一种基于自适应置信度图卷积网络的步态识别方法与流程
[0001]
本发明涉及计算机视觉技术领域,具体地说是一种基于自适应置信度图卷积网络的步态识别方法。
背景技术:
[0002]
身份识别是计算机视觉领域的一个重要课题,在视频监控、社会安全领域中有着重要的作用。步态识别旨在通过一个人行走的模式来判断其身份,相比于其他身份识别算法,具有非接触、作用距离远等优点。步态识别算法主要分为两大类:基于外观的算法和基于模型的算法。
[0003]
基于外观的算法通常利用人体轮廓图像作为输入数据,这种数据可以在去除贴图的同时保留步态信息。早期的算法采用构建步态模板的方式,将图像序列融合为一幅模板图像再进行识别。近期基于深度学习的算法则使用卷积神经网络从步态模板或步态序列中提取步态特征再进行识别。基于外观的算法应用非常广泛,但其也易受外界因素的干扰,如人体外观的变化(衣物变化、携带等)、视角变化和行走速度等。
[0004]
基于模型的算法利用人体的结构和运动的先验来对步态进行建模,因此对外观、视角等干扰更加鲁棒。但早期的算法仅能在限制条件下建模,相比于基于外观的算法适用范围和准确率都较低。近年来,深度学习引起了计算机视觉界的广泛关注,人们已经将其应用于各种视觉任务,其中基于深度学习的姿态估计算法能够更准确地获取人体姿态信息,为基于模型的步态识别提供了新的思路。但由于姿态估计算法自身性能的限制,以及图像中遮挡、背景干扰、低分辨率等因素的干扰,通过这种方法所获得的姿态学习往往包含噪声。目前基于姿态的步态算法一方面没有对姿态数据中的噪声做针对性处理,影响了识别的准确率;另一方面没有利用姿态数据之间的联系,所提取的步态特征不够全面。
技术实现要素:
[0005]
本发明为克服现有技术的不足之处,提出一种基于自适应置信度图卷积网络的步态识别方法,以期利用自适应置信度图卷积网络从含有噪声的人体姿态关键点数据中提取有效的步态表示并减少姿态数据中噪声的影响,同时考虑到姿态关键点之间的联系,以提高步态识别的准确率,并改善现有基于外观的步态识别算法对外观变化敏感的缺点。
[0006]
本发明为达到上述发明目的,采用如下技术方案:
[0007]
本发明一种基于自适应置信度图卷积网络的步态识别方法的特点是按如下步骤进行:
[0008]
步骤1、使用姿态估计算法从原始视频数据集中提取人体姿态关键点,得到n个t帧的步态序列并进行标准化处理,得到标准化的姿态骨架数据集记为其中,表示第n个标准化后的姿态骨架序列,且表示第n个标准化后的姿态骨架序列
中第t帧姿态骨架;表示第t帧姿态骨架中姿态关键点对应的置信度;n=1,2,...,n,t=1,2,...,t;
[0009]
步骤2、建立自适应置信度图卷积网络模型,包括:一层输入模块、α层自适应置信度模块、β层时空特征融合模块和一层输出模块组成;
[0010]
所述输入模块由一层批归一化层实现;
[0011]
所述自适应置信度模块依次由一层自适应置信度图卷积层、一层归一化层、一层relu激活层和一层dropout层组成;
[0012]
所述时空特征融合模块依次由一层自适应图卷积层、一层归一化层、一层relu激活层、一层dropout层、一层卷积层、一层归一化层和一层relu激活层组成;
[0013]
所述输出模块由一层池化层和带有softmax函数的一层全连接层组成;
[0014]
步骤2.1、将所标准化的姿态骨架述数据集x中的姿态数据按照人体结构构图,将每个姿态关键点看作图的顶点集v,将姿态关键点之间的自然连接看作图的边集e,从而构成图数据记为g=(v,e);
[0015]
步骤2.2、将所述图数据g送入输入模块进行数据归一化处理,得到归一化后的图数据g
′
=(v
′
,e
′
),v
′
表示归一化后的顶点集,e
′
表示通过正则化后的邻接矩阵;
[0016]
步骤2.3、将所述归一化后的图数据g
′
和所标准化的姿态骨架数据集x中的置信度向量依次输入α层自适应置信度模块,按照预设的图卷积算子从图数据g
′
中提取特征,并利用置信度向量对所提取的特征加权;经过α层自适应置信度模块后得到空间步态特征序列其中,f
ts
表示空间特征序列f
s
中第t帧特征图;
[0017]
步骤2.4、将所述空间步态特征序列依次输入β层时空特征融合模块,利用图卷积算子从空间步态特征序列f
s
中进一步提取深层空间步态特征,并利用时序卷积算子从空间步态特征序列中提取时空步态特征;经过β层的时空特征融合模块后得到时空步态特征序列其中,f
tst
表示时空特征序列f
st
中第t帧特征图,t
′
表示经过所有时空特征融合模块后的时空特征序列的帧数;
[0018]
步骤2.5、将所述时空步态特征序列在时序上进行平均处理,以融合t
′
帧特征图;将融合后的特征图再在空间上进行平均处理,以融合所有姿态关键点的特征,从而得到最终的步态特征f;
[0019]
步骤2.6、将所述步态特征f送入输出模块,得到预测结果y;
[0020]
步骤3、根据步态特征f计算三元组损失,根据预测结果y计算交叉熵损失,并使用sgd更新自适应置信度图卷积网络模型的权重,并在损失值趋于稳定时完成训练,得到最优自适应置信度图卷积网络模型;
[0021]
步骤4、利用所述最优自适应置信度图卷积网络模型对待检索序列和检索库种所有序列提取步态特征,计算待检索特征和检索库种所有特征间的欧式距离,按照距离由小到大进行排序,从而得到检索结果。
[0022]
本发明所述的基于自适应置信度图卷积网络的步态识别方法的特点也在于,所述步骤2.3包括:
[0023]
步骤2.3.1、将每个自适应置信度图卷积层的输入记为令分别经过两个卷积算子后得到特征图和通过矩阵乘法计算和的积,并使用softmax函数对结果进行归一化,得到自适应矩阵a;
[0024]
步骤2.3.2、将置信度向量按列扩展为与所述邻接矩阵a尺寸一致的矩阵,记为置信度矩阵c;并生成一个同样尺寸的全0矩阵,作为自适应矩阵b;
[0025]
步骤2.3.3、将所述邻接矩阵e
′
、自适应矩阵a、自适应矩阵b相加后与置信度矩阵c相乘计算哈达玛积得到最终的自适应置信度邻接矩阵e
″
,将所述最终的自适应置信度邻接矩阵e
″
与输入一起通过一个图卷积算子后得到自适应置信度图卷积层中自适应分支的输出
[0026]
步骤2.3.4、将所述输入与置信度向量相乘加权后再通过一个卷积算子得到自适应置信度图卷积层中置信度分支的输出
[0027]
步骤2.3.5、将所述自适应分支的输出与置信度分支的输出相加后得到自适应置信度图卷积层的输出再经过所述一层归一化层、一层relu激活层和一层dropout层得到自适应置信度图卷积模块的中间结果
[0028]
步骤2.3.6、若所述输入尺寸与中间结果不相等,则令输入通过一层卷积层后使其与中间结果尺寸相等,并与中间结果相加得到自适应置信度图卷积模块的输出若所述尺寸与中间结果相等,则直接令输入与中间结果相加得到自适应置信度图卷积模块的输出
[0029]
步骤2.3.7、重复步骤2.3.1-步骤2.3.6直到通过所有的自适应置信度模块,从而得到空间步态特征序列f
s
。
[0030]
所述步骤2.4包括:
[0031]
步骤2.4.1、将每个时空特征融合模块的输入记为令分别经过两个卷积算子后得到特征图和通过矩阵乘法计算和的积,并使用softmax函数对结果进行归一化,得到自适应矩阵a
′
;
[0032]
步骤2.4.2、将所述邻接矩阵e
′
、自适应矩阵a
′
相加得到自适应邻接矩阵e
″′
;将输入和自适应邻接矩阵e
″′
经过图卷积算子得到时空特征融合模块中自适应图卷积层的输出
[0033]
步骤2.4.3、将自适应图卷积层的输出依次经过一层批归一化层,一层relu激活层,一层dropout层后得到深层空间步态特征序列f
st
′
;
[0034]
步骤2.4.4、将所述深层空间步态特征序列f
st
′
依次经过一层卷积层、一层批归一化层,一层relu激活层后得到时空特征融合模块的中间结果
[0035]
步骤2.4.5、若所述输入的尺寸与中间结果不相等,则令输入通过一层卷积层后使其与中间结果尺寸相等,并与中间结果相加得到时空特征融合模块的
输出若输入尺寸与中间结果相等,则直接令输入与中间结果相加得到时空特征融合模块的输出
[0036]
步骤2.4.6、重复步骤2.4.1-步骤2.4.5直到通过所有的自适应置信度模块,从而得到时空步态特征序列f
st
。
[0037]
与已有技术相比,本发明的有益效果体现在:
[0038]
1、本发明设计了一种自适应置信度图卷积网络,将图卷积引入步态识别任务中,与目前主流的步态识别方法相比,本发明的方法计算量低、效率更高,且对外界干扰因素如外观变化等有更好的鲁棒性,从而更利于步态识别的实际应用。
[0039]
2、本发明通过所设计的自适应置信度图卷积网络从人体姿态信息中提取步态特征,与传统的卷积网络相比,该网络能更好的处理姿态关键点数据,并能够利用姿态关键点之间的联系以提取更丰富的步态特征,从而提高了步态识别的准确性。
[0040]
3、本发明构建了一种应用于图卷积网络的自适应置信度加权机制,使用姿态提取器所得到的置信度,在卷积过程中对各个姿态关键点进行加权,降低了噪声点的不良影响,更多利用准确的姿态信息,最终提高了步态识别的准确性。
[0041]
4、本发明通过构建自适应置信度图卷积网络以及注意力机制的应用,增加了步态特征的多样性,并保证了步态特征的精确性。
附图说明
[0042]
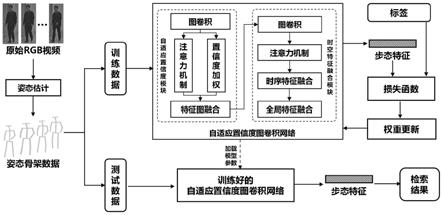
图1为本发明方法流程示意图;
[0043]
图2为本发明自适应置信度图卷积层的结构图;
[0044]
图3为本发明自适应置信度模块的结构图;
[0045]
图4为本发明时空特征融合模块的结构图;
[0046]
图5为本发明自适应置信度图卷积网络的结构图。
具体实施方式
[0047]
本实施例中,一种基于自适应置信度图卷积网络的步态识别方法,主要利用图卷积网络和注意力机制从带有噪声的姿态数据中提取有效的步态特征,如图1所示,具体步骤如下:
[0048]
步骤1、使用姿态估计算法从原始视频数据集中提取人体姿态关键点,得到n个t帧的步态序列并进行标准化处理,得到标准化的姿态骨架数据集记为其中,表示第n个标准化后的姿态骨架序列,且表示第n个标准化后的姿态骨架序列中第t帧姿态骨架;表示第t帧姿态骨架中姿态关键点对应的置信度;n=1,2,...,n,t=1,2,...,t;本实施例中利用casi-b步态数据集进行训练和测试,该数据集包含124人在不同行走状态、不同视角下的行走视频;使用前62人的数据作为训练集,后62人的数据作为测试集;所用姿态估计算法为alphapose;由于行人在行走时与相机的距离不断变化,因此获取的姿态骨架大小不一致,为了避免尺寸对步态特征的影响,需要将所有的姿态骨架数
据标准化;记原始姿态骨架为p={v
i
|i=1,2,...,m},其中v
i
表示姿态骨架中第i个姿态关键点,m表示一幅姿态骨架中姿态关键点的数量;记标准化后的姿态骨架为标准化的过程可表示为式(1):
[0049][0050]
式(1)中,v
neck
和v
hip
分别表示颈部关键点和臀部关键点的坐标,dist表示欧式距离函数;因为在姿态估计中,颈部关键点和臀部关键点较为准确,因此将这两个关键点间的距离归一化可以得到尺寸相对一致的姿态数据;在训练时,视频序列长度t取30,这是因为一个完整的步态周期约为25帧,因此取30帧可以保证步态数据包含一个完整的步态,若数据集中的视频长度短于30帧,则将其重复到30帧以上再截取前30帧;使用统一的视频长度是为了利用批处理加速训练过程;
[0051]
步骤2、建立自适应置信度图卷积网络模型,包括:一层输入模块、α层自适应置信度模块、β层时空特征融合模块和一层输出模块组成,如图5所示,本实施例中α取3,β取7,以使网络达到最佳的识别准确率;
[0052]
输入模块由一层批归一化层实现;
[0053]
如图3所示,自适应置信度模块依次由一层自适应置信度图卷积层、一层归一化层、一层relu激活层和一层dropout层组成;
[0054]
如图4所示,时空特征融合模块依次由一层自适应图卷积层、一层归一化层、一层relu激活层、一层dropout层、一层卷积层、一层归一化层和一层relu激活层组成;
[0055]
输出模块由一层池化层和带有softmax函数的一层全连接层组成;
[0056]
步骤2.1、将所标准化的姿态骨架述数据集x中的姿态数据按照人体结构构图,将每个姿态关键点看作图的顶点集v,将姿态关键点之间的自然连接看作图的边集e,从而构成图数据记为g=(v,e);
[0057]
步骤2.2、将图数据g送入输入模块进行数据归一化处理,得到归一化后的图数据g
′
=(v
′
,e
′
),v
′
表示归一化后的顶点集,e
′
表示通过正则化后的邻接矩阵;输入模块使数据归一化处理为满足均值为0、标准差为1分布的数据,有助于减少训练集和测试集分布间的偏差,从而提高准确率;
[0058]
步骤2.3、将归一化后的图数据g
′
和所标准化的姿态骨架数据集x中的置信度向量依次输入α层自适应置信度模块,按照预设的图卷积算子从图数据g
′
中提取特征,并利用置信度向量对所提取的特征加权;经过α层自适应置信度模块后得到空间步态特征序列其中,表示空间特征序列f
s
中第t帧特征图;本实施例中使用了3层自适应置信度模块,每层置信度模块输出的特征图通道数分别为64,64和64,如图5所示;
[0059]
步骤2.3.1、自适应置信度模块中自适应置信度图卷积层的结构如图2所示,将每个自适应置信度图卷积层的输入记为令分别经过两个卷积算子后得到特征图和通过矩阵乘法计算和的积,并使用softmax函数对结果进行归一化,得到自适应矩阵a;对于姿态骨架中的姿态关键点而言,各个关键点的重要性并不相同,在步态识别任务
中,显然腿部关键点比头部关键点包含更多的步态信息,因此需要对各个关键点进行加权;而邻接矩阵e
′
仅用来表示关键点之间是否有连接,并没有表示各个关键点的权重,因此需要额外的权重矩阵;该步骤通过注意力机制计算各个关键点间的相关性,得到的矩阵a能够自适应地更新各个关键点的权重;
[0060]
步骤2.3.2、将置信度向量按列扩展为与邻接矩阵a尺寸一致的矩阵,记为置信度矩阵c;并生成一个同样尺寸的全0矩阵,作为自适应矩阵b;图卷积的过程就是各个关键点进行信息交换的过程,但由于部分关键点是噪声数据,所包含地信息并不准确,因此需要在信息交换过程中抑制这些噪声关键点;将置信度向量按列扩展为置信度矩阵后,就可以利用置信度矩阵在图卷积过程中按照关键点的置信度对关键点加权,从而抑制噪声关键点向其他关键点传播信息,同时不影响噪声关键点接收正确关键点的信息;自适应矩阵b是对邻接矩阵e
′
的进一步补充,在e
′
中仅按人体的自然连接定义了关键点之间的连接,但关键点之间还有隐含的联系,例如人在行走时同一侧的手臂和腿部运动方向相反,这说明手臂和腿部间存在隐含的联系,自适应矩阵b网络的训练过程中自动更新以扩展关键点间的连接及权重。
[0061]
步骤2.3.3、将邻接矩阵e
′
、自适应矩阵a、自适应矩阵b相加后与置信度矩阵c相乘计算哈达玛积得到最终的自适应置信度邻接矩阵e
″
,将最终的自适应置信度邻接矩阵e
″
与输入一起通过一个图卷积算子后得到自适应置信度图卷积层中自适应分支的输出
[0062]
步骤2.3.4、将输入与置信度向量相乘加权后再通过一个卷积算子得到自适应置信度图卷积层中置信度分支的输出
[0063]
步骤2.3.5、将自适应分支的输出与置信度分支的输出相加后得到自适应置信度图卷积层的输出再经过一层归一化层、一层relu激活层和一层dropout层得到自适应置信度图卷积模块的中间结果使用dropout层的原因是避免网络出现过拟合现象,本实施例中所有dropout层的概率都为0.5;
[0064]
步骤2.3.6、若输入尺寸与中间结果不相等,则令输入通过一层卷积层后使其与中间结果尺寸相等,并与中间结果相加得到自适应置信度图卷积模块的输出若尺寸与中间结果相等,则直接令输入与中间结果相加得到自适应置信度图卷积模块的输出该步骤将输入与中间结果相加,通过残差学习提高网络的性能;
[0065]
步骤2.3.7、重复步骤2.3.1-步骤2.3.6直到通过所有的自适应置信度模块,从而得到空间步态特征序列f
s
;
[0066]
步骤2.4、将空间步态特征序列依次输入β层时空特征融合模块,利用图卷积算子从空间步态特征序列f
s
中进一步提取深层空间步态特征,并利用时序卷积算子从空间步态特征序列中提取时空步态特征;经过β层的时空特征融合模块后得到时空步态特征序列其中,表示时空特征序列f
st
中第t帧特征图,t
′
表示经过所有时空特征融合模块后的时空特征序列的帧数;时空特征融合模块与
自适应置信度模块的主要区别在于时空特征融合模块不使用置信度进行加权,仅利用注意力机制扩展邻接矩阵,原因有两方面:一方面经过α层自适应置信度模块后,各个关键点进行信息交换,原本的噪声关键点在接收正确信息后自身的噪声被抑制,因此可以视作正确的关键点;另一方面置信度加权需要置信度与各个姿态关键点一一对应,而时空特征融合模块在时序卷积的过程中改变了姿态序列的长度,不再满足一一对应的关系;本实施例中使用了7层时空特征融合模块,每层时空特征融合模块输出的特征图通道数分别为64,128,128,128,256,256和256,如图5所示;且第2层和第5层的时空特征融合模块中的卷积层的步长为2,其余时空特征融合模块中的卷积层步长都为1;
[0067]
步骤2.4.1、将每个时空特征融合模块的输入记为令分别经过两个卷积算子后得到特征图和通过矩阵乘法计算和的积,并使用softmax函数对结果进行归一化,得到自适应矩阵a
′
;
[0068]
步骤2.4.2、将邻接矩阵e
′
、自适应矩阵a
′
相加得到自适应邻接矩阵e
″′
;将输入和自适应邻接矩阵e
″′
经过图卷积算子得到时空特征融合模块中自适应图卷积层的输出
[0069]
步骤2.4.3、将自适应图卷积层的输出依次经过一层批归一化层,一层relu激活层,一层dropout层后得到深层空间步态特征序列f
st
′
;
[0070]
步骤2.4.4、将深层空间步态特征序列f
st
′
依次经过一层卷积层、一层批归一化层,一层relu激活层后得到时空特征融合模块的中间结果
[0071]
步骤2.4.5、若输入的尺寸与中间结果不相等,则令输入通过一层卷积层后使其与中间结果尺寸相等,并与中间结果相加得到时空特征融合模块的输出若输入尺寸与中间结果相等,则直接令输入与中间结果相加得到时空特征融合模块的输出
[0072]
步骤2.4.6、重复步骤2.4.1-步骤2.4.5直到通过所有的自适应置信度模块,从而得到时空步态特征序列f
st
;
[0073]
步骤2.5、将时空步态特征序列在时序上进行平均处理,以融合t
′
帧特征图;将融合后的特征图再在空间上进行平均处理,以融合所有姿态关键点的特征,从而得到最终的步态特征f;该步骤中采用平均处理融合时序特征,使得长度不一致的序列在经过网络后能够得到相同尺寸的步态特征,以便于测试;
[0074]
步骤2.6、将步态特征f送入输出模块,得到预测结果y;
[0075]
步骤3、根据步态特征f计算三元组损失,根据预测结果y计算交叉熵损失,并使用sgd更新自适应置信度图卷积网络模型的权重,并在损失值趋于稳定时完成训练,得到最优自适应置信度图卷积网络模型;本实施例中,每次迭代时从训练集中随机挑选12人,再从每个人的数据中随机挑选2个步态序列,因此每次迭代时的批尺寸为24个序列;三元组损失的边界距离设为1.5,且三元组损失的权重为0.25;训练过程采用了预热的训练策略,该策略有助于缓解网络的过拟合现象,提高准确率,具体策略实施为:将初始学习率设置为0.0001,并在1000次迭代中线性增长到0.1,之后迭代到第5000次、第7000次和第9000次时
都将学习率减少到原来的0.1倍,在迭代10000次后结束训练;
[0076]
步骤4、利用最优自适应置信度图卷积网络模型对待检索序列和检索库种所有序列提取步态特征,计算待检索特征和检索库种所有特征间的欧式距离,按照距离由小到大进行排序,从而得到检索结果;在测试时将每个序列的所有帧都送入模型提取步态特征,以充分利用数据中的信息。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1