一种用于油气田生产的时序数据库系统的制作方法
本发明涉及油田生产数据处理领域,特别涉及一种用于油气田生产的时序数据库系统。
背景技术:
随着互联网在油气田生产领域的不断推进,油井生产监控平台产生了越来越多的基于时间序列的数据,这些数据被称为时序数据,各大油气田都在研究利用这些时序数据进行数据挖掘,并完善报警预警功能模块,从而实现自动预警和超前预警,提高生产管控、生产分析和生产决策的智能化水平。
在油气田生产过程中,对于一个检测对象需要大量的传感器进行监控检测,意味着需要存储大量的数据,随着指标对象的积累,数据库系统需要存储大量的历史数据,如果对数据处理不当,将会造成大量的存储设备资源浪费。检测对象有时会出现各种异常情况,现有技术中对异常情况的预警可靠性不高。
现有的油气田生产领域的数据库存储消耗大、写入性能差、查询效率低,且针对时序数据的预警普通的预警模型存在模型分析的数据源单一、模型分析过程会消耗大量服务计算资源的技术问题,而在实际生产运营过程中,业务预警往往是复杂多变的。
技术实现要素:
本发明的目的在于至少解决现有技术中存在的技术问题之一,提供一种用于油气田生产的时序数据库系统,能够节省服务器存储资源开销,提高数据查询效率且保证预警结果的可靠性。
根据本发明的第一方面,提供一种用于油气田生产的时序数据库系统,该系统包括:
至少一台联网的计算机;
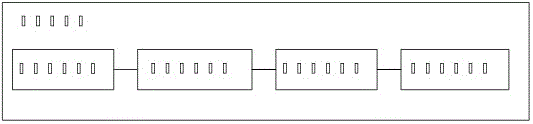
在所述计算机上运行本系统的软件数据获取模块、数据存储模块、数据压缩模块、及数据预警模块,上述模块依次相连接,所述时序数据的属性包括度量、指标、周期、时间戳和数据值属性;
所述数据获取模块,用于获取油气田生产中的时序数据,建立若干个数据源;
所述数据存储模块,用于将所述时序数据按照预定的时间段划分为多个数据文件存储,每个数据文件划分为多个数据块,并建立索引文件,根据所述时间戳对所述数据文件和所述索引文件编号,在索引文件中基于所述时序数据的度量和指标属性的不同组合构建键,通过键对应的值查找到每个所述组合的时序数据在索引文件内对应的索引的存储位置,该索引指向每个所述组合的时序数据在不同的所述数据文件中的所述数据块的存储位置,再通过计算所述数据文件的编号最终找到待存储或查询的所述时序数据所对应的数据文件中的存储位置;
所述数据压缩模块,用于将预设时间点t0之前的所有所述数据文件按顺序压缩为压缩文件;
所述数据预警模块,用于构建预警模型,并将若干个所述数据源的所述时序数据基于所述度量和指标属性的不同组合将预警模型解析成多个运算窗口,在每个结算周期对该运算窗口关联到的所述数据源进行模型结算,并根据设定的判定分判定是否发出预警信息。
根据本发明第一方面所述的,所述数据压缩模块,用于将预设时间点t0之前的所有所述数据文件按顺序压缩为压缩文件包括:将预设时间点t0之前的每个所述数据文件按该数据文件内的所述数据块压缩为所述压缩文件。
根据本发明第一方面所述的,当待存储的时序数据在时间上跨多个数据文件时,将所述时序数据在写入前先根据所述时间段分成多个区段,如果某个区段占用所述数据块的一部分,则定位到所述索引找到其所指向的数据块后,把所述某个区段中的数据点存放到该数据块中,如果所述区段跨越整个块,则把该区段的数据追加到不同的数据文件中,并记录对应索引指向的存储位置。
本发明实施例至少具有以下有益技术效果:针对油气田生产领域的数据特殊性,将时序数据库划分为数据块存储,降低了存储消耗,以时序数据的度量和指标属性构建索引文件中的键,既能存储大量数据,又支持灵活的条件查询,改善对于时间序列数据的查询效率;同时本发明采用每个模型多数据源的预警模型构建方案,多指标多算法组合运算及窗口化处理,组合协同判断,降低了运算的复杂性并保证了预警结果的可靠性。
附图说明
下面结合附图和实施例对本发明进一步地说明;
图1为本发明实施例用于油气田生产的时序数据库系统的逻辑结构图;
图2为本发明实施例中时序数据在时序数据库的数据文件中的存储示意图;
图3为本发明实施例时序数据库中预警模型、数据源、运算窗口之间的逻辑关系示意图。
具体实施方式
本部分将详细描述本发明的具体实施例,本发明之较佳实施例在附图中示出,附图的作用在于用图形补充说明书文字部分的描述,使人能够直观地、形象地理解本发明的每个技术特征和整体技术方案,但其不能理解为对本发明保护范围的限制。
在本发明的描述中,若干的含义是一个或者多个,多个的含义是两个以上,大于、小于、超过等理解为不包括本数,以上、以下、以内等理解为包括本数。
本发明的时序数据库应用于油气田生产领域,参照图1,为本发明实施例中的时序数据库系统的逻辑结构图,提供了一种应用于油气田生产的时序数据库系统,该系统包括:至少一台联网的计算机;在计算机上运行本系统的软件数据数据获取模块、数据存储模块、数据压缩模块、及数据预警模块,上述模块依次相连接,所述时序数据的属性包括度量、指标、周期、时间戳和指标数据值属性。
在本发明实施例中,数据获取模块,用于获取油气田生产中的时序数据,建立若干个数据源。时序数据的获取方式,包括但不限于时序数据库、关系数据库,轮询数据服务,人工导入等。
可以理解的是,时序数据是按照时间顺序记录的时间序列,其依赖于时间而变化,可以用数值来反映其变化程度的数据。获取的时序数据来源可以是油气田生产领域定频采集的时序数据。时序数据至少具有以下属性,度量metric、指标target、周期、时间戳stamp和指标数据值本身。
本申请实施例中的时序数据的度量metric代表数据的归属;target是指定频采集的测量值,周期是指测量值采集的周期。例如:每分钟采集一次输油管线g1的瞬时流量为100l/min;其中输油管线g1就是度量属性,瞬时流量就是指标属性,每分钟为周期,100l/min为指标的数据值。时间戳stamp是指格林威治时间1970年01月01日00时00分00秒000毫秒(北京时间:1970年01月01日08时00分00秒000毫秒)起至现在的总毫秒数。本申请实施例的时序数据可以具有多个不同的度量和指标。
本发明中的时序数据库系统中,数据存储模块,用于将时序数据按照预定的时间段划分为多个数据文件存储,每个数据文件划分为多个数据块,并建立索引文件,根据所述时间戳对所述数据文件和所述索引文件编号,在索引文件中基于所述时序数据的度量和指标属性的不同组合构建键,通过键对应的值查找到每个所述组合的时序数据在索引文件内对应的索引的存储位置,该索引指向每个所述组合的时序数据在不同的所述数据文件中的所述数据块的存储位置,再通过计算所述数据文件的编号最终找到待存储或查询的所述时序数据所对应的数据文件中的存储位置。
本发明实施例中,在时序数据写入数据库系统时,将获取的时序数据在数据库中按一定的时间段划分为多个数据文件存储,并对每个数据文件按照时间戳进行编号,以方便后续查找数据文件的位置。由于时序数据可以有多个度量和指标,则度量和指标具有多个不同的组合方式,则在即将存储的每个数据文件中划分为多个数据块,每个数据块仅存储该时间段内的一种度量和指标组合下的时序数据的指标数据值,该时间段是指所要存储的数据文件所在的时间段。其中,每个数据文件中数据块的数量为度量指标的组合数。
参照图2所示,为本发明实施例中时序数据在数据文件中的存储示意图,其中,block-x轴代表数据文件中的数据块,ts-y轴代表数据文件编号,r代表数据文件区,values-z代表数据块中的每个数据值点。
在时序数据库中,对应于上述多个数据文件建立索引文件,索引文件会记录时序数据在数据文件中的存储位置。本发明实施例中一个索引文件映射n个数据文件,其中,n为正整数。在索引文件中,对数据文件中的每个数据块建立索引,并利用时序数据的属性度量和指标构建键,键对应的值是对应每个度量和指标组合后在索引文件的存储地址。由于每个数据块对应存储度量和指标一种组合方式下的时序数据的指标数据值,因而通过索引文件中的键即可找到该度量和指标组合在不同时间段的数据块,这些数据块分别位于不同时间段的多个数据文件中。
作为本发明实施例的一个具体示例,例如,时序数据写入数据库的数据文件后,数据文件1中的时序数据包括度量属性m1、m2和指标属性t1、t2,则度量和指标的组合包括m1t1、m1t2、m2t1和m2t2四种组合方式,那么该数据文件1包含四个数据块,分别用于存储不同组合的时序数据的指标数据值。该数据文件1的时间段为t1,相应的,m1t1组合下的时序数据在t2时间段存储于在时间上连续的数据文件2中,以此类推。
本发明实施例中将时序数据划分为不同的数据文件存储,并对数据文件进行编号,可以快速定位到指定的数据文件。假设数据区的时间间隔是7天,那么1970-01-0100:00:00:000到1970-01-0700:00:00:000的数据就被划分在一个数据区内也就是一个数据文件。然后根据时间戳分配一个数据文件编号。
例如,数据文件编号的方式为,该数据区起始的毫秒时间戳除以7天的毫秒时间差的取整数部分,就是数据文件编号。
在本发明的一个实施例中,索引文件编号的方式为,根据当前时间戳stamp和格林威治时间stamp0(1970年01月01日00时00分00秒000毫秒)做差值计算得到的时间戳差值,时间戳差值除以n×时间间隔的毫秒时间戳总数的结果进行向下取整(floor)就是索引文件的编号。
例如,n取8,时间间隔为7天时,索引文件编号为:floor((stamp-stamp0)/(8*7*86400000))。
在本发明的一个实施例中,可以批量存储时序数据到时序数据库。当待存储的时序数据在时间上跨多个数据文件时,将所述时序数据在写入前先根据所述时间段分成多个区段,如果某个区段占用所述数据块的一部分,则定位到所述索引找到其所指向的数据块后,把所述某个区段中的数据点存放到该数据块中,如果所述区段跨越整个块,则把该区段的数据追加到不同的数据文件中,并记录对应索引指向的存储位置。
例如,一个存储任务为存储度量m18点到9点的电压指标时序数据,假设数据文件的时间间隔,即上文中的时间段为30分钟,时序数据周期beat为1分钟,那么需要存储的数据跨越两个区域,则采用数据切块分割的方式,把8点到8点半的数据划分为一个数据区的数据块中,把8点半到9点的数据划分为另一个数据区的数据块中,分别查找对应的索引并存储在对应的数据文件。
随着时间积累,时序数据库中的数据存储量会越来越大,而且时序数据往往具有历史数据应用性不强的特点,所以需要对历史积累的时序数据进行必要的压缩处理。
针对上述技术问题,本发明实施例中的数据库还包括数据压缩模块,用于将预设时间点t0之前的所有所述数据文件按顺序压缩为压缩文件。
具体地,数据库中的每个数据文件包含多个数据块,在对t0之前的数据文件进行压缩时,将每个数据文件以该数据文件中的数据块为单位采用现有的数据压缩算法进行压缩。在本实施例中,所使用的压缩算法为现有技术中的数据压缩算法,包括但不限于deflate、bzip2等。
本发明实施例中,还包括对数据源的数据异常的情况进行预警的过程。因此,本发明的时序数据库系统包括数据预警模块,用于构建预警模型,并将多个数据源的所述时序数据基于所述度量和指标属性的不同组合将预警模型解析成多个运算窗口,在每个结算周期对该运算窗口关联到的所述数据源进行模型结算,并根据设定的判定分判定是否发出预警信息。
可以理解的是,该预警模型可以为一静态数据模型,设置了结算周期、预警对象、数据源(可多个)和判定分属性。
其中,结算周期是指预警模型按固定周期进行结算,判定是否发出预警消息。例如每30分钟判断一次最近1小时的平均流量是否出现异常。预警对象是指预警模型对应的实体对象,比如一个设备、一口油井等,模型判定成功后,会发出针对此对象的报警消息。判定分是指预警模型结算成功的所需分数。
作为本发明的一个具体实施例,预警模型内关联到若干个数据源的时序数据,对模型内的所有数据源分别设置权重分,用于判断数据是否异常,正常则该数据源权重分为0,异常则取其预置的权重分,模型内的所有数据源异常情况判定结束后,所有数据源的权重分累加,若该累加分超过模型的判定分,则发出预警消息,反之,不会发出预警消息。
比如模型判定分100,对数据源1、数据源2和数据源3分别设置权重分分别为60,40,40。结算成功的数据源会累加计分,总分超过判定分,则发出预警消息。所以数据源1+2或者数据源1+3会发出预警,数据源2+3则不会发出。这就是多个数据源组合预警的意义,依托多个数据源进行逻辑判定,可以大大增加预警消息的可靠性。
在本发明实施例中,如果有多个预警模型,例如2个,则预警模型、数据源、运算窗口之间的逻辑关系如图3所示。需要说明的是,图3中运算窗口γ可以同时被模型a和b结算时使用,也就是上文所说明的,运算窗口可以关联所有度量metric和指标target相同的数据源,节省了系统内存资源,这在预警模型数量较大时会体现的更显著。
上面结合附图对本发明实施例作了详细说明,但是本发明不限于上述实施例,在所述技术领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!