一种面向空间数据的高效空间k核挖掘方法与流程
[0001]
本发明属于图数据挖掘技术领域,尤其涉及一种面向空间数据的高效空间k核挖掘方法。
背景技术:
[0002]
随着gps设备的增加,每天产生的空间数据越来越多。例如在twitter中,用户可以发 送带有地理位置信息的tweets。在facebook上,用户可以通过签到来标记访问过的地方,并 通过地理标签发布信息。对于空间数据的分析,一个重要的问题是如何快速识别数据的内聚 结构。目前研究中人们已经提出了各种模型,如最小覆盖圆和空间团模型,它们可以来捕捉 空间数据中的内聚结构和组。然而计算这些模型通常是耗时的。利用团概念的空间团模型要 求所挖掘的子集中的每一对点,在空间上是接近的,即它们之间的距离有一定的限制,不大 于给定距离阈值r。然而极大空间团枚举问题是一个np-hard的问题,很难将该模型应用在一 些具有时间效率的应用中。而k核在图分析内用来衡量子图结构的内聚性,是使用最广泛的 模型之一,为了有效地识别空间数据集中的内聚结构,本发明基于k核模型概念提出了空间 k核模型。
技术实现要素:
[0003]
为了找到同时满足距离约束和内聚性约束的k核,本发明在空间数据集上提出了一种新 的内聚子图模型,称为空间k核,它满足三个条件:两个顶点之间的距离不大于距离阈值r; 每个顶点至少有k个邻居;是极大的,即它的任何超图都不能满足前面两个条件。
[0004]
空间k核是一个满足约束度且具有地理位置的k核;可以运用四叉树框架,对数据集不 断进行四等划分,通过修剪规则得到空间图,在空间图上进行核分解计算实现空间k核的挖 掘。空间k核模型在真实世界中可以找到许多的应用,如挖掘潜在的社区,识别关键模式等。 例如蚂蚁是群居动物,它们有很多距离相邻的同伴,在蚁群中,蚂蚁的社区分工很细致,以 至于不被人们所熟知。因此我们可以使用该模型来挖掘它们潜在的社区分工。此外在传染病 分析中,人与人之间如果距离较近,即在距离r内,则更容易相互感染。考虑到感染的概率 (1/k),在较大的空间k核内,意味着疾病暴发有更高的可能性。我们可以利用空间k核模型 来有效地挖掘疾病扩散模式,根据疾病扩散模式我们可以很容易找到扩散源头以及规模,并 及时进行抑制。
[0005]
本发明通过利用四叉树框架来开发新的修剪方法,从而显著地修剪没有希望的顶点。此 外,本发明开发了高效的基于边界的算法,简称为bound-based算法,从而能在大型空间数据 集中更有效地找到空间k核。
[0006]
本发明解决其技术问题的技术方案具体如下:一种面向空间数据的高效k核挖掘方法, 该方法包括以下步骤:
[0007]
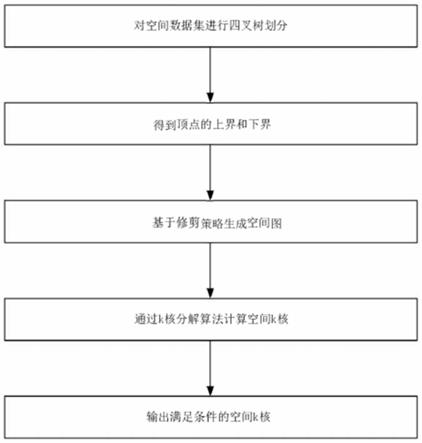
步骤一,运用四叉树框架,对带有地理位置的空间数据集不断进行四等划分,直到数据 集中每个点都位于所划分的矩形区域内。
[0008]
步骤二,遍历数据集内顶点,以顶点为圆心,距离阈值r为半径,画一个圆;将该圆的 外切矩形作为顶点的上界,其内切矩形作为顶点的下界,得到顶点的上界和下界。
[0009]
步骤三,结合边界修剪策略生成空间图:定义为顶点的上界值,r为顶点的下界值。 顶点到区域的距离,为顶点到区域四个顶点的距离,如果四叉树中某个区域与顶点的最小距 离大于上界值时,我们需要删除该区域;如果该区域与顶点的最大距离小于等于下界值时, 则该区域内的所有点都可以直接放入该顶点的邻居集合中;如果该区域与顶点的最小距离大 于下界值且最大距离小于等于上界值时,需要进一步计算区域内所包含的点与该顶点之间的 距离大小。处理完所有的顶点后,如果两个点之间的距离小于给定距离阈值r,那么它们之间 将会用一条边相连接,从而生成空间图。
[0010]
步骤四,在空间图上进行空间k核的挖掘,包括:运用核分解技术,计算空间图中顶点 邻居的数量,并且不断地删除邻居数量小于k的顶点,直到空间图中所有的顶点其邻居的数 量都大于等于k,最终得到空间k核;输出所有满足条件的空间k核,即被挖掘的内聚子图。
[0011]
进一步,所述步骤二包括:在步骤一划分区域内,以顶点为圆心,距离阈值r为半径, 画一个圆。将该圆的外切矩形作为顶点的上界,其边长为2r
×
2r;将该圆的内切矩形作为顶点 的下界,其边长为
[0012]
进一步,所述步骤三中具体的修剪策略包括:
[0013]
(a)如果被划分的区域为空,那么我们就删除该区域;
[0014]
(b)如果区域不为空,但是与顶点的最小距离大于其上界值,那么我们仍然删除该区域;
[0015]
(c)如果区域与顶点的最大距离小于等于下界值,则可以直接将该区域内的顶点直接插 入到顶点的邻居集合中;
[0016]
(d)如果区域与顶点的最大距离小于等于上界值,但是最小距离大于下界值,那么我们 需要进一步计算区域内的顶点与该顶点的距离,从而判断其是否小于等于距离阈值r。
[0017]
本申请还提出了一种服务器,所述服务器包括处理器和存储器,所述存储器中存储有至 少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所 述代码集或指令集由所述处理器加载并执行以实现上述方法。
[0018]
本申请还提出了一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少 一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集 由处理器加载并执行以实现上述方法。
[0019]
本发明的有益效果为:为了找到同时满足距离约束和内聚性约束的核(一种内聚子图), 本发明提出了新颖的空间k核模型。本发明通过该模型得到的社区具有很强的稳健性,并且 可以挖掘潜在的社区以及识别关键模式。考虑到四叉树和k核的属性,本发明提出新的修剪 策略,从而更有效的缩减搜索空间。与此同时,本发明结合新的剪枝策略开发了高效的基于 边界的算法,即bound-based算法,从而能在大型空间数据集中迅速有效的找到空间k核。因 此,面向空间数据的高效空间k核挖掘方法的应用对于潜在社区的挖掘以及识别空间数据集 的关键模式有着极大地效益。
附图说明
[0020]
图1是本发明挖掘空间k核方法流程图;
[0021]
图2是原始空间k核模型图;
[0022]
图3-图4是对原始空间图进行四叉树划分以及修剪操作的示意图;
[0023]
图5是在过滤后的真实世界中的空间k核道路网络示意图。
具体实施方式
[0024]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体 实施方式做详细的说明。
[0025]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其 他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做 类似推广,因此本发明不受下面公开的具体实施案例的限制。
[0026]
本申请提出的一种面向空间数据的高效空间k核挖掘方法,该方法包括修剪策略和高效 的基于边界的空间k核挖掘算法(简称bound-based算法),该方法的具体实现流程如下:
[0027]
步骤一,运用四叉树框架,对带有地理位置的空间数据集不断进行四等划分,直到数据 集中每个点都位于所划分的矩形区域内。
[0028]
步骤二,遍历数据集内顶点,以顶点为圆心,距离阈值r为半径,画一个圆;将该圆的 外切矩形作为顶点的上界,其内切矩形作为顶点的下界,得到顶点的上界和下界。
[0029]
步骤三,结合边界修剪策略生成空间图:定义为顶点的上界值,r为顶点的下界值。 顶点到区域的距离,为顶点到区域四个顶点的距离,如果四叉树中某个区域与顶点的最小距 离大于上界值时,我们需要删除该区域;如果该区域与顶点的最大距离小于等于下界值时, 则该区域内的所有点都可以直接放入该顶点的邻居集合中;如果该区域与顶点的最小距离大 于下界值且最大距离小于等于上界值时,需要进一步计算区域内所包含的点与该顶点之间的 距离大小。处理完所有的顶点后,如果两个点之间的距离小于给定距离阈值r,那么它们之间 将会用一条边相连接,从而生成空间图。
[0030]
步骤四,在空间图上进行空间k核的挖掘,包括:运用核分解技术,计算空间图中顶点 邻居的数量,并且不断地删除邻居数量小于k的顶点,直到空间图中所有的顶点其邻居的数 量都大于等于k,最终得到空间k核;输出所有满足条件的空间k核,即被挖掘的内聚子图。
[0031]
以下以图2所示原始空间k核模型图为示例描述本发明实现效果,在空间k核模型图中, 每个用户代表一个顶点,用户之间距离如果小于给定距离阈值r,那么用户之间就有边相连接, 而且在空间k核内,每个用户都至少有k个邻居与他们相连。如图所示,当k=3时,那么空 间3核就是图中阴影部分所覆盖的用户集合;图3所示,它是一个具有16个数据点的空间数 据集,在这个数据集内,顶点之间距离如果不大于r,那么它们之间有一条边相连接;图4 为步骤三修剪后的子图,在图4中以顶点a为圆心,r为半径,画一个圆,然后分别画一个 2r
×
2r的矩形为a的上界,的矩形为a的下界。上界和下界分别是以a为圆心的圆 的外切矩形和内切矩形,这样做的好处是,可以直接删除处于上界之外的点,以及把处于下 界之内的顶点直接放入顶点a的邻居集合中。对于在上界和下界之间的顶点,我
们需要进一 步计算它们与顶点a之间的距离,分别于r作比较,距离大于r的顶点需要删除。图5是在 修剪后的真实世界中的空间k核道路网络示意图,在图中我们可以发现,空间k核内的对象 都聚集在道路网络比较密集的部分。侧面反映了我们设计空间k核的动机和意义。
[0032]
此外,本发明在五个真实世界的空间数据集上进行了广泛的实验,以评估所提出的方法 的有效性和高效性。为了评估所提出方法的性能,我们通过改变参数k以及距离阈值r进行 实验。本发明用算法消耗时间和空间k核的数量大小分别来衡量所提出方法的有效性和效率。 所有程序均在标准的c++中实现,所有实验均在配备intel i5-9600kf cpu和32gb主内存的 pc上进行。实验表明,本发明提出的基于边界的算法,即bound-based算法比基础的baseline 算法快了将近3个数量级。
[0033]
以上所述仅是本发明的优选实施方式,虽然本发明已以较佳实施例披露如上,然而并非 用以限定本发明。任何熟悉本领域的技术人员,在不脱离本发明技术方案范围情况下,都可 利用上述揭示的方法和技术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等 同变化的等效实施例。因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对 以上实施例所做的任何的简单修改、等同变化及修饰,均仍属于本发明技术方案保护的范围 内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1