基于尺度不变性与特征融合的目标检测算法的制作方法
本发明涉及目标检测技术领域,具体涉及一种基于尺度不变性与特征融合的目标检测算法。
背景技术:
随着深度学习技术的不断发展,目标检测方法越来越多。图像中存在大量的目标,对每一个目标进行分类与检测是比较困难的,特别是一些小目标,因此小目标的检测是目前目标检测领域中的重点区域。
目标检测是一个复杂且重要的任务,对军事,医疗,生活等方面都有着巨大的作用。已有的目标检测技术主要分为两种类型:一是基于手工标注特征的传统方法,例如hear特征和adaboost算法、svm算法和dpm算法;二是基于深度学习技术的方法。在深度学习下,目标检测主要分为了以下两个任务:一个是边框的预测,标出每个物体的上下左右的位置。另一个是类别的预测,预测出每个像素属于哪个物体。而又因为步骤不同,目标检测又分为了二阶段检测和单阶段目标检测。二阶段目标检测的代表论文主要有rcnn系列,即先产生物体候选区域(regionproposals),然后在对其进行修正。单阶段的目标检测的代表论文主要是yolo、ssd系列,即通过网络直接预测出边框的位置。总体上来说,二阶段的目标检测的精度比单阶段的目标检测的精度更高,而单阶段目标检测精度不如二阶段的,但是在保证了一定的精度下检测速度更快。但是这俩种方法都存在一个尺度变换问题。因为这俩种方法都是基于较大的下采样因子,而产生较高的感受野来获得更多的语义信息,这是有利于大物体识别。但是,下采样必定带来空间分辨率的损害,下采样越大,分辨率越小,小物体识别也就更困难。为了解决下采样带来的尺度变换问题,常用的方法是多尺度特征融合。fpn首次使用了该方法,通过自顶向下的思想,低层的特征融合高层的特征来获得了更多的语义信息。其后panet在fpn的基础上进行了改进,在加上了自底向上的思想,在从低层特征逐步下采样到高层特征的分辨率,并且与高层特征融合,使得高层特征也具有了低层特征的空间信息。但是这种方法也存在缺陷,不同层对不同尺度的敏感性不同,高层特征即使融合了低层特征的空间信息,但同时也带来了低层的语义信息,因此会对本身已经训练好的高层特征产生影响,使得高层特征对大物体的分类以及预测能力减弱。
技术实现要素:
本发明针对现有技术的不足,提出一种解决现有的目标检测方法中存在的尺度变化问题,提升小目标以及大目标的检测的基于尺度不变性与特征融合的目标检测算法,具体技术方案如下:
一种基于尺度不变性与特征融合的目标检测算法,采用的步骤为:
步骤一:将待检测图像输入到detnet59中进行特征提取,获得多个特征图;
步骤二:对获得的多个特征图进行选择融合特征的方式,获得新的具有相同通道的多个特征图;
步骤三:使用多个特征图生成候选框,对候选框进行多次选择分类与回归。
作为优化:所述detnet59为改进的detnet59,所述改进的detnet59与detnet59拥有相同的第一步到第五步,分别生成1-5个特征图,从第五步开始,使用第5个特征图,分成了三个分支,生成第6-8个特征图,第6个特征图的分辨率与第5个特征图保持一样,使用膨胀卷积保持感受野不同,第7,8个特征图使用下采样降低分辨率增加语义信息,再使用膨胀卷积增加第7,8个特征图的感受野。
作为优化:所述步骤二中选择融合特征的方式具体为;
步骤2.1:将第2-8的特征图通过卷积操作变为通道256的特征图,其中第6-8的特征图就生成为p6-p8;
步骤2.2:在将7和8的特征图经过上采样后和6的特征图一起融合到特征图5中,在融合之后再对每个融合结果进行卷积生成p5;
步骤2.3:再将p5进行上采样融合到特征图4中,在融合之后再对每个融合结果进行卷积生成p4;
步骤2.4:一直重复2.3步骤直到融合完特征图2,生成p2、p3。
作为优化:所述步骤三具体为,
步骤3.1:对于p2、p3、p4、p5、p6、p7和p8层,生成大量的anchor;
步骤3.2:对于p6、p7、p8这三层,对其产生的anchor和groundtruth根据l_i≤√wh〖≤u〗_i函数进行了筛选,l_i代表宽度最小值,u_i代表宽度最大值,w、h分别代表边框的高和宽,p6只保留小的anchor,p7只保留中等的anchor,p8只保留大的anchor;然后对anchor使用iou阈值为0.5的nms非极大值抑制生成第一部分的候选框,再对第一部分的候选框进行分类和边框回归;iou的值就是两个预测框的交集除以两个预测框的并集的值;nms就是对所有的框进行一一比较,如果两个框的交集大于iou设置的阈值,则保留得分最大的框,删除另外的框;获得第一部分候选框;p6再只对小的groundtruth回传损失,p7再只对中等的groundtruth回传损失,p8再只对大的groundtruth回传损失;
步骤3.2:得到第一部分回归后的候选框后,使用阈值为0.6的nms非极大值抑制生成第二部分的候选框,再对第二部分的候选框进行分类和边框回归;
步骤3.3:得到第二部分回归后的候选框后,使用阈值为0.7的nms非极大值抑制生成最终的候选框,再对最终的候选框进行分类和边框回归。
作为优化:所述对候选框进行分类包括,
分类利用softmax函数将候选框对应的特征映射到(0,1)区间,对应n个类别上去,n为大于1的整数,概率最高的类别为预测的类别;
其中si表示对于类别的概率,ei表示对类别的预测分数,∑jej表示所有类别分数和。
作为优化:所述对最终的候选框进行回归包括:
回归利用diou损失函数将候选框与目标之间的尺度,重叠率以及距离都参与计算;
其中iou表示目标框与候选框的交并比,b表示候选框的的中心点,bgt表示目标框的中心点,ρ代表的是计算两个中心点间的欧式狙击,c代表的是能够同时包含候选框和目标框的最小闭包区域的对角线距离。
本发明的有益效果为:将图像输入到深度神经网络中进行特征提取,获得拥有尺度不变性的特征图,对特征图进行筛选,获取多个候选框,利用特征图生成候选框,再对候选框进行交并比为0.5的极大值抑制选出第一部分候选框,对第一部分候选框进行分类和回归获得新的候选框,再对新的候选框做交并比为0.6的极大值抑制,获得第二部分候选框。再对第二部分候选框进行分类和回归获得新的候选框,再对新的候选框做交并比为0.7的极大值抑制,获得最终的候选框。
附图说明
图1为本发明基于尺度不变性与特征融合的目标检测算法的流程图;
图2为本发明中多分支detnet网络结构图;
图3为本发明中选择融合结构图;
图4为本发明中每个分支预测物体大小图;
图5为本发明中候选框多次分类与回归图;
图6为本发明中网络结构图;
具体实施方式
下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
本发明所用到的硬件设备有pc机1台、nvidia1080ti显卡1个;
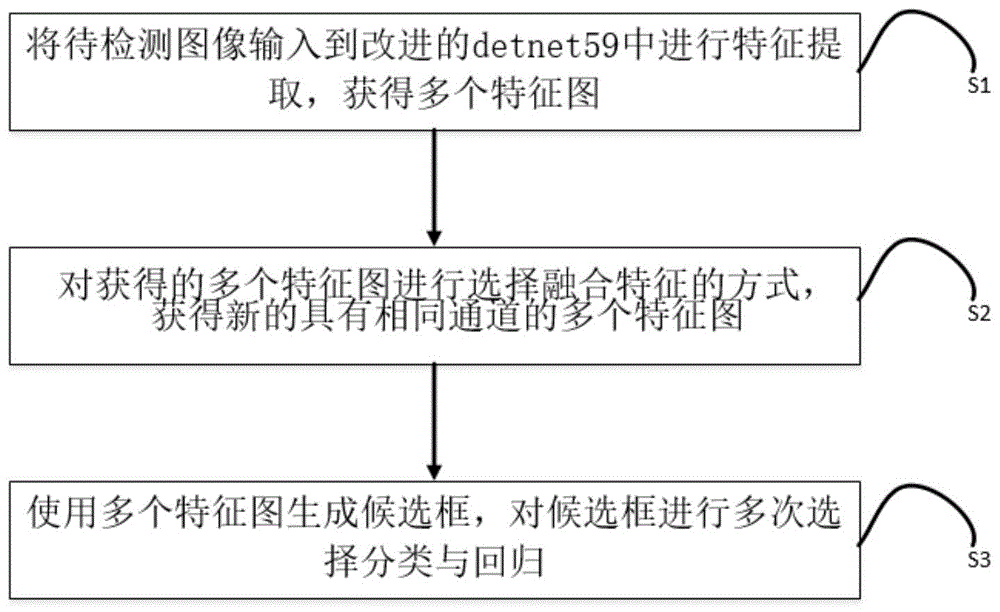
如图1所示:一种基于尺度不变性与特征融合的目标检测算法,包括以下步骤:
s1:将待检测图像输入到改进的detnet59中进行特征提取,获得多个特征图;
s2:对获得的多个特征图进行选择融合特征的方式,获得新的具有相同通道的多个特征图;
s3:使用多个特征图生成候选框,对候选框进行多次选择分类与回归。
改进的detnet59网络结构:
参见图2,所使用的改进的detnet59网络结构,对输入的图片每次使用步长为2的卷积操作产生4层不同大小的特征图c2,c2,c3,c4。其中使用了36个使用膨胀卷积,每9个膨胀卷积层后取一个特征图,分为c5,c6,c7,c8。而c5使用的膨胀率为2的膨胀卷积,c6在c5的基础上再使用了膨胀率为2的膨胀卷积,获得了不同于c5的感受野。c7是在c5的基础上,先对c5进行了一次步长为2的卷积,使得图像大小变小,在对变小后的图像进行膨胀率为2的膨胀卷积,获得不同于c6的感受野。c8也是在c5的基础上,先对c5进行了一次步长为2的卷积,使得图像大小变小,在对变小后的图像进行膨胀率为2的膨胀卷积,获得不同于c6,c7的感受野。
选择融合:
参见图3,利用第一步提取出来的特征图{c2,c3,c4,c5,c6,c7,c8},对所有的特征图使用一个1*1卷积核为256的卷积操作生成{c2_reduced,c3_reduced,c4_reduced,c5_reduced,p6,p7,p8};{p7,p8}进行一个双线性插值处理变为{p7_upsampled,p8_upsampled},c5_reduced和{p7_upsampled,p8_upsampled,c6_reduced}进行add卷积融合生成p5_merged,p5_merged经过一个3*3卷积核为256的卷积得到p5;p5进行一个双线性插值处理变为p5_upsampled,c4_reduced和p5_upsampled进行add卷积融合生成p4_merged,p4_merged经过一个3*3卷积核为256的卷积得到p4;
同样的方式,p4进行一个双线性插值处理变为p4_upsampled,c3_reduced和p4_upsampled进行add卷积融合生成p3_merged,p3_merged经过一个3*3卷积核为256的卷积得到p3;p3进行一个双线性插值处理变为p3_upsampled,c2_reduced和p3_upsampled进行add卷积融合生成p2_merged,p2_merged经过一个3*3卷积核为256的卷积得到p2;
预测anchor:
参见图4,{p6,p7,p8}送入rpn网络中,对其产生的anchor和groundtruth根据
候选框多次分类与回归:
参见图5,使用iou阈值为0.5的nms非极大值抑制生成第一部分的候选框,再对第一部分的候选框进行分类和边框回归。得到回归后的候选框后,再使用iou阈值为0.6的nms非极大值抑制生成第二部分的候选框,再对第二部分的候选框进行分类和边框回归。得到回归后的候选框后,再使用iou阈值为0.7的nms非极大值抑制生成最终部分的候选框,再对最终部分的候选框进行分类和边框回归。所有的分类都使用softmax函数,所有的回归都是diou损失函数。
如图6所示,是专利中使用的总体网络的结构图
训练目标检测网络
加载imagene预训练模型,对网络的特征提取部分的参数进行冻结,只训练之后的网络,达到最好结果后进行下一步训练。
- 还没有人留言评论。精彩留言会获得点赞!