一种快速准确侦测多次上传的物料清单属于同一产品的方法与流程
本发明涉及数据信息处理
技术领域:
,特别涉及一种快速准确侦测多次上传的物料清单属于同一产品的方法。
背景技术:
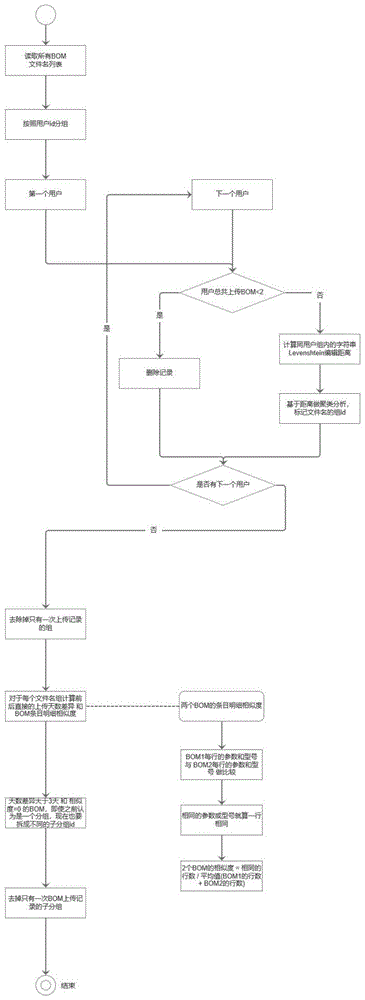
:在采购过程中,客户和销售会协商增加/删除/修改bom(物料清单)文件中的条目明细,然后多次上传。在整理、统计客户和销售上传的bom时,我们需要知道哪些bom文件实际是同一产品的bom,以便于清洗数据,得到唯一准确的信息,本质上,这是一个分组问题。现有技术下,一般采用按照文件名全字符匹配的方式侦测物料清单,可以找出一些,但找不完整,因为客户和销售通常在文件名加后缀,比如:日期或者版本号。技术实现要素:为了解决现有技术的问题,本发明提供了一种快速准确侦测多次上传的物料清单属于同一产品的方法,其综合考虑文件名的字符串相似度、文件上传日期差异、bom条目明细3个维度,从而快速准确的获取多次上传的物料清单是否属于同一产品,提高了侦测容错性和准确性。本发明所采用的技术方案如下:一种快速准确侦测多次上传的物料清单属于同一产品的方法,包括以下步骤:a、读取物料清单的所有文件名列表;b、按照用户id分组,并从第一个用户开始;c、判断此用户上传的物料清单的次数,如果次数<2,则删除记录;如果次数≥2,则计算同用户组内的字符串相似度,基于所述的字符串相似度做聚类分析,并标记文件名的组id;d、判断是否有下一个用户,如果有则重复步骤c,如果没有,则去除掉只有一次上传记录的组;e、对于每个文件名组,计算上传天数差异和物料清单条目明细相似度;f、最终上传天数差异小和物料清单条目相似度度高的物料清单属于同一产品。步骤c中,计算字符串相似度选用计算levenshtein编辑距离的方式进行。步骤e中,计算物料清单条目明细相似度的具体方法包括:e1、比较两组物料清单中每行的参数和型号,相同的参数或者型号归为一行相同;e2、物料清单的相似度=相同行数/平均值(第一组物料清单的行数+第二组物料清单的行数)。步骤e中,如果天数差异大于n,且所述的物料清单条目明细相似度≤m,则需要将所述的文件名组拆分为不同的子分组,并标注子分组id;且去除掉只有一次上传记录的子分组。天数差异值n至少为3天。天数差异值n为3天,所述的m为0。先判断所述物料清单条目明细相似度,如果所述的物料清单条目明细相似度不为0,再判断天数差异。本发明提供的技术方案带来的有益效果是:本发明的一种快速准确侦测多次上传的物料清单属于同一产品的方法,其利用字符串相似度代替全字符匹配,增加了算法的容错性,能找出更多多次上传的物料清单。同时,比较上传日期和物料清单中的明细条目,根据上传日期差异和物料清单的明细条目的相似度控制算法的准确性,从而方便系统更快更准确的找到多次上传的物料清单是否属于同一产品,进而简化系统显示,提高系统效率。附图说明为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本发明的一种快速准确侦测多次上传的物料清单属于同一产品的方法的流程图。具体实施方式为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。实施例一如附图1所示,一种快速准确侦测多次上传的物料清单属于同一产品的方法,包括以下步骤:a、读取物料清单的所有文件名列表;b、按照用户id分组,并判断是否为第一个用户;c、如果是第一个用户,则判断此用户上传的物料清单的次数,如果次数<2,则删除记录;如果次数≥2,则计算同用户组内的字符串levenshtein编辑距离,基于所述的levenshtein编辑距离做聚类分析,并标记文件名的组id;d、判断是否有下一个用户,如果有则重复步骤b-步骤c,如果没有,则去除掉只有一次上传记录的组;e、对于每个文件名组,计算上传天数差异和物料清单条目明细相似度;如果天数差异大于n,且所述的物料清单条目明细相似度=0,则需要将所述的文件名组拆分为不同的子分组,并标注子分组id;且去除掉只有一次上传记录的子分组。天数差异值n为3天。f、最终根据所述的上传天数差异和物料清单条目明细相似度确定需要侦测的物料清单。步骤e中,计算物料清单条目明细相似度的具体方法包括:e1、比较两组物料清单中每行的参数和型号,相同的参数或者型号归为一行相同;e2、物料清单的相似度=相同行数/平均值(第一组物料清单的行数+第二组物料清单的行数)。本实施例的一种快速准确侦测多次上传的物料清单属于同一产品的方法,其方法具体实施原则如下:1)按用户id分组客户上传的物料清单是需要登录的,因此系统可以知道每个物料清单是属于哪个客户的。同时,销售代客户上传物料清单时,也需要选择客户,因为也知道每个物料清单是属于哪个客户的。因此,按照用户id将物料清单分组的背后逻辑是一个隐含假设:同一个产品的物料清单都是由一个用户上传。因此,为了在物料清单库中找到哪些物料清单其实是同一个产品的物料清单不同版本,可以利用用户id来分组缩小范围。后续不需要区分是客户自己上传的,还是销售帮客户上传的。只要看物料清单所属的客户id就好。2)文件名相似度比如:同一个客户的两个物料清单文件《通讯视频捕捉1.xlsx》,《通讯视频捕捉2.xlsx》,根据算法可以判定他们相似度极高,所以可以分为一组。本实施例采用的具体算法如下:levenshteindistance,一般称为编辑距离(editdistance,levenshteindistance只是编辑距离的其中一种)或者莱文斯坦距离,算法概念是俄罗斯科学家弗拉基米尔·莱文斯坦(levenshtein·vladimir)在1965年提出。levenshteindistance指两个字串之间,由一个转换成另一个所需的最少编辑操作次数,允许的编辑操作包括:●将其中一个字符替换成另一个字符(substitutions)。●插入一个字符(insertions)。●删除一个字符(deletions)。levenshteindistance公式定义如果分别用a|和|b|表示a,b两个字符串的长度,那么它们的列文斯坦距离为leva,b(|a|,|b|),它符合:是-个指示函数(indicatorfunction),当ai=bj时,其值为0,其他时候它等于1。leva,b(i,j)表示a的前i个字符与b的前j个字符之间的列文斯坦距离。(i和j都是从1开始的下标)注意:min运算中的第-个公式代表(从a中)删除字符(以到达b);第二个公式代表插入字符;第三个代表替换(取决于当前字等是否相同)可以使用动态规划的方法去测量levenshteindistance(ld)的值,步骤大致如下:●初始化一个ld矩阵(m,n),m和n分别是两个输入字符串的长度。●矩阵可以从左上角到右下角进行填充,每个水平或垂直跳转分别对应于一个插入或一个删除。●通过定义每个操作的成本为1,如果两个字符串不匹配,则对角跳转的代价为1,否则为0,简单来说就是:■如果[i][j]位置的两个字符串相等,则从[i][j]位置左加1,上加1,左上加0,然后从这三个数中取出最小的值填充到[i][j]。■如果[i][j]位置的两个字符串不相等,则从[i][j]位置左、左上、上三个位置的值中取最小值,这个最小值加1(或者说这三个值都加1然后取最小值),然后填充到[i][j]。●按照上面规则ld矩阵(m,n)填充完毕后,最终矩阵右下角的数字就是两个字符串的ld值。3)文件上传日期间隔在文件名相似度高的前提下,一个客户上传了10次bom文件,日期时间如下:算法发现每次上传间隔小于3天,因此判定可以分为一组。在文件名相似度高的前提下,另一个客户上传了3次,日期时间如下:上传间隔都大于3天,因此需要分为3组。4)物料清单明细相似度实际场景中的修改bom:第1版物料清单,客户提交的原始版本如下表:参数型号cap,mlcc,x5r,4.7uf,6.3vcap,mlcc,x5r,470nf,10v销售和客户沟通后完善参数、型号的第2版如下表:参数型号cap,mlcc,x5r,4.7uf,6.3v,±10%,0603cl10a475kq8nnwccap,mlcc,x5r,470nf,10v,±10%,0402grm155r61a474ke15j由于这是一个和客户沟通完善物料清单的过程,所以第1版和第2版都是同一个产品的物料清单。除了修改条目之外,客户还可能因为商品供应的原因增加或者删除物料清单条目,以便使物料清单表明下单意向。增删条目后还应该算作同一个产品的物料清单,因为背后对应的客户产品没有变,只是采购的范围变了。5)结论只有用户id分组、文件名相似度、文件上传日期间隔、物料清单明细相似度都分为1组,才能判定这些bom是同一个产品的物料清单。以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1