基于改进TOPSIS和聚类分析的智能电表运行状态评价方法与流程
本发明属于故障预测领域,具体涉及一种基于改进topsis和聚类分析的智能电表运行状态评价方法。
背景技术:
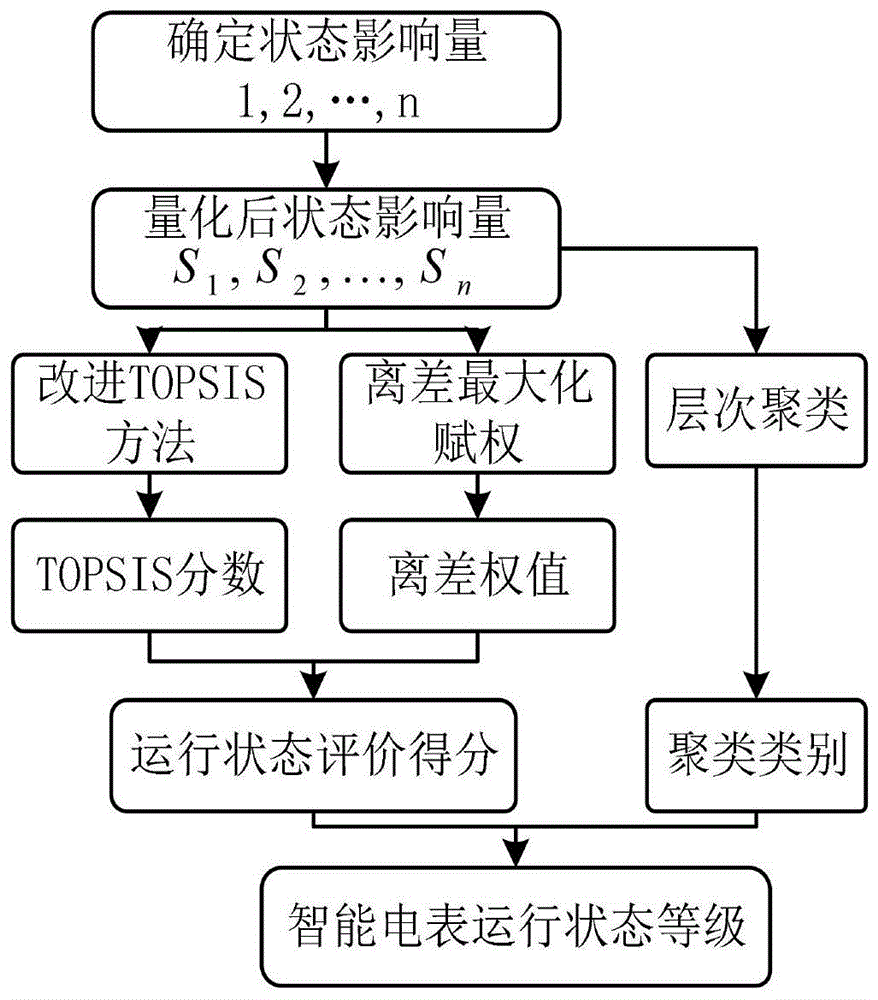
:电力是国家发展的基石,实现电网智能化对于保障我国经济社会发展,提高人民生活水平意义重大。现代智能电表是集计量数据自动处理、传输、管理和使用,电表自动化管理和双向通信的智能化电力计量设备,是实现电网智能化不可或缺的计量设备。智能电表在运行过程中由于内外应力的交替作用将会产生性能上的退化,从而使得其运行状态劣化而不能满足工作要求。对运行中的电能表进行运行状态评价,其目的是及时发现已经不适合继续运行的电能表,其任务是为了明确在运行中的智能电表的健康状态并预测健康状态的发展趋势,防止大规模电表故障带来的社会经济损失。电力公司通常用新智能电表替换已达到一定运行时间的旧智能电表,这种替换方法将导致替换一些仍可以正常工作的智能电表,从而造成大量浪费,因此需要采用一种更加准确的方法来对智能电表进行状态评价。目前对于智能电表的状态评估的主流方法是数据驱动方法,即利用多源信息融合技术及人工智能等相关算法来整合智能电表运行过程中产生的以及与智能电表运行状态相关的各类数据,从而实现对智能电表的运行状态评价的精细化和智能化。目前,随着信息采集技术、机器学习和信息融合技术的发展,目前已有较为充足的数据和技术来构建智能电表运行状态模型。对于现代智能电表,其结构复杂,工作环境多种多样,难以仅仅采用单一的数据对其进行状态评价。而且电能表数量庞大,采取抽样检查的方式十分费时费力。因此需要一种能够融合多种智能电表数据信息的方法来对智能电表进行自动化的评估。技术实现要素:针对现有技术的不足,本发明提供一种基于信息融合技术的智能电表运行状态评价方法。本发明集合改进topsis方法、离差最大化方法和聚类分析方法,对智能电表运行状态进行评价,构建了全面反映智能电表运行状态的状态影响量,改进了topsis方法计算表达式,结合离差最大化赋权方法和聚类方法确定了电表的运行状态。本发明的一种基于改进topsis和聚类分析的智能电表运行状态评价方法,其包括如下步骤:s1、构建并量化智能电表运行状态影响量;根据状态影响量构建原则,构建并量化智能电表运行状态影响量,所述状态影响量包括误差最值,误差一致性,误差变差和批次故障率;;s2、利用改进的topsis方法计算所述状态影响量的topsis得分,步骤如下;s21、构造决策矩阵x=(xij)m×n;其中,m为评价对象的个数,n为每个评价对象的状态影响量的个数,xij表示第i个被评价对象在第j个状态影响量下的值,i=1,2,…,m;j=1,2,…,n;s22、对决策矩阵x按状态影响量的性质进行无量纲化处理;对于效益型状态影响量的决策矩阵x,无量纲化处理后为:对于成本型状态影响量的决策矩阵x,无量纲化处理后为:其中,zij表示xij经过无量纲化处理之后的数值,即分别表示第j个状态影响量下的最大值和最小值;s23、确定zij的正理想解aij+和负理想解aij-,所述正理想解是第i个评价对象对于第j个状态影响量最好的值,所述负理想解是第i个评价对象对于第j个状态影响量最差的值;s24、分别计算zij与正理想解aij+的距离和负理想解aij-的距离s25、计算xij与正理想解aij+的相对贴近度得到改进的所述状态影响量的topsis得分;用相对贴近度来衡量各评价对象在各状态影响量下靠近正理想解的程度,越大,表示评价对象在该向量下越优;根据不同状态影响量性质,的计算表达式分别为:成本型状态影响量时:效益型状态影响量时:s3:计算各状态影响量的离差最大化权重值,步骤如下;设各个状态影响量之间的加权向量为w,且w=(w1,w2,…,wn)t>0,并满足表达式:加权向量下的加权决策矩阵为:其中,zij表示经过无量纲化处理之后的决策矩阵数值,wj表示第j个状态影响量的权重;s31:计算所有评价对象在第j个状态影响量下与其他评价对象的总离差vj(w);对于第j个状态影响量来说第i个评价对象与其他所有决策方案的离差用vij(w)表示为:其中,zij与zkj都表示经过无量纲化处理之后的决策矩阵数值,k≠i,wj表示第j个状态影响量的权重;则对第j个状态影响量而言,所有评价对象与其他评价对象的总离差vj(w)为其中,zij与zkj都表示经过无量纲化处理之后的决策矩阵数值,k≠i,wj表示第j个状态影响量的权重;s32:构造目标函数,得到使总离差vj(w)达到最大的权重向量为使评价对象在加权向量w下得到尽可能的区分,应该使得离差vj(w)最大,为求出能使得vj(w)达到最大的权向量,构造目标函数:得到:其中,zij与zkj都表示经过无量纲化处理之后的决策矩阵数值,k≠i,wj表示第j个状态影响量的权重;对权向量wj进行归一化处理,得到归一化之后的权重向量为:s4、根据得到的离差最大化权重和改进的状态影响量topsis得分的贴近度c+ij计算智能电表运行状态得分si;第i个被评价电表的运行状态评分表达式为:其中,si表示第i个被评价对象的运行状态得分,表示归一化之后的第j个状态影响量的,c+ij表示第i个被评价对象在第j个状态影响量下与正理想解的贴近度;s5、根据对智能电表状态影响量数据的聚类分析,得到智能电表的运行状态聚类类别;s6、根据电表的运行状态聚类类别,确定电表的运行状态得分划分阈值,得到智能电表运行状态的等级划分结果。优选地,所述步骤s1中误差最值为:s1=max{|e1|,|e2},...,|en|}其中,e1,e2,...,en,分别为第1次到第n次测量电能表误差,由于电表的误差具有对称性,因此将电表的误差取绝对值。优选地,所述步骤s1中误差一致性的定义为:同一批次数只被试样品在同一测试点的测试误差与平均值间的偏差;第i个电表的误差一致性的计算表达式如下:其中,ea表示一致性误差值,ei表示被评价电表在第i个测试点下的测量误差值,表示在相同测试点下同一批次数只被试样品在同该测试点下的测试误差平均值;如果在多个负载点进行了测量,取这几个测量误差变差的最大值进行计算;可以得到状态影响量:s2=max{|ea1|,|ea2|,...,|ean|}其中,|ea1|,|ea2|,...,|ean|代表电表在同一负载电流下所测得的n次误差一致性绝对值。优选地,所述步骤s1中误差变差的定义为:对同一被试样品相同的测试点,在负荷电流为1b、功率因数为1.0和0.5l的负载点进行重复测试,相邻测试结果间的最大误差变化的绝对值;误差变差的计算表达式如下:ec=|max{ei-ej}|其中,ec代表误差变差值,ei和ej表示在同一负载点进行的第i次和第j次测量误差值(i≠j);若在某个负载点进行了多次测试,则可以取变差的最大值进行计算,故可以得到状态影响量的量化表达式有:s3=max{ec1,ec2,...,ecn}其中,ec1,ec2,...,ecn代表多个误差变差值。优选地,所述步骤s1中批次故障率代表该智能电表所属批次的故障率,代表该批次电能表总体质量水平的高低,其计算表达式如下:其中,nf为该批次电能表故障数量,n为该批次电能表总数量。优选地,所述步骤s5中的聚类分析过程如下;s51、确定状态影响量数据的聚类方法,所述聚类方法为层次聚类、划分聚类、基于密度的聚类和基于网格的聚类方法中的一种;s52、确定状态影响量数据的聚类评价指标,所述聚类评价指标至少包括ch指标、轮廓系数和dbi指数中间的一种;s53、根据聚类评价指标确定状态影响量数据的最佳聚类数目;s54、根据最佳聚类数目对状态影响量进行聚类,得到电表的运行状态聚类类别。本发明的有益效果:1.本发明为科学高效地评价智能电表的运行状态,说明了从状态评价的主要原则、智能电表的产品特性以及数据实际出发构建了智能电表运行状态影响量的原则,具有较好的指导性。2.本发明采用信息融合的技术,将能够反映智能电表运行状态的状态影响量最终融合为状态得分值,使得智能电表的运行状态得以量化。3.本发明对topsis方法进行改进,使得评价结果更加科学高效;离差最大化方法的引入使得得出的评价结果更加接近数据实际;将聚类分析用于智能电表的状态得分阈值划分,使得状态得分到状态等级的转换不再过于依赖工程经验。4.本发明创新的将topsis方法进行了改进,克服了原方法只能得出被评价对象的相对排序结果、不能体现不同状态影响量权重以及不能将不同标准的被评价对象放在一起进行评价的缺点,改进了其距离计算表达式。在经过改进之后,由于每个评价对象都是根据在各个状态影响量下相应的正负理想解下进行评价,因此可以将不同标准的评价对象放在一起进行比较,同时使得得到的结果是绝对评价结果。在经过对正负理想解的距离表达式改造之后,去掉了原表达式中的求和部分,使得能够引入离差最大化的赋权方法,解决了原方法不能体现不同状态影响量重要程度的缺点。5.本发明创新性地将离差最大化的方法引入了智能电表的运行状态评价之中,离差最大化的赋权方法是基于实际数据来计算权重,是一种客观的赋权方法,因而可以避免人主观因素的过多影响,避免了搜集专家意见的过程,简化了评价流程。6.本发明创新性地提出了采用聚类的方法来进行电表运行状态得分阈值划分的方法。聚类分析的引入使得得出的得到的状态等级更加符合数据本身的状态,使得状态得分的阈值划分不再过多地依赖工程经验。附图说明图1是本发明基于改进topsis和聚类分析的智能电表运行状态评价方法的一个实施方式的流程图;图2是本发明一个实施方式的不同聚类数目时的轮廓值;图3是本发明一个实施方式的不同聚类类别的状态得分分布图。具体实施方式下面将结合附图1-3及实施例对本发明作进一步的详细说明。本实施例选取了来自国家电网福建分公司的数据,数据字段包括生产厂家、条码号、批次号、运行时长、批次数目、建档时间、批次退货数目、批次故障数目、检验误差等共18个属性,包含10个厂家50个批次19652条数据。对全部19652条数据信息进行整理,得到数据集基本信息如下表:一种基于改进topsis和聚类分析的智能电表运行状态评价方法,包括以下步骤:s1:构建并量化智能电表运行状态影响量;我们根据状态影响量构建原则,我们构建了误差最值,误差一致性,误差变差和批次故障率四个状态影响量,计算选取10个电表数据作为数据集示例,所采用的数据均来自本步骤中的示例数据表。1.误差最值智能电表的误差值是其核心计量功能的最直接的指标。根据国家电网的相关标准,智能电表的运行误差应该在一定的范围内。运行误差最值的计算表达式如下式:s1=max{|e1|,|e2|,...,|en|}式中,|e1|,|e2|,...,|en|,分别为第1次到第n次测量电能表误差的绝对值。由于电表的误差具有对称性,因此将电表的误差取绝对值。在本研究的数据集中,进行了四次误差的测量,即e1,e2,e3,e4分别为“实验室_1_imax_误差1”、“实验室_1_imax_误差2”、“实验室_0.5l_ib_误差1”和“实验室_0.5l_ib_误差2”的值。数据示例如下表。因此根据误差最值s1的计算表达式可以得到各电表误差最值s1的计算结果分别为:电表1为0.108;电表2为0.042;电表3为0.089;电表4为0.067;电表5为0.075;电表6为0.117;电表7为0.111;电表8为0.056;电表9为0.017;电表10为0.1059。2.误差一致性误差一致性的定义为:同一批次数只被试样品在同一测试点的测试误差与平均值间的偏差。第i个电表的误差一致性的计算表达式如下:式中,ea表示一致性误差值,ei表示被评价电表在第i个测试点下的测量误差值,表示在相同测试点下同一批次数只被试样品在同该测试点下的测试误差平均值。如果在多个负载点进行了测量,取这几个测量误差变差的最大值作为误差一致性的代表参与智能电表的运行状态评价。可以得到状态影响量:s2=max{|ea1|,|ea2|,...,|ean|}其中,|ea1|,|ea2|,...,|ean|代表电表在同一负载电流下所测得的n次误差一致性绝对值。计算采用的数据示例即ei(由于进行了4次测量故i=1,2,3,4)的值如下表。我们先对批次号相同的智能电表误差值取平均值,得到按照上表的实例数据,由于该表数据为同一批次,可以得到该批次的值如下表:于是根据表达式可以求得这些电表的误差一致性ea的值如下表:然后取一致性最大值,得到各电表最大一致性s2的计算结果分别为:电表1为0.04471;电表2为0.05539;电表3为0.05229;电表4为0.0149;电表5为0.01671;电表6为0.0441;电表7为0.05871;电表8为0.05229;电表9为0.06139;电表10为0.05361。3.误差变差误差变差的定义为:对同一被试样品相同的测试点,在负荷电流为1b、功率因数为1.0和0.5l的负载点进行重复测试,相邻测试结果间的最大误差变化的绝对值。误差变差的计算表达式如下:ec=|max{ei-ej}|式中ec代表误差变差值,ei和ej表示在同一负载点进行的第i次和第j次测量误差值(i≠j)。若在某个负载点进行了多次测试,则可以取变差的最大值进行计算,故可以得到状态影响量的量化表达式有:s3=max{ec1,ec2,...,ecn}式中,ec1,ec2,...,ecn代表多个误差变差值。由于误差变差的定义,因此只需要考虑在负荷电流为1b的负载下的数据,计算采用的数据示例如下表。表中的数据对同一个负载点下进行了两次误差测试,于是根据误差变差的计算表达式,ec=|max{ei-ej}|(此处i=1,j=2)可以得到实验室_0.5l_ib_误差变差值为:电表1为0.005;电表2为0.011;电表3为0.006;电表4为0.009;电表5为0.003;电表6为0.003;电表7为0.009;电表8为0.003;电表9为0.006;电表10为0.004。我们取误差变差的最大值进行运行状态评价,此处只有一个误差变差值,故数据结果与上表保持一致,于是可以得到各电表最大误差变差s3的计算结果分别为:电表1为0.005;电表2为0.011;电表3为0.006;电表4为0.009;电表5为0.003;电表6为0.003;电表7为0.009;电表8为0.003;电表9为0.006;电表10为0.004。4.批次故障率批次故障率代表该智能电表所属批次的故障率,代表该批次电能表总体质量水平的高低,其计算表达式如下:其中,nf为该批次电能表故障数量,n为该批次电能表总数量。计算采用的实例数据集如下:电表序号批次故障数量批次总数11454702145470314547041454705145470614547071454708145470914547010145470于是根据计算表达式,可以得到各电表最大误差变差s4的计算结果分别为:电表1为0.256;电表2为0.256;电表3为0.256;电表4为0.256;电表5为0.256;电表6为0.256;电表7为0.256;电表8为0.256;电表9为0.256;电表10为0.256。于是,我们便可以得到四个状态影响的量化值以继续进行状态评价。s2、利用改进的topsis方法计算状态影响量的topsis得分,步骤如下;经典topsis(techniquefororderpreferencebysimilaritytoanidealsolution)法又被称为优劣解距离法,该方法的核心思想是设定一个理想化的目标即正理想解和负理想解,正理想解即对于该状态影响量来说最好的值,负理想解即对于该状态影响量来说最差的值,然后根据评价对象与正负理想解的接近程度进行排序。如果被评价对象与正理想解距离较近同时与负理想解距离较远,则评价对象得分越高;反之则得分越低。topsis方法的基本步骤如下:1.构造决策矩阵及规范化若某次评价中有评价对象m个,每个评价对象有n个状态影响量,则可形成评价矩阵x=(xij)m×n,矩阵元素xij表示第i个评价对象在第j个状态影响量下的值,所得到的矩阵称为决策矩阵:其中,xij(i=1,2,…,m;j=1,2,…,n)表示第i个被评价对象在第j个状态影响量下的值。2.对决策矩阵x进行无量纲化处理在决策矩阵中存在效益型状态影响量和成本性状态影响量,效益型状态影响量指的是其值越大越好的状态影响量,而成本性属指的是其数值越小越好的状态影响量。由于效益型影响量和成本型影响量往往有不同的量纲和量纲单位,因此为了他们之间能够进行比较,消除他们之间的不可公度性,需要对他们进行无量纲化处理。对于效益型状态影响量,一般的无量纲化处理如下式:式中,zij表示经过无量纲化处理之后的数值,其中,xij表示第i个被评价对象在第j个状态影响量下的值;即分别表示第j个影响量下的最大值和最小值。对于成本型状态影响量,一般的无量纲化处理如下式:其中,xij表示第i个被评价对象在第j个状态影响量下的值;zij表示经过无量纲化处理之后的数值,即分别表示第j个影响量下的最大值和最小值。经过无量纲化处理之后,所有状态影响量的数值都将转化为0-1之间的值,且数值越大,表明该评价对象状态越好。3.确定正理想解a+向量和负理想解a-向量,确定正理想解a+向量和负理想解a-向量,分别表示最理想状态最差状态:其中:式中,zij表示经过无量纲化处理之后的数值,t1,t2分别表示效益型和成本性状态影响量的样本空间。该式表示在效益型状态影响量中,某个状态影响量的正理想解和负理想解分别表示某个状态影响量下所有被评价对象的最大值和最小值。在成本型状态影响量中,某个状态影响量的正理想解和负理想解分别表示某个状态影响量下所有被评价对象的最小值和最大值。计算第i个被评价对象在各状态影响量下与正理想解的距离和负理想解的距离计算公式如下式:式中,zi=(zi1,zi2,…,zin)。该式表示某个被评价对象与正理想解的距离为该评价对象的各状态影响量值与正理想解a+的欧式距离;某个被评价对象与负理想解的距离为该评价对象的各状态影响量值与负理想解a-的欧式距离。4.计算各评价对象与正理想解的相对贴近度c+i用相对贴近度c+i来衡量各评价对象靠近正理想解的程度,c+i越大,表示评价对象越优。式中,和第分别表示第i个被评价对象在各状态影响量下与正理想解的距离和负理想解的距离。但是由于根据经典的topsis方法只能得到评价对象之间的相对“好坏”结果,即得出的评价结果为相对评价结果,因此我们对topsis方法进行改造,主要体现在在以下两个方面:计算第i个对象在第j个状态影响量下与正理想解的距离和负理想解的距离时变更距离计算方式,采用下式:式中,zij表示经过无量纲化处理之后的数值,表示第i个评价对象在j状态影响量下的正理想解,表示第i个评价对象在第j个状态影响量下的负理想解,和分别表示第i个评价对象在第j个状态影响量下的与正理想解的距离和与负理想解的距离。由于距离计算方式的变更,去掉了原有计算公式中的求和项,因此新公式计算得出的距离是每个被评价对象与每个状态影响量的正负理想解之间的距离。于是,改造后的topsis方法计算过程如下:1.确定各评价对象在某个指标下的正理想解aij+和负理想解aij-。aij+表示第i个评价对象在j状态影响量下的正理想解,aij-表示第i个评价对象在第j个状态影响量下的负理想解,两者的值分别由各标准所规定的最好状态值和最差状态值所确定。也就是说,我们对每一个评价对象在不同状态影响量下都确立了正负理想解。2.计算第i个被评价对象在第j个状态影响量下与正理想解的距离和负理想解的距离其中,表示第i个评价对象在j状态影响量下的正理想解,表示第i个评价对象在第j个状态影响量下的负理想解,和分别表示第i个评价对象在第j个状态影响量下的与正理想解的距离和与负理想解的距离。3.计算第i个被评价对象在第j个状态影响量下的与正理想解相对贴近度用相对贴近度来衡量各评价对象在各状态影响量下靠近正理想解的程度,越大,表示评价对象在该向量下越优。根据计算公式可以推导,当评价状态影响量为成本型状态影响量和效益型状态影响量时,的计算方式不同,具体计算公式如下。当某状态影响量为成本型状态影响量时:当某状态影响量为效益型状态影响量时上面的公式中,zij表示经过无量纲化处理之后的数值,表示第i个评价对象在j状态影响量下的正理想解,表示第i个评价对象在第j个状态影响量下的负理想解,和分别表示第i个评价对象在第j个状态影响量下的与正理想解的距离和与负理想解的距离。在对状态影响量进行量化之后便需要对其进行改进后的topsis评分,首先需要确定各状态影响量的正负理想解。1.确定各状态影响量的正负理想解(1)误差最大值的正负理想解根据jjg596《电子式交流电能表检定规程》,各等级仪表的百分数误差极限如下表:从表中可以找出,各级电表在本研究数据使用的负载下得误差极限值如下表:本研究所使用的误差数据来源于验收试验时的测量数据,国家电网规定验收试验时电能表在参比条件下,其百分数误差应控制在表2-3规定的误差限的60%范围内。故各等级仪表在不同负载下误差正负理想解如下:可以看出,误差最大值的负理想解是根据标准中智能电表的准确度等级而确定的,由于电表最好的情况是没有误差,因此其正理想解为0。若在评价过程中误差最值出现在某个负载点下,则选用该负载点下的误差负理想解进行评价。在步骤二中已经对状态影响量进行了量化,得到各电表误差最值s1的计算结果分别为:电表1为0.108;电表2为0.042;电表3为0.089;电表4为0.067;电表5为0.075;电表6为0.117;电表7为0.111;电表8为0.056;电表9为0.017;电表10为0.1059。根据误差最值所属的负载点,可以得到这些电表的正负理想解,若出现误差最值同时出现在两个负载点的情况,则选择数值较小的负理想解,得到结果如下表:(1).误差一致性要求同一批次数只被试样品在同一测试点的测试误差与平均值间的偏差不能超过一定的限定值。各级电表的一致性误差限值如下表:一致性误差限值表(1级,2级仪表)负载ib(cos=1.0、0.5l)0.1ib(cos=1.0、0.5l)误差限值±0.3±0.4一致性误差限值表(0.2s级仪表)负载ib(cos=1.0、0.5l)0.1ib(cos=1.0、0.5l)误差限值±0.06±0.08一致性误差限值表(0.5s级仪表)负载ib(cos=1.0、0.5l)0.1ib(cos=1.0、0.5l)误差限值±0.15±0.2由于误差一致性的最好情况为0,故得到在本研究中各等级仪表的误差一致性正负理想解如下:根据步骤二的结算结果,得到各电表最大一致性s2的计算结果分别为:电表1为0.04471;电表2为0.05539;电表3为0.05229;电表4为0.0149;电表5为0.01671;电表6为0.0441;电表7为0.05871;电表8为0.05229;电表9为0.06139;电表10为0.05361。根据误差变差的正负理想解确定标准,可以得到误差一致性的正负理想解如下表:(2).误差变差正负理想解误差变差的正负理想解为对同一被试样品相同的测试点,在负荷电流为ib、功率因数为1.0和0.5l的负载点进行重复测试结果间的最大误差变化的绝对值不应超过一定范围,各等级电表的该数值极限如下表。各等级电表误差变差限表(1级、2级、0.2s级、0.5s级仪表)准确度等级210.2s0.5s误差变差限(%)0.20.20.040.1由于误差变差的最好情况为0,故各等级电表误差变差的正负理想解如下表:误差变差正负理想解可以看出,误差变差的负理想解由负载点和电表准确度等级共同确定。根据步骤二的计算结果,得到各电表最大误差变差s3的计算结果分别为:电表1为0.005;电表2为0.011;电表3为0.006;电表4为0.009;电表5为0.003;电表6为0.003;电表7为0.009;电表8为0.003;电表9为0.006;电表10为0.004。根据误差变差的正负理想解确定标准,可以得到误差变差的正负理想解结果如下表。(3).故障率要求根据智能电能表的国家标准,产品的设计和元器件选用应保证整表使用寿命大于等于10年,产品从验收合格之日起,由于电能表质量原因引起的故障,其允许故障率应小于等于规定值,见下表。智能电表寿命保证期内允许的故障率上表规定了批次电表当年的允许故障率,由于本研究所使用的故障率数据为在进行评价时所得到的累积故障率,于是对规定故障率进行累加操作,得到各年份对应的故障率允许限值表:智能电表各年份累积允许故障率由于故障率的最好情况为0,于是可以得到各年份的故障率正负理想解如下:故障率正负理想解根据步骤二的计算结果,得到各电表最大误差变差s4的计算结果分别为:电表1为0.256;电表2为0.256;电表3为0.256;电表4为0.256;电表5为0.256;电表6为0.256;电表7为0.256;电表8为0.256;电表9为0.256;电表10为0.256。批次电表故障率负理想解根据电表从安装日期至进行评价的时间确定,由于同一批次的电表可能出现使用时间不一致的现象,因此批次电表的运行时间按照该批次电表的平均运行时间进行计算,运行时间不足1年的按1年计算,运行时间1-2年的按两年计算,以此类推。示例数据中,该批次电表平均运行时间为16280.9小时,合1.86年,因此故障率限值为0.45%。即负理想解为0.45。于是我们得到故障率的正负理想解确定情况如下:电表1-10的准确度等级均为2,故障率正理想解均为0,故障率均为0.256,故障率负理想解均为0.45。经过上面的计算,我们将示例中数据的状态影响量量化值及其正负理想解进行总结,得到结果表格如下:状态影响量数据及其正负理想解状态影响量数据及其正负理想解(续)2.计算贴近度由于评价均为成本型状态影响量,故由可得到距离贴近度的计算公式如下:其中,zij表示经过无量纲化处理之后的数值,表示第i个评价对象在j个状态影响量下的正理想解,表示第i个评价对象在第j个状态影响量下的负理想解,和分别表示第i个评价对象在第j个状态影响量下的与正理想解的距离和与负理想解的距离。我们可以求得在各状态影响量下各评价对象与正负理想解的贴近程度,故可得到电表的topsis得分,为方便后续步骤,分数范围[0,1],该项状况越好,得分越高,示例样表如下:电表的topsis得分如下序号误差一致性误差变差误差最值故障率10.9100.8510.9750.43120.9650.8150.9450.43130.9260.8260.9700.43140.9440.9500.9550.43150.9380.9440.9850.43160.9030.8530.9850.43170.9080.8040.9550.43180.9530.8260.9850.43190.9860.7950.9700.431100.9120.8210.9800.431s3:计算各状态影响量的离差最大化权重值,经过无量纲化处理之后新得到的决策矩阵z=(zij)m×n,设各个状态影响量之间的权向量为w=(w1,w2,…,wn)t>0并满足:于是,我们可以得到加权向量下的加权决策矩阵:于是,第i个被评价对象的综合评价值可以表示为:其中,zij表示经过无量纲化处理之后的决策矩阵数值,wj表示第j个状态影响量的权重。可以根据各评价对象综合评价值的大小,对各评价对象作出科学的评价比较和排序分析。1、定义并计算离差对于第j个状态影响量来说第i个评价对象ai与其他所有决策方案的离差用vij(w)表示,其可以定义为:令其中,zij表示经过无量纲化处理之后的决策矩阵数值,wj表示第j个状态影响量的权重,vj(w)表示第j个状态影响量的总离差用。2、构造并求解目标函数vj(w)表示对第j个状态影响量而言,所有评价对象与其他评价对象的总离差。显然,如果在某个状态影响量下所有评价对象的值一样,那么该向量就无法对评价起作用。反之,如果某个在某个向量下不同的评价对象能够很好地区分,那么该向量应该给与更大的权重。因此,加权向量w应该使得各个对象之间尽可能的区分,即应该使得离差vj(w)最大,为求出能使得vj(w)达到最大的权向量,构造目标函数:要解上方程,即求解如下最优化问题:解上方程可得到:其中,zij与zkj都表示经过无量纲化处理之后的决策矩阵数值(k≠i),wj表示第j个状态影响量的权重。可以证明权向量w=(w1,w2,…,wn)t为目标函数f(w)的唯一极大值点。在得到单位化加权向量w之后,对权向量按下式对w进行归一化处理,计算公式如下:由于直接计算wj较为复杂,结合上面的归一化公式之后能够得到归一化之后的权重向量的解析解,计算公式为:经过计算可得到各状态影响量的离差最大化权重如下:s4、根据得到的最大化权重和改进的状态影响量topsis得分的贴近度计算智能电表运行状态得分;第i个被评价电表的运行状态评分公式为:式中,si表示第i个被评价对象的状态得分,表示归一化之后的第j个状态影响量的差最大化权重,c+ij表示第i个被评价对象在第j个状态影响量下与正理想解的贴近度。根据各状态影响量的topsis得分和权重,将电表状态影响量的topsis得分与其对应的权重进行加权求和,得到其加权得分即可以得到各批次电能表的评价得分,将评价结果用百分制表示,结果示例如下表:电能表运行状态得分示例表序号误差一致性误差变差误差最值故障率电表状态评价得分10.9100.8510.9750.43177.6320.9650.8150.9450.43177.0130.9260.8260.9700.43177.1440.9440.9500.9550.43180.4950.9380.9440.9850.43180.9560.9030.8530.9850.43177.7870.9080.8040.9550.43175.8280.9530.8260.9850.43178.0690.9860.7950.9700.43177.52100.9120.8210.9800.43176.98s5、根据对智能电表状态影响量数据的聚类分析,得到智能电表的运行状态聚类类别;为确定智能电表运行状态得分划分为状态等级的分数阈值,对状态影响量数据进行聚类分析,主要有以下几个过程。1.确定聚类方法聚类方法是机器学习领域的一种无监督方法,不需要提前知道数据的标签,聚类时一种根据数据的分布特点来对其进行类划分的一类算法,其基本原则是每一类样本的内部相似性尽可能高而类与类之间的相似性尽可能的低。根据聚类算法的不同,聚类方法可以分为层次聚类、划分聚类、基于密度的聚类和基于网格的聚类方法。各种方法有不同的优缺点,需要根据数据实际情况来确定聚类方法。2.确定聚类评价指标聚类方法的评价指标有内部指标和外部指标,外部指标针对有实际数据标签的数据,不适用于本发明所针对的情况,因此采用聚类的内部指标对其进行评价,聚类分析的主要内部评价指标如下。(1).ch指标(calinski-harabaszcriterion)ch指标又被称为,方差比准则(varianceratiocriterion(vrc)),其定义为:其中,ssb是总类间方差,ssw是总类内方差,k是集群数,n是观察数。总类间方差ssb定义为:其中,k是聚类的数量,ni是聚类i的观测样本数量,mi是聚类i的质心,m是样本数据的总体平均值,并且||mi-m||2是两个向量之间的l2范数(欧几里得距离)。总类内方差ssb定义为:其中,k是类的数目,x是样本,ci表示第i类,mi是第i类的质心,||x-mi||是两个向量之间的l2范数(欧几里得距离)。能明显分开的类具有较大的群集间方差(ssb)和较小的群集内方差(ssw)。vrck比越大,数据分区越好。(2).轮廓系数(silhouettecoefficient)每个点的轮廓值是与其他聚类中的点相比,该点与其自身聚类中的点有多相似的度量。它被定义为:其中,ai是从第i个点到同一集群中其他点的平均距离,bi是从第i个点到不同集群中的点的最小平均距离。轮廓值的范围是从–1到1。高轮廓值表示第个i样本与自己的类聚类较紧密,而与其他类分离。如果大多数点具有较高的轮廓值,则聚类解决方案是合适的。(3).dbi指数(davies-bouldincriterion)dbi指数的基本含义是类内距离与类间距离的比值。它被定义为:其中,di,j是第i类与第j类的类内距离与类间距离的比值,它被定义为:其中,是在第i类中每一个点到其质心的平均距离,是在第j类中每一个点到其质心的平均距离。di,j是第i类与第j类质心的距离。db值越小,聚类效果越好。3.根据聚类评价指标确定最佳聚类数目计算在不同聚类数目下的不同评价指标的值,从而选取合适的聚类数目。若不同的指标的最佳聚类数目不同,则选取不同评价指标下最佳聚类数对应的评价指标值最好的聚类数进行聚类分析。4.根据聚类数目对状态影响量进行聚类根据选取出来的最佳聚类数目,对运行状态影响量数据进行聚类,得到电表的运行状态聚类类别。示例采用凝聚型层次聚类方法对电表的评价数据进行聚类,采用轮廓值作为聚类结果好坏的评价标准。本研究使用福建地区19652条数据,共误差一致性、误差变差、误差最值和故障率四个状态影响量,计算在不同聚类数时的轮廓值,以得到最佳的聚类数目。附图2显示了当聚类数目为1-6时的轮廓值。可见,当类别数为3时,聚类的效果最佳,因此我们将数据聚成3类,即将电表的运行状态划分为3类。s6、根据电表的运行状态聚类类别,确定电表的运行状态得分划分阈值,得到智能电表运行状态的等级划分结果;统计不同的聚类类别对应的电表运行状态得分的分布情况,从而确定电表的运行状态得分划分阈值,根据阈值划分出电表的运行等级,最后分析不同聚类类别下的电表数据,赋予状态等级对应的工程含义。我们根据电表的3类聚类结果将电表的运行状态得分分为3级,得到电表分级后分布结果如附图3,从分数的对应结果可以较为清晰的看到,不同等级的电表集中在不同的分数段。其中,“等级1”电表对应的分数段主要集中在70-100分;“等级2”电表对应的分数段主要集中在55-70分;“等级3”电表对应的分数段主要集中在0-55分。因此我们根据此结果划分出智能电表的等级分数阈值,并赋予其相应的含义,以使其能够指导实践。划分结果如下。电表等级分数段含义1[70,100]优2[55,70]良3[0,55]差根据我们对划分结果的分析,以“电表等级3”为例,处于“电表等级3”的智能电表往往具有较高的误差和较高的批次故障率等情况,证明这些电表可能已经不再适合于运行,因此其处于评价分数集中在较低的分数段,这与工程实际是一致的,也证明了我们得出的评价结果的合理性。根据分数段划分表格,我们对示例样表中的电表进行等级划分,结果如下表。序号误差一致性误差变差误差最值故障率电表状态评价得分电表等级含义10.9100.8510.9750.43177.632良20.9650.8150.9450.43177.012良30.9260.8260.9700.43177.142良40.9440.9500.9550.43180.492良50.9380.9440.9850.43180.952良60.9030.8530.9850.43177.782良70.9080.8040.9550.43175.822良80.9530.8260.9850.43178.062良90.9860.7950.9700.43177.522良100.9120.8210.9800.43176.982良本发明先针对智能电表运行过程中产生的数据以及其他电表数据进行筛选,构建出智能电表运行状态影响量,同时结合改进后的topsis方法和离差最大化赋权方法,能够很好地将电表运行状态影响量信息进行融合,得到智能电表运行状态得分,最后结合聚类分析的方法将运行状态得分进行阈值划分,得到了电表的运行状态等级。本发明有效地克服了传统状态评价过于依赖专家经验以及只能得到相对评价结果的弊端,并且聚类分析方法的引入使得根据运行状态得分来进行运行状态等级更加符合数据实际,不再仅仅依赖于工程经验,具有较好的实际意义。以上所述的实施例仅是对本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1