一种通过改进随机森林提高类不平衡分类性能的方法与流程
本发明涉及一种改进随机森林算法提高类不平衡分类准确性的方法,属于数据分析、挖掘和机器学习
技术领域:
。
背景技术:
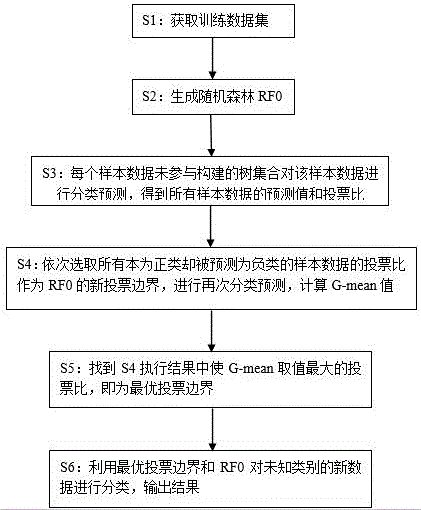
:类不平衡分类问题是数据挖掘和机器学习领域中一个非常重要的组成部分。所谓类不平衡分类问题是指由于训练分类器的数据集具有类别分布不平衡的特点,属于不同类别的训练样本数量差别比较大,从而导致传统的分类算法失效的问题。在类不平衡问题中,人们通常将包含样本数较多的类别称为多数类或负类,而把包含样本数较少的类别称为少数类或正类。针对类不平衡分类问题的研究具有广泛的实际应用价值,特别值得关注的是,在许多类不平衡分类的实际问题中,人们非常期待分类算法能准确地预测出少数类样本的类别。然而,传统的分类算法在解决类别不平衡分类问题时效果不佳,特别是对少数类样本的分类预测精度比较低。原因是传统分类算法是基于样本类别分布均衡的假设,算法的目标是使总体的训练误差最小化,并不会特别关注少数类样本的分类准确度。比如训练集中有99个多数类样本,1个少数类样本,则分类算法只需要将所有的训练样本都预测为多数类,即可达到99%的高准确率。但是这样的分类器对于大部分类不平衡分类问题是没有价值的,因为它不能正确预测出任何少数类样本的类别。目前用于解决类不平衡问题的技术主要分为以下几类:(1)重采样技术:通过对训练样本集的重新采样,增加少数类样本或者减少多数类样本,来平衡训练集样本类别的分布,减轻分类算法在预测时对多数类的偏向。随机过采样ros和随机欠采样rus是最为简单常用的两种重采样技术。ros由于增加了重复的少数类样本,增大了分类算法的开销和过拟合的风险;rus随机减少了多数类的样本,可能导致关键分类信息的丢失,导致分类算法性能下降。(2)代价敏感技术:它的主要思想是通过定义代价矩阵为不同的误分类情况分配不同的代价,特别是少数类样本被误分为多数类时所付出的代价要远远高于多数类样本的被误分。使用代价敏感学习技术解决类不平衡学习问题的难度在于代价矩阵的定义,现实问题中代价矩阵往往不可知,需要用户凭经验设定。(3)决策阈值移动技术:其主要思想是对决策阈值做适当的补偿,将决策平面向多数类区域靠近,使得尽可能多的少数类样本被预测正确。目前提出了基于bp神经网络、支持向量机、决策树、置信度等技术的决策阈值移动方法。但上述方法的缺点在于决策阈值需要人通过经验设定,算法本身不能自适应地确定最优的决策阈值。综上,现有分类方法无法有效解决类不平衡分类时性能不佳、且少数类样本分类准确度低的问题;且无法自动实施,需要用户凭经验设定参数。技术实现要素:本发明的目的是提供一种通过改进随机森林算法提高类不平衡分类性能的方法,以弥补现有技术的不足。本发明将对传统的随机森林算法进行改进,通过充分利用训练集的样本信息,自动确定随机森林的最优决策阈值。下文中将传统的随机森林算法简称为rf算法,将本发明提出的优化算法简称为rf-odt算法。为达到上述目的,本发明采取的具体技术方案为:一种通过改进随机森林算法提高类不平衡分类性能的方法,该方法包括以下步骤:s1:获取训练样本数据集,且各样本数据均能够明确其为正类或负类;s2:基于上述训练样本数据集,利用rf算法生成一个随机森林rf0;s3:利用每个样本数据未参与构建的树集合对该样本数据进行分类预测,得到每个样本数据的预测分类值;s4:选取本为正类却被预测为负类的样本数据,将其votes值作为新的投票边界进行再次分类预测,并计算g-mean值;所述votes值代表投票某个样本数据为负类的树数占所有投票树数的比例;s5:找到s4执行结果中使g-mean取值最大的votes值,即为最优投票边界;s6:利用s5得到的最优投票边界和rf0,对未知类别的新数据进行分类,输出分类结果。进一步的,所述s3具体为:s3-1:根据所述s2得到随机森林rf0,利用每个样本数据未参与构建的树集合对该样本数据进行分类预测,此时随机森林的投票边界采用默认值0.5;s3-2:获取每一个训练样本被其未参与构建的树集合进行分类预测时的投票结果votes:设x为随机森林中预测某一样本为正类的树数,y为预测该样本为负类的树数;votes代表判定该样本为负类的树数占所有投票树数的比例,即votes=y/(x+y);设threshold为投票边界,当votes≥threshold时,该样本被判定为负类;否则,该样本被判定为正类;s3-3:将所有训练样本按照其votes值从大到小顺序进行排列。更进一步的,所述s3-1中,随机森林的投票边界还可以根据待分类数据集的人工经验值进行选取,不限于0.5的默认值。进一步的,所述s4具体为:s4-1:确定最优投票边界的候选投票边界位置集合从rf的默认投票边界值0.5开始,沿着votes值逐渐增大的方向,自动搜索那些本是正类却被预测为负类的训练样本,将这些样本的votes值放入候选的投票边界位置集合;s4-2:依次将上述投票边界位置集合中的votes值作为rf0的新的投票边界再进行分类,计算对应的g-mean值。更进一步的,所述s4-1中,所述默认投票边界值0.5还能够被待分类数据集的人工经验值进行替代,不限于0.5的默认值。所述的提高类不平衡分类性能的方法能够用于网络安全、生物信息、工业故障检测、医学领域(例如罕见病诊断等)等
技术领域:
。本发明的优点和技术效果:本发明通过对传统的随机森林算法进行改进,能够自动获取最优的投票边界,无需凭借人工经验设定,只根据分布不平衡的训练数据集就能够自动确定随机森林的最优决策边界;本发明简便、有效地解决了传统分类算法中类不平衡分类性能不佳甚至失效、少数类样本预测准确度低的问题。且通过仿真试验,本发明与其他常用的五种算法进行比较,其性能指标g-mean值具有明显的优势,也进一步说明了本发明能够显著提高类不平衡分类性能和少数类样本分类准确度。附图说明图1为本发明的技术路线流程图。具体实施方式以下通过具体实施例并结合附图对本发明进一步解释和说明。实施例1:一种通过改进随机森林算法提高类不平衡分类性能的方法,该方法包括以下步骤(如图1所示):(1)首先在训练数据集上利用传统rf算法生成一个随机森林rf0,同时获取每一个训练样本被其未参与构建的树集合进行分类预测时的投票结果。根据传统rf算法的定义,由于在rf的建树过程中采用有放回采样,一个训练样本有接近63.2%的概率被选中去构建一棵树。它未参与构建的树集合可用于对该样本进行分类预测。所以,可以获取到每一个训练样本的投票结果,即在它未参与构建的树集合中有多少棵树投票将它划分为多数类(即负类),有多少棵树投票将它划分为少数类(即正类)。设x为随机森林中预测某一样本为正类的树数,y为预测该样本为负类的树数。votes代表判定某个样本为负类的树数占所有投票树数的比例,即votes=y/(x+y)。设threshold为投票边界,当votes≥threshold时,该样本被判定为负类;否则,该样本被判定为正类。传统rf算法中投票边界threshold默认取值为0.5。即当森林中有半数及以上的树投票判定某个样本为负类,则该样本被最终判定为负类;否则被判定为正类。(2)将所有训练样本的相关信息按照其votes值从大到小顺序进行排列。此时随机森林的投票边界采用默认值0.5。以下表1为例说明排序情况。表1训练样本信息ytrue是样本的真实类别。表中粗黑实线的位置代表传统rf算法所采用的决策边界threshold,默认情况下取0.5,即当训练样本的votes值大于等于0.5时,该样本被判定为负类,反之则被判定为正类。决策边界threshold取0.5时样本的分类预测结果在ypredict-old列显示。如果rf的决策边界threshold被调整为0.58,即表中的虚线位置,则当训练样本的votes值大于等于0.58时,该样本被判定为负类,反之则被判定为正类,样本在采用了新的决策边界后得到的分类结果在ypredict-new列显示。由上表可见,当threshold由0.5变为0.58时,第8、9号样本的预测值由负类变为正类。(3)确定最优决策边界的候选位置集合,并计算对应的g-mean值。从rf的默认决策边界值threshold=0.5开始,沿着votes值逐渐增大的方向,搜索那些本是正类却被预测为负类的训练样本,将这些样本的votes值放入候选的最佳决策边界位置集合。依次将这些候选位置作为rf0的决策边界threshold进行分类,计算g-mean值,即类不平衡分类算法的性能评价指标。表2:分类混淆矩阵被预测为正类样本被预测为负类样本真实的正类样本tpfn真实的负类样本fptn为了更加全面、准确地评价分类算法对于不同类别样本的分类能力,定义了分类结果的混淆矩阵,如表2所示。在表2中,tp和tn分别表示本来就是正类/负类,结果被准确地预测为正类/负类的样本数量。fn和fp分别表示本来是正类/负类,结果被错误地预测为负类/正类的样本数量。为了综合考量分类算法在正类样本和负类样本上的分类精度,衡量算法在矛盾的度量指标之间的平衡能力,在评价类不平衡分类算法性能时常用g-mean指标,定义如下:g-mean值越高表示分类算法在正类样本和负类样本上分类精度越均衡。以表1为例,从threshold=0.5开始向上增加,依次有样本#8、样本#6和样本#3是正类却被预测为负类(加星号标注),所以只有将投票边界值threshold升高到0.58、0.65、0.85时,才会导致被正确预测的正类样本数量tp的增加,才能提高少数类样本的分类精度。由此可以确定候选投票边界值集合为{0.5,0.58,0.65,0.85},分别将随机森林的投票边界设定为这四个值对样本进行分类,计算出相应g-mean值。(4)从候选投票边界集合中选择产生最大g-mean值的投票边界值作为随机森林rf0的最终投票边界threshold-best,用于今后对类别未知的样本进行分类。实施例2:在30个数据集上对本发明所提出的rf-odt方法进行了性能测试,数据集的信息如表3所示,数据按数据集的类不平衡比从小到大排列。类不平衡比是指数据集中多数类样本数与少数类样本数的比值。表3:实验数据集信息表数据集名称样本数特征数类不平衡比glass121491.82wisconsin68391.86pima76881.87haberman30632.78vehicle1846182.9new-thyroid121555.14yeast3148488.1ecoli333678.6ecoli-0-3-4_vs_520079ecoli-0-6-7_vs_3-522279.09yeast-0-3-5-9_vs_7-850689.12yeast-0-2-5-7-9_vs_3-6-8100489.14ecoli-0-1_vs_2-3-524479.17vowel0988139.98ecoli-0-6-7_vs_5220610led7digit-0-2-4-5-6-7-8-9_vs_1443710.97ecoli-0-1_vs_5240611yeast-1_vs_7459714.3ecoli4336715.8abalone9-18731816.4shuttle-c2-vs-c4129920.5shuttle-6_vs_2-3230922flare-f10661123.79yeast41484828.1winequality-red-415991129.17yeast51484832.73shuttle-2_vs_53316966.67poker-8-9_vs_520751082poker-8_vs_614771085.88abalone1941748129.44为了测试rf-odt算法的性能,将它与其他五种方法进行比较,其他五种方法分别是:rf0:传统的随机森林算法;svm-smote:经过smote算法采样后训练的svm分类器;svm-othr:现有文献中提出的算法:(hualongyu,chaoxumu,etal.supportvectormachine-basedoptimizeddecisionthresholdadjustmentstrategyforclassifyingimbalanceddata[j].knowledge-basedsystems,2015,76:67-78.);svm-rus:经过随机欠采样算法采样后训练的svm分类器;svm-ros:经过随机过采样算法采样后训练的svm分类器;上述方法的g-mean值比较如下表:表4:各个算法在30个数据集上的g-mean值各个算法在30个数据集上进行分类,得到的性能指标g-mean值如表4所示:在30个数据集上,本发明提出的rf-odt方法在其中的26个数据集上g-mean平均值第一,1个数据集上g-mean平均值排名第二。由上表对比结果可知,本发明利用自动获取的最优投票边界值对数据集进行分类时的g-mean性能指标要明显优于其他算法。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1