故障预测方法、装置、设备及可读存储介质与流程
本发明涉及运维
技术领域:
,尤其涉及一种故障预测方法、装置、设备及可读存储介质。
背景技术:
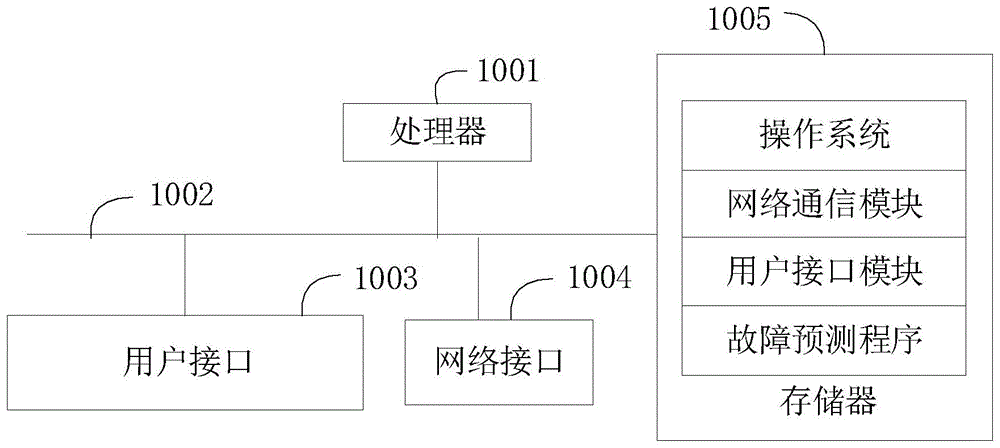
:随着通信系统复杂度不断提升,其出现故障的概率也越来越大,一旦出现故障将造成巨大损失。为了避免系统故障带来的损失,目前常用的方式为机器学习训练得到的故障预测模型对通信系统进行故障预测,从而及时排出故障隐患。但是目前在训练故障预测模型时,一般是使用系统性能指标如cpu占用率、内存占用率等作为训练使用的样本数据。即后续在使用训练得到的故障预测模型对系统进行故障预测时,也仅仅只使用cpu占用率、内存占用率作为预测基础,而忽视了其他因素对系统稳定性的影响,从而导致预测结果不够准确。技术实现要素:本发明的主要目的在于提供一种故障预测方法、装置、设备及可读存储介质,旨在解决现有技术中使用片面的信息进行故障预测,导致预测结果不够准确的技术问题。第一方面,本发明提供一种故障预测方法,所述故障预测方法包括以下步骤:构建训练集,所述训练集包括n个训练样本,一组训练样本包括系统性能信息的量化值、场景信息的量化值、堆栈信息的量化值、堆栈信息对应的进程信息的量化值以及故障信息的量化值,n为大于1的正整数;基于所述训练集,对循环神经网络模型进行训练,得到故障预测模型;通过所述故障预测模型,对系统故障进行预测。可选的,所述构建训练集,所述训练集包括n个训练样本,一组训练样本包括系统性能信息的量化值、场景信息的量化值、堆栈信息的量化值、堆栈信息对应的进程信息的量化值以及故障信息的量化值,n为大于1的正整数的步骤包括:获取系统在第一时刻的系统性能信息、场景信息、堆栈信息、堆栈信息对应的进程信息,以及故障信息;基于性能量化规则,得到所述系统性能信息的量化值;基于场景与数值的对应关系,得到所述场景信息的量化值;从所述堆栈信息对应的堆栈中取出s个内核函数,分别对所述s个内核函数进行哈希计算,得到s个哈希值,以所述s个哈希值组成所述堆栈信息的量化值,s为大于1的正整数;对所述进程信息对应的进程进行哈希计算,以计算得到的哈希值作为所述进程信息的量化值;基于所述故障信息确定系统在第一时刻的故障类型,将预置m维向量中所述故障类型对应的目标维度上的分量设置为第一数值,除所述目标维度以外的其他维度上的分量设置为第二数值,得到新的m维向量,以所述新的m维向量作为所述故障信息的量化值;以所述系统性能信息的量化值、场景信息的量化值、堆栈信息的量化值、堆栈信息对应的进程信息的量化值以及故障信息的量化值作为第一训练样本;以此类推,直至得到n个训练样本,n为大于1的正整数;以所述n个训练样本构建得到训练集。可选的,所述从所述堆栈信息对应的堆栈中取出s个内核函数的步骤包括:从所述堆栈信息对应的堆栈的栈顶以及栈底上取出内核函数,从所述堆栈信息对应的堆栈的次栈顶以及次栈底上取出内核函数,以此类推,直至取出s个内核函数。可选的,所述故障预测方法还包括:当只能从所述堆栈信息对应的堆栈中取出p个内核函数时,所述p为小于s的正整数,分别对所述p个内核函数进行哈希计算,得到p个哈希值;以所述p个哈希值以及q个第三数值,组成所述堆栈信息的量化值,所述q=s-p。可选的,在得到所述n个训练样本对应的时间段内,所述系统经过至少一次版本升级。第二方面,本发明还提供一种故障预测装置,所述故障预测装置包括:构建模块,用于构建训练集,所述训练集包括n个训练样本,一组训练样本包括系统性能信息的量化值、场景信息的量化值、堆栈信息的量化值、堆栈信息对应的进程信息的量化值以及故障信息的量化值,n为大于1的正整数;训练模块,用于基于所述训练集,对循环神经网络模型进行训练,得到故障预测模型;预测模块,用于通过所述故障预测模型,对系统故障进行预测。第三方面,本发明还提供一种故障预测设备,所述故障预测设备包括处理器、存储器、以及存储在所述存储器上并可被所述处理器执行的故障预测程序,其中所述故障预测程序被所述处理器执行时,实现如上所述的故障预测方法的步骤。第四方面,本发明还提供一种可读存储介质,所述可读存储介质上存储有故障预测程序,其中所述故障预测程序被处理器执行时,实现如上所述的故障预测方法的步骤。本发明中,构建训练集,所述训练集包括n个训练样本,一组训练样本包括系统性能信息的量化值、场景信息的量化值、堆栈信息的量化值、堆栈信息对应的进程信息的量化值以及故障信息的量化值,n为大于1的正整数;基于所述训练集,对循环神经网络模型进行训练,得到故障预测模型;通过所述故障预测模型,对系统故障进行预测。本发明考虑到系统性能信息、内核态的信息(堆栈信息)、用户态的信息(堆栈信息对应的进程信息)以及场景信息均是系统故障的诱因,因此,综合多个方面的信息,构建训练集,从而对循环神经网络模型进行训练,得到故障预测模型。后续,使用故障预测模型对系统故障进行预测时,也需使用多方面的信息作为预测基础,可显著提高故障预测准确度。附图说明图1为本发明实施例方案中涉及的故障预测设备的硬件结构示意图;图2为本发明故障预测方法一实施例的流程示意图;图3为一实施例中对内核函数进行哈希转换的示意图;图4为一实施例中堆栈的示意图;图5为一实施例中一训练样本的示意图;图6为本发明故障预测装置一实施例的功能模块示意图。本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。具体实施方式应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。第一方面,本发明实施例提供一种故障预测设备,该故障预测设备可以是个人计算机(personalcomputer,pc)、笔记本电脑、服务器等具有数据处理功能的设备。参照图1,图1为本发明实施例方案中涉及的故障预测设备的硬件结构示意图。本发明实施例中,故障预测设备可以包括处理器1001(例如中央处理器centralprocessingunit,cpu),通信总线1002,用户接口1003,网络接口1004,存储器1005。其中,通信总线1002用于实现这些组件之间的连接通信;用户接口1003可以包括显示屏(display)、输入单元比如键盘(keyboard);网络接口1004可选的可以包括标准的有线接口、无线接口(如无线保真wireless-fidelity,wi-fi接口);存储器1005可以是高速随机存取存储器(randomaccessmemory,ram),也可以是稳定的存储器(non-volatilememory),例如磁盘存储器,存储器1005可选的还可以是独立于前述处理器1001的存储装置。本领域技术人员可以理解,图1中示出的硬件结构并不构成对本发明的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。继续参照图1,图1中作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及故障预测程序。其中,处理器1001可以调用存储器1005中存储的故障预测程序,并执行本发明实施例提供的故障预测方法。第二方面,本发明实施例提供了一种故障预测方法。参照图2,图2为本发明故障预测方法一实施例的流程示意图。一实施例中,故障预测方法包括以下步骤:步骤s10,构建训练集,所述训练集包括n个训练样本,一组训练样本包括系统性能信息的量化值、场景信息的量化值、堆栈信息的量化值、堆栈信息对应的进程信息的量化值以及故障信息的量化值,n为大于1的正整数;现有技术中,对系统进行故障诊断只关注系统本身的性能信息,例如cpu利用率,内存利用率等,而忽视了其他因素带来的风险。基于此,本实施例中,在构建用于对循环神经网络模型进行训练的训练集时,除了需要考虑系统本身的性能信息外,还关注系统的场景信息、系统的内核态信息、系统的用户态信息,其中,系统的内核态信息即系统cpu内核的堆栈信息,系统的用户态信息即系统cpu内核的堆栈信息所对应的进程信息。容易理解的是,若系统由多个cpu内核,则对应有多个堆栈信息,以及每个堆栈信息对应的进程信息。且为了便于对循环神经网络模型进行训练,还需要将上述信息进行量化,得到具体的量化值。因此,一组训练样本包括系统性能信息的量化值、场景信息的量化值、堆栈信息的量化值、堆栈信息对应的进程信息的量化值以及故障信息的量化值,n组训练样本即组成训练集。n根据实际需要进行设置,例如设置为10000。步骤s20,基于所述训练集,对循环神经网络模型进行训练,得到故障预测模型;本实施例中,基于训练集对循环神经网络模型进行训练,即分别将每个训练样本包括的系统性能信息的量化值、场景信息的量化值、堆栈信息的量化值、堆栈信息对应的进程信息的量化值作为循环神经网络模型的输入,并将循环神经网络模型输出的值分别与每个训练样本包括的故障信息的量化值进行对比,若一致,则记为1,不一致则记为0,并统计记为1的次数在总次数n中所占的比例。若比例大于预设比例,则认为训练完成,否则调整循环神经网络模型的模型参数,并重复上述步骤,直至统计记为1的次数在总次数n中所占的比例大于预设比例时,以此时的循环神经网络模型作为故障预测模型。步骤s30,通过所述故障预测模型,对系统故障进行预测。本实施例中,基于上述步骤s10至步骤s20得到故障预测模型后,便可以系统的实时数据作为故障预测模型的输入,输入故障预测模型中,故障预测模型的输出即系统故障预测结果,从而可以根据故障预测结果,进行故障定位。其中,系统的实时数据包括某时刻系统性能信息的量化值、场景信息的量化值、堆栈信息的量化值、堆栈信息对应的进程信息的量化值。本实施例中,构建训练集,所述训练集包括n个训练样本,一组训练样本包括系统性能信息的量化值、场景信息的量化值、堆栈信息的量化值、堆栈信息对应的进程信息的量化值以及故障信息的量化值,n为大于1的正整数;基于所述训练集,对循环神经网络模型进行训练,得到故障预测模型;通过所述故障预测模型,对系统故障进行预测。本实施例考虑到系统性能信息、内核态的信息(堆栈信息)、用户态的信息(堆栈信息对应的进程信息)以及场景信息均是系统故障的诱因,因此,综合多个方面的信息,构建训练集,从而对循环神经网络模型进行训练,得到故障预测模型。后续,使用故障预测模型对系统故障进行预测时,也需使用多方面的信息作为预测基础,可显著提高故障预测准确度。进一步地,一实施例中,步骤s10包括:步骤s101,获取系统在第一时刻的系统性能信息、场景信息、堆栈信息、堆栈信息对应的进程信息,以及故障信息;本实施例中,第一时刻可以是人为设置的一个时刻,当时间点到达第一时刻时,获取系统的系统性能信息,场景信息、堆栈信息、堆栈信息对应的进程信息,以及故障信息。另一实施例中,第一时刻还可以是系统发生故障的时刻。例如,通过kprobe设置一个动态探测点,如果t1时刻发现信号如sigill非法指令,则认为系统发生了故障,则获取t1时刻的系统性能信息、场景信息、堆栈信息、堆栈信息对应的进程信息,以及故障信息。或是,在t1时刻检测到系统输出的日志中包括目标关键字:“outofmemory”,“kernelpanic”,“oops”则认为系统发生了故障,则获取t1时刻的系统性能信息、场景信息、堆栈信息、堆栈信息对应的进程信息,以及故障信息。其中,系统性能信息包括:cpu、内存占用率和io访问率;场景信息即系统所处的场景,系统所处的场景为升级重启,倒换请求失败,自动版本回退,正常运行中的任一种;堆栈信息为系统cpu内核的堆栈信息,堆栈信息是设备在内核态运行的表现,堆栈信息从上到下反映了用户程序对系统内核函数调用顺序;对堆栈信息对应的堆栈中的最顶层函数利用内核的kprobe,tracepoint技术,即可确定堆栈信息对应的进程的进程信息;故障信息即系统的故障情况,通过对系统信号跟踪捕获和/或在系统日志中查找关键字的方式确定,故障类型包括:系统段错误;超过cpu门限;超过内存门限;死锁;oom;cpustall;系统oops,panic;系统调度异常;非法指令;进程d状态;其他。步骤s102,基于性能量化规则,得到所述系统性能信息的量化值;本实施例中,系统性能信息包括:cpu、内存占用率和io访问率。由于cpu、内存占用率和io访问率均是具体的值,则性能量化规则可以是:cpu占用率的量化值=cpu占用率;内存占用率的量化值=内存占用率;io访问率的量化值=io访问率。例如,cpu占用率为50%、内存占用率为35%、io访问率为2%,则量化值分别为0.5、0.35、0.02。当然,性能量化规则还可以是:cpu占用率的量化值=cpu占用率×100;内存占用率的量化值=内存占用率×100;io访问率的量化值=io访问率×100。例如,cpu占用率为50%、内存占用率为35%、io访问率为2%,则量化值分别为50、35、2。步骤s103,基于场景与数值的对应关系,得到所述场景信息的量化值;本实施例中,预先各个场景对应的数值,例如,场景1(升级重启)对应的数值为1,场景2(倒换请求失败)对应的数值为2,场景3(自动版本回退)对应的数值为3,场景4(正常运行)对应的数值为4。若场景信息为升级重启,则场景信息的量化值为1,同理,若场景信息为倒换请求失败,则场景信息的量化值为2......以此类推。容易理解的是,场景与数值的对应关系根据实际需要进行设置,在此不作限制。步骤s104,从所述堆栈信息对应的堆栈中取出s个内核函数,分别对所述s个内核函数进行哈希计算,得到s个哈希值,以所述s个哈希值组成所述堆栈信息的量化值,s为大于1的正整数;本实施例中,堆栈信息指cpu内核的堆栈信息,堆栈信息从上到下反映了用户程序对系统内核函数调用顺序。从堆栈信息对应的堆栈中取出s个内核函数,分别对s个内核函数进行哈希计算,得到s个哈希值,以s个哈希值组成堆栈信息的量化值,s为大于1的正整数,例如s取值为11。其中,可以是从堆栈的栈顶依次向下,取出s个内核函数;还可以是,从堆栈的栈顶依次向下,取出若干个内核函数,从堆栈的栈底依次向上,取出若干个内核函数,共计取出s个内核函数。容易理解的是,现在的cpu一般为多核cpu,则堆栈信息包括每个cpu内核的堆栈信息。例如,系统cpu为8核cpu,则堆栈信息包括内核1的堆栈信息1、内核2的堆栈信息2、......、内核8的堆栈信息8。以内核1的堆栈信息1为例,则从堆栈信息1对应的堆栈中取出s个内核函数,分别对所述s个内核函数进行哈希计算,得到s个哈希值,以s个哈希值组成堆栈信息1的量化值1。同理,对内核2的堆栈信息2、内核3的堆栈信息3、......、内核8的堆栈信息8做同样处理,以得到的量化值1至量化值8组成堆栈信息的量化值。参照图3,图3为一实施例中对内核函数进行哈希转换的示意图。如图3所示,图3左侧从上到下依次为9个内核函数,图3右侧即为每个内核函数对应的哈希值。其实质即通过哈希算法将内核函数转换为长度一定的字符串。进一步地,一实施例中,所述从所述堆栈信息对应的堆栈中取出s个内核函数的步骤包括:从所述堆栈信息对应的堆栈的栈顶以及栈底上取出内核函数,从所述堆栈信息对应的堆栈的次栈顶以及次栈底上取出内核函数,以此类推,直至取出s个内核函数。本实施例中,从堆栈中取出内核函数的方式为:从堆栈信息对应的堆栈的栈顶以及栈底上取出内核函数,从堆栈信息对应的堆栈的次栈顶以及次栈底上取出内核函数,以此类推,直至取出s个内核函数。这是因为考虑到栈顶是直接调用的第一个内核函数,如果系统发生了故障,其反映了第一现场,即调用什么函数发生故障。而栈底是操作系统基础函数,同一类操作最后一般会调用同函数,故障与哪类操作有关,可从此层总结归类。而次顶,次底是与其相关的第二层,以此类推。并且这种方式易于进程调用关系同层级的对齐,在有限层次下最大限度对调用直接系统函数和系统函数类信息进行保留。进一步地,一实施例中,所述故障预测方法还包括:当只能从所述堆栈信息对应的堆栈中取出p个内核函数时,所述p为小于s的正整数,分别对所述p个内核函数进行哈希计算,得到p个哈希值;以所述p个哈希值以及q个第三数值,组成所述堆栈信息的量化值,所述q=s-p。本实施例中,参照图4,图4为一实施例中堆栈的示意图。当一堆栈信息对应的堆栈如图4所示时,只能从堆栈中取出9个内核函数,若s为11,则以9个内核函数的哈希值以及2个第三数值,组成堆栈信息的量化值。其中,第三数值根据实际需要进行设置,例如以0作为第三数值。步骤s105,对所述进程信息对应的进程进行哈希计算,以计算得到的哈希值作为所述进程信息的量化值;本实施例中,直接对进程信息对应的进程进行哈希计算,以计算得到的哈希值作为进程信息的量化值。步骤s106,基于所述故障信息确定系统在第一时刻的故障类型,将预置m维向量中所述故障类型对应的目标维度上的分量设置为第一数值,除所述目标维度以外的其他维度上的分量设置为第二数值,得到新的m维向量,以所述新的m维向量作为所述故障信息的量化值;本实施例中,m的数值根据系统故障类型的种类进行确定。例如,系统故障类型包括:系统段错误;超过cpu门限;超过内存门限;死锁;oom;cpustall;系统oops,panic;系统调度异常;非法指令;进程d状态;其他。共计12个类型,则m设置为12。其中,预置12维向量每个维度上的分量与一个故障类型对应,例如,第一维度上的分量与系统段错误对应,第二维度上的分量与超过cpu门限对应......以此类推。参见表1,表1为一实施例中各个维度上的分量与故障类型的对应关系表。第一维度上的分量系统段错误第二维度上的分量超过cpu门限第三维度上的分量超过内存门限第四维度上的分量死锁第五维度上的分量oom第六维度上的分量cpustall第七维度上的分量系统oops第八维度上的分量panic第九维度上的分量系统调度异常第十维度上的分量非法指令第十一维度上的分量进程d状态第十二维度上的分量其他若根据故障信息确定系统在第一时刻的故障类型为死锁,则将第四维度上的分量设置为第一数值,将第一至第三、第五至第十二维度上的分量设置为第二数值。例如,第一数值为1,第二数值为0,则得到的新的m维向量为(0,0,0,1,0,0,0,0,0,0,0,0),并以新的m维向量作为故障信息的量化值。步骤s107,以所述系统性能信息的量化值、场景信息的量化值、堆栈信息的量化值、堆栈信息对应的进程信息的量化值以及故障信息的量化值作为第一训练样本;本实施例中,训练样本包括两部分的数据,一部分为用于输入循环神经网络的数据,另一部分为标注数据。将上述得到的系统性能信息的量化值、场景信息的量化值、堆栈信息的量化值、堆栈信息对应的进程信息的量化值进行组合,得到用于输入循环神经网络的数据,以故障信息的量化值作为标注数据。参照图5,图5为一实施例中一训练样本的示意图。如图5所示,对一单核cpu而言,若上述q值取11,则训练样本中用于输入循环神经网络的数据为:cpu占用率的量化值(1维)、内存占用率的量化值(1维)、io访问率的量化值(1维)、场景信息的的量化值(1维)、进程信息的量化值(1维)、堆栈信息的量化值(11维),共计16维数据。容易理解的是,若cpu为8核cpu,则训练样本中用于输入循环神经网络的数据的维度为100,其中,100=4+12*8。步骤s108,以此类推,直至得到n个训练样本,n为大于1的正整数;本实施例中,重复执行上述步骤,直至得到n个训练样本,其中,n为大于1的正整数,n的取值根据实际需要进行设置,例如设置为10000。步骤s109,以所述n个训练样本构建得到训练集。本实施例,得到n个训练样本后,便以n个样本构建得到训练集,用于后续对循环神经网络进行训练。本实施例中,训练样本中用于输入循环神经网络的数据的维度远远大于现有技术中用于输入循环神经网络的数据的维度,从而实现了从多个维度预测系统故障,提高了故障预测的准确性。进一步地,一实施例中,在得到所述n个训练样本对应的时间段内,所述系统经过至少一次版本升级。本实施例中,若在第一时刻得到第一训练样本,在第n时刻得到第n训练样本,则得到n个训练样本对应的时间段即为第一时刻至第n时刻这段时间。考虑到系统升级对系统稳定性的影响,在此限制第一时刻至第n时刻这段时间内系统经过至少一次版本升级,使得n个训练样本中存在场景信息的量化值表示升级重启场景的训练样本,从而实现整合系统升级前的数据与升级后的数据对循环神经网络进行训练,保证了训练数据的连续性。第三方面,本发明实施例还提供一种故障预测装置。参照图6,图6为本发明故障预测装置一实施例的功能模块示意图。本实施例中,所述故障预测装置包括:构建模块10,用于构建训练集,所述训练集包括n个训练样本,一组训练样本包括系统性能信息的量化值、场景信息的量化值、堆栈信息的量化值、堆栈信息对应的进程信息的量化值以及故障信息的量化值,n为大于1的正整数;训练模块20,用于基于所述训练集,对循环神经网络模型进行训练,得到故障预测模型;预测模块30,用于通过所述故障预测模型,对系统故障进行预测。进一步地,一实施例中,所述构建模块10包括:获取单元,用于获取系统在第一时刻的系统性能信息、场景信息、堆栈信息、堆栈信息对应的进程信息,以及故障信息;第一量化单元,用于基于性能量化规则,得到所述系统性能信息的量化值;第二量化单元,用于基于场景与数值的对应关系,得到所述场景信息的量化值;第三量化单元,用于从所述堆栈信息对应的堆栈中取出s个内核函数,分别对所述s个内核函数进行哈希计算,得到s个哈希值,以所述s个哈希值组成所述堆栈信息的量化值,s为大于1的正整数;第四量化单元,用于对所述进程信息对应的进程进行哈希计算,以计算得到的哈希值作为所述进程信息的量化值;第五量化单元,用于基于所述故障信息确定系统在第一时刻的故障类型,将预置m维向量中所述故障类型对应的目标维度上的分量设置为第一数值,除所述目标维度以外的其他维度上的分量设置为第二数值,得到新的m维向量,以所述新的m维向量作为所述故障信息的量化值;组合单元,用于以所述系统性能信息的量化值、场景信息的量化值、堆栈信息的量化值、堆栈信息对应的进程信息的量化值以及故障信息的量化值作为第一训练样本;重执行单元,用于以此类推,直至得到n个训练样本,n为大于1的正整数;构建单元,用于以所述n个训练样本构建得到训练集。进一步地,一实施例中,所述第三量化单元包括:量化子单元,用于从所述堆栈信息对应的堆栈的栈顶以及栈底上取出内核函数,从所述堆栈信息对应的堆栈的次栈顶以及次栈底上取出内核函数,以此类推,直至取出s个内核函数。进一步地,一实施例中,所述构建模块10还包括:第六量化单元,用于当只能从所述堆栈信息对应的堆栈中取出p个内核函数时,所述p为小于s的正整数,分别对所述p个内核函数进行哈希计算,得到p个哈希值;以所述p个哈希值以及q个第三数值,组成所述堆栈信息的量化值,所述q=s-p。进一步地,一实施例中,在得到所述n个训练样本对应的时间段内,所述系统经过至少一次版本升级。其中,上述故障预测装置中各个模块的功能实现与上述故障预测方法实施例中各步骤相对应,其功能和实现过程在此处不再一一赘述。第四方面,本发明实施例还提供一种可读存储介质。本发明可读存储介质上存储有故障预测程序,其中所述故障预测程序被处理器执行时,实现如上述的故障预测方法的步骤。其中,故障预测程序被执行时所实现的方法可参照本发明故障预测方法的各个实施例,此处不再赘述。需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备执行本发明各个实施例所述的方法。以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的
技术领域:
,均同理包括在本发明的专利保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1