一种口型纠正方法及一种口型纠正系统与流程
[0001]
本发明涉及一种口型纠正方法和一种口型纠正系统。
背景技术:
[0002]
外语学习中,掌握正确的发音非常重要。对于自主学习工具,如何使工具识别并纠正学习者的发音,则是重要的功能之一。
[0003]
目前市面上的自主学习工具,在这一功能上有两种形式:一是被动型,提供口形图,让学习者模仿图中口型进行发音,但这种形式无法对学习者的错误理解进行纠正;另一种是主动型,通过录音比对学习者的发音来主动提出错误,由于具备这样的反馈功能,是学习者可以观察到错误,及时更正。
[0004]
然而,录音效果往往受客观因素影响,导致比对时发生错判,且录音不能直接识别口型,对于不同口型发出的近似音的判断非常不准确。
[0005]
因此,除了录音,现有一些方案提出录音的同时对照口型。通过口型和语音的双重比对,可能避免近似音的错判,增加判断的准确性。
[0006]
但是,现有方案对口型的识别准确度还有所欠缺。
技术实现要素:
[0007]
为了解决上述技术问题,本发明提出了一种口型纠正方法,包括如下步骤:
[0008]
将预置标准读音、预置标准口形图像、预置传感数据、传感允许误差值、口型重合阈值和语音重合阈值储存在预置模块中,
[0009]
通过传感模块实时获取人脸距离信息,并将获取的人脸距离信息实时传输至预置模块,
[0010]
通过预置模块将人脸距离信息与预置传感数据实时做比对,当且仅当两者差值的绝对值小于或等于传感允许误差值时,进行后续步骤,
[0011]
通过摄像模块实时获取人脸口型信息及语音信息,
[0012]
将人脸口型信息实时传输至图像处理模块,同时将语音信息实时传输至语音处理模块,
[0013]
通过图像处理模块实时将人脸口型信息简化为灰度图并识别出口型图像实时传输至预置模块,同时通过语音处理模块实时将语音信息切分提取各单元发音实时传输至预置模块,
[0014]
通过预置模块将口形图像与预置标准口型图像实时做比对,并同时将各单元发音与预置标准读音实时做比对,
[0015]
当且仅当口型重合度大于口型重合阈值,且语音重合度大于语音重合阈值时,视为符合标准,否则通过提示模块实时发送错误警示信息。
[0016]
优选地,当且仅当口型重合度大于口型重合阈值,且语音重合度大于语音重合阈值时,视为符合标准。
[0017]
优选地,通过预置模块将人脸距离信息与预置传感数据实时做比对,当且仅当两者差值的绝对值小于或等于传感允许误差值时,进行后续步骤,否则将通过提示模块发送未工作通知。
[0018]
优选地,预置传感数据的取值范围为10~40cm。
[0019]
优选地,传感允许误差值的取值范围为5~15cm。
[0020]
另一方面,本发明还提出了一种口型纠正系统,由预置模块、传感模块、摄像模块、图像处理模块、语音处理模块和提示模块组成,
[0021]
传感模块用于实时获取人脸距离信息并实时传输至预置模块,
[0022]
摄像模块用于实时获取人脸口型信息和语音信息并实时传输至图像处理模块和语音处理模块,
[0023]
图像处理模块用于实时将人脸口型信息简化为灰度图并识别出口型图像,实时传输至预置模块,
[0024]
语音处理模块用于实时将语音信息切分提取各单元发音并实时传输至预置模块,
[0025]
预置模块用于存储预置标准读音、预置标准口形图像、预置传感数据、传感允许误差值、口型重合阈值和语音重合阈值,并用于将同类数据做实时比对,
[0026]
提示模块用于发出告知信息。
[0027]
有益效果在于,这种口型纠正方法及其系统,通过传感模块和设定传感允许误差值,将使用者与教学工具之间的距离进行了充分限定,以确保后续的口型对比结果更具有参考性,避免了距离过大时摄像所获取口型可能与实际不符的问题。
附图说明
[0028]
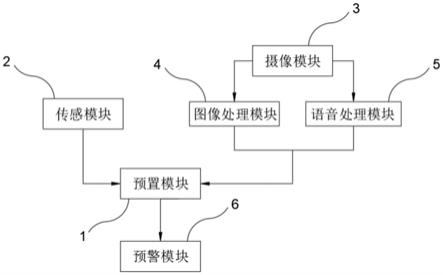
图1为本发明的口型纠正系统的整体示意图。
具体实施方式
[0029]
为详细说明本发明的技术内容、所实现目的及效果,以下结合实施方式并配合附图予以说明。
[0030]
本发明最关键的构思在于:由于距离问题导致摄像获取的口型图像可能不准确,距离过远或过近时所摄口型图像可能与实际口型有出入,这样后续的口型比对就有可能造成误判,因此通过传感距离限制使用者与教学设备之间的距离,该距离不易过远或过近,以确保口型识别的准确性,减少误判情况发生。
[0031]
本发明提出了一种口型纠正方法,包括如下步骤:
[0032]
s1、将预置标准读音、预置标准口形图像、预置传感数据、传感允许误差值、口型重合阈值和语音重合阈值储存在预置模块中。
[0033]
预置标准读音和预置标准口形图像均可参照选用现有教科书标准。预置传感数据是一个关于距离的数值,以该距离作为一个标准位置,传感允许误差值可理解相当于在该标准位置的可允许误差的距离远近范围。
[0034]
s2、通过传感模块实时获取人脸距离信息,并将获取的人脸距离信息实时传输至预置模块。
[0035]
本发明主要用于自主的语言学习工具,通常为点读笔等。因此本方案的步骤基本
都是实时进行,以便学习者出现不标准情况时,学习工具能及时提醒到位。
[0036]
s3、通过预置模块将人脸距离信息与预置传感数据实时做比对,当且仅当两者差值的绝对值小于或等于传感允许误差值时,进行后续步骤。
[0037]
如上所述,可理解预置传感数是锚定了一个标准距离位置,当学习者人脸处在该标准距离范围内时,后续步骤中口型的识别才能尽可能地保证准确。因此,检测人脸距离与预置数值做比对时,要求小于或等于两者差值的绝对值,相当于学习者在实际学习中被要求人脸距离学习工具的距离始终在预置的标准距离位置附近,一旦超出标准距离位置太多,则口型识别可能不准确,那么也没必要继续进行后续步骤了。如此一来,该步骤一方面确保了纠正口型的有效性,另一方面也可降低应用此方法的学习工具的实际功耗。
[0038]
另外,视学习工具的不同,预置传感数据的取值范围不同,同时考虑到摄像清晰度问题、收音问题、学习者年龄、学习者姿势合理性问题等,合理取值范围可选择在10~40cm之间。此外,传感允许误差值的合理取值范围可选择在5~15cm。
[0039]
如当应用在点读笔时,可将预置传感数据设定为20cm,并将传感允许误差值设定为10cm,则实际可允许的人脸距离在10~30cm之间,这样无论是小孩子或是大人,都可基本确保使用坐姿的常态下即可使用点读笔进行自主学习。且经验证,为使自主学习有效,学习者在注意维持规定距离时,事实上同时纠正了自身的坐姿,因为学习者过度弯腰头太低或歪歪扭扭有其他不正确姿势时,人脸距离都无法维持在规定距离内。因此,可以理解,通过本发明的方法设定合理的取值,除了提高口型识别准确度,还隐形地帮助学习者纠正了学习姿势。
[0040]
s4、通过摄像模块实时获取人脸口型信息及语音信息。
[0041]
s5、将人脸口型信息实时传输至图像处理模块,同时将语音信息实时传输至语音处理模块,
[0042]
s6、通过图像处理模块实时将人脸口型信息简化为灰度图并识别出口型图像实时传输至预置模块,同时通过语音处理模块实时将语音信息切分提取各单元发音实时传输至预置模块,
[0043]
s7、通过预置模块将口形图像与预置标准口型图像实时做比对,并同时将各单元发音与预置标准读音实时做比对,
[0044]
s8、当且仅当口型重合度大于口型重合阈值,且语音重合度大于语音重合阈值时,视为符合标准,否则通过提示模块实时发送错误警示信息。
[0045]
口型和语音的识别对比属于现有技术,此处不再赘述。本方案与现有技术的主要区别在于增加对人脸距离的限制,并在此基础上,在口型识别中限定为灰度图的识别处理。在以点读笔为市场主流的现状下,对自主学习工具做规格较高的设计将造成成本大幅上涨,并不符合市场规律。自主学习工具的口型纠正功能的核心在于确保实时快速处理的前提下尽可能准确,快速处理与精确识别存在一定矛盾,因此需要合理取舍。本方案选择在口型识别中做一定的简化处理,如此就可以在保证实时快速的前提下有效降本,并将节约的成本覆盖到距离传感的功能中。因此,应用本方案的自主学习工具具有更准确的判断,还能帮助学习者纠正学习资质。且当与口型识别性能相一致的自主学习工具相比时,应用本方案的产品具有更好的识别准确性,价格还可持平,属于全面进步的迭代新产品。
[0046]
警示信息一般只需以亮灯表达即可。本方案限定仅在不符合标准时显示警示信
息,可减少提示模块的工作量,从而提高寿命节省成本。此外,经验证,仅在错误时有提示,相比标准范围内持续提示,可更大程度地降低对学习者的影响。口型纠正是语言学习中的重要一环,但基础是语言学习本身,因此自主学习工作在提供辅助纠正功能时,更应考虑的是新增功能对学习者的影响,如分散注意力、影响积极性、功利引导等。因此,本方案限定警示信息只在不符合标准时显示,不仅可提高寿命节省成本,也改善了自主学习体验。
[0047]
进一步地,当且仅当口型重合度大于口型重合阈值,且语音重合度大于语音重合阈值时,视为符合标准。
[0048]
口型比对和语音比对均为现有技术,其中口型重合度和语音重合度也均有现有技术说明,因此此处不再赘述。如前述,本方案中与现有技术的主要区别在于,选择在口型识别中做一定的简化处理,如此就可以在保证实时快速的前提下有效降本,并将节约的成本覆盖到距离传感的功能中。因此,此处限定为两者均符合时,无需单独对口型和语音做解释,可进一步降本。当然理论上,口型不正确时,发出的口音一定会有所差异。
[0049]
进一步地,通过预置模块将人脸距离信息与预置传感数据实时做比对,当且仅当两者差值的绝对值小于或等于传感允许误差值时,进行后续步骤,否则将通过提示模块发送未工作通知。
[0050]
该功能主要用于告知学习者,应用本方案的学习工具未启动口型纠正功能。因为如果只有错误提醒而没有未工作提醒的话,学习者无法区分现在是距离不正确导致的错误,还是口型不正确导致的错误。
[0051]
本发明还提出了一种口型纠正系统,如图1,由预置模块1、传感模块2、摄像模块3、图像处理模块4、语音处理模块5和提示模块6组成,
[0052]
传感模块2用于实时获取人脸距离信息并实时传输至预置模块1,
[0053]
摄像模块3用于实时获取人脸口型信息和语音信息并实时传输至图像处理模块4和语音处理模块5,
[0054]
图像处理模块4用于实时将人脸口型信息简化为灰度图并识别出口型图像,实时传输至预置模块1,
[0055]
语音处理模块5用于实时将语音信息切分提取各单元发音并实时传输至预置模块1,
[0056]
预置模块1用于存储预置标准读音、预置标准口形图像、预置传感数据、传感允许误差值、口型重合阈值和语音重合阈值,并用于将同类数据做实时比对,
[0057]
提示模块6用于发出告知信息。
[0058]
综上,本发明的这种口型纠正方法及其系统,通过传感模块2和设定传感允许误差值,将使用者与教学工具之间的距离进行了充分限定,以确保后续的口型对比结果更具有参考性,避免了距离过大时摄像所获取口型可能与实际不符的问题。
[0059]
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1