一种基于图模型的高光谱图像分类方法与流程
[0001]
本发明涉及高光谱图像、图模型与机器学习技术领域,具体是一种基于图模型的高光谱图像分类方法。
背景技术:
[0002]
高光谱图像数据是一种特殊的图像,最先应用在卫星遥感技术上,现已在军事、医学、地质、农业等领域得到广泛的应用。普通图像在成像时进行的是宽波段成像,成像结果几乎不具备频谱特性,相关研究极度依赖图像的空间分辨率。高光谱图像是多窄波段成像的结果,相比于普通图像,其携带了丰富的频谱信息。对高光谱数据的研究十分广泛,分类是其中较为重要的一项内容。高光谱图像分类的目的是对像素点进行标记,标记结果能很好地反应待测目标的相关特性。然而高光谱图像分类存在已知样本量少、数据维度高等问题。
[0003]
图是一种常见的数据结构,常用于无线传感器网络、社交网络等场景。此外,图也常用于对特征维度较高的数据进行降维表示。
[0004]
机器学习是一类任务求解方法的统称,该类方法对相关任务进行数学建模,接着使用计算机等工具对建模的优化问题进行求解以得到结果。机器学习经过数十年的发展,已在工业、交通、ic设计等方面得到广泛应用。
技术实现要素:
[0005]
本发明的目的是针对高光谱图像分类任务中存在的数据量大、数据维度高、已知样本量少等问题,而提供一种基于图模型的高光谱图像分类方法。这种方法在大规模数据下计算复杂度低、能完成较高精度的分类。
[0006]
实现本发明目的的技术方案是:
[0007]
一种基于图模型的高光谱图像分类方法,包括如下步骤:
[0008]
1)图建模:假设高光谱图像数据为x=[x1,x2,
…
,x
m
×
n
]∈r
m
×
n
×
d
,共有m
×
n个像素点,x
i
∈r
d
为第i个像素的特征向量,为数据中像素点上的标签,标签均来自于l={l1,l2,...,l
c
},共c类,为x中已知部分的标签,为未知的标签,值均为0,且通过高光谱图像数据不同像素点特征向量x
i
的相似特性,构建出图g={v,e,w},v为图的节点集,对应数据中的每一个像素,由边相连接,e是边集,边用于描述节点之间的相似与邻接关系,w是权矩阵,内部元素表示对应两个节点的相似程度,定义为公式(1)所示:
[0009][0010]
为节点i的邻居集合;
[0011]
2)优化问题归结:标签y的one-hot编码矩阵y定义为公式(2)所示:
[0012][0013]
y
i
为标签y中第i个元素,由y,高光谱图像的分类问题可归结如公式(3)所示:
[0014][0015]
对公式(3)求解可得到用于分类的one-hot编码矩阵f,公式(3)中,α为权重因子,l
n
=i-d-1/2
wd-1/2
为归一化图拉普拉斯矩阵,i为单位阵,y
j
与f
j
分别为y与f的第j列,为f
j
的转置,d为度矩阵,定义为公式(4)所示:
[0016][0017]
将d-1/2
wd-1/2
记为w
n
,公式(3)中问题由c个优化问题组成,这些优化问题相互独立且求解过程相似,仅对其中之一进行分析,令f=f
j
,有:
[0018][0019]
公式(5)中为匹配项,为正则项;
[0020]
3)hessian矩阵的分解:公式(5)中问题用牛顿法求解,其一阶与二阶梯度信息分别为公式(6)、(7)所示:
[0021][0022][0023]
由此得目标函数的hessian矩阵h=αi+l
n
,令w
n
=w
nd
+w
nu
,其中w
nd
=diag(w
n
),由l
n
=i-w
n
,有:
[0024]
a=αi+(1+θ)(i-w
nd
)
ꢀꢀꢀꢀꢀꢀꢀ
(8),
[0025]
b=w
nu
+θ(i-w
nd
)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(9),
[0026]
其中θ≥0是控制分解的参数,hessian矩阵可分解为a与b的组合如公式(10)所示:
[0027]
h=a-b
ꢀꢀꢀꢀꢀꢀꢀ
(10);
[0028]
4)牛顿步长的近似:牛顿法求解时,第k步的牛顿步长由公式(10)有:
[0029][0030]
令p=w
n-αi,q=(i-p)-1
,由泰勒展开得q≈i+p,通过公式(12)对公式(11)的牛顿步长进行近似:
[0031][0032]
5)迭代求解:根据公式(13),采用公式(12)中的近似牛顿步长对公式(5)进行求解:
[0033][0034]
公式(13)中,变量右上角的k为迭代次数,且f0=0,f1=1,当成立时,终止迭代;
[0035]
6)分布式求解:公式(5)中匹配项分别表示为第i个节点上的一阶梯度信息为公式(14)所示:
[0036][0037]
w
ij
是w
n
中第i行j列的元素,在图上对应节点i与节点j之间的权重值,由此,对于节点i,有:
[0038]
6-1)与中的节点进行通信,获取f
k
在上的值;
[0039]
6-2)计算2)计算为e
k
在节点i上的值,a
ii
为a对角线上的第i个元素;
[0040]
6-3)与中的节点进行通信,获取e在上的值;
[0041]
6-4)计算4)计算为u
k
在节点i上的值;
[0042]
6-5)与中的节点进行通信,获取u在的值;
[0043]
6-6)计算步长6)计算步长为步长s
k
在节点i上的值;
[0044]
6-7)计算对f
k
在节点i上的值进行更新;
[0045]
6-8)将所有节点上的拼接成f
k+1
,判断终止条件是否成立:如果终止条件成立,则f
k+1
设为one-hot矩阵中的对应列,并开始one-hot矩阵下一列的求解;如果终止条件不成立,则以f
k+1
为初始值,进行下一次迭代;
[0046]
7)求解分类结果:由步骤6)得到one-hot编码矩阵f,最后通过公式(15)得出分类结果
[0047][0048]
本技术方案采用图模型对高光谱图像数据进行降维,接着对学习任务进行问题归结,然后通过矩阵分解对hessian矩阵进行近似,并使用近似的hessian矩阵通过拟牛顿法求解。
[0049]
这种方法计算复杂度底,分类精度较高,更适用于大规模的高光谱图像分类问题。
附图说明
[0050]
图1为实施方法在ksc数据中的迭代收敛情况示意图;
[0051]
图2为实施方法在indianpines数据中迭代收敛情况示意图。
具体实施方式
[0052]
下面结合附图和实施例对发明的内容作进一步的阐述,但不是对本发明的限定。
[0053]
实施例:
[0054]
一种基于图模型的高光谱图像分类方法,包括如下步骤:
[0055]
1)图建模:假设高光谱图像数据为x=[x1,x2,...,x
m
×
n
]∈r
m
×
n
×
d
,共有m
×
n个像素点,x
i
∈r
d
为第i个像素的特征向量,为数据中像素点上的标签,标签均来自于l={l1,l2,...,l
c
},共c类,为x中已知部分的标签,为未知的标签,值均为0,且通过高光谱图像数据不同像素点特征向量x
i
的相似特性,构建出图g={v,e,w},v为图的节点集,对应数据中的每一个像素,由边相连接,e是边集,边用于描述节点之间的相似与邻接关系,w是权矩阵,内部元素表示对应两个节点的相似程度,定义为公式(1)所示:
[0056][0057]
为节点i的邻居集合;
[0058]
2)优化问题归结:标签y的one-hot编码矩阵y定义为公式(2)所示:
[0059][0060]
y
i
为标签y中第i个元素,由y,高光谱图像的分类问题可归结如公式(3)所示:
[0061][0062]
对公式(3)求解可得到用于分类的one-hot编码矩阵f,公式(3)中,α为权重因子,l
n
=i-d-1/2
wd-1/2
为归一化图拉普拉斯矩阵,i为单位阵,y
j
与f
j
分别为y与f的第j列,为f
j
的转置,d为度矩阵,定义为公式(4)所示:
[0063][0064]
将d-1/2
wd-1/2
记为w
n
,公式(3)中问题由c个优化问题组成,这些优化问题相互独立且求解过程相似,仅对其中之一进行分析,令f=f
j
,有:
[0065][0066]
公式(5)中为匹配项,为正则项;
[0067]
3)hessian矩阵的分解:公式(5)中问题用牛顿法求解,其一阶与二阶梯度信息分别为公式(6)、(7)所示:
[0068][0069][0070]
由此得目标函数的hessian矩阵h=αi+l
n
,令w
n
=w
nd
+w
nu
,其中w
nd
=diag(w
n
),由l
n
=i-w
n
,有:
[0071]
a=αi+(1+θ)(i-w
nd
)
ꢀꢀꢀꢀꢀꢀꢀ
(8),
[0072]
b=w
nu
+θ(i-w
nd
)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(9),
[0073]
其中θ≥0是控制分解的参数,hessian矩阵可分解为a与b的组合如公式(10)所示:
[0074]
h=a-b
ꢀꢀꢀꢀꢀꢀꢀꢀ
(10);
[0075]
4)牛顿步长的近似:牛顿法求解时,第k步的牛顿步长由公式(10)有:
[0076][0077]
令p=w
n-αi,q=(i-p)-1
,由泰勒展开得q≈i+p,通过公式(12)对公式(11)的牛顿步长进行近似:
[0078][0079]
5)迭代求解:根据公式(13),采用公式(12)中的近似牛顿步长对公式(5)进行求解:
[0080][0081]
公式(13)中,变量右上角的k为迭代次数,且f0=0,f1=1,当成立时,终止迭代;
[0082]
6)分布式求解:公式(5)中匹配项分别表示为第i个节点上的一阶梯度信息为公式(14)所示:
[0083][0084]
w
ij
是w
n
中第i行j列的元素,在图上对应节点i与节点j之间的权重值,由此,对于节点i,有:
[0085]
6-1)与中的节点进行通信,获取f
k
在上的值;
[0086]
6-2)计算2)计算为e
k
在节点i上的值,a
ii
为a对角线上的第i个元素;
[0087]
6-3)与中的节点进行通信,获取e在上的值;
[0088]
6-4)计算4)计算为u
k
在节点i上的值;
[0089]
6-5)与中的节点进行通信,获取u在的值;
[0090]
6-6)计算步长6)计算步长为步长s
k
在节点i上的值;
[0091]
6-7)计算对f
k
在节点i上的值进行更新;
[0092]
6-8)将所有节点上的拼接成f
k+1
,判断终止条件是否成立:如果终止条件成立,则f
k+1
设为one-hot矩阵中的对应列,并开始one-hot矩阵下一列的求解;如果终止条件不成立,则以f
k+1
为初始值,进行下一次迭代;
[0093]
7)求解分类结果:由步骤6)得到one-hot编码矩阵f,最后通过公式(15)得出分类结果
[0094][0095]
仿真例1:
[0096]
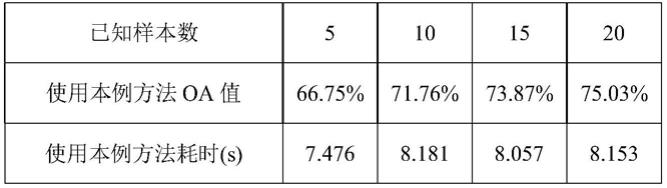
本例采用ksc数据进行仿真,ksc数据内有176个频段,去除背景后共有5211个像素点,像素点可分为13类,是一个多分类的学习任务,仿真前,对标签值进行抽样以生成已知标签数量不同的数据集,为了多项对比,生成每类仅剩5、10、15、20个已知样本的数据集,表1中给出了采用本例方法与采用集中式方法在ksc数据中的分类性能对比,包括oa参数与计算耗时,表1的仿真结果表明,在ksc数据中,采用本例方法与采用集中式方法相比,采用本例方法与采用集中式方法的分类精度完全一致,而采用本例方法的计算速度略快于采用集中式方法,如图1所示,采用本例方法能在有限次数内迭代收敛,说明采用本例方法能产生出较好的结果,且消耗时间较短。
[0097]
表1
[0098][0099][0100]
仿真例2:
[0101]
本例采用indianpines数据进行仿真,indianpines数据内有200个频段,去除背景后共有10249个像素点,像素点可分为16类,同样是一个多分类的学习任务,与仿真例1相同,抽样生成每类仅剩5、10、15、20个已知样本的数据集,表2中给出了采用本例方法与采用集中式方法在indianpines数据中的分类性能对比,同样包括oa参数与计算耗时,表2的仿真结果表明,在indianpines数据中,采用本例方法与采用集中式方法相比,采用本例方法与采用集中式方法的分类精确度基本一致,而在本仿真例,采用本例方法的计算速度远优
于采用集中式方法,如图2所示,采用本例方法同样能在有限次数内迭代收敛,说明本例方法更适用于大规模数据下的高光谱图像分类任务。
[0102]
表2
[0103]
已知样本数5101520使用本例方法oa值41.98%46.69%49.71%51.67%使用本例方法耗时(s)37.0938.5939.139.83使用集中式方法oa值42.02%46.7%49.72%51.68%使用集中式方法耗时(s)242.9271242.5299.6。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1