基于改进YOLOv3-tiny的交通标志检测与识别方法与流程
基于改进yolov3-tiny的交通标志检测与识别方法
技术领域
1.本发明涉及人工智能的深度学习技术领域,特别涉及一种基于yolov3-tiny改进的交通标志检测与识别方法。
背景技术:
2.深度学习目标检测技术使用卷积神经网络进行特征提取,通过训练学习,实现了更加强大的适应能力和泛化能力。yolov3网络模型采用多个尺度融合的方式进行预测,预测性能代表了目前目标检测领域的顶尖水平,但其网络模型体积较为庞大,无法在算力有限的车载嵌入式设备中达到实时性要求,而注重检测速度的精简版本yolov3-tiny实时性较高,占用显存空间较小,却存在检测准确性不高的问题,不能完全适用于自动驾驶的交通标志检测任务中。
3.因此,需要对yolov3-tiny检测算法进行改进以满足车载嵌入式设备的算力和交通标志检测精度要求。
技术实现要素:
4.本发明的目的在于提供一种基于yolov3-tiny改进的交通标志检测与识别方法,选取yolov3的精简版本yolov3-tiny为基础算法,在网络结构上对基础算法进行改进,改进的yolov3-tiny有较强的泛化能力,占用存储空间和显存空间较小,提高了检测识别准确率,同时还能保证实时性,能够在算力有限的车载嵌入式设备中实现精确和快速的交通标志检测与识别。
5.为实现上述目的,本发明提供了如下方案:本发明提供基于改进yolov3-tiny的交通标志检测与识别方法,包括以下步骤:
6.采集交通标志图像数据,采用几何变换和色彩变换对图像数据进行增强扩增,并进行图像标注,得到交通标志训练集;
7.构建改进的yolov3-tiny网络模型,并采用交通标志训练集对改进的yolov3-tiny网络模型进行训练;
8.根据交通标志图像数据构建交通标志测试集,并利用训练好的改进的yolov3-tiny网络模型对交通标志测试集进行检测与识别。
9.优选地,所述调节色彩变换是通过调节色相、对比度、饱和度和亮度来进行色彩变换;
10.所述几何变换是通过随机剪裁和随机拼接来进行图像的几何变换。
11.优选地,所述改进的yolov3-tiny网络模型的改进过程为:
12.在yolov3-tiny主干网络末尾增加一层卷积核数量为256、尺寸为1
×
1、步长为1的卷积层构成新的主干网络;在新的主干网络之后连接一层卷积核数量为128、尺寸为1
×
1、步长为1的卷积层和一层上采样层;在8
×
8尺度的输出层之前增加一层卷积核数量为42、尺寸为1
×
1、步长为1的卷积层,在16
×
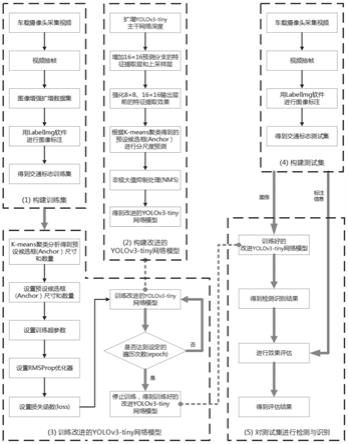
16尺度的输出层之前增加一层卷积核数量为42、尺寸
为1
×
1、步长为1的卷积层。
13.优选地,所述改进的yolov3-tiny网络模型的主干网络主要由6个大小为3
×
3的卷积层、2个大小为1
×
1的卷积层和5个步长为2的池化层组成;并在每个卷积层后添加批标准化层;
14.所述改进的yolov3-tiny网络模型的前7个卷积层的卷积核个数依2的幂次关系递增,分别有16、32、64、128、256、512、1024个卷积核,最后一个卷积层拥有256个卷积核;
15.所述改进的yolov3-tiny网络模型的主干网络后分别引出8
×
8尺度分支和16
×
16尺度分支。
16.优选地,所述16
×
16尺度分支接入一层卷积核数量为128、尺寸为1
×
1、步长为1的卷积层和一层上采样层,并与主干网络中第4个池化层引出的分支一起进行维度扩增,接入一个卷积核数量为256、尺寸为3
×
3、步长为1的卷积层和一个卷积核数量为42、尺寸为1
×
1、步长为1的卷积层,能够输出16
×
16尺度分支的检测结果;
17.所述8
×
8尺度分支接入一个卷积核数量为512、尺寸为3
×
3、步长为1的卷积层和一个卷积核数量为42、尺寸为1
×
1、步长为1的卷积层,能够输出8
×
8尺度分支的检测结果。
18.优选地,所述改进的yolov3-tiny网络模型的检测与识别过程为:将交通标志测试集图像的每个像素值进行归一化并将图像缩放,并送入改进的yolov3-tiny网络模型的网络进行推理;通过不同尺度的输出通道直接得到包含目标框坐标、目标置信度和目标框内物体类别在内的特征图;根据网络模型输出的置信度对检测结果进行非极大值抑制和分类识别,得到最终的检测结果。
19.优选地,所述对改进的yolov3-tiny网络模型进行训练过程中,采用动态学习率改善模型在不同训练阶段的收敛速度,并使用rmsprop优化器改善损失下降路径。
20.优选地,采用平均类别准确率、平均交并比和fps作为性能指标来检测所述改进的yolov3-tiny网络模型对交通标志的检测能力。
21.本发明公开了以下技术效果:
22.(1)与原版yolov3-tiny相比,本发明构建的改进的yolov3-tiny网络模型仅增加很小的存储空间占用量,就能显著提高对交通标志检测识别的准确率,还能保证实时性;
23.(2)本发明构建的改进的yolov3-tiny占用存储空间小,具有yolov3-tiny的高实时性及yolov3的高准确率的双重优点,在保证检测实时性的同时,大大提高了准确率;
24.(3)本发明构建的改进的yolov3-tiny网络模型对交通标志类别的分类能力强,预测交通标志位置准确度高,检测速度快,实时性好,能够在算力很小的车载嵌入式设备中实现准确和快速的检测识别。
附图说明
25.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
26.图1为本发明基于改进yolov3-tiny的交通标志检测与识别方法流程示意图;
27.图2为本发明改进的yolov3-tiny网络模型结构示意图;
28.图3为本发明改进的yolov3-tiny目标检测流程示意图。
具体实施方式
29.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
30.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
31.如图1所示,本发明提供基于改进yolov3-tiny的交通标志检测与识别方法,包括以下步骤:
32.s1、采集交通标志图像数据,采用几何变换和色彩变换对图像数据进行增强扩增,并进行图像标注,得到交通标志训练集。
33.本实施例通过人工遥控小车在车道上行驶,利用车载摄像头获取包含起跑线、斑马线、限速标志、取消限速标志、直行、左转弯、红灯、绿灯、停车标志、蓝色路障、红色路障、红线、超车标志共13个类别的交通标志图像,构成基础数据集。为增强图像的多样性,通过人工控制灯光照射的角度和强度及室外光照来实现不同的行车光线环境,模拟行车过程中可能受到的视觉干扰效果,进行多种环境干扰下数据的采集,并通过控制不同的车速来采集不同清晰度的交通标志图像。
34.本实施例采用调节色彩变换和几何变换两种数据增强的方法对交通标志基础数据集进行扩增,共获得了2964张rgb三通道图片。其中包含起跑线、斑马线、限速标志、取消限速标志、直行、左转弯、红灯、绿灯、停车标志、蓝色路障、红色路障、红线、超车标志共13个类别的交通标志,各类别图像数量在200~400不等,得到的数据集具有多样性和均衡性。
35.调节色彩变换是指通过调节色相、对比度、饱和度和亮度来进行色彩变换;几何变换是指通过随机剪裁和随机拼接来进行图像的几何变换。其中,设置任一图片都有50%的概率增加或减少[0,18]绝对值范围内的色相、[0,0.5]比例范围内的对比度、[0,0.5]比例范围内的饱和度和[0,0.125]比例范围内的亮度,以及50%的概率进行随机剪裁和拼接。
[0036]
用labelimg标注软件生成包含目标标注信息的xml文件,构建出与原图像对应的交通标志训练集。将目标的标注信息做可视化,叠加在原图像中。
[0037]
s2、构建改进的yolov3-tiny网络模型,并采用交通标志训练集对改进的yolov3-tiny网络模型进行训练。
[0038]
本实施例选取yolov3的精简版本yolov3-tiny为基础算法,在网络不同部分增加了特定的卷积层对基础算法进行改进,通过聚类分析确定最符合数据集分布的预设候选框(anchor)组合。
[0039]
本实施例将交通标志训练集图像的每个像素值进行归一化并将图像缩放到256
×
256尺寸,送入网络进行推理,通过2个不同尺度(8
×
8、16
×
16)的输出通道直接得到包含目标框坐标、目标置信度和目标框内物体类别在内的特征图,根据网络模型输出的置信度对检测结果进行非极大值抑制(nms)和分类识别,最终输出检测结果。
[0040]
本实施例对原版yolov3-tiny网络进行改进,在原主干网络末尾增加一层卷积核
数量为256、尺寸为1
×
1、步长为1的卷积层构成新的主干网络,在新的主干网络之后连接一层卷积核数量为128、尺寸为1
×
1、步长为1的卷积层和一层上采样层以将特征图尺寸上采样到16
×
16,在8
×
8尺度的输出层之前增加一层卷积核数量为42、尺寸为1
×
1、步长为1的卷积层,在16
×
16尺度的输出层之前增加一层卷积核数量为42、尺寸为1
×
1、步长为1的卷积层,以更好地适应行车环境下的数据,强化特征提取过程,增强多尺度特征融合能力,提升网络的检测精度。
[0041]
具体而言,如图2所示,本实施例改进的yolov3-tiny主干网络主要由6个大小为3
×
3的卷积层(conv2d)、2个大小为1
×
1的卷积层(conv2d)和5个步长为2的池化层(pool2d)组成。每个卷积层后添加批标准化层(batch normalization),加速了网络的收敛。不同的卷积运算如1
×
1和3
×
3的卷积核可以获得交通标志图像中不同感受域的信息,汇集这些卷积运算的结果可以获得丰富的特征信息,非常适合多尺度特征的提取,从而将网络的低级特征和高级特征关联起来。增加的1
×
1卷积核只有一个参数,相当于原始特征图的缩放,实现跨通道信息的整合和通道数量的改变。
[0042]
主干网络中除最后一个卷积层拥有256个卷积核之外,前7个卷积层卷积核个数依2的幂次关系递增,分别有16、32、64、128、256、512、1024个卷积核。
[0043]
主干网络后分别引出8
×
8尺度分支和16
×
16尺度分支。因此本实施例改进的yolov3-tiny包括两尺度预测的方式:
[0044]
(1)16
×
16尺度分支接入一层卷积核数量为128、尺寸为1
×
1、步长为1的卷积层和一层上采样层(unsample),后与主干网络中第4个池化层引出的分支一起进行维度扩增,接入一个卷积核数量为256、尺寸为3
×
3、步长为1的卷积层和一个卷积核数量为42、尺寸为1
×
1、步长为1的卷积层,最终能够输出16
×
16尺度分支的检测结果,这种方式易于检测小目标物体;
[0045]
(2)8
×
8尺度分支则接入一个卷积核数量为512、尺寸为3
×
3、步长为1的卷积层和一个卷积核数量为42、尺寸为1
×
1、步长为1的卷积层,最终能够输出8
×
8尺度分支的检测结果,这种方式易于检测大目标物体。
[0046]
如图3所示,本实施例改进的yolov3-tiny的目标检测思路为:先将输入图像划分成s
×
s个网格,如果某网格的中心内落有某目标物体,则这个网格就负责预测这个物体。每个网格预测出检测物体边界框的4个偏移坐标(t
x
,t
y
,t
w
,t
h
)以及置信度得分。
[0047]
改进的yolov3-tiny的网络在2种不同的尺度上进行预测,分别为8
×
8和16
×
16,每种尺度预测3个边界框,得到的张量尺寸为s
×
s
×
[3
×
(4+1+9)],其中包含4个边界框的坐标(t
x
,t
y
,t
w
,t
h
)、1个目标预测以及9种分类预测。假设以图像左上角顶点为坐标原点,则单元格相对于图像的坐标为(x0,y0),且先验边界框(bounding box prior)具有宽度p
w
和高度p
h
,那么预测出的检测框可以表示为:
[0048][0049][0050]
其中:(b
x
,b
y
)为检测框的中心坐标;σ()表示将t
x
和t
y
归一化为0~1;b
w
和b
h
分别为
检测框的宽度和高度。
[0051]
对改进的yolov3-tiny算法在预设候选框(anchor)方面,通过维度聚类确定出最优anchor宽高维度。在维度聚类分析时采用k-means算法,得到的距离函数如下:
[0052][0053]
其中:i表示聚类的类别数;j表示数据集的数据;box[i]表示每个聚类中心预设框的尺寸大小;truth[j]表示数据集中交通标志框的尺寸大小。
[0054]
改进的yolov3-tiny网络在处理输入图像时采用网格对其进行分割,在每个网格中设置6个参考anchor,训练以真实框(ground truth)作为基准计算分类与回归损失。6个anchor boxes对应6个不同尺度,都具有独立分类结果,减少了训练所需的迭代次数,优化了网络的准确率。
[0055]
对候选区域内的预测框按照分类器类别得分由高到低的顺序进行排序,选择得分最高的候选框并依次计算与其余候选框的iou值;设定阈值,若iou值大于设定阈值,则将得分较低的检测框删除;最后,从未处理的检测框中继续选择得分最高的检测框,重复进行直到所有的预测框都被处理。
[0056][0057]
其中:s
i
表示窗口被过滤掉的可能;iou()表示面积的交并比;m表示第i次筛选中置信度得分最高的候选框;b
i
表示除去m以外其它的候选框;n
t
表示预先设定的阈值,本实施例设置阈值为0.45。
[0058]
本实施例采用训练集对改进的yolov3-tiny网络模型进行训练,将训练集数据送入改进的yolov3-tiny网络模型进行正向传播,得到网络模型的输出结果,将网络模型的输出结果送入损失函数,通过反向传播算法来确定梯度向量,最后通过梯度向量来调整每一个网络权值,使得网络模型的输出误差趋向收敛于零,重复上述过程直至达到设定的遍历次数即训练完成。为了提高模型训练性能,采用动态学习率改善模型在不同训练阶段的收敛速度,使用rmsprop优化器改善损失下降路径。
[0059]
本实施例网络模型训练超参数设置为:输入数据的批大小为32,输入图像尺寸为256
×
256,迭代次数为40000,遍历次数(epoch)为1000,初始学习率为0.01,结束学习率0.0002。设置初始学习率为0.01,算法在100个epoch后开始收敛,继续训练随着学习率的动态调整,算法得以进一步收敛,经过300个epoch后,学习率衰减为初始学习率的0.5倍;经过500个epoch后,学习率衰减为初始学习率的0.25倍;经过700个epoch后,学习率衰减为初始学习率的0.1倍;经过900个epoch后,学习率衰减为初始学习率的0.02倍,最终训练结束时学习率为0.0002。说明交通标志检测网络有效且性能较好。
[0060]
为了进一步优化损失函数在更新中存在摆动幅度过大的问题,加快函数的收敛速度,优化器选用rmsprop(root mean square prop),该算法对权重w和偏置b的梯度使用了微分平方加权平均数。当dw或者db中有一个值比较大,则更新权重或者偏置的时候除以之前累积的梯度的平方根,这样就可以使得更新幅度变小。
[0061]
其中,假设在第t轮迭代过程中,各个公式如下所示:
[0062]
s
dw
=βs
dw
+(1-β)dw2ꢀꢀꢀ
(5)
[0063]
s
db
=βs
db
+(1-β)db2ꢀꢀꢀ
(6)
[0064][0065][0066]
其中:s
dw
和s
db
分别是损失函数在前t-1轮迭代过程中累积的权重梯度动量和偏置梯度动量;α是学习率;β是梯度累积指数,取值为0.9;ε为常数,为了防止分母为零,设置ε取值为10-8
以进行平滑。
[0067]
选取损失值为指标,对交通标志检测网络的性能和有效性进行评价。在模型的训练过程中,不断调整网络中的参数,优化损失函数loss的值达到最小,完成模型的训练。在yolov3-tiny中,损失函数yolo loss封装自定义lambda的损失层中,作为模型的最后一层,参与训练。损失层lambda的输入是已有模型的输出和真值,输出是损失值。
[0068]
改进的yolov3-tiny网络模型沿用yolov3-tiny的loss。其中,k
×
k为网格数,在本发明中即为8
×
8、16
×
16;m为box,当box有目标物时,值为1,否则为0;当box无目标物时,值为1,否则为0。
[0069]
由此得损失函数loss为:
[0070][0071]
s3、根据交通标志图像数据构建交通标志测试集,并利用训练好的改进的yolov3-tiny网络模型对交通标志测试集进行检测与识别。
[0072]
测试集由600张行车车载摄像头采集的交通标志图像组成,是小车在不同的时间段、不同的天气因素、不同的灯光情况、不同的门窗开启情况以及不同的人员走动情况下采集的图像,包括起跑线、斑马线、限速标志、取消限速标志、直行、左转弯、红灯信号、绿灯信号、停车标志、蓝色路障、红色路障、红线、超车标志共13类交通标志图像。用labelimg标注软件生成包含目标标注信息的xml文件,构建出与原图像对应的交通标志测试集。
[0073]
利用训练好的改进型yolov3-tiny网络模型对交通标志测试集进行检测和识别。将交通标志测试集图像进行处理,对每个像素值进行归一化并将图像缩放,并送入改进的yolov3-tiny网络模型的网络进行推理;通过不同尺度的输出通道直接得到包含目标框坐标、目标置信度和目标框内物体类别在内的特征图;根据网络模型输出的置信度对检测结果进行非极大值抑制和分类识别,得到最终的检测结果;以平均类别准确率(macc)、平均交并比(miou)和fps作为性能指标来检测算法对交通标志的检测能力。macc代表模型的分类能力,计算方法为:
[0074][0075][0076]
其中:n
truei
为第i张图像中预测正确的目标类别数量;n
alli
为第i张图像中所有目标类别的数量;acc
i
为第i张图像的类别准确率;macc的计算结果值范围为[0,1];miou可以表征模型预测目标所在位置的准确程度,iou计算方法为:
[0077][0078]
其中:r
t
为真实标注框;r
a
为模型预测框;miou即为所有图像iou的平均值,越高代表模型预测的目标位置与目标的真实位置重合程度越高,即预测位置更准确,计算结果值范围为[0,1];fps反映了模型的推理速度,fps越高,实时性越好。
[0079]
为了验证本发明的有效性,本实施例在三个平台上对交通标志测试集进行检测与识别,分别是:(1)搭载英伟达v100显卡(算力为125tops),搭配完整版paddle神经网络框架的百度at studio计算服务器;(2)搭载英伟达gtx1050 max-q显卡(算力为35tops),搭配完整版paddle神经网络框架的pc;(3)搭载edgeboard计算卡(算力为1.2tops),搭配paddle-lite轻量级神经网络框架的小车。测试结果见表1。
[0080]
为了比较各模型的性能,本实施例对原版yolov3-tiny和yolov3也进行测试,测试结果如表1所示,各种交通标志检测模型占用存储空间如表2所示。
[0081]
表1
[0082][0083]
表2
[0084]
检测算法占用存储空间本发明改进的yolov3-tiny16.3mb原版yolov3-tiny14.9mbyolov3236mb
[0085]
由表1和表2可知:
[0086]
(1)本发明构建的改进的yolov3-tiny网络模型在ai studio平台上测试的结果是:平均类别准确率为97.25%,平均交并比为76.38%,分别比原版yolov3-tiny提高10.31%和8.1%;fps为124,比yolov3-tiny减少2,比yolov3增加66。由此可见,本发明改进
的yolov3-tiny网络模型占用空间小,且拥有yolov3-tiny的高实时性及yolov3的高准确率的双重优点,在保证实时性的同时,大大提高了准确率。
[0087]
(2)本发明构建的改进的yolov3-tiny网络模型在显卡为gtx1050max-q的pc平台上测试的结果是:平均类别准确率为99.83%,平均交并比为69.24%,分别比原版yolov3-tiny提高14.72%和9.72%;fps为97,比yolov3-tiny减少6,比yolov3增加76。由此可见,本发明改进的yolov3-tiny网络模型占用空间小,且具有yolov3-tiny的高实时性及yolov3的高准确率的双重优点,在保证实时性的同时,大大提高了准确率。
[0088]
(3)本发明构建的改进的yolov3-tiny网络模型在搭载edgeboard计算卡、搭配paddle-lite轻量级神经网络框架的小车上测试的结果是:平均类别准确率为96.67%,平均交并比为70.53%,fps为73。本发明改进的yolov3-tiny网络模型能够在算力很小的车载嵌入式设备中实现准确和快速的检测。
[0089]
以上所述的实施例仅是对本发明优选方式进行的描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1