一种基于卷积神经网络的三维人脸建模方法与流程
[0001]
本发明属于计算机视觉领域,涉及一种基于卷积神经网络的三维人脸建模方法。
背景技术:
[0002]
随着计算机视觉的飞速发展,和人脸三维数字化在医疗、影视动画制作、人机交互等领域需求的不断扩大,人脸三维建模越来越成为计算机视觉的研究热点。一个快速、完整、精确的三维人脸重建的系统能够广泛的应用于各行各业,有效的推动产业智能化。
[0003]
传统双目视觉的三维数字化通过双目摄像机获取图像,提取图像中被测物的表面纹理特征进行特征匹配,从而获得点云图,虽然成本低,但受环境光照和被测物体表面纹理复杂度的影响较大,点云密度低,三维建模粗糙。基于结构光的三维数字化虽然不受被测物体表面纹理复杂度的影响,但是受环境光影响较大。
技术实现要素:
[0004]
本发明的目的是提供一种基于卷积神经网络的三维人脸建模方法,解决了现有三维重建技术中存在的受环境影响大,配准效率低的问题。
[0005]
本发明所采用的技术方案是,一种基于卷积神经网络的三维人脸建模方法,具体按照如下步骤实施:
[0006]
步骤1,使用kinect相机分别从人脸的左侧、右侧和正前方采集人脸点云信息;
[0007]
步骤2,对步骤1采集到的人脸点云信息进行预处理,分割出目标物体点云,并对点云进行除噪和平滑;
[0008]
步骤3,采用基于卷积神经网络的配准方法,得到三个方向的平移配准参数和三个方向的旋转配准参数,实现点云的配准拼接;
[0009]
步骤4,利用泊松曲面重建法,对点云进行三维重建。
[0010]
本发明的特点特点还在于,
[0011]
步骤2具体为:
[0012]
步骤2.1,对z轴方向上的维度设置一定的深度距离阈值,将目标物点云与其他距离较远的无用信息分割出来,表达式如下:
[0013][0014]
d(z)为分割后获取的点云数据,若点在最大阈值depth_max和最小阈值depth_min之间,就分割出来,若在范围之外就舍弃掉;
[0015]
步骤2.2,将步骤2.1分割出来的点云通过快速双边滤波法,进行高斯线性卷积和双线性插值,对点云数据进行除噪和平滑。
[0016]
步骤2.2具体如下:
[0017]
步骤2.2.1,对步骤2.1分割出来的每一个点云数据点p=(x,y,z),求出它的m个邻域点q
i
(x
i
,y
i
,z
i
)及其深度值d
i
(u,v);
[0018]
步骤2.2.2,计算光顺滤波函数g
s
和g
r
以及三维高斯核函数g,计算公式如下:
[0019][0020][0021]
g=g
s
*g
r
ꢀꢀꢀ
(4)
[0022]
其中,g
s
为空间邻近度因子,g
r
为深度相似性因子,σ
s
和σ
r
分别为空间邻域标准差和深度标准差;
[0023]
步骤2.2.3,计算每个单位区域像素深度值之和wd和w,计算公式如下:
[0024][0025][0026]
其中,d
i
(u,v)为点p=(x,y,z)邻域的深度值,邻域三维空间合集为r;
[0027]
步骤2.2.4,将wd和w分别与三维高斯核函数g进行高斯线性卷积,并进行双线性插值,具体公式如下:
[0028][0029]
其中,interpolate为插值函数,求出滤波后的点云数据d
b
(x,y),实现三维点云数据的平滑。
[0030]
步骤3具体为:
[0031]
步骤3.1,构造卷积神经网络的点云配准模型;
[0032]
步骤3.2,用训练数据训练卷积神经网络的点云配准模型;
[0033]
步骤3.3,将步骤2得到的点云数据转化为深度图像数据,运用训练好的卷积神经网络的点云配准模型进行配准拼接。
[0034]
步骤3.1具体为;
[0035]
步骤3.1.1,构造网络结构;
[0036]
利用卷积神经网络计算点云深度图像的特征,再利用得到的特征计算配准参数;模型采用n组并联的卷积神经网络相互独立地提取深度图像的n种不同的特征,每种特征都是128维的向量,将深度图像x1的第一种特征向量x
11
与深度图像x2的第一种特征向量相减,得到第一种特征的差分向量d1;将n种不同的差分向量d1,d2,...,d
n
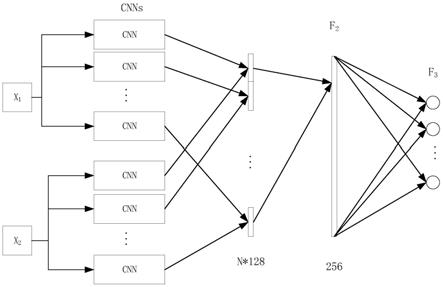
并联为配准的整体差分向量;整体差分向量经过以relu为激活函数的全连接层f2得到256维向量,最后经过全连接层f3得到6种不同的配置参数,通过对整个网络进行端到端的训练,网络各部分得以协调,使得在各种配准参数范围内网络均能有效配准;
[0037]
步骤3.1.2,构造网络模型的迭代点云配准方法;
[0038]
采用迭代地进行点云配准,将待配准的参数分为三组,即t
x
,t
y
,t
θ
,t
α
,t
β
,t
z
;先配准容易估计的配准参数,再配准较难估计的配准参数,使得配准过程容易进行;首先将x1和
x2输入配准网络模型得到配准参数t
x
,t
y
,t
θ
,利用得到的配准参数对深度图像x1进行更新,然后将x2和更新过的x1再次输入配准网络模型得到配准参数t
α
,t
β
,利用t
α
,t
β
对深度图像x1再一次更新,最后再次将x2和更新过的x1输入配准网络得到配准参数t
z
,利用t
z
对x1再一次更新,得到经过一次迭代后更新的深度图像x1,重复迭代k次,k为常数,通常设置为10以内,使得最后迭代得到的配准参数能够让x1和x2的配准误差小于设定的阈值。
[0039]
步骤3.2具体为;
[0040]
步骤3.2.1,采用普林斯顿形状数据集中的约1000个模型作为训练数据,首先利用opengl的深度测试功能拍摄三维模型的深度图像x1,然后按一定的配准参数y
i
旋转模型,并拍摄变换之后的深度图像x2,将x1、x2作为配准网络的输入并将y
i
作为训练目标;
[0041]
步骤3.2.2,按照步骤3.1.2的方法流程训练整个模型;
[0042]
整个网络模型的训练优化目标是使估计配准参数与真实配准参数的均方损失最小,定义为:
[0043][0044]
其中,m为训练样本数,y
i
为第i组样本的真实配准参数,x
i
为第i组输入的深度图像对,θ为模型中待训练的参数,模型采用xavier方法初始化网络参数以提高网络的训练效率,训练采用随机梯度下降的方法进行参数优化,其中梯度更新的批大小设置为100,梯度更新的动量为m=0.9,权值衰减率d=0.0001,对于参数θ的更新公式可表示为:
[0045][0046]
其中,i为梯度更新的次数,μ为梯度的动量,η
i
是第i次梯度更新时的学习率,是基于反向传播算法计算得到的目标函数对i时刻网络参数的偏导数,学习率η
i
随着训练而衰减,以使网络训练稳定。
[0047]
步骤3.3具体为;
[0048]
步骤3.3.1,计算左侧人脸点云和正面人脸点云的深度图像x1和x2,将深度图像作为卷积神经网络的输入,给定点云p,其中观测视角处点(x,y)的深度为d,则该点在深度图像中的像素值c可表示为:
[0049][0050]
其中,f和n被设置为合适值使得计算得到的深度图像对比充分,通过计算获得了点云的深度图像数据;
[0051]
步骤3.3.2,将步骤3.3.1中求出的深度图像x1和x2作为卷积神经网络模型的输入,进行迭代配准,直至配准误差小于设定的阈值,得到最优的配准参数,完成左侧人脸和正面人脸点云的配准拼接;
[0052]
步骤3.3.3,将步骤3.3.2得到的左侧人脸和正面人脸拼接好的点云与右侧人脸点云进行配准拼接,最终得到完整的人脸点云。
[0053]
步骤4具体为:
[0054]
步骤4.1,将点云数据进行八叉树分割,便于在函数的三维空间内对泊松方程问题进行分割离散化,使用八叉树结构储存点集,根据采样点集的位置定义八叉树,然后细分八叉树使每个采样点都落在深度为d的叶节点,则将八叉树的每个节点用函数f
q
来定义:
[0055][0056]
其中,q
c
和q
w
分别为节点q的中心和宽度,同时,为了将节点函数f
q
能与空间向量场构建起对应关系,则可通过基函数f来进行说明,则有:
[0057][0058]
选用一个方差近似为2-d
的高斯滤波器,实现点云数据的平均采样;
[0059]
步骤4.2,创建向量场来逼近指示函数梯度算子,算法选用三次线性插值法将八个近邻点进行分配,以减少采样点与树节点位置的误差,则指示函数梯度算子与向量场之间的关系可表示为:
[0060][0061]
其中,q为三维点云数据集,s是点q的邻近域点集,nb
d
(q)是当前点q的八个邻近节点,n
q
为点q的法向量,是线性插值权重;
[0062]
步骤4.3,定义向量场后,就可以进行求解泊松方程进而得到指示函数χ,采用拉普拉斯算子对其进行求解;
[0063]
步骤4.4,选取适合的等值面阈值来重构表面等值面阈值的选取可以采用三维点云数据采样点的坐标来估计指示函数χ,然后将估计的结果取均值,用其平均值进行等值面提取即:
[0064][0065]
步骤4.5,通过等值面的提取,然后将提取的等值面进行拼接,完成三维人脸模型的曲面重建。
[0066]
本发明的有益效果是:本发明一种基于卷积神经网络的人脸三维建模的方法,使用了基于激光散斑的kinect相机对人脸进行点云信息采集,不受环境光和被测物体表面纹理复杂度的影响,点云密度高,三维建模效果好。采用直通滤波完成目标物点云和其他点云的分割,通过快速双边滤波快速高效的完成点云数据的除噪。采用基于卷积神经网络的点云配准方法进行点云的配准拼接,相较于传统点云配准方法,计算量大大降低,配准效率明显提升,能够应对实时性要求较高的场合。
附图说明
[0067]
图1是本发明一种基于卷积神经网络的三维人脸建模方法的基于cnn的点云配准模型;
[0068]
图2是本发明一种基于卷积神经网络的三维人脸建模方法的泊松曲面重建流程图;
具体实施方式
[0069]
下面结合附图和具体实施方式对本发明进行详细说明。
[0070]
本发明一种基于卷积神经网络的三维人脸建模方法,具体按照如下步骤实施:
[0071]
步骤1,使用kinect相机分别从人脸的左侧、右侧和正前方采集人脸点云信息;
[0072]
步骤2,对步骤1采集到的人脸点云信息进行预处理,分割出目标物体点云,并对点云进行除噪和平滑;
[0073]
步骤2具体为:
[0074]
步骤2.1,对z轴方向上的维度设置一定的深度距离阈值,将目标物点云与其他距离较远的无用信息分割出来,具体表达式如下:
[0075][0076]
d(z)为分割后获取的点云数据,若点在最大阈值depth_max和最小阈值depth_min之间,就分割出来,若在范围之外就舍弃掉;
[0077]
步骤2.2,将步骤2.1分割出来的点云通过快速双边滤波法,进行高斯线性卷积和双线性插值,对点云数据进行除噪和平滑;
[0078]
步骤2.2具体如下:
[0079]
步骤2.2.1,对步骤2.1分割出来的每一个点云数据点p=(x,y,z),求出它的m个邻域点q
i
(x
i
,y
i
,z
i
)及其深度值d
i
(u,v);
[0080]
步骤2.2.2,计算光顺滤波函数g
s
和g
r
以及三维高斯核函数g,计算公式如下:
[0081][0082][0083]
g=g
s
*g
r
ꢀꢀꢀ
(4)
[0084]
其中,g
s
为空间邻近度因子,g
r
为深度相似性因子,σ
s
和σ
r
分别为空间邻域标准差和深度标准差;
[0085]
步骤2.2.3,计算每个单位区域像素深度值之和wd和w,计算公式如下:
[0086][0087][0088]
其中,d
i
(u,v)为点p=(x,y,z)邻域的深度值,邻域三维空间合集为r;
[0089]
步骤2.2.4,将wd和w分别与三维高斯核函数g进行高斯线性卷积,并进行双线性插值,具体公式如下:
[0090][0091]
其中,interpolate为插值函数,求出滤波后的点云数据d
b
(x,y),实现三维点云数据的平滑;
[0092]
步骤3,采用基于卷积神经网络的配准方法,得到三个方向的平移配准参数和三个方向的旋转配准参数,实现点云的配准拼接;
[0093]
步骤3具体为:
[0094]
步骤3.1,构造卷积神经网络的点云配准模型;
[0095]
步骤3.1具体为;
[0096]
步骤3.1.1,构造网络结构;
[0097]
利用卷积神经网络计算点云深度图像的特征,再利用得到的特征计算配准参数。模型采用n组并联的卷积神经网络相互独立地提取深度图像的n种不同的特征,每种特征都是128维的向量。将深度图像x1的第一种特征向量x
11
与深度图像x2的第一种特征向量相减,得到第一种特征的差分向量d1。将n种不同的差分向量d1,d2,...,d
n
并联为配准的整体差分向量。整体差分向量经过以relu为激活函数的全连接层f2得到256维向量,最后经过全连接层f3得到6种不同的配置参数,通过对整个网络进行端到端的训练,网络各部分得以协调,使得在各种配准参数范围内网络均能有效配准,卷积神经网络的点云匹配模型,如图1所示;
[0098]
步骤3.1.2,构造网络模型的迭代点云配准方法;
[0099]
由于点云空间位置变换的复杂性,难以有效地对配准参数进行一次性地精确估计。因此采用迭代地进行点云配准,将待配准的参数分为三组,即t
x
,t
y
,t
θ
,t
α
,t
β
,t
z
。先配准容易估计的配准参数,再配准较难估计的配准参数,使得配准过程容易进行。首先将x1和x2输入配准网络模型得到配准参数t
x
,t
y
,t
θ
,利用得到的配准参数对深度图像x1进行更新。然后将x2和更新过的x1再次输入配准网络模型得到配准参数t
α
,t
β
,利用t
α
,t
β
对深度图像x1再一次更新。最后再次将x2和更新过的x1输入配准网络得到配准参数t
z
,利用t
z
对x1再一次更新,得到经过一次迭代后更新的深度图像x1。重复迭代k次,k为常数,通常设置为10以内,使得最后迭代得到的配准参数能够让x1和x2的配准误差小于设定的阈值;
[0100]
步骤3.2,用训练数据训练卷积神经网络的点云配准模型;
[0101]
步骤3.2具体为;
[0102]
步骤3.2.1,采用普林斯顿形状数据集中的约1000个模型作为训练数据。首先利用opengl的深度测试功能拍摄三维模型的深度图像x1,然后按一定的配准参数y
i
旋转模型,并拍摄变换之后的深度图像x2,将x1、x2作为配准网络的输入并将y
i
作为训练目标;
[0103]
步骤3.2.2,按照步骤3.1.2的方法流程训练整个模型;
[0104]
整个网络模型的训练优化目标是使估计配准参数与真实配准参数的均方损失最小,定义为:
[0105][0106]
其中,m为训练样本数,y
i
为第i组样本的真实配准参数,x
i
为第i组输入的深度图像对,θ为模型中待训练的参数。模型采用xavier方法初始化网络参数以提高网络的训练效率。训练采用随机梯度下降的方法进行参数优化,其中梯度更新的批大小设置为100,梯度更新的动量为m=0.9,权值衰减率d=0.0001,对于参数θ的更新公式可表示为:
[0107][0108]
其中,i为梯度更新的次数,μ为梯度的动量,η
i
是第i次梯度更新时的学习率,是基于反向传播算法计算得到的目标函数对i时刻网络参数的偏导数。学习率η
i
随着训练而衰减,以使网络训练稳定;
[0109]
步骤3.3,将步骤2得到的点云数据转化为深度图像数据,运用训练好的卷积神经网络的点云配准模型进行配准拼接;
[0110]
步骤3.3具体为;
[0111]
步骤3.3.1,计算左侧人脸点云和正面人脸点云的深度图像x1和x2,将深度图像作为卷积神经网络的输入。给定点云p,其中观测视角处点(x,y)的深度为d,则该点在深度图像中的像素值c可表示为:
[0112][0113]
其中,f和n被设置为合适值使得计算得到的深度图像对比充分,通过计算获得了点云的深度图像数据;
[0114]
步骤3.3.2,将步骤3.3.1中求出的深度图像x1和x2作为卷积神经网络模型的输入,进行迭代配准,直至配准误差小于设定的阈值,得到最优的配准参数,完成左侧人脸和正面人脸点云的配准拼接;
[0115]
步骤3.3.3,按照步骤3.3.1和步骤3.3.2的方法,将步骤3.3.2得到的左侧人脸和正面人脸拼接好的点云与右侧人脸点云进行配准拼接。最终得到完整的人脸点云;
[0116]
步骤4,利用泊松曲面重建法,对点云进行三维重建;
[0117]
步骤4的流程图,如图2所示,具体为:
[0118]
步骤4.1,将点云数据进行八叉树分割,便于在函数的三维空间内对泊松方程问题进行分割离散化。使用八叉树结构储存点集,根据采样点集的位置定义八叉树,然后细分八叉树使每个采样点都落在深度为d的叶节点,则将八叉树的每个节点用函数f
q
来定义:
[0119][0120]
其中,q
c
和q
w
分别为节点q的中心和宽度。同时,为了将节点函数f
q
能与空间向量场构建起对应关系,则可通过基函数f来进行说明,则有:
[0121][0122]
这里选用一个方差近似为2-d
的高斯滤波器,实现点云数据的平均采样;
[0123]
步骤4.2,创建向量场来逼近指示函数梯度算子,算法选用三次线性插值法将八个近邻点进行分配,以减少采样点与树节点位置的误差,则指示函数梯度算子与向量场之间的关系可表示为:
[0124][0125]
其中,q为三维点云数据集,s是点q的邻近域点集,nb
d
(q)是当前点q的八个邻近节点,n
q
为点q的法向量,是线性插值权重;
[0126]
步骤4.3,定义向量场后,就可以进行求解泊松方程进而得到指示函数χ,采用拉普拉斯算子对其进行求解;
[0127]
步骤4.4,选取适合的等值面阈值来重构表面等值面阈值的选取可以采用三维点云数据采样点的坐标来估计指示函数χ,然后将估计的结果取均值,用其平均值进行等值面提取即:
[0128][0129]
步骤4.5,通过等值面的提取,然后将提取的等值面进行拼接,完成三维人脸模型的曲面重建。
[0130]
本发明是一种基于卷积神经网络的三维人脸建模方法,采用基于激光散斑的kinect相机进行点云信息的采集,不受环境光和被测物体表面纹理复杂度的影响,操作简单,生成的点云密度大、精度高,三维建模效果好。通过直通滤波和快速双边滤波对点云信息进行预处理,采用基于卷积神经网络的点云配准方法进行点云的配准和拼接,相比较于传统的先进行粗配准再进行精配准的方法具有计算量小、配准效率高的优点。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1