一种基于Spark的并行卷积神经网络轴承故障诊断方法
本发明涉及滚动轴承故障检测技术领域,特别涉及一种基于spark的并行卷积神经网络轴承故障诊断方法。
背景技术:
在现代工业机电设备中旋转机械占据着举足轻重的地位。而滚动轴承又是旋转机械的关键部件其运行状态的正常与否直接关系到机电设备的运转;据不完全统计,轴承引起的电动机故障率高达40%-50%左右,直接影响电机设备的安全运行。
随着近几年来智能控制的不断发展以及工业数据量的不断增大,传统的特征提取方法例如频提取分析、倒谱分析、小波变换、经验模态分解等此类方法在以大数据驱动的当代弊端也逐渐显现。因而近些年出现了许多基于深度学习的轴承故障诊断特征自提取技术。例如,公开号为cn110031227a,名为“一种基于双通道卷积神经网络的滚动轴承状态诊断方法”一文通过利用数据集增强技术以及多通道特征提取方法,实现了诊断的整个过程,同时也大大的扩展了卷积神经网络算法的迁移能力。但是其并没有解决神经网络训练速度慢这一特点。
技术实现要素:
为了克服上述现有技术的不足,本发明的目的在于提供一种基于spark的并行卷积神经网络轴承故障诊断方法,利用spark技术将神经网络进行并行加速训练,最后在利用bagging算法做出策略决策,从而显著提高了神经网络训练速度。
为了实现上述目的,本发明采用的技术方案是:
一种基于spark的并行卷积神经网络轴承故障诊断方法,包括以下步骤;
步骤一:
将加速度计布置在轴承一端,用于采集轴承在不同荷载以及损坏状况下滚动轴承的振动信号,从而得到损坏轴承的振动信号数据;
步骤二:
对步骤一收集的信号使用数据集堆叠技术,对采集来的数据做进一步处理,以增多训练集数量;
步骤三:
依照轴承损坏状态对数据进行打标处理;根据轴承损坏情况对数据集做标签分类;
步骤四:
依据随机抽样模型的方式对步骤三得到的数据集做出划分并存储在hdfs上;划分而成的多个子训练集;
构建并行卷积神经网络轴承故障诊断模型,并用打好标签的数据集对模型进行训练;其中,所述并行模型包含由spark管理的众多分布于不同计算机的弱cnn学习机,以及运行在driver端的bagging投票算法;
步骤五:
评估训练之后的并行模型,并将该模型用以诊断、分类滚动轴承故障类型。
所述步骤三中轴承损坏标签分为正常轴承振动数据以及损伤大小分别为0.007、0.014、0.021的轴承振动数据。
所述步骤五依据模型训练结果的准确率、加速比来对训练的模型进行评估,从而判断模型是否出现过拟合或训练不充分等情况。
所述步骤四具体为:
(4-1):将打完标签的数据依据集群中的机器数量划分为多个子训
练集,划分方式如下式:
n=n÷k
其中n为整体数据集大小,k为集群节点数量,n为每个节点训练集的大小。n通过有放回的随机抽样方式从n中选取。被切分的数据集存以block形式存储在hdfs上;
(4-2):初始化一维cnn模型,该模型拥有两个卷积层,卷积核大小分别为20×1,5×1,步长为6×1,3×1,两个池化层,卷积核大小分别为4×1,2×1,步长4×1,2×1,之后连接一个神经元为600个的全连接层以及最终的含有10个输出的softmax层;
(4-3):利用spark的分布式模型将统一的初始化一维cnn网络广播到各个executor上;各个executor上获得的广播模型读取hdfs上的分割数据来进行分布式并行训练,多个executor上训练的cnn此时是单独训练的;
(4-4):每个executor的cnn弱学习机,自己单独进行准确率评估,并自行进行误差修正,当所有cnn弱学习机均达到了预测精度要求,训练完毕,此时并没有bagging的参与;
(4-5):在对测试数据进行测试时,所有的弱学习机均会获得到相同的数据集,分别单独进行预测推断,所有弱学习机训练完成最终利用在driver端的bagging投票算法依据弱学习机预测的结果得出模型最终结果。
本发明的有益效果:
本发明通过将采集来的轴承振动信号通过叠加数据集增强技术对源数据进行数据集增强;在将处理后的数据依据随机抽样的模型进行划分,将大数据集切分后传至hdfs上;在利用spark的分布式模型将统一的初始化cnn网络广播到各个executor上;各个executor上获得的广播模型读取hdfs上的分割数据来进行分布式并行训练;最终利用在driver端的bagging算法依据弱学习机预测的结果得出模型最终结果。本发明的方法通过划分原始大数据集为多个小数据集分别训练在最终得出结果的方法,大大的缩减了卷积神经网络训练的时间,并且具有很好的分类精度和鲁棒性。
附图说明
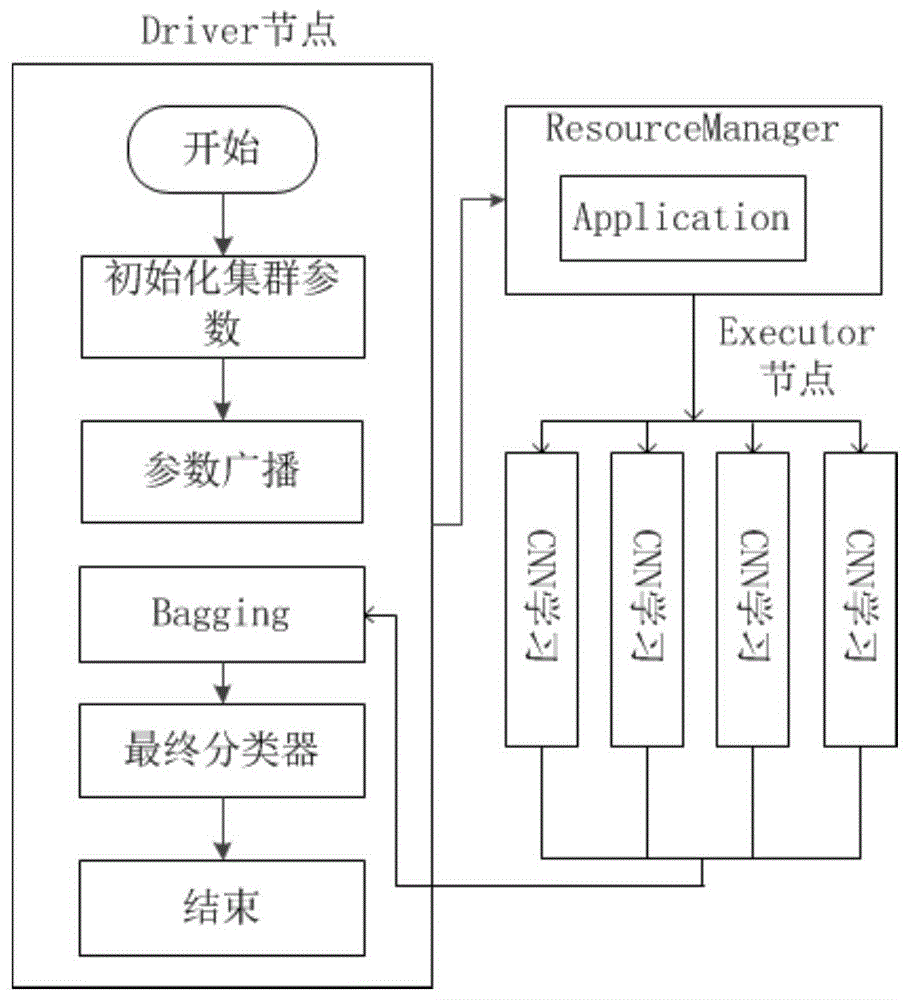
图1为并行卷积神经网络轴承故障诊断的整体结构流程图。
图2为堆叠式数据集增强处理技术示意图。
图3为所用神经网络结构图。
图4spark启动时序图。
图5为集群中含有四个节点时模型训练精度图。
图6为各节点下进行10次试验训练所需时间。
具体实施方式
下面结合附图对本发明作进一步详细说明。
如图1所示,本实施例的基于并行卷积神经网络的轴承故障诊断方法,包含以下步骤:
(1)首先使用加速度计传感器收集在不同负载和损坏情况下滚动轴承的时域振动信号;
实例数据集使用目前被学界广泛认可的凯斯西储大学轴承数据集(cwru)。实例的研究对象为驱动端的轴承,轴承型号为深沟球轴承skf6205。数据集中包含有正常轴承数据、单点驱动端和风机端缺陷的数据。驱动端的数据中又包含分别以12khz和48khz为采样频率收集而来的数据。数据中除了包含正常状态下采集的轴承数据外还有三种数据来自于有损伤的轴承。损伤部位分别为外圈故障、内圈故障和滚动体故障,每种故障又有三种不同的损伤程度。本申请实验采用的是正常轴承数据和采样频率为12khz的驱动端有损坏的轴承数据,转速为1797r/min负载分别为1hp、2hp、3hp。
(2)对上述数据进行堆叠式的数据集增强处理;
神经网络模型的构建过程,数据占着极其重要的作用,但是我们有时可能并没有待研究领域的足够数据去支撑网络的训练,而数据集增强技术可以让我们利用现有的数据制造出更多的数据,不仅如此还可以提升模型的泛化能力。在机器视觉领域,可以通过对现有图片的旋转、镜像、平移等方式来产生新的数据集。但是目前在轴承故障诊断领域并没有专门针对这一领域的数据集增强方式,因此由于数据集的样本数少很可能造成模型过拟合。对于振动数据的特殊性其并不能使用图片的方式来进行增强。
所以本文考虑到振动数据的周期性和时序性,采用了一种重叠采样的数据集增强方式,即从原始信号采集训练所需的样本时,每一段样本信号同其后的样本信号有部分重叠。采样方式如图2所示。
(3)对数据集进行增强之后,按照损伤的不同进行打标签处理,处理表如下:
1实验数据集分类
上表a、b、c数据集分别包含了负载力为1、2、3时的正常数据以及轴承损伤分别为0.007的滚动体损坏数据、0.014的滚动体损坏数据、0.021的轴承滚动体损坏数据、0.007的内圈损坏数据、0.014的内圈损坏数据、0.021的内圈损坏数据、0.007的外圈损坏数据、0.014的外圈损坏数据和0.021的外圈损坏数据。每类训练数据集均选择7000个、测试数据集为300个。
(4)搭建并行卷积神经网络诊断模型,并利用上述数据集对模型进行训练测试,其中并行卷积神经网络诊断模型为由spark管理的众多分布于不同计算机的弱cnn学习机,以及运行在driver端的bagging投票算法组成;
(4-1)将打完标签的数据依据集群中的机器数量划分为多个子训
练集,划分方式如下式:
n=n÷k
其中n为整体数据集大小,k为集群节点数量,n为每个节点训练集的大小。n通过有放回的随机抽样方式从n中选取。被切分的数据集存以block形式存储在hdfs上。
(4-2)实验中的spark采用yarn模式部署,其启动时序图如图4。driver端在任务提交的机器上运行,driver启动完毕之后会和resourcemanager进行通信启动applicationmaster这一组件,之后resourcemanager会分配container(计算所需资源),resourcemanager会在合适的nodemanager上启动applicationmaster,此时的applicationmaster相当于一个启动executor的启动器,由于我们设定的节点数为4,所以spark通过applicationmaster向resourcemanager申请了4个executor所需的内存、线程数等资源。
resourcemanager接到applicationmaster的资源申请之后会分配container资源,然后applicationmaster在资源分配制定的nodemanager上启动executor进程,这些启动的executor就是未来用于分布计算cnn网络的计算节点,executor进程启动完毕之后会向driver端进行反向注册,当4个executor完成注册之后,driver端开始执行main函数。
(4-3)在driver端的main函数中初始化一维cnn模型,模型如图3所示。该模型拥有两个卷积层,卷积核大小分别为20×1,5×1,步长为6×1,3×1。两个池化层,卷积核大小分别为4×1,2×1,步长4×1,2×1。之后连接一个神经元为600个的全连接层以及最终的含有10个输出的softmax层。
(4-4)将统一的初始化一维cnn网络广播到各个executor上;各个executor上获得的广播模型读取hdfs上的分割数据来进行分布式并行训练,多个executor上训练的cnn此时是单独训练的;
(4-5)每个executor的cnn弱学习机,自己单独进行准确率评估,并自行进行误差修正,当所有cnn弱学习机均达到了预测精度要求,训练完毕,此时并没有bagging的参与。
(4-6)在对测试数据进行测试时,所有的弱学习机均会获得到相同的数据集,分别单独进行预测推断,所有弱学习机训练完成最终利用在driver端的bagging投票算法依据弱学习机预测的结果得出模型最终结果。
(5)以测试数据集来作为模型评估标准,并将其应用于诊断待分类的轴承数据;评估标准有,模型在不同节点数量下的训练时间以及模型在测试数据集上的准确率,如图5,6。
上述实施例仅用于解释本发明的技术构成而非限制,但是本发现的实施方式并不受限于实施例,其他任何未背离该发明的精神实质与原理下所做的修盖、替换和组合均应视为等效的置换方式,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!