一种基于数据关联模型的产品深度溯源方法与流程
本发明涉及一种基于数据关联模型的产品深度溯源方法,尤其涉及一种构建相关产品属性参数逻辑关联模式映射的实现方法。
背景技术:
随着市场消费者对产品质量安全愈发加剧的关注,实现完整、可信、安全的供应链全过程溯源,并且可进行高效的多级关联溯源,让消费者和有关监管部门可对产品质量安全进行全面的监控,是目前诸多行业的关注焦点。
目前市场上所使用的溯源技术,主要的实现能力为对某一产品的单一一段生产加工流通过程,读取数据库存储的所有信息,形成过程溯源查询。现有溯源信息检索技术因依赖环节与环节、产品与产品之间的单链跳转读取数据模式,检索效率较低,也无法实现智能化多级深度溯源。只适用于检索路径简单、待关联资源的种类少、业务场景不复杂的场合,并且需要较多的人工数据整理和任务衔接工作。单链跳转读取数据模式检索效率低且具有局限性、容易造假、容易瞒报溯源信息。
技术实现要素:
发明目的:针对现有溯源检索技术的低效率运作、无法智能化多级深度溯源的缺陷,本发明提供一种基于数据关联模型的产品深度溯源方法。本发明旨在升级已有溯源技术所能达到的溯源能力,在全供应链流通环节实现正确可信、完整高效、可智能化多级深度溯源和多级检索、对全局检索更具规划控制力的溯源技术,来服务终端市场、服务相关产业、服务有关监管部门。
技术方案:一种基于数据关联模型的产品深度溯源方法,通过溯源信息录入平台和溯源信息检索平台进行实现,包括如下步骤:
1)在溯源信息录入平台中对录入的不同供应链节点的产品属性参数展开进行解读,包括:
101,在生产加工过程、供应链环节中,用现实逻辑先筛选出录入节点,标记录入节点;
102,展开每一个节点数据的完整录入结构,包括把节点的完整字段结构展开并录入;
103,对字段自然属性与语义属性进行解读;
104,提取字段信息关键词并归类到逻辑性数据结构内,在逻辑性数据结构内形成字段名称标记;
105,按照逻辑性数据结构存储数据。
所述内容1)中,节点的字段结构通过xml可扩展标记语言编写实现,创建dom转换,把节点字段结构的字符串转换成dom对象。
2)形成映射路径与关联检索模型,包括:
201,编码标记逻辑性数据结构内的属性参数关键词,其中,属性参数关键词的编码中必须标记投入品参数的被引用功能;
202,以产品生产加工过程时间节点链为主线、逻辑子结构为分线形成供应链所有节点与字段信息之间的完整映射路径;
203,将标记编码代入完整映射路径即形成数据关联检索模型。
3)在溯源信息检索平台中检索某一关键词,沿完整映射路径进行正逆向溯源查询,包括:
301,检索并定位到检索路径最短的一个关键词所在节点与子结构位置;
302,沿映射路径正逆向检索,按照标记编码形成这一检索词的唯一检索映射路径。
4)按照映射路径从相关数据库读取全部所需数据。
401,根据检索关键词读取用户所需的某段映射路径;
402,通过负载均衡优先在数据缓存库字典服务中查找匹配字段,
403,如果有匹配的字段,则读取全部相关溯源信息,所述相关溯源信息指的是和匹配字段在同一条检索映射路径上的相关字段信息,
404,如果没有匹配的字段,则进入下一级负载均衡选择,在数据库中查找匹配字段,
405,如果有则读取全部相关溯源信息;
406,如果没有则视为读取失败。
所述供应链指的是:种源投入品-养殖/种植-生产加工-物流销售。基于供应链的描述,所述节点含义为:种源投入品环节的节点包括购种源、存种源等,养殖/种植环节的节点包括育苗、育种、浇水施肥、喂食等,生产加工环节的节点包括清洗、煮制、包装等,物流销售环节的节点包括物流、分销、购买等。
所述展开每一个节点数据的完整录入结构:指将每一个节点所包含字段信息列出,并定义字段类型。
有益效果:与现有技术相比,本发明提供的基于数据关联模型的产品深度溯源方法,可以快速检索溯源信息。本发明可广泛应用于智慧农业信息化管理体系,应用成本低,维护简单,并具有功能性优势与广阔的开发前景。本发明核心优势总结如下:
1)溯源信息结构化存储,存储结构更清晰,可有效避免数据重复存储、脏数据误存等操作,有效减少在数据整理和跳转衔接中的人力工作。
2)根据逻辑数据结构建立数据关联检索模型与检索映射路径,优化检索速度和正确率,提高对全局检索行为的规划和控制能力。
3)通过完整映射路径,支持在多级深度溯源中,提前进行多步、多路发现路径的规划,并对运行过程中发生的耗时、失败等情况,具备有效的控制能力。
4)基于以上技术优势基础,可以适应更复杂的业务场景与更高级的检索任务模式。
附图说明
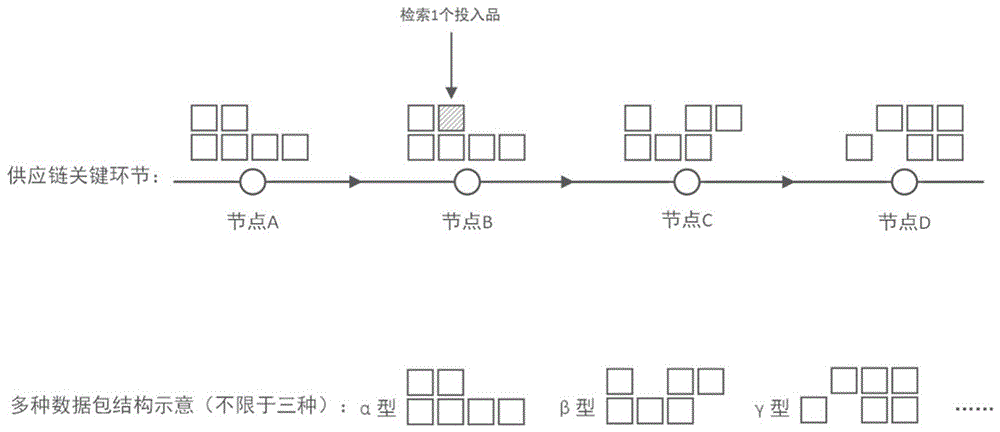
图1是数据多级关联检索映射模型示意图;
图2是建立数据关联检索模型与正逆向溯源查询流程示意图,对应流程1)~3);
图3是多级关联检索数据高效读取流程示意图,对应流程4)。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
基于数据关联模型的产品深度溯源方法,通过溯源信息录入平台和溯源信息检索平台进行实现,包括如下步骤:
1)在溯源信息录入平台中对录入的不同供应链节点的产品属性参数展开进行解读,如图2所示,包括:
101,在生产加工过程、供应链环节中,用现实逻辑先筛选出录入节点,标记录入节点;
102,展开每一个节点数据的完整录入结构,包括把节点的完整字段结构展开并录入;
103,对字段自然属性与语义属性进行解读;
104,提取字段信息关键词并归类到逻辑性数据结构内,在逻辑性数据结构内形成字段名称标记;
105,按照逻辑性数据结构存储数据。
所述内容1)中,节点的字段结构通过xml可扩展标记语言编写实现,创建dom转换,把节点字段结构的字符串转换成dom对象。
2)形成映射路径与关联检索模型,如图2所示,包括:
201,编码标记逻辑性数据结构内的属性参数关键词,其中,属性参数关键词的编码中必须标记投入品参数的被引用功能;开发者可以自行定义自己开发的系统的编码形式,比如在实施例1中所示,所采用的编码方法是12位数字字母混编,也许可以采用10位纯字母编码或者15位纯数字编码。编码:‘南粳555’|0954ap4c5c21,‘25g/l咯菌腈悬浮’|2h532gm8b1qa;首位数字0表示该关键词是作为品种名被引用的,首位数字2表示该关键词是作为种植投入品使用的。
202,以产品生产加工过程时间节点链为主线、逻辑子结构为分线形成供应链所有节点与字段信息之间的完整映射路径;
203,将标记编码代入完整映射路径即形成数据关联检索模型。
3)在溯源信息检索平台中检索某一关键词,沿完整映射路径进行正逆向溯源查询,如图2所示,包括:
301,检索并定位到检索路径最短的一个关键词所在节点与子结构位置;
302,沿映射路径正逆向检索,按照标记编码形成这一检索词的唯一检索映射路径。
4)按照映射路径从相关数据库读取全部所需数据。如图3所示。
401,根据检索关键词读取用户所需的某段映射路径;
402,通过负载均衡优先在数据缓存库字典服务中查找匹配字段,
403,如果有匹配的字段,则读取全部相关溯源信息,所述相关溯源信息指的是和匹配字段在同一条检索映射路径上的相关字段信息,
404,如果没有匹配的字段,则进入下一级负载均衡选择,在数据库中查找匹配字段,
405,如果有则读取全部相关溯源信息;
406,如果没有则视为读取失败。
实施例1
基于数据关联模型的产品深度溯源方法,通过基于数据关联模型的产品深度溯源系统实现,系统包括溯源信息录入平台和溯源信息检索平台,在创建产品a的生产加工信息项目时,可创建配置一个及以上的生产加工操作,比如:品种选择、育种、耕地、育秧等,该生产加工操作即为标记的录入节点。
针对每一个生产加工操作可定义其数据的完整录入结构,即生产加工操作的属性字段个数。比如“品种选择”操作的数据结构包含:品种名称、品种等级、品种适用地3个属性字段,“育种”操作的数据结构包含:育种环境温度、育种土壤湿度、育种时间、育种投入品、其他育种干预措施4个属性字段。
完成生产加工操作属性字段的定义后,系统将对所有属性字段参数的自然属性和语义属性进行解读,如:“品种选择”操作中的“品种名称”属性字段的自然属性为字符串(string),其语义属性为“品种选择”节点的主语型关键检索字段(subt)。如:“育种”操作中的“育种时间”属性字段,其自然属性为浮点型数值(float),其语义属性为“育种”节点的状语型关键控制字段(advc)。再如“育种”操作中的“其他育种干预措施”属性字段,其自然属性为字符串(string),其语义属性为“育种”节点的补充型信息字段(remark)。
系统自动解读完所有产品a生产加工项目中包含的操作节点的字段参数属性后,将把提取到的信息关键词归类到逻辑性数据结构内。比如“品种选择-育种”这一段节点链上,形成的逻辑性数据结构为:[01品种名称]string|subt+[02品种等级]string|remark+[03品种适用地]string|remark>>[01育种环境温度]string|remark+[02育种土壤湿度]string|remark+[03育种时间]float|advc+[04育种投入品]string|subt+[05其他育种干预措施]string|remark。
当实际系统用户在溯源信息录入平台中对生产加工操作节点的属性字段进行填写时,系统获取到的输入值将按照上述逻辑性数据结构存储于数据库中。以“品种选择-育种”这一段操作填写举例:[01‘南粳555’]string|subt+[02‘a级’]string|remark+[03‘江苏’]string|remark>>[01‘15℃’]string|remark+[02‘40%’]string|remark+[03‘15.3333’]float|advc+[04‘25g/l咯菌腈悬浮’]string|subt+[05‘每666.7m2用种量控制在3kg~3.5kg,配合使用25g/l咯菌腈悬浮200ml/100kg~300ml/100kg’]string|remark。
当所有生产加工操作节点的属性字段的数据按结构存储到数据库中后,后端核心代码将针对不同的字段自然属性、语义属性类型,对关键词进行标记编码,并存入数据缓存库redis字典服务中。关键词和编码举例:‘南粳555’|0954ap4c5c21,‘25g/l咯菌腈悬浮’|2h532gm8b1qa。
将标记编码代入以生产加工过程时间节点链为主线、逻辑子结构为分线形成完整映射路径即形成数据关联检索模型。以产品a的“品种选择-育种”这一段节点链举例模型形态示意:[‘品种选择’-[01‘南粳555’|0954ap4c5c21]+[02]+[03]]>>[‘育种’-[01]+[02]+[03]+[04‘25g/l咯菌腈悬浮’|2h532gm8b1qa]+[05]]。
同理,假如投入品“25g/l咯菌腈悬浮”作为产品b在系统中也进行相关产品信息填充,也将具有类似于产品a“南粳555”的完整映射路径和数据关联检索。同时产品b作为产品a的“育种”节点投入品,可成为下一级溯源检索的对象。
当溯源信息检索平台用户对产品a发起检索时,系统将定位到匹配度最高、检索路径最短的关键词“南粳555”(该字段已存在于数据缓存库redis字典服务中)所在的节点和节点子结构位置(此例中为“品种选择”节点)。
如果检索平台向后端发出的下一步查看指令为“查看‘育种’节点的全部数据信息”,则按照标记编码“0954ap4c5c21”为起始,以正向检索方向形成唯一检索映射路径[‘品种选择’-[01‘南粳555’|0954ap4c5c21]]>>[‘育种’-[01]+[02]+[03]+[04‘25g/l咯菌腈悬浮’|2h532gm8b1qa]+[05]]。数据库将按照映射路径,读取“育种”节点中01-育种环境温度、02-育种土壤湿度、03-育种时间、04-育种投入品、05-其他育种干预措施的所有数据信息。其中04-育种投入品的数据信息关键词存在于数据缓存库redis服务中,其他01、02、03、05序号对应数据信息存在于普通数据库存储区内。此时溯源信息检索平台用户也可以连续性地对“25g/l咯菌腈悬浮”的相关数据发起溯源检索。
如果溯源信息检索平台用户一开始对“南粳”两字发起搜索,此时“南粳”两字不能完全匹配“南粳555”或其他产品品名,数据库在redis字典服务中快速读取失败,通过负载均衡选择,在数据库中模糊搜索匹配所有包含“南粳”关键词的相关信息并返回给用户。
如果溯源信息检索平台用户一开始对“南梗”两字(输入有误的情况)发起搜索,此时“南梗”两字不能匹配任何产品品名或存在于redis字典服务中的任何关键词,通过负载均衡选择,在数据库也无法模糊搜索匹配到任何与“南梗”相关的数据,则本次溯源检索将返回“检索失败”的信息给用户。
- 还没有人留言评论。精彩留言会获得点赞!