基于NLP的行业政策信息处理方法、装置、设备及介质与流程
【技术领域】
本发明涉及数据处理技术领域,尤其涉及一种基于nlp的行业政策信息处理方法、装置、设备及介质。
背景技术:
随着大数据技术的发展,对各类型数据的具体分析在各方面有着重要影响,以政府发布的各项监管政策为例,由于政府对经济社会发展起着重要宏观调控作用,政府包括很多的职能机构,每个职能机构每一次发布的行业政策信息,都会对行业、企业以及产品产生一定程度的影响,短期可对行业发展产生冲击效应,长期可引领行业发展方向,对资产配置、行业发展预测等具有重要指导意义。
对于政府各项行业政策信息,现有技术的处理方式能实现的是政策文本的获取与管理,具体的影响范围,一般需要通过分析者对政策文件的层层解读与分析才能得到,数据分析效率不高,数据分析准确性不高。
技术实现要素:
本发明的目的在于提供一种基于nlp的行业政策信息处理方法、装置、设备及介质,以解决现有技术中数据分析效率低以及数据分析准确性低的技术问题。
本发明的技术方案如下:提供一种基于nlp的行业政策信息处理方法,包括:
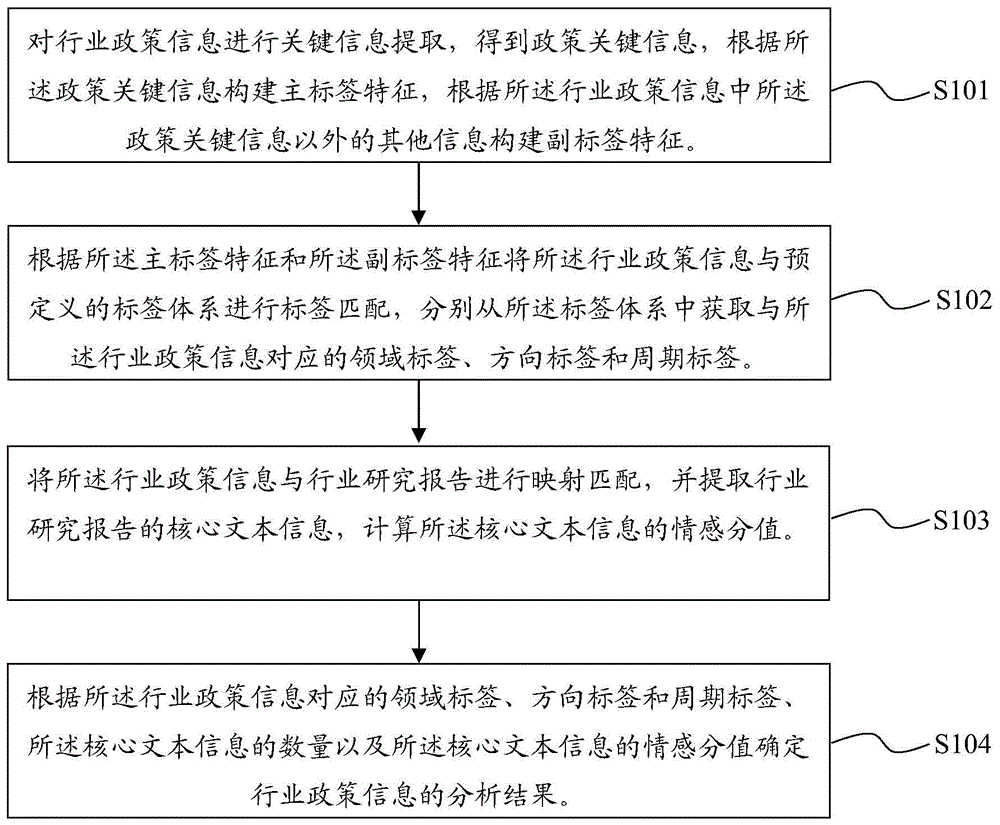
对行业政策信息进行关键信息提取,得到政策关键信息,根据所述政策关键信息构建主标签特征,根据所述行业政策信息中所述政策关键信息以外的其他信息构建副标签特征;
根据所述主标签特征和所述副标签特征将所述行业政策信息与预定义的标签体系进行标签匹配,分别从所述标签体系中获取与所述行业政策信息对应的领域标签、方向标签和周期标签,其中,所述标签体系包括领域标签组、方向标签组以及周期标签组;
将所述行业政策信息与行业研究报告进行映射匹配,并提取行业研究报告的核心文本信息,计算所述核心文本信息的情感分值;
根据所述行业政策信息对应的领域标签、方向标签和周期标签、所述核心文本信息的数量以及所述核心文本信息的情感分值确定行业政策信息的分析结果。
优选地,所述对行业政策信息进行关键信息提取,得到政策关键信息,根据所述政策关键信息构建主标签特征,根据所述行业政策信息中所述政策关键信息以外的其他信息构建副标签特征,包括:
获取所述行业政策信息的高频词和关键词,确定所述高频词和所述关键词中均包括的交集词汇;
获取所述行业政策信息的关键短语和关键句;
获取所述行业政策信息中以大写数字或小写数字开头的核心语句;
根据所述高频词和所述关键词的交集词汇、所述关键短语、所述关键句和所述核心语句构建所述主标签特征;
将所述高频词和所述关键词的交集词汇和所述关键短语所在的语句、所述关键句和所述核心语句分别从所述行业政策信息中剔除,根据剩余段落构建所述副标签特征。
优选地,在预定义的标签体系中,所述领域标签组为领域标签树,所述领域标签树包括多个根节点,每个所述根节点包括至少一层子节点,所述领域标签树中每个节点对应一个领域标签;所述方向标签组为方向标签树,所述方向标签树包括多个根节点,每个根节点对应一个方向标签;所述周期标签组为周期标签树,所述周期标签树包括多个根节点,每个根节点对应一个周期标签;
所述根据所述主标签特征和所述副标签特征将所述行业政策信息与预定义的标签体系进行标签匹配,分别从所述标签体系中获取与所述行业政策信息对应的领域标签、方向标签和周期标签,包括:
将所述主标签特征和所述副标签特征从所述根节点开始与领域标签树中各节点的领域标签进行匹配;
当匹配失败时,将当前节点的上一层节点对应的领域标签输出,作为所述行业政策信息对应的领域标签;
当匹配成功时,将所述主标签特征和所述副标签特征继续与当前节点的下一层节点的领域标签进行匹配,直至所述领域标签树的顶层节点;
将所述主标签特征与所述方向标签树中各根节点标签进行匹配,确定所述行业政策信息对应的方向标签;
将所述主标签特征与所述周期标签树中各根节点标签进行匹配,确定所述行业政策信息对应的周期标签。
优选地,所述领域标签对应设有至少一类正向关键词组以及至少一类过滤关键词组,每类正向关键词组对应设有多个正向关键词,每类过滤关键词组对应设有多个过滤关键词;
相应地,所述将所述主标签特征和所述副标签特征从所述根节点开始与领域标签树中各节点的领域标签进行匹配,包括:
将所述主标签特征和所述副标签特征与所述领域标签的每类正向关键词组的多个正向关键词进行匹配,当匹配成功的正向关键词的数量大于或等于预设数量阈值时,所述行业政策信息与所述正向关键词组匹配;
将所述主标签特征和所述副标签特征与所述领域标签的每类过滤关键词组的多个过滤关键词进行匹配,当匹配成功的过滤关键词的数量小于所述预设数量阈值时,所述行业政策信息与所述过滤关键词组不匹配;
当所述行业政策信息与每类所述正向关键词组均匹配且所述行业政策信息与每类所述过滤关键词组均不匹配时,所述行业政策信息与对应的所述领域标签匹配。
优选地,所述方向标签或所述周期标签对应设有至少一类正向关键词组,每个正向关键词组对应设有多个正向关键词;
相应地,所述将所述主标签特征与所述方向标签树中各根节点标签进行匹配,确定所述行业政策信息对应的方向标签,包括:
将所述主标签特征与所述方向标签的每类正向关键词组的多个正向关键词进行匹配,当匹配成功的正向关键词的数量大于或等于预设数量阈值时,所述行业政策信息与所述正向关键词组匹配;
当所述行业政策信息与每类所述正向关键词组均匹配时,所述行业政策信息与对应的所述方向标签匹配;
相应地,所述将所述主标签特征与所述周期标签树中各根节点标签进行匹配,确定所述行业政策信息对应的周期标签,包括:
将所述主标签特征与所述周期标签的每类正向关键词组的多个正向关键词进行匹配,当匹配成功的正向关键词的数量大于或等于预设数量阈值时,所述行业政策信息与所述正向关键词组匹配;
当所述行业政策信息与每类所述正向关键词组均匹配时,所述行业政策信息与对应的所述周期标签匹配。
优选地,所述将所述行业政策信息与行业研究报告进行映射匹配,并提取行业研究报告的核心文本信息,包括:
对所述行业政策信息的政策标题进行实体识别,去除所述政策标题中的实体,得到政策主题;
将所述政策主题在所述行业研究报告中进行模糊匹配,将匹配成功的所述行业研究报告与所述行业政策信息建立映射关系;
将所述政策主题在匹配成功的所述行业研究报告的正文中进行定位,提取定位处、位于定位处之前的第一预设数量句以及位于定位处之后的第二预设数量句作为待选核心内容;
提取所述待选核心内容中与所述政策主题相关的部分,将所提取的相关的部分作为所述核心文本信息。
优选地,所述计算所述核心文本信息的情感分值,包括:
分别对所述核心文本信息中的情绪词、程度词和否定词进行识别,根据识别结果确定所述程度词相对于所述情绪词的位置以及所述否定词相对于所述情绪词的位置;
根据所述程度词相对于所述情绪词的位置确定程度词权重,根据所述否定词相对于所述情绪词的位置确定否定词权重;
统计所述核心文本信息中积极情绪词的出现频率以及消极情绪词的出现频率;
根据积极情绪词权重、消极情绪词权重、所述程度词权重、所述否定词权重以及所述积极分词的出现频率和所述消极分词的出现频率,计算所述核心文本信息的情感分值;
当所述核心文本信息的数量为多个时,计算多个所述核心文本信息的情感分值的加权平均值,作为所述核心文本信息的最终情感分值。
本发明的另一技术方案如下:提供一种基于nlp的行业政策信息处理装置,包括:
特征提取模块,用于对行业政策信息进行关键信息提取,得到政策关键信息,根据所述政策关键信息构建主标签特征,根据所述行业政策信息中所述政策关键信息以外的其他信息构建副标签特征;
第一处理模块,用于根据所述主标签特征和所述副标签特征将所述行业政策信息与预定义的标签体系进行标签匹配,分别从所述标签体系中获取与所述行业政策信息对应的领域标签、方向标签和周期标签,其中,所述标签体系包括领域标签组、方向标签组以及周期标签组;
第二处理模块,用于将所述行业政策信息与行业研究报告进行映射匹配,并提取行业研究报告的核心文本信息,计算所述核心文本信息的情感分值;以及
结果输出模块,用于根据所述行业政策信息对应的领域标签、方向标签和周期标签、所述核心文本信息的数量以及所述核心文本信息的情感分值确定行业政策信息的分析结果。
本发明的另一技术方案如下:提供一种电子设备,包括处理器、以及与所述处理器耦接的存储器,所述存储器存储有可被所述处理器执行的程序指令;所述处理器执行所述存储器存储的所述程序指令时实现上述的基于nlp的行业政策信息处理方法。
本发明的另一技术方案如下:提供一种存储介质,所述存储介质内存储有程序指令,所述程序指令被处理器执行时实现能够实现上述的基于nlp的行业政策信息处理方法。
本发明的有益效果在于:本发明的基于nlp的行业政策信息处理方法、装置、设备及介质,通过构建行业政策信息的主标签特征和副标签特征,根据主标签特征和副标签特征将所述行业政策信息与预先设置的标签体系进行匹配,分别得到领域标签、方向标签和周期标签;将所述行业政策信息与行业研究报告进行映射匹配,提取行业研究报告中与所述行业政策信息相关的核心文字信息,进行情感分值计算;再根据领域标签、方向标签、周期标签和情感分值输出结果;通过上述方式,提高了数据分析效率,并且充分挖掘行业政策信息自身属性特征以及行业研究报告共同实现了行业政策信息影响力领域、周期、大小和方向的多维度分析,并实现了影响力大小的量化,提高了行业政策信息的数据分析准确性。
【附图说明】
图1为本发明第一实施例的基于nlp的行业政策信息处理方法的流程图;
图2为本发明第一实施例的基于nlp的行业政策信息处理方法中步骤s101的子步骤的流程图;
图3为本发明第一实施例的基于nlp的行业政策信息处理方法中步骤s102的子步骤的流程图;
图4为本发明第一实施例的基于nlp的行业政策信息处理方法中步骤s103的子步骤的流程图;
图5为本发明第二实施例的基于nlp的行业政策信息处理装置的结构示意图;
图6为本发明第三实施例的电子设备的结构示意图;
图7为本发明第四实施例的存储介质的结构示意图。
【具体实施方式】
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明中的术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”、“第三”的特征可以明示或者隐含地包括至少一个该特征。本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。本发明实施例中所有方向性指示(诸如上、下、左、右、前、后……)仅用于解释在某一特定姿态(如附图所示)下各部件之间的相对位置关系、运动情况等,如果该特定姿态发生改变时,则该方向性指示也相应地随之改变。此外,术语“包括”和“具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。
在本文中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本发明的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本文所描述的实施例可以与其它实施例相结合。
图1为本发明第一实施例的基于nlp的行业政策信息处理方法的流程示意图。需注意的是,若有实质上相同的结果,本发明的方法并不以图1所示的流程顺序为限。如图1所示,该基于nlp的行业政策信息处理方法包括步骤:
s101,对行业政策信息进行关键信息提取,得到政策关键信息,根据所述政策关键信息构建主标签特征,根据所述行业政策信息中所述政策关键信息以外的其他信息构建副标签特征。
其中,行业政策信息可以为行业监管政策文本,例如,为2020年2月20日发布的《关于做好2020年短期出口信用保险相关工作全力支持外贸企业应对新冠肺炎疫情影响的通知》;又如,为《国务院关于保险业改革发展的若干意见》。
其中,所述主标签特征用于表征所述政策信息的核心内容,代表了该政策的核心属性。所述副标签特征用于表征所述政策信息的重要但非核心内容,可用于构建该政策与其他政策的联系。例如,一个关于规范保险资金运用的政策,提到如果偿付能力达到一定要求,就可以用某种方式运用资金。这个政策的主标签特征就包括资金运用,而副标签特征就包括偿付能力,说明该政策可能需要与主标签特征为偿付能力的政策结合起来解读。
其中,主标签特征和副标签特征均为特征文本。
s102,根据所述主标签特征和所述副标签特征将所述行业政策信息与预定义的标签体系进行标签匹配,分别从所述标签体系中获取与所述行业政策信息对应的领域标签、方向标签和周期标签,其中,所述标签体系包括领域标签组、方向标签组以及周期标签组。
其中,在预定义的标签体系中,所述领域标签组为领域标签树,所述领域标签树包括多个根节点,每个所述根节点包括至少一层子节点,所述领域标签树中每个节点对应一个领域标签;所述方向标签组为方向标签树,所述方向标签树包括多个根节点,每个根节点对应一个方向标签;所述周期标签组为周期标签树,所述周期标签树包括多个根节点,每个根节点对应一个周期标签。具体地,领域标签树包括若干根节点(第一层,每个根节点对应一个根节点领域标签),每个根节点包括至少一个第一子节点(第二层,每个第一子节点对应一级子节点领域标签),每个第一子节点包括至少一个第二子节点(第三层,每个第二子节点对应二级子节点领域标签),依次向下分层设置。方向标签树包括若干根节点(第一层,每个根节点对应一个方向标签),周期标签数包括若干根节点(第一层,每个根节点对应一个周期标签)。
所述领域标签用于表征所述行业政策信息的政策对象,政策对象可能为业务、公司及产品,下面以保险行业政策信息以及三层次的领域标签树为例进行详细说明,领域标签树种中,第一层领域标签为人身险产品(tag1-1)、财产险产品(tag1-2);进一步地,对于人身险产品(tag1-1)还可以继续设置子标签,例如,人身险产品的销售(tag2-1)、人身险产品的赔付(tag2-2);进一步地,对于人身险产品的销售(tag2-1)也可以继续设置子标签,例如,人身险产品的线上销售(tag3-1)、人身险产品的电话销售(tag3-2)以及人身险产品的面销(tag3-3),根据不同场景,可持续细分至tagm-k(m=4,5...,k=1,2...)。
在本实施例的标签体系中,所述领域标签对应设有至少一类正向关键词组以及至少一类过滤关键词组,每类正向关键词组对应设有多个正向关键词,每类过滤关键词组对应设有多个过滤关键词;领域标签的关键字用于与主标签特征和副标签特征基于标签判定规则进行匹配,进而判断所述行业政策信息是否属于当前的领域标签。
所述方向标签对应设有至少一类正向关键词组,每个正向关键词组对应设有多个正向关键词,方向标签的关键字用于与主标签特征基于标签判定规则进行匹配,进而判断所述行业政策信息是否属于当前的方向标签。
所述周期标签对应设有至少一类正向关键词组,每个正向关键词组对应设有多个正向关键词,周期标签的关键字用于与主标签特征基于标签判定规则进行匹配,进而判断所述行业政策信息是否属于当前的方向标签。
s103,将所述行业政策信息与行业研究报告进行映射匹配,并提取行业研究报告的核心文本信息,计算所述核心文本信息的情感分值。
其中,行业研究报告通过对特定行业的长期跟踪监测,分析行业需求、供给、经营特性、获取能力、产业链和价值链等多方面的内容,整合行业、市场、企业、用户等多层面数据和信息资源,为客户提供深度的行业市场研究报告,以专业的研究方法帮助客户深入的了解行业,发现投资价值和投资机会,规避经营风险,提高管理和运营能力。行业研究报告中的与政策相匹配的核心内容,包含政策对行业影响的重要信息。
其中,核心内容为所述行业研究报告中与所述行业政策信息进行模糊匹配得到的文本信息,利用该文本信息作为后续分析的对象。
其中,核心文本信息的数量可以为一个或多个,每个核心文本信息对应一个行业研究报告。
其中,针对每个核心文本信息计算对应的情感分值。
具体地,核心文本信息按照如下步骤获取:
步骤s1031,对所述行业政策信息的政策标题进行实体识别,去除所述政策标题中的实体,得到政策主题;
其中,所述实体可以为职业名称、机构名称、人名、地名、商品名称以及一些专有名称等等。可选的,可以采用任意的方法对中文文本进行实体识别处理,只要能够识别出中文文本中的实体即可。例如,可以基于paddle框架、spacy源等等。
其中,实体识别还需要基于自定义组织机构库进行二次精准识别,组织机构库包括全国及各地方省市的机构、部委、地方部门等全称、简称,基于模糊匹配技术进行二次识别。
s1032,将所述政策主题在所述行业研究报告中进行模糊匹配,将匹配成功的所述行业研究报告与所述行业政策信息建立映射关系;
本步骤中,可以通过与数据库中存储的行业研究报告的摘要或目录进行模糊匹配,来建立行业研究报告和行业政策信息的映射关系。
s1033,将所述政策主题在匹配成功的所述行业研究报告的正文中进行定位,提取定位处、位于定位处之前的第一预设数量句以及位于定位处之后的第二预设数量句作为待选核心内容;
其中,将所述政策主题作为正则匹配文本在所述行业研究报告的正文中进行查找定位,在正文中查找到政策主题后,对政策主题进行定位,提取待选主题核心内容:
其中,ri,j第j处定位索引为i的主题相关内容。
s1034,提取所述待选核心内容中与所述政策主题相关的部分,将所提取的相关的部分作为所述核心文本信息;
其中,基于所述待选核心内容中与所述政策主题相关的部分,进行二次提取;具体地,针对待选核心内容中的每个分句,判断该分句是否与政策主题相关;当判断结果为是时,将所述分句作为与所述政策主题相关的部分;当判断结果为否时,所述分句与政策主题不相关,从核心内容中剔除。
具体地,计算所述核心文本信息的情感分值的步骤如下:
s1035,分别对所述核心文本信息中的情绪词、程度词和否定词进行识别,根据识别结果确定所述程度词相对于所述情绪词的位置以及所述否定词相对于所述情绪词的位置;
其中,利用预先构建的情绪词词典、程度词词典和否定词词典对所述核心文本信息中的情绪词、程度词和否定词分别进行识别,对识别出的情绪词、程度词和否定词在所述核心文本信息中进行标记定位。
利用分词技术和计算机统计算法初步建立情绪词词典,并赋予每个情绪词一定情感极性权重,权重分正负,越大表示正面感情越强烈,无感情则情感值为0。
搜集程度修饰词语构建程度词词典,将程度词根据修饰的程度分为极高、高度、中度、轻度四个级别,每个级别的程度值不同,例如,极高程度词的程度值为2、高度程度词的程度值为1.75、中度程度词的程度值为1.5、轻度程度词的程度值为0.75。
s1036,根据所述程度词相对于所述情绪词的位置确定程度词权重,根据所述否定词相对于所述情绪词的位置确定否定词权重;
其中,程度词权重为wd,
其中,degree_value为程度词的权重值,sen_locs为情绪词定位值,degree_locs为程度词定位值。
否定词权重为wn,
其中,sen_locs为情绪词定位值,not_locs为否定词定位值。
s1037,统计所述核心文本信息中积极情绪词的出现频率以及消极情绪词的出现频率;
s1038,根据积极情绪词权重、消极情绪词权重、所述程度词权重、所述否定词权重以及所述积极分词的出现频率和所述消极分词的出现频率,计算所述核心文本信息的情感分值;
情感分值按照以下公式计算:
score=(sp·fp+sn·fn)/(fp+fn)
其中,sp=wsp·wd·wn;sn=wsn·wd·wn;wsp为积极情绪词权重;wsn为消极情绪词权重。
s1039,当所述核心文本信息的数量为多个时,计算多个所述核心文本信息的情感分值的加权平均值,作为所述核心文本信息的最终情感分值;
其中,可以为每个行业研究报告设置一个权重,核心文本信息的权重与对应的行业研究报告的权重一致。
s104,根据所述行业政策信息对应的领域标签、方向标签和周期标签、所述核心文本信息的数量以及所述核心文本信息的情感分值确定行业政策信息的分析结果。
其中,分析结果包括四个维度,分别为领域维度、方向维度、大小维度和周期维度;领域标签表征所述行业政策信息的影响领域,例如,业务、公司或产品;方向标签表征所述行业政策信息的影响方向,例如,积极、消极或中性;周期标签表征所述行业政策信息的影响周期,例如,长期、中期或短期;所述核心文本信息的情感分值的大小表征所述行业政策信息的影响大小,例如,重大,一般,无影响;所述核心文本信息的情感分值的正负表征所述行业政策信息的影响方向,例如,积极、消极或中性。
其中,根据所述核心文本信息的数量确定所述行业政策信息在行业研究报告中的热度,体现其影响力的大小。
其中,领域维度由领域标签确定;方向维度由方向标签和所述核心文本信息的情感分值的正负共同确定;大小维度由所述核心文本信息的情感分值的大小以及核心文本信息的数量共同确定;周期维度由周期标签确定。
对于大小维度,可以直接输出情感分值的绝对值和核心文本信息的数量;也可以为情感分值和核心文本信息的数量分别设置影响评分标准,根据感情分值的绝对值获得第一评分,根据核心文本信息的数量获取第二评分,计算第一评分和第二评分的加权平均值,当该加权平均值大于或等于第一分数阈值时,为重大;当该加权平均值小于或等于第二分数阈值时,为无影响;当该加权平均值大于第二分数阈值且小于第一分数阈值时,为一般。
对于方向维度,可以为方向标签和情感分值分别设置影响权重,当方向标签与核心文本信息的情感分值的正负结果一致时,直接输出该一致的结果,例如,方向标签为积极,情感分值为正,则方向维度的结果为积极。当方向标签与核心文本信息的情感分值的正负结果不一致时,输出影响权重较大的结果并对该结果进行标记,例如,方向标签为积极,情感分值为负,方向标签的影响权重大则输出积极,情感分值的权重大则输出消极,将结果进行标记以提醒用户此处两个判断方式结果不一致。
在一个可选的实施方式中,主标签特征由高频词、关键词、关键语句、关键句及核心句共同构建,请参阅图2所示,步骤s101具体通过如下步骤s1021至步骤s1025实现:
s1011,获取所述行业政策信息的高频词和关键词,确定所述高频词和所述关键词中均包括的交集词汇;
其中,对所述行业政策信息进行分词处理,分词处理可以利用现有开源的分词工具,例如pyltp、snownlp等等,可以将文本信息拆分为以字或词为单位的多个词组。
其中,分词处理后,统计所述行业政策信息中每个分词的出现频率,按照以下方式筛选高频词汇信息:当f大于或等于第一预设阈值时,或当fp大于或等于第二预设阈值时,确定对应分词为高频词,其中,f为词频,fp为频率/有效词频总量,第一预设阈值和第二预设阈值根据实际应用需求进行确定。其中,分词处理后,基于tf-idf计算得到每个分词的重要度。
具体地,tf-idf(termfrequency-inversedocumentfrequency,词频-逆向文件频率)是一种用于信息检索与数据挖掘的常用加权技术。tf意思是词频(termfrequency),idf意思是逆文本频率指数(inversedocumentfrequency)。tf-idf用于评估一个字词对于一个语料库中的一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。具体的,tf的计算公式为
其中,交集词汇为既属于高频词又属于关键词的词汇。
s1012,获取所述行业政策信息的关键短语和关键句;
其中,关键短语采用凝练简洁的形式表示文本主题信息的词序列,具有强文本特性,能够鲜明的表示出文本的内容特性。一般文本中的文本信息的信息量是巨大的,因此,为了能够快速确定中文本文的要义信息,还需要对中文文本进行关键短语提取。
关键短语和关键句均可以通过textrank算法提取。
其中,提取关键短语时,首先提取权重词,过程为首先进行分句处理,然后分词并去除异常字符、语气词等无效词汇,在长度为k的窗口中计算单词共现关系,构建无向的共现关系图,一般k≤10,按照以下方法计算单词重要性:
其中,in(vi)为vi所在共现窗口中单词集合,d为阻尼系数,wi,j为vi、vj链接关系权重,
对wi进行排序,提取前mv个权重词,然后基于n-gram模型抽取nkw个权重词构建关键短语。
提取关键句时,首先,使用word2vec或bert结合行业语料训练词向量模型,计算得到所述行业政策信息的任意两个句子之间的欧式距离ds,按照以下方法计算句子重要性:
其中,in(ssi)为ssi所在共现窗口中语句集合,di,j为ssi、ssj链接关系权重,
s1013,获取所述行业政策信息中以大写数字或小写数字开头的核心语句;
其中,采用正则匹配的方式在行业政策信息中匹配大写数字或小写数字,进行分句处理后,提取大写数字或小写数字之后的语句作为核心语句。
s1014,根据所述高频词和所述关键词的交集词汇、所述关键短语、所述关键句和所述核心语句构建所述主标签特征;
具体组合方式为:
s主标签特征=st+skw∩shw+skp+sks+scs
其中,st为标题内容,skw为关键词信息,shw为高频词信息,skp为关键短语,sks为关键句,scs为核心语句。
其中,主标签特征具有冗余信息,保证能够对政策文本信息中的核心内容进行全面覆盖。
其中,可以将词汇信息(交集词汇)、关键短语、关键句和核心语句直接组合得到主标签特征;或者,也可以将词汇信息(交集词汇)、关键短语、关键句和核心语句进行重新整合形成第一核心文本,将所述第一核心文本作为主标签特征;或者,还可以将交集词汇(交集词汇)、关键短语、关键句和核心语句所在段落进行拼接,形成第二核心文本,将所述第二核心文本作为主标签特征。
s1015,将所述高频词和所述关键词的交集词汇和所述关键短语所在的语句、所述关键句和所述核心语句分别从所述行业政策信息中剔除,根据剩余段落构建所述副标签特征;
其中,剔除了交集词汇、关键短语、关键句和核心语句所在段落后,剩余的为不包括核心内容的语句,将剩余语句直接作为副标签特征。例如,将没有提取上述关键内容的整段文本或
请参阅图3所示,步骤s102具体通过如下步骤s1021至步骤s1025实现:
s1021,将所述主标签特征和所述副标签特征从所述根节点开始与领域标签树中各节点的领域标签进行匹配;
s1022,当匹配失败时,将当前节点的上一层节点对应的领域标签输出,作为所述行业政策信息对应的领域标签;
s1023,当匹配成功时,将所述主标签特征和所述副标签特征继续与当前节点的下一层节点的领域标签进行匹配,直至所述领域标签树的顶层节点;
在步骤s1021至步骤s1023中,在进行领域标签匹配时,首先,将所述主标签特征和所述副标签特征与领域标签树中各根节点标签进行匹配,确定所述行业政策信息对应的根节点标签;然后,将所述主标签特征和所述副标签特征与所述根节点标签的各一级子节点标签进行匹配;当匹配失败时,将所述根节点标签作为所述行业政策信息的领域标签;当匹配成功时,确定所述行业政策信息对应的一级子节点标签;然后,继续将所述主标签特征和所述副标签特征与所述一级子节点标签的各二级子节点标签进行匹配;当匹配失败时,将所述一级子节点标签作为所述行业政策信息的领域标签;当匹配成功时,确定所述行业政策信息对应的二级子节点标签;然后,继续将所述主标签特征和所述副标签特征与下一级子节点标签进行匹配,直至所述标签树的顶层子节点,将匹配上的最上层子节点对应的子节点标签作为所述行业政策信息的领域标签。
也就是说,在进行领域标签匹配时,层间进行递进判定,只有当tm,k=1时,进行tagm-k标签判定:
在步骤s1021和步骤s1023中,领域标签的标签判定规则如下:将所述主标签特征和所述副标签特征与所述领域标签的每类正向关键词组的多个正向关键词进行匹配,当匹配成功的正向关键词的数量大于或等于预设数量阈值时,所述行业政策信息与所述正向关键词组匹配;将所述主标签特征和所述副标签特征与所述领域标签的每类过滤关键词组的多个过滤关键词进行匹配,当匹配成功的过滤关键词的数量小于所述预设数量阈值时,所述行业政策信息与所述过滤关键词组不匹配;当所述行业政策信息与每类所述正向关键词组均匹配且所述行业政策信息与每类所述过滤关键词组均不匹配时,所述行业政策信息与对应的所述领域标签匹配。其中,预设数量阈值可以为1或2。
具体地,在本实施例的标签体系中,每个领域标签tagm-k,包含关键字kw1,kw2,kw3,……,kwn(第一类关键字组,正向),关键字kvl,kv2,kv3,……,kvn(第二类关键字组,正向),关键字kn1,kn2,kn3,……,knn(第三类关键字组,过滤)。判断所述行业政策信息与当前的领域标签-人身险产品的电话销售(tag3-2)是否匹配时,判断主标签特征和副标签特征是否满足如下条件之一:
logic_1=(kw1|kw2|...)&(kv1|kv2|...)not(kn1|kn2|...)
logic_2=(sum(kw)≥q)&(sum(kv)≥q)not(sum(kn)≥q),(q=2)
当主标签特征和副标签特征满足logic_1或logic_2时,说明行业政策信息与对应的领域标签匹配。上述的tag3-2为人身险产品的电话销售,kw1为电话,kw2为手机,kw3为座机;kv1为销售,kv2为卖,kv3为出售;kn1为汽车,kn2为信用卡,kn3为游戏;以logic1为例,主标签特征和副标签特征与关键字kw1,kw2,kw3中的至少一项匹配,与关键字kv1,kv2,kv3中的至少一项匹配,不包括关键字kn1,kn2,kn3中的任何一个,即可判断主标签特征和副标签特征与标签tag3-2是匹配的,所述行业政策信息对应标签tag3-2。
s1024,将所述主标签特征与所述方向标签树中各根节点标签进行匹配,确定所述行业政策信息对应的方向标签;
在步骤s1024中,方向标签的标签判定规则如下:将所述主标签特征与所述方向标签的每类正向关键词组的多个正向关键词进行匹配,当匹配成功的正向关键词的数量大于或等于预设数量阈值时,所述行业政策信息与所述正向关键词组匹配;当所述行业政策信息与每类所述正向关键词组均匹配时,所述行业政策信息与对应的所述方向标签匹配。进一步地,预设数量阈值为1或2。
在本实施例中,方向标签树包括三个根节点,分别为积极、消极和中性;每个根节点的标签设置有关键字,例如,“积极”的关键词可以包括“利好”、“利于”、“利多”、“受益”。在进行方向标签匹配时,只需要利用主标签特征,无需利用副标签特征。具体地,每个方向标签设有关键字kw1,kw2,……,kwn,方向标签判定规则为logic_1或logic_2:
logic_1:(kw1|kw2|...),logic_2=(sum(kw)≥q),(q=2),其中,kw∈l(n)_k1,n=1,2,3。当主标签特征满足logic_1或logic_2时,说明行业政策信息与对应的方向标签匹配。
s1025,将所述主标签特征与所述周期标签树中各根节点标签进行匹配,确定所述行业政策信息对应的周期标签;
在步骤s1025中,周期标签的标签判定规则如下:将所述主标签特征与所述周期标签的每类正向关键词组的多个正向关键词进行匹配,当匹配成功的正向关键词的数量大于或等于预设数量阈值时,所述行业政策信息与所述正向关键词组匹配;当所述行业政策信息与每类所述正向关键词组均匹配时,所述行业政策信息与对应的所述周期标签匹配。进一步地,预设数量阈值为1或2。
在本实施例中,周期标签树包括三个根节点,分别为长期、中期和短期;每个根节点的标签设置有关键字,例如,“长期”的关键词可以包括“长远”、“二十年”、“长期”、“三十年”、“数十年”。在进行周期标签匹配时,只需要利用主标签特征,无需利用副标签特征。具体地,每个周期标签设有关键字kw1,kw2,……,kwn,周期标签判定规则为logic_1或logic_2:
logic_1:(kw1|kw2|...),logic_2=(sum(kw)≥q),(q=2),其中,kw∈l(n)_k1,n=1,2,3。当主标签特征满足logic_1或logic_2时,说明行业政策信息与对应的周期标签匹配。
在一个可选的实施方式中,在步骤s104之后,还包括如下步骤:
s105,将所述分析结果上传至区块链中,以使得所述区块链对所述分析结果进行加密存储。
在步骤s105中,基于所述分析结果得到对应的摘要信息,具体来说,摘要信息由所述分析结果进行散列处理得到,比如利用sha256s算法处理得到。将摘要信息上传至区块链可保证其安全性和对用户的公正透明性。用户设备可以从区块链中下载得该摘要信息,以便查证所述分析结果是否被篡改。本示例所指区块链是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。区块链(blockchain),本质上是一个去中心化的数据库,是一串使用密码学方法相关联产生的数据块,每一个数据块中包含了一批次网络交易的信息,用于验证其信息的有效性(防伪)和生成下一个区块。区块链可以包括区块链底层平台、平台产品服务层以及应用服务层等。
图5是本发明第二实施例的基于nlp的行业政策信息处理装置的结构示意图。如图5所示,该装置50包括特征提取模块51、第一处理模块52、第二处理模块53以及结果输出模块54,其中,特征提取模块51,用于对行业政策信息进行关键信息提取,得到政策关键信息,根据所述政策关键信息构建主标签特征,根据所述行业政策信息中所述政策关键信息以外的其他信息构建副标签特征;第一处理模块52,用于根据所述主标签特征和所述副标签特征将所述行业政策信息与预定义的标签体系进行标签匹配,分别从所述标签体系中获取与所述行业政策信息对应的领域标签、方向标签和周期标签,其中,所述标签体系包括领域标签组、方向标签组以及周期标签组;第二处理模块53,用于将所述行业政策信息与行业研究报告进行映射匹配,并提取行业研究报告的核心文本信息,计算所述核心文本信息的情感分值;结果输出模块54,用于根据所述行业政策信息对应的领域标签、方向标签和周期标签、所述核心文本信息的数量以及所述核心文本信息的情感分值确定行业政策信息的分析结果。
进一步地,特征提取模块51还用于获取所述行业政策信息的高频词和关键词,确定所述高频词和所述关键词中均包括的交集词汇;获取所述行业政策信息的关键短语和关键句;获取所述行业政策信息中以大写数字或小写数字开头的核心语句;根据所述高频词和所述关键词的交集词汇、所述关键短语、所述关键句和所述核心语句构建所述主标签特征;将所述高频词和所述关键词的交集词汇和所述关键短语所在的语句、所述关键句和所述核心语句分别从所述行业政策信息中剔除,根据剩余段落构建所述副标签特征。
进一步地,在预定义的标签体系中,所述领域标签组为领域标签树,所述领域标签树包括多个根节点,每个所述根节点包括至少一层子节点,所述领域标签树中每个节点对应一个领域标签;所述方向标签组为方向标签树,所述方向标签树包括多个根节点,每个根节点对应一个方向标签;所述周期标签组为周期标签树,所述周期标签树包括多个根节点,每个根节点对应一个周期标签。第一处理模块52还用于将所述主标签特征和所述副标签特征从所述根节点开始与领域标签树中各节点的领域标签进行匹配;当匹配失败时,将当前节点的上一层节点对应的领域标签输出,作为所述行业政策信息对应的领域标签;当匹配成功时,将所述主标签特征和所述副标签特征继续与当前节点的下一层节点的领域标签进行匹配,直至所述领域标签树的顶层节点;将所述主标签特征与所述方向标签树中各根节点标签进行匹配,确定所述行业政策信息对应的方向标签;将所述主标签特征与所述周期标签树中各根节点标签进行匹配,确定所述行业政策信息对应的周期标签。
进一步地,所述领域标签对应设有至少一类正向关键词组以及至少一类过滤关键词组,每类正向关键词组对应设有多个正向关键词,每类过滤关键词组对应设有多个过滤关键词。第一处理模块52还用于将所述主标签特征和所述副标签特征与所述领域标签的每类正向关键词组的多个正向关键词进行匹配,当匹配成功的正向关键词的数量大于或等于预设数量阈值时,所述行业政策信息与所述正向关键词组匹配;将所述主标签特征和所述副标签特征与所述领域标签的每类过滤关键词组的多个过滤关键词进行匹配,当匹配成功的过滤关键词的数量小于所述预设数量阈值时,所述行业政策信息与所述过滤关键词组不匹配;当所述行业政策信息与每类所述正向关键词组均匹配且所述行业政策信息与每类所述过滤关键词组均不匹配时,所述行业政策信息与对应的所述领域标签匹配。
进一步地,所述方向标签或所述周期标签对应设有至少一类正向关键词组,每个正向关键词组对应设有多个正向关键词;第一处理模块52还用于将所述主标签特征与所述方向标签的每类正向关键词组的多个正向关键词进行匹配,当匹配成功的正向关键词的数量大于或等于预设数量阈值时,所述行业政策信息与所述正向关键词组匹配;当所述行业政策信息与每类所述正向关键词组均匹配时,所述行业政策信息与对应的所述方向标签匹配;将所述主标签特征与所述周期标签的每类正向关键词组的多个正向关键词进行匹配,当匹配成功的正向关键词的数量大于或等于预设数量阈值时,所述行业政策信息与所述正向关键词组匹配;当所述行业政策信息与每类所述正向关键词组均匹配时,所述行业政策信息与对应的所述周期标签匹配。
进一步地,第二处理模块53还用于对所述行业政策信息的政策标题进行实体识别,去除所述政策标题中的实体,得到政策主题;将所述政策主题在所述行业研究报告中进行模糊匹配,将匹配成功的所述行业研究报告与所述行业政策信息建立映射关系;将所述政策主题在匹配成功的所述行业研究报告的正文中进行定位,提取定位处、位于定位处之前的第一预设数量句以及位于定位处之后的第二预设数量句作为待选核心内容;提取所述待选核心内容中与所述政策主题相关的部分,将所提取的相关的部分作为所述核心文本信息。
进一步地,第二处理模块53还用于分别对所述核心文本信息中的情绪词、程度词和否定词进行识别,根据识别结果确定所述程度词相对于所述情绪词的位置以及所述否定词相对于所述情绪词的位置;根据所述程度词相对于所述情绪词的位置确定程度词权重,根据所述否定词相对于所述情绪词的位置确定否定词权重;统计所述核心文本信息中积极情绪词的出现频率以及消极情绪词的出现频率;根据积极情绪词权重、消极情绪词权重、所述程度词权重、所述否定词权重以及所述积极分词的出现频率和所述消极分词的出现频率,计算所述核心文本信息的情感分值;当所述核心文本信息的数量为多个时,计算多个所述核心文本信息的情感分值的加权平均值,作为所述核心文本信息的最终情感分值。
图6是本发明第三实施例的电子设备的结构示意图。如图6所示,该电子设备60包括处理器61及和处理器61耦接的存储器62。
存储器62存储有用于实现上述任一实施例的基于nlp的行业政策信息处理方法的程序指令。
处理器61用于执行存储器62存储的程序指令以进行基于nlp的行业政策信息处理。
其中,处理器61还可以称为cpu(centralprocessingunit,中央处理单元)。处理器61可能是一种集成电路芯片,具有信号的处理能力。处理器61还可以是通用处理器、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
参阅图7,图7为本发明第四实施例的存储介质的结构示意图。本发明第四实施例的存储介质70存储有能够实现上述所有方法的程序指令71,其中,该程序指令71可以以软件产品的形式存储在上述存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本发明各个实施方式所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质,或者是计算机、服务器、手机、平板等终端设备。
在本发明所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。以上仅为本发明的实施方式,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围。
以上所述的仅是本发明的实施方式,在此应当指出,对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出改进,但这些均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!