一种基于分治网格的空间大数据算法的制作方法
[0001]
本发明涉及分布式空间计算技术领域,具体为一种基于分治网格的空间大数据算法。
背景技术:
[0002]
大数据(big data),it行业术语,是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产,在维克托
·
迈尔-舍恩伯格及肯尼斯
·
库克耶编写的《大数据时代》中大数据指不用随机分析法(抽样调查)这样捷径,而采用所有数据进行分析处理;但是随着移动设备的普及,空间数据规模越来越大,出现了井喷式的大发展,如何能够实现tb级空间数据的快速分析,是当前海量空间数据分析面临的重要问题。
技术实现要素:
[0003]
本发明提供一种基于分治网格的空间大数据算法,可以有效解决上述背景技术中提出随着移动设备的普及,空间数据规模越来越大,出现了井喷式的大发展,如何能够实现tb级空间数据的快速分析,是当前海量空间数据分析面临的重要问题。
[0004]
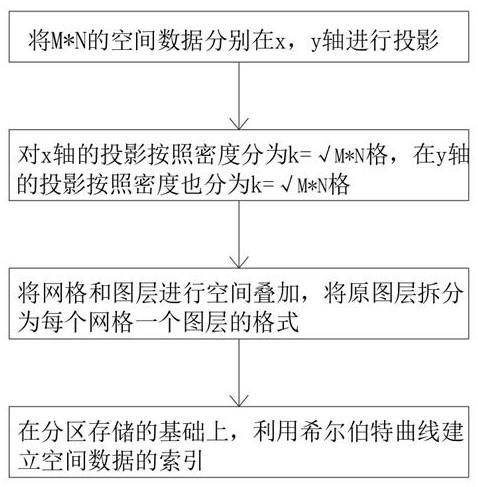
为实现上述目的,本发明提供如下技术方案:一种基于分治网格的空间大数据算法,包括分治网格划分,首先将需要计算的空间数据进行预处理,并且进行降维投影,根据投影的密度分布进行分治可变网格划分;所述分治网格划分具体步骤如下:步骤1:将mn的空间数据分别在x,y轴进行投影;步骤2:对x轴的投影按照密度分为k=格,在y轴的投影按照密度也分为k=格;步骤3:将网格和图层进行空间叠加,将原图层拆分为每个网格一个图层的格式;步骤4:在分区存储的基础上,利用希尔伯特曲线建立空间数据的索引。
[0005]
根据上述技术方案,所述密度分布可变网格划分,对于x轴数据,采用快速排序法排序后的数据可表示为d = { q1,q2,
…
,qn},将d等深划分为k 个区间段,则各区间段内的数据点个数均为[n/k],此时第i个区间段ii = q([n/k]*i) - q([n/k]*(i-1) +1) 。
[0006]
根据上述技术方案,将不同图层和网格的叠加分析任务并行化,利用多个节点的计算能力并行处理,称为分配调度计算;在集群化处理方面,利用spark将整个的计算任务分解为每个网格的计算任务在集群上分别执行,最终通过数据汇总任务将各个子任务的结果进行汇总形成最终结果;通过分布式的分配调度计算可以突破以往单机计算能力不足的缺陷。
[0007]
根据上述技术方案,所述spark分布式桉网格进行计算,按照网格将数据解析处理,提取出计算需要的数据,然后将数据封装为任务,提交到 kafka 的消费者模块,传输到
数据处理程序当中;spark 数据处理模块接收到 kafka 发出的任务执行命令,spark 根据任务选择计算程序进行计算,并且渲染计算结果。
[0008]
与现有技术相比,本发明的有益效果:本发明结构科学合理,使用安全方便,本发明集实现的分治网格分布式核心算法,可以大幅提升大规模数据下的空间计算性能;考虑空间数据海量,多图层叠加分析计算需求普遍,传统的单机计算模式难以满足时效性要求的情况,基于“分而治之”理念的空间数据并行化分析技术,可以有效提升分析速度;利用集群处理技术,对需要进行分析的空间图层,按照各个分治网格进行分配调度,利用多台计算资源进行并行计算,之后进行汇总,形成统一的结果。
附图说明
[0009]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
[0010]
在附图中:图1是本发明的步骤流程结构示意图;图2是本发明的希尔伯特曲线的空间填充曲线结构示意图。
具体实施方式
[0011]
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
[0012]
实施例:如图1所示,本发明提供技术方案,一种基于分治网格的空间大数据算法,包括分治网格划分,首先将需要计算的空间数据进行预处理,并且进行降维投影,根据投影的密度分布进行分治可变网格划分;分治网格划分具体步骤如下:步骤1:将mn的空间数据分别在x,y轴进行投影;步骤2:对x轴的投影按照密度分为k=格,在y轴的投影按照密度也分为k=格;步骤3:将网格和图层进行空间叠加,将原图层拆分为每个网格一个图层的格式;步骤4:在分区存储的基础上,利用希尔伯特曲线建立空间数据的索引。
[0013]
根据上述技术方案,密度分布可变网格划分,对于x轴数据,采用快速排序法排序后的数据可表示为d = { q1,q2,
…
,qn},将d等深划分为k 个区间段,则各区间段内的数据点个数均为[n/k],此时第i个区间段ii = q([n/k]*i) - q([n/k]*(i-1) +1) 。
[0014]
如图2所示:根据上述技术方案,希尔伯特曲线索引,是利用希尔伯特曲线来构建网格索引,通过这样的索引可以快速的进行查询空间点、线、面的所属网格位置,希尔伯特曲线是一种能填充满一个平面正方形的分形曲线,利用希尔伯特曲线索引,可以有效的进行数据降维,并且具有稳定和连续的特性。
[0015]
根据上述技术方案,将不同图层和网格的叠加分析任务并行化,利用多个节点的计算能力并行处理,称为分配调度计算;
在集群化处理方面,利用spark将整个的计算任务分解为每个网格的计算任务在集群上分别执行,最终通过数据汇总任务将各个子任务的结果进行汇总形成最终结果,通过分布式的分配调度计算可以突破以往单机计算能力不足的缺陷。
[0016]
在集群化处理方面,利用spark将整个的计算任务分解为每个网格的计算任务在集群上分别执行,最终通过数据汇总任务将各个子任务的结果进行汇总形成最终结果;通过分布式的分配调度计算可以突破以往单机计算能力不足的缺陷。
[0017]
根据上述技术方案,spark分布式桉网格进行计算,按照网格将数据解析处理,提取出计算需要的数据,然后将数据封装为任务,提交到 kafka 的消费者模块,传输到数据处理程序当中;spark 数据处理模块接收到 kafka 发出的任务执行命令,spark 根据任务选择计算程序进行计算,并且渲染计算结果。
[0018]
根据上述技术方案,spark 是一个用来实现快速而通用地集群计算的平台,spark 通过弹性分布式数据集(rdd)提供了丰富的的计算模式,rdd的重要属性,首先rdd代表数据集合,是对数据的抽象模型;其次,获得rdd有两种途径,可以通过封装文件系统上的数据创建,或者通过转换rdd的得到新的rdd,通过将每个网格的数据通过pairrdd来封装,网格的索引标识作为pairrdd的键值对的键,这样就保证了相同网格的数据存储在集群相同的节点上,通过partitionby()控制rdd的分区数量,也就能控制任务的并行计算,使用两个stage,第一个stage负责数据的读取和预处理;第二个stage完成空间分析计算并存储和渲染结果。
[0019]
与现有技术相比,本发明的有益效果:本发明结构科学合理,使用安全方便,本发明集实现的分治网格分布式核心算法,可以大幅提升大规模数据下的空间计算性能;考虑空间数据海量,多图层叠加分析计算需求普遍,传统的单机计算模式难以满足时效性要求的情况,基于“分而治之”理念的空间数据并行化分析技术,可以有效提升分析速度;利用集群处理技术,对需要进行分析的空间图层,按照各个分治网格进行分配调度,利用多台计算资源进行并行计算,之后进行汇总,形成统一的结果。
[0020]
最后应说明的是:以上所述仅为本发明的优选实例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1