639806725],[930.4862006745526,3897.9802682969967],[806.2773204603955,3808.8030360193275]],”,0.0007631320622749627),([[786.367069592015,3887.025076859389],[948.9347662733124,3968.980449026334],[916.632930407985,4028.974923140611],[754.0652337266876,3948.019550973666]],'2~40$',0.006789735052734613)]。
上述识别结果包括:文本框坐标信息、文本识别内容、和相应的损失值。整理后列出最终的文本识别内容如下。
1.噩、2.31-700、3.2-11!-02、4.9/37-130'、5.-11~-2、6.71737-130、7.2-1711-32、8.2-1011-、9.13/31-130'、10.17yd、11.-、12.17r-、13.01/6y-139、14.17n-7、15.17n-2、16.37(67-739、17.17n-8、18.5({&y-139、19.5、20.9、21.1
作为对比,对于图2a也使用现有技术进行识别,图3为cnocr方法的对比实验效果图,图4为tesseractocr方法的对比实验效果图。需要注意的是,主流方法cnocr与tesseractocr均不是端到端处理方法,检测中需要提供带有文本的区域坐标信息。在做对比实验过程中,将由步骤2求取得到的细粒度文本信息输入到cnocr和tesseractocr中,得到结果如图3和图4的对比效果。综合对比图2c和图3图4的结果,可见本发明提出的方法在查全率和查准率方面均最好,具有良好的实际应用意义。
- 还没有人留言评论。精彩留言会获得点赞!