一种成品卷烟物流调度方法与流程
本发明属于物流领域,更具体的说涉及一种成品卷烟物流调度方法。
背景技术:
在我国烟草行业现产业结构下,卷烟工业企业的客户是市级烟草商业公司,由于烟草公司是按照地级市行政区划设置,每一个地级市拥有一个烟草公司,因此卷烟工业企业配送主要是沿高速公路或者国道的干线运输,同时,考虑到调度时点和实际运输发生时点间隔较长,故在调度时将路网简化为时序静态的、点与点之间有且仅有一条路径的有向图,不考虑多路径选择及拥堵、过路费高低等实际情况。工业企业一般在省级行政区划内拥有若干个发货点,且发货点间拥有不完全相同的库存结构。由于卷烟运输实行法定准运证制度,即每一个客户订单都必须对应一个由行政管理部门签发的有时效的准运证,订单必须在准运证有效期内完成交付,同时,该制度要求订单不能越库装运,当发货点库存结构与订单需求不匹配时,可以采用向中心库转储实现库存结构调整的方式,实现需求和库存的匹配,并且订单及订单对应的准运证和承运车辆的关系只能是“多对一”,即一辆货车可以承运总和不超过其装载量上限、不低于其装载量下限的多个订单,每一个订单只能有一辆承运车辆,不能同一订单分车装运。
技术实现要素:
本发明设计某一配送调度周期内,工业企业根据客户下达的订单信息,综合考虑运输路线、库存结构、车辆装载量、发货点作业能力,以及由订单要求到货日期、准运证时限组成的时间窗口、订单需求库存结构,合理组拼订单并调配承运车辆,确定发货点和发货日期,从而实现时间窗条件下的最低成本的运输配送。
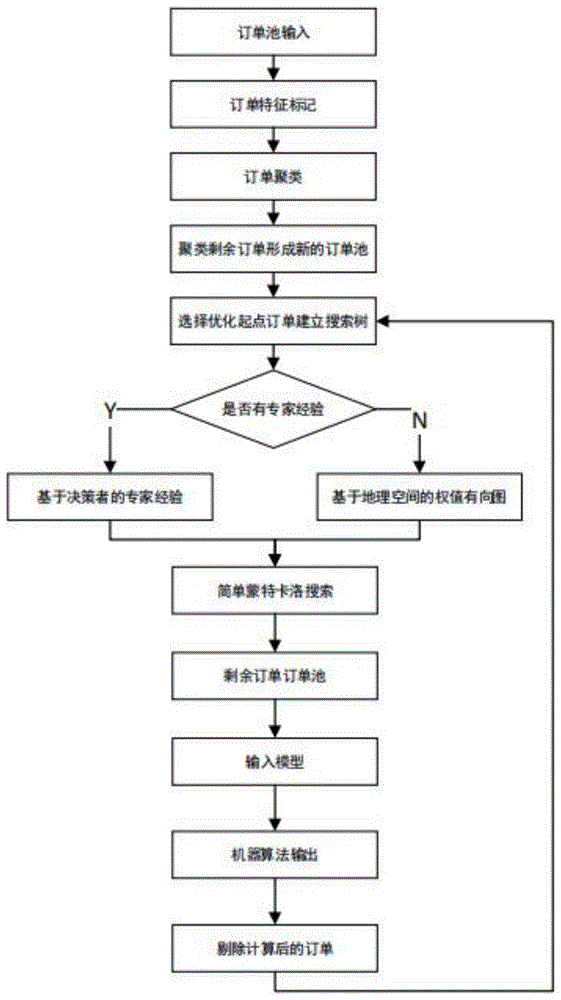
为了实现上述目的,本发明是采用以下技术方案实现的:步骤1,模型构建,构建卷烟物流调度模型;步骤2,算法设计,通过种基于机器学习的算法,首先对原问题按照一定的业务规则进行凝聚聚类,通过将历史拼车订单数据作为样本,输入算法作为原始知识,利用一个基于算法原始知识(历史调度数据)的专家策略函数和一个基于地理空间有向图的机器策略函数,采用蒙特卡洛搜索建立搜索树,最后建立一个由业务规则组成的调度优化评价函数来评价当前调度阶段结果优劣,实现基于机器算法组拼结果的自动推荐。
优选的,所述的步骤1模型构建,a.在决策周期p内,有m个客户向工业企业下单r个订单,订单在销的t个规格的成品卷烟,设第m个客户下单的r歌订单为
优选的,所述的步骤1模型构建,b.用ns表示发货点,i∈ns,第i个发货点出库能力上限为hi;用nc表示到货点,到货点结合定义为nc={uj|j∈m};定义网络为g=(n,a),其中n=ns∪nc,a=n×n,网络空间关系用基于地理路网的权值有向图表示。
优选的,所述的步骤1模型构建,c.定义sitk在决策周期p初始时,发货点i∈ns库存的批次为k∈k的规格t∈t的数量,发货点的库存结构表示为规格向eitkt=(ei1k,ei2k,…,eitk)及数量向量qitkt=(qi1k,qi2k,…,qitk)的组合,qitk为发货点i库存批次为k的规格t的库存数量,如果库存不为零,则eitk=1,否则等于eitk=0,第i个发货点的库存总数
优选的,步骤2,算法涉及,包括a.订单聚类,b.基于策略函数的待决策子集优化;c.装载量规则;d.时间窗规则。
优选的,所述的基于策略函数的待决策子集优化,首先根据初始节点订单r0的客户信息,订单容量、品规、发货点等关键特征从历史调度经验中,抽取关键特征满足阈值与初始节点有过历史组合的订单组成历史订单集r0history,求取待决策订单集r0orginal与历史订单集r0history的交集r0result=r0history∩r0orginal,订单集r0和订单集r0result就组成了一颗二级搜索树。
优选的,所述的装载量规则的核心是车辆满载率尽可能趋于100%,故基于初始节点订单r0的订单数量可以建立关系
本发明有益效果:
本发明设计某一配送调度周期内,工业企业根据客户下达的订单信息,综合考虑运输路线、库存结构、车辆装载量、发货点作业能力,以及由订单要求到货日期、准运证时限组成的时间窗口、订单需求库存结构,合理组拼订单并调配承运车辆,确定发货点和发货日期,从而实现时间窗条件下的最低成本的运输配送。
附图说明
图1为本发明算法流程图;
具体实施方式
为了便于本领域一般技术人员理解和实现本发明,现结合附图及具体实施例进一步描述本发明的技术方案。
步骤1,模型构建,构建卷烟物流调度模型;步骤2,算法设计,通过种基于机器学习的算法,首先对原问题按照一定的业务规则进行凝聚聚类,通过将历史拼车订单数据作为样本,输入算法作为原始知识,利用一个基于算法原始知识(历史调度数据)的专家策略函数和一个基于地理空间有向图的机器策略函数,采用蒙特卡洛搜索建立搜索树,最后建立一个由业务规则组成的调度优化评价函数来评价当前调度阶段结果优劣,实现基于机器算法组拼结果的自动推荐。在决策周期p内,有m个客户向工业企业下达了r个订单,订购在销的t个规格的成品卷烟,设第m个客户下达的r个订单为
用ns表示发货点,i∈ns,第i个发货点出库能力上限为hi;用nc表示到货点,到货点集合定义为nc={uj|j∈m};定义网络为g=(n,a),其中n=ns∪nc,a=n×n,网络空间关系用基于地理路网的权值有向图表示,如图1所示。其中arc(i,j)表示有向图中第i个节点到第j个节点的路径,路径权重wij表示两点间的运输距离(表一所示),τij表示两点间的运输时间,τij=wij/v,如果i∈ns,则τis表示装货时间,如果i∈nc,则τic表示卸货时间,。
定义sitk在决策周期p初始时,发货点i∈ns库存的批次为k∈k的规格t∈t的数量,发货点的库存结构表示为规格向量eitkt=(ei1k,ei2k,…,eitk)及数量向量qitkt=(qi1k,qi2k,…,qitk)的组合,qitk为发货点i库存批次为k的规格t的库存数量,如果库存不为零,则eitk=1,否则等于eitk=0,第i个发货点的库存总数
如果车辆在时间窗下限drm(order-9am)之前到达,要产生因等待卸货带来的承运机会损失成本c1;如果车辆在窗口上限drm(order-3pm)之后、准运证到期之前到达,将产生因延迟到货带来客户满意度损失成本c2;如果车辆准运证到期drm(vaild)之后到达,将产生因违规经营产生的成本c3=+∞。
b表示可调配车辆的集合,对于任意发货点i∈ns,bi表示发货点i可调配车辆的集合,gbll表示车辆b∈b的装载量下限(lowerlimit),gbsl表示装载量上限(superiorlimit)。
1)定义决策变量:
dbi=车辆b从i点出发的时间,
2)设定优化调度模型目标函数为总成本最小:
v=mincost(c),令c=u1+u2+u3,
其中:
u1u1c4,u1表示运输路程,
u2=u2c5,u2表示执行任务的车辆数量,c5表示每一车辆的使用成本。
u3表示时间成本,表示为:
3)约束条件:
步骤2,算法设计
具备完全信息的决策都可以通过穷举迭代,获得找到实现目标函数的最优解,对于当前的调度优化问题也是如此。但是在实际应用中,由业务实践抽象而来的数学规划模型求通常都会有大量的约束条件,如果直接通过解线性规划的方式求解,往往会随问题规模的增大出现可行解迭代进化较慢,甚至无法获得最优解的情况。因此,为了有效控制求解规模,设计提出一种基于机器学习的算法,首先对原问题按照一定的业务规则进行凝聚聚类,通过将2015年-2019年以来的历史拼车订单数据作为样本,输入算法作为原始知识,利用一个基于算法原始知识(历史调度数据)的专家策略函数和一个基于地理空间有向图的机器策略函数,采用蒙特卡洛搜索建立搜索树,最后建立一个由业务规则组成的调度优化评价函数来评价当前调度阶段结果优劣,实现基于机器算法组拼结果的自动推荐。然后再将每一次调度结果作为算法的新知识更新原始知识,实现机器算法的智能迭代。
1)订单聚类
基于实践中部分订单组合具备清晰的业务规则,例如同一个客户的订单如果满足规模运输量的同时满足时间窗和库存,那么这一类订单就可以直接输出调度结果,而无需继续通过模型进行求解。因此,在获取订单池后,首先利用订单数据中的关键特征,将特征转化为哑变量,然后使用无监督学习算法,对特征进行聚类,实现调度问题规模的“瘦身”。在待决策的订单池中,诸如客户信息、运达地、订单规格等关键特征绝大部分为字符串数据,故首先将字符串类型特征转化为哑变量,将订单池数据变为稀疏矩阵。对转化后的稀疏矩阵,使用凝聚聚类(agglomerativeclustering)对完成关键特征欧式空间化的订单进行聚类合并,将样本归入不同的簇。并自动添加了簇标签(cluster),从而实现将订单区分为已合并订单和待合并订单两类,并将已合并订单从待决策的订单池中剔除,直接输出调度结果,待合并订单形成新的待决策订单池,从而实现了调度问题规模的“瘦身”。
2)基于策略函数的待决策子集优化
经过聚类后的待决策子集是由一系列关键特征离散的订单组成,组合这些订单实现目标函数是调度决策的核心内容。显而易见,遍历所有可能的组合并评估目标函数值是获得最优解的最佳方式,但是这种遍历的深度和广度显然不可接受,为此,算法模拟人工在调度中通常采用的“按图索骥”的搜索方式,基于简单蒙特卡洛搜索,设计了一个包括两个部分的策略函数,用来控制决策空间搜索的深度和广度,从而实现待决策子集的进一步优化。
将待决策订单池r0orginal作为初始态s0,在订单池中选择距离发货点最远即max(wij)的一个订单r0,r0=r0orginal,作为初始节点并创建搜索树,搜索树的分支由历史调度经验和距离矩阵共同确定,赋予专家经验更高的优先级,因为历史调度结果是专家在多种客观约束下做出的现实选择,也更符合业务,当状态s0不具备专家经验时,以距离矩阵替代专家经验。在专家经验下,订单r0都会存在若干种专家历史调度决策的订单组合,记每一种组合出现的频p(a|s0,r0result)表示在当前状态s0下
首先根据初始节点订单r0的客户信息,订单容量、品规、发货点等关键特征从历史调度经验中,抽取关键特征满足阈值与初始节点有过历史组合的订单组成历史订单集r0history,求取待决策订单集
3)装载量规则由于成品卷烟物流是规模效益显著的经济活动,因此,所述的装载量规则的核心是车辆满载率尽可能趋于100%,故基于初始节点订单r0的订单数量可以建立关系
装载量计算表
4)时间规则
成品卷烟物流是具备时间窗的约束问题,因此,还必须对订单组合的时间窗协调程度进行评价。初始节点订单r0的时间窗
如果同时多个组合均满足两个规则,则根据p(a|s0,r0result)的大小决定组合的取舍。经过基于策略函数构建的搜索树决策后,将订单r0和与之组合的订单ri从待决策的订单池,
随着调度行动的数量不断增加,每一期调度决策可以使用的历史行动数据也会不断增加,专家策略空间的规模将逐步增大,当时间足够长时专家策略空间将逐步取代快速策略网络,并趋近于当前状态下的全部策略空间,即
实施例一、
算例采用的数据为某期内需完成调度的实际成品卷烟物流发运计划,包括100个客户的584个订单,合计待配送数量191574.68万支。算例准备基础数据包括决策期内的生产入库计划及库存数据、可用车辆数据、2016年-2019年历史调度拼单数据、准运证有效期数据、生产摆布数据、距离矩阵数据、运输里程数据、运输时间数据。采用本算法形成调度结果。如下表所示:
机器算法调度结果表
为了进一步验证机器算法的性能,就相同的待决策问题,基于同一计算平台,使用相同的基础数据,分别采用数学规划模型gurobi求解器直接求解的方法和冯子炎设计验证的用于解决带时间窗的vrp问题的遗传算法进行求解,然后综合比较实用车辆数及结构、运输里程、时间成本以及组合的质量。两种方法的调度结果,如下表所示:
用于比较的两种算法调度结果表
从下表结果对比表可以看出,相较于机器算法,规划求解器解线性规划的调度结果使用的车次数较少,呈现出明显的组合趋大的特点,即多点到货的组合车次占比较高,这样虽然能够减少运输里程和使用的车次数,但是会显著增加时间成本,特别的是,在机器算法中的时间成本主要来自于车辆提前到达客户产生的等待成本,而在解线性规划中时间成本主要来自于迟到的惩罚成本,这种结果对于业务实际而言可接受度较低。而使用遗传算法获得的调度结果总体性能与机器算法相当,但是较为突出的问题是组合结果不够合理,遗传算法使用的车辆数是三种方法中最少的,但是其所需行驶的里程却与机器算法相当,原因就在于订单组合与实际业务符合度较低,部分线路存在迂回,同时,遗传算法的调度结果产生的时间成本也是高于机器算法的用于比较的两种算法调度结果表
因此本发明设计的机器算法在节约运输里程和减少惩罚时间方面具备较好的性能,同时单车单点到货率较高,这是因为机器算法的核心策略来自于历史订单调度结果和里程阈值,使用的车辆数较多提高单点到货的比例更加符合成品卷烟物流调度实际业务。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的仅为本发明的优选例,并不用来限制本发明,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!