神经网络模型的计算方法、装置、终端及存储介质与流程
1.本技术实施例涉及计算机技术领域,特别涉及一种神经网络模型的计算方法、装置、终端及存储介质。
背景技术:
2.神经网络处理器(neural processing unit,npu)是一款人工智能芯片,其用于神经网络模型的运算。
3.在npu计算神经网络模型的过程中,由动态随机存取内存(dynamic random access memory,dram)为npu提供输入数据和输出数据的存储空间。为了满足npu对输入数据的高速读取、以及对输出数据的高速送出,可以采用增加dram传输带宽的方式或者提高dram吞吐频率的方式,以保证神经网络模型计算所需数据进出npu的速度足够快。
技术实现要素:
4.本技术实施例提供了一种神经网络模型的计算方法、装置、终端及存储介质。所述技术方案如下:
5.根据本技术的一方面内容,提供了一种神经网络模型的计算方法,所述方法包括:
6.获取神经网络模型;
7.确定所述神经网络模型在运算过程中的第一类型进度分段和第二类型进度分段,所述第一类型进度分段上网络运算所需的带宽大于带宽阈值,所述第二类型进度分段上网络运算所需的带宽小于或者等于所述带宽阈值;以及
8.通过神经网络处理器在所述第一类型进度分段上采用第一存储器存取神经网络数据,在所述第二类型进度分段上采用第二存储器存取所述神经网络数据,进行所述神经网络模型的运算,其中,所述第一存储器的存取速度大于所述第二存储器的存取速度。
9.根据本技术的另一方面内容,提供了一种神经网络模型的计算装置,所述装置包括:
10.获取模块,用于获取神经网络模型;
11.获取模块,用于获取神经网络模型;
12.确定模块,用于确定所述神经网络模型在运算过程中的第一类型进度分段和第二类型进度分段,所述第一类型进度分段上网络运算所需的带宽大于带宽阈值,所述第二类型进度分段上网络运算所需的带宽小于或者等于所述带宽阈值;
13.运算模块,用于通过神经网络处理器在所述第一类型进度分段上采用第一存储器存取神经网络数据,在所述第二类型进度分段上采用第二存储器存取所述神经网络数据,进行所述神经网络模型的运算,其中,所述第一存储器的存取速度大于所述第二存储器的存取速度。
14.根据本技术的另一方面内容,提供了一种终端,所述终端包括:
15.处理器;以及
16.存储器;其中,所述存储器上存储有程序指令,所述处理器执行所述程序指令时实现如上一个方面所述的神经网络模型的计算方法。
17.根据本技术的另一方面内容,提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有程序指令,所述程序指令被处理器执行时实现如上一个方面所述的神经网络模型的计算方法。
18.根据本技术的一个方面,提供了一种计算机程序产品,所述计算机程序产品包括计算机指令,所述计算机指令存储在计算机可读存储介质中。计算机设备的处理器从所述计算机可读存储介质读取所述计算机指令,所述处理器执行所述计算机指令,使得所述计算机设备执行如上一个方面所述的神经网络模型的计算方法。
19.本技术实施例提供的技术方案带来的有益效果可以包括:
20.本技术提供的方法是在计算神经网络模型时先确定出神经网络模型在运算过程中的第一类型进度分段和第二类型进度分段,第一类型进度分段上网络运算所需的带宽大于带宽阈值,第二类型进度分段上网络运算所需的带宽小于或者等于带宽阈值,之后使得神经网络处理器计算神经网络模型的过程中在第一类型进度分段上采用存取速度相对更快的第一存储器存取神经网络数据,在第二类型进度分段上采用存取速度相对稍慢一点儿的第二存储器,使得存储器在神经网络模型的每一个运算进度上均能满足神经网络处理器的数据吞吐量要求,充分运用神经网络处理器的运算性能,使神经网络处理器近饱和工作甚至饱和工作,解决了存储器吞吐速率不足造成的神经网络处理器的性能下降的问题。
附图说明
21.为了更清楚地介绍本技术实施例中的技术方案,下面将对本技术实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
22.图1是本技术一个示例性实施例提供的终端的结构框图;
23.图2是本技术一个示例性实施例提供的神经网络模型的计算方法的流程图;
24.图3是本技术另一个示例性实施例提供的神经网络模型的计算方法的流程图;
25.图4是本技术一个示例性实施例提供的神经网络处理器的数据存取示意图;
26.图5是本技术一个示例性实施例提供的神经网络数据传输的预估带宽的计算示意图;
27.图6是本技术一个示例性实施例提供的神经网络数据的带宽分配示意图;
28.图7是本技术一个示例性实施例提供的进度分段的示意图;
29.图8是本技术一个示例性实施例提供的神经网络模型的计算装置的结构框图。
具体实施方式
30.为使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术实施方式作进一步地详细描述。
31.下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本技术相一致的所有实施方
式。相反,它们仅是与如所附权利要求书中所详述的、本技术的一些方面相一致的装置和方法的例子。
32.为了本技术实施例所示方案易于理解,下面对本技术实施例中出现的若干名词进行介绍。
33.进度分段,是指对运算进度的分段。运算进度,是指计算一个神经网络模型的完成进度。比如,可以采用百分数来表示计算一个神经网络模型的完成进度,神经网络模型的运算进度从0%至100%,运算进度至100%时表示完成了对神经网络模型的计算。又比如,可以采用时间来表示计算一个神经网络模型的完成进度,神经网络模型的运算进度从第0秒至第t秒,运算进度至第t秒时表示完成了对神经网络模型的计算,t为正整数。
34.示例性地,本技术实施例所示的神经网络模型的计算方法,可以应用在终端中,该终端具备神经网络模型的运算功能。终端可以包括手机、平板电脑、膝上型电脑、台式电脑、电脑一体机、服务器、工作站、电视、机顶盒、智能眼镜、智能手表、数码相机、动态影像专家压缩标准音频层面4(moving picture experts group audio layer iv,mp4)播放终端、动态影像专家压缩标准音频层面5(moving picture experts group audio layer iv,mp5)播放终端、学习机、点读机、电纸书、电子词典、车载终端、虚拟现实(virtual reality,vr)播放终端或增强现实(augmented reality,ar)播放终端等。
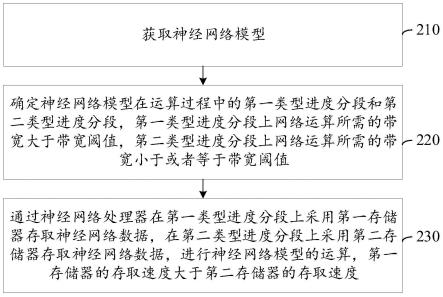
35.图1是本技术一个示例性实施例提供的终端的结构框图,如图1所示,该终端包括处理器120和存储器140,存储器140中存储有至少一条指令,上述至少一条指令由处理器120加载并执行以实现如本技术各个方法实施例所述的神经网络模型的计算方法。
36.在本技术中,终端100是具备神经网络模型运算功能的电子设备。当终端100运行神经网络模型时,终端100能够在正式运行神经网络模型之前,对神经网络模型进行模拟运算,确定每一个运算进度上神经网络数据存取所需的预估带宽,之后基于预估带宽与带宽阈值的大小关系将神经网络模型的整个运算进度划分为第一类型进度分段和第二类型进度分段,进一步确定在预估带宽大于带宽阈值的第一类型进度分段上采用第一存储器存取神经网络数据、以及在预估带宽小于或者等于带宽阈值的第二类型进度分段上采用第二存储器存取神经网络数据,其中,第一存储器的存取速度大于第二存取速度;然后终端100中神经网络处理器按照第一类型进度分段和第二类型进度分段上存储器的分配使用进行神经网络数据的存取,以进行神经网络模型的计算。
37.处理器120可以包括一个或者多个处理核心。处理器120利用各种接口和线路连接整个终端100内的各个部分,通过运行或执行存储在存储器140内的指令、程序、代码集或指令集,以及调用存储在存储器140内的数据,执行终端100的各种功能和处理数据。可选的,处理器120可以采用数字信号处理(digital signal processing,dsp)、现场可编程门阵列(field-programmable gate array,fpga)、可编程逻辑阵列(programmable logic array,pla)中的至少一种硬件形式来实现。处理器120可集成中央处理器(central processing unit,cpu)、图像处理器(graphics processing unit,gpu)、神经网络处理器(neural processing unit,npu)和调制解调器等中的一种或几种的组合。其中,cpu主要处理操作系统、用户界面和应用程序等;gpu用于负责显示屏所需要显示的内容的渲染和绘制;npu用于神经网络模型的运算,尤其擅长处理视频、图像类的多媒体数据;调制解调器用于处理无线通信。可以理解的是,上述调制解调器也可以不集成到处理器120中,单独通过
一块芯片进行实现。
38.存储器140可以包括随机存储器(random access memory,ram),也可以包括只读存储器(read-only memory,rom)。可选地,存储器140还可以包括动态随机存取内存(dynamic random access memory,dram)和静态随机存取存储器(static random-access memory,sram)。可选的,该存储器140包括非瞬时性计算机可读介质(non-transitory computer-readable storage medium)。存储器140可用于存储指令、程序、代码、代码集或指令集。存储器140可包括存储程序区和存储数据区,其中,存储程序区可存储用于实现操作系统的指令、用于至少一个功能的指令(比如触控功能、声音播放功能、图像播放功能等)、用于实现下述各个方法实施例的指令等;存储数据区可存储下面各个方法实施例中涉及到的数据等。
39.图2是本技术一个示例性实施例提供的神经网络模型的计算方法的流程图。该神经网络模型的计算方法可以应用在上述所示的终端中,该方法包括:
40.步骤210,获取神经网络模型。
41.示例性的,终端的本地存储器中存储有神经网络模型,终端从本地存储器中获取神经网络模型。或者,终端的本地存储器中未存储神经网络模型,终端通过有线或者无线网络从服务器中下载神经网络模型至终端。
42.步骤220,确定神经网络模型在运算过程中的第一类型进度分段和第二类型进度分段,第一类型进度分段上网络运算所需的带宽大于带宽阈值,第二类型进度分段上网络运算所需的带宽小于或者等于带宽阈值。
43.终端基于神经网络模型确定出该神经网络模型在运算过程中的第一类型进度分段和第二类型进度分段。示例性的,终端中已存在神经网络模型的进度分段,则直接获取神经网络模型的第一类型进度分段和第二类型进度分段;或者,终端计算出神经网络模型的进度分段。
44.可选地,带宽阈值是基于第二存储器的数据传输带宽设置的。可选地,带宽阈值设置为第二存储器的数据传输带宽。上述带宽阈值用于确定神经网络模型运算所需的带宽是否超过了第二存储器所提供的数据传输带宽。
45.步骤230,通过神经网络处理器在第一类型进度分段上采用第一存储器存取神经网络数据,在第二类型进度分段上采用第二存储器存取神经网络数据,进行神经网络模型的运算,第一存储器的存取速度大于第二存储器的存取速度。
46.终端在确定出第一类型进度分段和第二类型进度分段之后,通过神经网络处理器计算神经网络模型,计算神经网络模型模型的过程中在第一类型进度分段上采用第一存储器存取神经网络数据,在第二类型进度分段上采用第二存储器存取神经网络数据。示例性的,终端计算的神经网络模型是由编译器对神经网络模型进行编译,得到神经网络处理器的可执行指令,之后神经网络处理器执行上述可执行指令实现对神经网络模型的计算。
47.可选地,第一存储器包括系统高速缓存(system cache,sys$)和系统缓冲存储器(system buffer,sysbuf)中的至少一种;第二存储器包括dram。示例性的,上述sys$和sysbuf是由sram构成的。
48.示例性的,终端计算神经网络模型模型的过程中在第一类型进度分段上采用sys$和/或sysbuf来存取神经网络数据,在第二类型进度分段上采用dram存取神经网络数据。
49.需要说明的是,本实施例中不限定步骤220和步骤230的先后执行顺序,终端可以先执行步骤220后执行步骤230,也可以同时执行步骤220和步骤230。
50.综上所述,本实施例提供的神经网络模型计算方法,在计算神经网络模型时先确定出神经网络模型在运算过程中的第一类型进度分段和第二类型进度分段,第一类型进度分段上网络运算所需的带宽大于带宽阈值,第二类型进度分段上网络运算所需的带宽小于或者等于带宽阈值,之后使得神经网络处理器计算神经网络模型的过程中在第一类型进度分段上采用存取速度相对更快的第一存储器存取神经网络数据,在第二类型进度分段上采用存取速度相对稍慢一点儿的第二存储器,使得存储器在神经网络模型的每一个运算进度上均能满足神经网络处理器的数据吞吐量要求,充分运用神经网络处理器的运算性能,使神经网络处理器近饱和工作甚至饱和工作,解决了存储器吞吐速率不足造成的神经网络处理器的性能下降的问题。其次,将神经网络数据存于sys$和/或sysbuf上时,由于sys$和/或sysbuf的省电性能,还能够达到神经网络模型计算过程中的节省电量和防止系统过热的效果。
51.基于上一个实施例所公开的方案,对终端执行步骤220的方式进行详细说明,如图3,步骤220可以包括步骤221至步骤224,步骤如下:
52.步骤221,从对应关系表中查询与神经网络模型的模型标识对应的进度分段信息。
53.终端中设置有进度分段信息与模型标识的对应关系表,上述进度分段信息包括神经网络模型运行过程中的第一类型进度分段和第二类型进度分段。终端在获取得到神经网络模型之后,首先从对应关系表中查询与神经网络模型的模型标识对应的进度分段信息,若对应关系表中存在进度分段信息,终端执行步骤224,若对应关系表中不存在进度分段信息,终端执行步骤222至步骤223。
54.步骤222,当对应关系表中不存在进度分段信息时,对神经网络模型进行模拟运算,得到模拟运算过程中的每一个运算进度上神经网络数据存取所需的预估带宽。
55.终端对神经网络模型进行模拟运算,预估在运算神经网络模型时每一个运算进度上神经网络数据存取所需的带宽;上述运算进度是指计算一个神经网络模型的完成进度,神经网络数据包括神经网络模型运算时读取和写出的数据。
56.在神经网络模型运算的过程中,存在原始数据的输入节点和结果数据的输出节点;在神经网络模型的中间过程中,还存在中间特征数据写出和读取的中间存取节点。相应地,上述神经网络数据包括原始数据、中间特征数据、以及结果数据;其中,原始数据是指未经过神经网络模型计算的原始数据,结果数据是指神经网络模型计算出的结果数据。
57.在一种可能的实现方式中,终端对神经网络模型进行模拟运算,直接计算每一个运算进度上神经网络数据存取所需的预估带宽。
58.在另一种可能的实现方式中,终端对神经网络模型进行模拟运算,分别计算每一个运算进度上原始数据读取所需的第一预估带宽、中间特征数据存取所需的第二预估带宽、以及结果数据写出所需的第三预估带宽;将第一预估带宽、第二预估带宽和第三预估带宽按照运算进度对应叠加,得到预估带宽。
59.可选地,神经网络模型包括中间特征数据的n个中间存取节点,n为大于1的正整数;对于第二预估带宽的计算,终端对神经网络模型进行模拟运算,计算每一个中间存取节点上中间特征数据存取所需的第二预估带宽,最终得到n个中间存取节点对应的n个第二预
估带宽。
60.示例性的,如图4,在npu 11上运行某一神经网络模型时,存在4块数据进出npu,分别是一块原始数据的输入、两块中间特征图像的写出与读入、以及一块结果数据的输出,也即,上述神经网络模型上存在一个输入节点、两个中间存取节点和一个输出节点,因此,需要一个原始数据的输入缓存12、一个中间存取缓存13、一个中间存取缓存14和一个结果数据的输出缓存15。
61.如图5,对上述4个读取节点上数据存取所需的带宽进行预测,得到了原始数据对应的第一预估带宽在运算进度上的预估带宽曲线21、中间特征图像1对应的第二预估带宽在运算进度上的预估带宽曲线22、中间特征图像2对应的第二预估带宽在运算进度上的预估带宽曲线23、以及结果数据对应的第三预估带宽在运算进度上的预估带宽曲线24,按照运算进度的对应关系对预估带宽曲线21、预估带宽曲线22、预估带宽曲线23、以及预估带宽曲线24相加,即得到神经网络数据对应的整体预估带宽在运算进度上的预估带宽曲线25。
62.步骤223,确定预估带宽大于带宽阈值的第一类型进度分段、以及预估带宽小于或者等于带宽阈值的第二类型进度分段。
63.终端比较预估带宽和带宽阈值,划分出预估带宽大于带宽阈值的第一类型进度分段,以及预估带宽小于或者等于带宽阈值的第二类型进度分段。
64.示例性的,若某一个运算进度的前l1个连续的运算进度的预估带宽大于带宽阈值,且该运算进度的后l2个连续的运算进度的预估带宽也大于带宽阈值,将该运算进度划分至第一类型进度分段;l1、l2为正整数。
65.示例性的,终端在确定出第一类型进度分段和第二类型进度分段之后,按照第一类型进度分段和第二类型进度分段确定原始数据的读取进度分段、中间特征数据的存取进度分段、以及结果数据的写出进度分段。如图6,按照第一类型进度分段和第二类型进度分段确定出原始数据缓存31的位置划分、中间特征图像1缓存32、中间特征图像2缓存33、以及结果数据缓存34。在原始数据缓存31上,左斜线图形上标记出的点图形即是原始数据缓存至第一存储器的部分,剩余部分即是原始数据缓存至第二存储器的部分;在中间特征图像1缓存32上,方格图形上标记出的点图形即是中间特征图像1缓存至第一存储器的部分,剩余部分即是中间特征图像1缓存至第二存储器的部分;在中间特征图像2缓存33上,斜方格图形上标记出的点图形即是中间特征图像2缓存至第一存储器的部分,剩余部分即是中间特征图像2缓存至第二存储器的部分;在结果数据缓存34上,右斜线图形上标记出的点图形即是结果数据缓存至第一存储器的部分,剩余部分即是结果数据缓存至第二存储器的部分。
66.示例性的,终端还可以在确定出第一类型进度分段和第二类型进度分段之后,确定在第一类型进度分段上分配使用第二存储器的第一带宽,上述第一带宽小于或者等于带宽阈值;计算第一类型进度分段上预估带宽与第一带宽之间的差值,得到第二带宽;确定在第一类型进度分段上分配使用第一存储器的第二带宽;还确定在第一类型进度分段上采用第二存储器存取神经网络数据。示例性的,终端可以随机确定出小于或者等于带宽阈值的第一带宽。如图7,给出了全dram的数据存取解决方案和dram结合sys$/sysbuf的数据存取解决方案,终端基于带宽阈值确定出了4个第一类型进度分段和4个第二类型进度分段,确定在第一类型进度分段上采用sys$或sysbuf来存取神经网络数据,确定在第二类型进度分段上采用dram存取神经网络数据。
67.需要说明的是,本实施例中不限定计算预估带宽与确定进度分段的先后执行顺序,终端可以先执行计算出预估带宽,再确定进度分段,也可以计算预估带宽的同时,确定进度分段。
68.步骤224,当对应关系表中存在进度分段信息时,从对应关系表中直接获取进度分段信息。
69.当对应关系表中存在进度分段信息时,终端基于神经网络模型的模型标识从对应关系表中直接获取进度分段信息。
70.综上所述,本实施例提供的神经网络模型的计算方法,在对应关系表中存储有进度分段信息的前提下可以直接获取使用,无需对每一个运算的神经网络模型均进行进度分段信息的计算,提高了神经网络模型的运算效率。
71.基于上一个实施例所公开的方案,终端还可以在步骤223之后,执行将进度分段信息与神经网络模型的模型标识对应存储至对应关系表的步骤,从而使得终端只需一次计算神经网络模型的进度分段信息,在之后的应用过程中无需再重复计算该进度分段信息即可获得,提高了神经网络模型的运算效率,也节省了终端的运算空间。
72.可选地,当上述对应关系表中进度分段信息与模型标识的对应关系的缓存时长大于或者时长阈值时,清除对应关系表中的该对应关系;或者,定时清除对应关系表中缓存的进度分段信息与模型标识的对应关系,比如,每天的24点清除对应关系表中缓存的进度分段信息与模型标识的对应关系。
73.上述进度分段信息用于指示神经网络处理器对神经网络模型运算时在第一类型进度分段上采用第一存储器存取神经网络数据、以及在第二类型进度分段上采用第二存储器存取神经网络数据。可选地,上述进度分段信息用于指示神经网络处理器对神经网络模型运算时在第一类型进度分段上采用第一存储器的第二带宽和第二存储器上的第一带宽来存取神经网络数据、以及在第二类型进度分段上采用第二存储器来存取神经网络数据。
74.对于上述进度分段信息与模型标识的对应关系的清除,可以达到节省存储空间的效果。
75.基于上一个实施例所公开的方案,终端可以通过编译器实现对神经网络模型的模拟运算。示例性的,终端获取神经网络模型的模型封装信息;通过编译器对模型封装信息进行编译,得到神经网络处理器的可执行指令;以及通过编译器模拟神经网络处理器执行可执行指令,从而可以计算出神经网络模型的进度分段信息。示例性的,编译器还将编译完成的可执行指令传输至神经网络处理器,以使神经网络处理器执行上述可执行指令,进而计算神经网络模型。示例性的,编译器在可以在完成整个模型封装信息的编译之后,模拟神经网络处理器执行可执行指令;也可以在模型封装信息的编译过程中,一边编译一边模拟神经网络处理器执行已编译出的可执行指令,本实施例中对上述过程不加以限定。
76.示例性的,上述神经网络模型的模型封装信息可以是终端的本地存储器中存储的,还可以是终端从服务器中下载得到的。
77.该方法中应用编译器即可实现对神经网络模型模型的分段存储信息的确定,进而可以广泛的应用于各类型的终端,且实现了编译器的功能扩展。
78.下述为本技术装置实施例,可以用于执行本技术方法实施例。对于本技术装置实施例中未披露的细节,请参照本技术方法实施例。
79.请参考图8,其示出了本技术一个示例性实施例提供的神经网络模型的计算装置的结构框图。该装置可以通过软件、硬件或者两者的结合实现成为终端的全部或一部分。该装置包括:
80.获取模块310,用于获取神经网络模型;
81.确定模块320,用于确定所述神经网络模型在运算过程中的第一类型进度分段和第二类型进度分段,所述第一类型进度分段上网络运算所需的带宽大于带宽阈值,所述第二类型进度分段上网络运算所需的带宽小于或者等于所述带宽阈值;以及
82.运算模块330,用于通过神经网络处理器在所述第一类型进度分段上采用第一存储器存取神经网络数据,在所述第二类型进度分段上采用第二存储器存取所述神经网络数据,进行所述神经网络模型的运算,其中,所述第一存储器的存取速度大于所述第二存储器的存取速度。
83.在一个可选的实施例中,所述确定模块320,用于:
84.对所述神经网络模型进行模拟运算,得到模拟运算过程中的每一个运算进度上所述神经网络数据存取所需的预估带宽,所述运算进度是指计算所述神经网络模型的完成进度;以及
85.确定所述预估带宽大于所述带宽阈值的所述第一类型进度分段、以及所述预估带宽小于或者等于所述带宽阈值的所述第二类型进度分段。
86.在一个可选的实施例中,所述神经网络数据包括原始数据、中间特征数据和结果数据;所述确定模块320,用于:
87.对所述神经网络模型进行模拟运算,计算所述每一个运算进度上所述原始数据读取所需的第一预估带宽、所述中间特征数据存取所需的第二预估带宽、以及所述结果数据写出所需的第三预估带宽;以及
88.将所述第一预估带宽、所述第二预估带宽和所述第三预估带宽按照所述运算进度对应叠加,得到所述预估带宽。
89.在一个可选的实施例中,所述确定模块320,用于:
90.通过编译器对所述神经网络模型的模型封装信息进行编译,得到所述神经网络处理器的可执行指令;以及
91.通过所述编译器模拟所述神经网络处理器执行所述可执行指令。
92.在一个可选的实施例中,所述装置中设置有进度分段信息与模型标识的对应关系表;所述确定模块320,用于:
93.从所述对应关系表中查询与所述神经网络模型的模型标识对应的进度分段信息;
94.当所述对应关系表中不存在所述进度分段信息时,确定执行所述对所述神经网络模型进行模拟运算,得到模拟运算过程中的每一个运算进度上所述神经网络数据存取所需的预估带宽;确定所述预估带宽大于所述带宽阈值的所述第一类型进度分段、以及所述预估带宽小于或者等于所述带宽阈值的所述第二类型进度分段的步骤,得到所述进度分段信息;
95.其中,所述进度分段信息包括所述第一类型进度分段和所述第二类型进度分段。
96.在一个可选的实施例中,所述确定模块320,用于:
97.当所述对应关系表中存在所述进度分段信息时,从所述对应关系表中直接获取所
述进度分段信息。
98.在一个可选的实施例中,所述确定模块320,用于:
99.将所述进度分段信息与所述神经网络模型的模型标识对应存储至所述对应关系表。
100.在一个可选的实施例中,所述第一存储器包括系统高速缓存和系统缓冲存储器中的至少一种;所述第二存储器包括动态随机存取内存。
101.综上所述,本实施例提供的神经网络模型计算装置,在计算神经网络模型时先确定出神经网络模型在运算过程中的第一类型进度分段和第二类型进度分段,第一类型进度分段上网络运算所需的带宽大于带宽阈值,第二类型进度分段上网络运算所需的带宽小于或者等于带宽阈值,之后使得神经网络处理器计算神经网络模型的过程中在第一类型进度分段上采用存取速度相对更快的第一存储器存取神经网络数据,在第二类型进度分段上采用存取速度相对稍慢一点儿的第二存储器,使得存储器在神经网络模型的每一个运算进度上均能满足神经网络处理器的数据吞吐量要求,充分运用神经网络处理器的运算性能,使神经网络处理器近饱和工作甚至饱和工作,解决了存储器吞吐速率不足造成的神经网络处理器的性能下降的问题。其次,将神经网络数据存于sys$和/或sysbuf上时,由于sys$和/或sysbuf的省电性能,还能够达到神经网络模型计算过程中的节省电量和防止系统过热的效果。
102.本技术实施例还提供了一种计算机可读介质,该计算机可读介质存储有至少一条指令,所述至少一条指令由所述处理器加载并执行以实现如上各个实施例所述的神经网络模型计算方法。
103.需要说明的是:上述实施例提供的神经网络模型计算装置在执行神经网络模型计算方法时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的神经网络模型计算装置与神经网络模型计算方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
104.上述本技术实施例序号仅仅为了描述,不代表实施例的优劣。
105.本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
106.以上所述仅为本技术的能够实现的示例性的实施例,并不用以限制本技术,凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1