一种实时人物视频去背景的方法和系统与流程
[0001]
本发明涉及图像数据处理技术领域,具体涉及一种实时人物视频去背景的方法和系统。
背景技术:
[0002]
随着在线视频会议的流行,虚拟背景已经成为一种有趣的技术现象。虚拟背景是实时系统地将每个输入的视频分为前景(多为人物)和背景。用户选择替代背景像素的图像或视频,该背景像素与前景层合成以生成人工视频流。
[0003]
现有技术中通常采用绿色屏蔽作为背景,但是,该方法主要考虑图像合成精度和质量,而没有考虑便捷性和效率,同时也不适用于普通用户在日常使用,因为很多时候没有办法提供绿幕背景。
技术实现要素:
[0004]
鉴于此,本发明实施例提供一种实时人物视频去背景的方法和系统,以解决上述技术问题。
[0005]
为实现上述技术目的,本发明实施例提供一种实时人物视频去背景的方法,其改进之处在于:包括以下内容:
[0006]
实时获取视频流;
[0007]
实时对视频流中的图像进行预处理;
[0008]
实时运行预先训练好的学生模型,以将图像中的人物轮廓图像抠出与预设虚拟图像融合,形成并显示融合图像,并更新学生模型;
[0009]
与学生模型异步运行教师模型,以对视频流进行在线蒸馏,并根据蒸馏结果更新学生模型。
[0010]
为实现上述技术目的,本发明实施例提供一种实时人物视频去背景的系统,其改进之处在于:
[0011]
获取模块,用于实时获取视频流;
[0012]
处理模块,用于实时对视频流中的图像进行预处理;
[0013]
执行模块,用于实时运行预先训练好的学生模型,以将图像中的人物轮廓图像抠出与预设虚拟图像融合,形成并显示融合图像,并更新学生模型;
[0014]
蒸馏模块,用于与学生模型异步运行教师模型,以对视频流进行在线蒸馏,并根据蒸馏结果更新学生模型。
[0015]
本发明由于采取以上技术方案,与现有技术相比,其具有以下优点:
[0016]
1.本发明通过预先训练好的学生模型进行虚拟背景融合处理,而学生模型运行快、效率高,因此,能够足够快的速度处理和推断每一帧,以保证实时视频的流畅性。
[0017]
2.本发明通过设置教师模型来执行在线蒸馏,能够平衡可控制的精度以获得更好的吞吐量,减少计算成本实现足够高质量的预测,而且设置与学生模型异步运行教师模型,
能够在低资源设置下实现高性能。
[0018]
本发明操作方便,成本低,可以广泛应用于图像数据处理技术领域,尤其是,视频会议中虚拟背景图像处理。
附图说明
[0019]
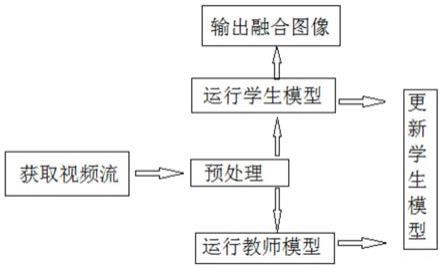
图1是本发明的实时人物视频去背景的方法其中一个实施例的流程图;
[0020]
图2是本发明的实时人物视频去背景的系统其中一个实施例的原理图。
具体实施方式
[0021]
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施方式和附图,对本发明做进一步详细说明。在此,本发明的示意性实施方式及其说明用于解释本发明,但并不作为对本发明的限定。
[0022]
如图1所示,本发明实施例提供一种实时人物视频去背景的方法,包括以下内容:
[0023]
实时获取视频流;
[0024]
实时对视频流中的图像进行预处理;
[0025]
实时运行预先训练好的学生模型,以将图像中的人物轮廓图像抠出与预设虚拟图像融合,形成并显示融合图像,并更新学生模型;
[0026]
与学生模型异步运行教师模型,以对视频流进行在线蒸馏,并根据蒸馏结果更新学生模型。
[0027]
其中,在线蒸馏是视频分割框架,利用帧之间的时间一致性来减少计算成本,大多数视频流观察范围非常小的子集,例如,一个固定的路口,一个特定的房间,通过高质量的教师模型来执行在线蒸馏,能够减少计算成本实现足够高质量的预测。
[0028]
显然,由于通过预先训练好的学生模型进行虚拟背景融合处理,而学生模型运行快、效率高,因此,能够足够快的速度处理和推断每一帧,以保证实时视频的流畅性。
[0029]
同时,由于设置教师模型来执行在线蒸馏,能够平衡可控制的精度以获得更好的吞吐量,减少计算成本实现足够高质量的预测,而且设置与学生模型异步运行教师模型,能够在低资源设置下实现高性能。
[0030]
可见,以上方案,能够有效提高虚拟背景的合成速度,人物提取的准确性,以及降低了对设备内存的要求,因此,非常适用于普通用户在日常使用。
[0031]
在一个实施例中,实时对视频流中的图像进行预处理,其中,预处理包括缩小图像尺寸,以及对图像做张量处理,以进一步缩短虚拟背景合成时间,提高效率。
[0032]
在一个实施例中,实时运行预先训练好的学生模型,以将图像中的人物轮廓图像抠出与预设虚拟图像融合,形成并显示融合图像,并更新学生模型,包括以下内容:实时运行预先训练好的学生模型,根据预设掩码面积阈值判断图像中是否存在人物轮廓图像,若不存在,则输出纯背景图像,并更新学生模型,若存在人物轮廓图像,则将人物轮廓图像抠出与预设虚拟图像融合,形成并显示融合图像,并更新学生模型。
[0033]
其中,预设掩码面积阈值可以设置为5%,但是不限于此,实际使用时,可以根据需要进行调整。
[0034]
显然,通过以上设置,能够有效避免在没有人物的视频中,学生模型过度拟合输出
空白等相关意外情况的发生。
[0035]
在一个实施例中,实时运行预先训练好的学生模型,以将图像中的人物轮廓图像抠出与预设虚拟图像融合,形成并显示融合图像,并更新学生模型,其中,根据bce loss(损失函数)和adam(优化算法)预先训练学生模型,以确保学生模型在开始时能够输出合理的融合图像。
[0036]
其中,学生模型可以采用jitnet数据集。
[0037]
在一个实施例中,教师模型可以采用mrcnn(目标检测算法)。
[0038]
基于同样的发明构思,本发明实施例还提供一种实时人物视频去背景的系统,如图2所示,包括:
[0039]
获取模块1,用于实时获取视频流;
[0040]
处理模块2,用于实时对视频流中的图像进行预处理;
[0041]
执行模块3,用于实时运行预先训练好的学生模型,以将图像中的人物轮廓图像抠出与预设虚拟图像融合,形成并显示融合图像,并更新学生模型;
[0042]
蒸馏模块4,用于与学生模型异步运行教师模型,以对视频流进行在线蒸馏,并根据蒸馏结果更新学生模型。
[0043]
其中,在线蒸馏是视频分割框架,利用帧之间的时间一致性来减少计算成本,大多数视频流观察范围非常小的子集,例如,一个固定的路口,一个特定的房间,通过高质量的教师模型来执行在线蒸馏,能够减少计算成本实现足够高质量的预测。
[0044]
显然,由于通过预先训练好的学生模型进行虚拟背景融合处理,而学生模型运行快、效率高,因此,能够足够快的速度处理和推断每一帧,以保证实时视频的流畅性。
[0045]
同时,由于设置教师模型来执行在线蒸馏,能够平衡可控制的精度以获得更好的吞吐量,减少计算成本实现足够高质量的预测,而且设置与学生模型异步运行教师模型,能够在低资源设置下实现高性能。
[0046]
可见,以上方案,能够有效提高虚拟背景的合成速度,人物提取的准确性,以及降低了对设备内存的要求,因此,非常适用于普通用户在日常使用。
[0047]
在一个实施例中,处理模块2包括:
[0048]
尺寸处理模块2,用于缩小图像尺寸;
[0049]
张量处理模块2,用于对图像做张量处理。
[0050]
显然,通过以上方案能够进一步缩短虚拟背景合成时间,提高效率。
[0051]
在一个实施例中,执行模块3包括:
[0052]
运行模块,用于实时运行预先训练好的学生模型;
[0053]
判断模块,用于根据预设掩码面积阈值判断图像中是否存在人物轮廓图像;
[0054]
执行子模块,用于当不存在人物轮廓图像时,输出纯背景图像,并更新学生模型,以及当存在人物轮廓图像时,则将人物轮廓图像抠出与预设虚拟图像融合,形成并显示融合图像,并更新学生模型。
[0055]
显然,通过以上设置,能够有效避免在没有人物的视频中,学生模型过度拟合输出空白等相关意外情况的发生。
[0056]
在一个实施例中,执行模块3包括:
[0057]
训练模块,用于根据bce loss(损失函数)和adam(优化算法)预先训练学生模型,
以确保学生模型在开始时能够输出合理的融合图像。
[0058]
显然,本领域的技术人员应该明白,上述的本发明实施例的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,并且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明实施例不限制于任何特定的硬件和软件结合。
[0059]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明实施例可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1