一种基于知识图谱增益的机器阅读理解模型
1.本发明属于人工智能领域,具体涉及一种基于知识图谱增益的机器阅读理解模型。
背景技术:
2.机器阅读理解是自然语言理解下的一个子任务,其目标为给定一段文本资料和与文本相关的一个问题,机器自行对此文本段分析后给出问题的答案。相对于其他传统自然语言处理任务(如词性判断、实体识别、语法分析等等)而言,机器阅读理解不仅要求机器学会去表示自然语言,同时要去理解、分析、并最终生成输出句。
3.机器阅读理解最广泛的应用是增强人机交互问答系统的表现。在最原始的问答系统中,机器只是将问题与数据库中现有的答案作匹配,返回现有的答案或是“未找到”等错误信息,完全不具有“智能”的特点。在我们实际的生产生活应用中,对于用户提出的问题,答案往往是即时的,不直接以答案形式存在于现有数据库内的。例如用户在搜索引擎中输入待解决的问题,现有的搜索引擎往往会返回包含用户键入内容作为关键字的文档,用户仍需逐一人工阅读每个文档来寻找目标信息。机器阅读理解模型可以从文档中自行识别出用户的问题在文档中对应的关键句,并将这些语句作为答案返回给用户,从而大幅度提升类似问答系统的表现。
4.传统的机器阅读理解模型主要围绕上下文联系与问题同文档之间的联系进行优化。对于原文中包含原样词汇的答案,传统模型往往能够通过其不断更新的上下文语言模型与注意力机制配合,快速定位并给出正确解答。然而,在实际应用中,我们遇到的文档往往问句和答句中的词汇是不完全相同的。这尤其体现在诸如新闻报道、小说散文等文体中,这些文档往往会用很多不同的近义词或相关联的词汇来描述同一事物。那么,当传统模型遇到这类文档时,就会产生不理想的输出结果。
技术实现要素:
5.本发明是为了解决上述问题而进行的,目的在于提供一种基于知识图谱增益的机器阅读理解模型。
6.本发明提供了一种基于知识图谱增益的机器阅读理解模型,用于接收包括文本文档与问题在内的文本数据集以及根据文本数据集自行生成的词汇表,并根据文本文档的内容得到问题的答案,具有这样的特征,包括:文档问题排列模块,用于对文本数据集进行文本预处理与分离,使得文本数据集中的内容格式规范化,并将文本数据集中的每个文本文档与对应问题作为一个组合进行排列,得到文档问题排列数据;命名实体识别模块,用于对文本数据集进行命名实体识别处理,在识别到实体后分别用对应的种族标签替代实体;ernie上下文语言模块,与文档问题排列模块连接,用于接收文档问题排列数据并生成对应的词向量;外部知识库,包括wordnet知识库和conceptnet知识库,用于根据词汇表在各自库中检索对应的外部知识信息,并将外部知识信息通过rotate算法固定为既定长度的向
量,对应生成wordnet知识特征向量和conceptnet知识特征向量;知识匹配与连接层,与ernie上下文语言模块、命名实体识别模块和外部知识库连接,用于接收词向量、wordnet知识特征向量、conceptnet知识特征向量,并对于文本文档与问题中匹配成功的实体,将对应的词向量与wordnet知识特征向量或conceptnet知识特征向量进行连接;注意力计算单元,用于读取连接后的词向量、wordnet知识特征向量以及conceptnet知识特征向量,并为每个向量分配一个tensor进行存储和计算,将词向量分别与每个wordnet知识特征向量和conceptnet知识特征向量进行双向注意力运算,再将词向量与每个经过双向注意力运算的wordnet知识特征向量和conceptnet知识特征向量进行连接,并用新的tensor进行保存,再将新的tensor进行自注意力运算后得到答案;以及结果生成单元,用于接收答案,并对答案的置信度进行判定,当答案中的最佳置信度高于预定阈值时,将答案输出,当答案中的最佳置信度低于预定阈值时,启用答案优选机制,首先将置信度排名前五的答案均作为备选答案,之后将每一个备选答案放入语料库中进行语句困惑度的计算,并将语句困惑度最低的备选答案进行输出。
7.在本发明提供的基于知识图谱增益的机器阅读理解模型中,还可以具有这样的特征:其中,文档问题排列模块将文本数据集中的每个文本文档与对应问题作为一个组合进行排列时,按照g={[p0,q0],[p1,q1]...[p
n,
q
n
]}的格式排列,g为当前批次的文档数据集,p为文本文档,q为问题。
[0008]
在本发明提供的基于知识图谱增益的机器阅读理解模型中,还可以具有这样的特征:其中,conceptnet知识库中收录了关于词汇的同义词、近义词、不同语态、多语言以及关联词,并以图的形式进行保存。
[0009]
在本发明提供的基于知识图谱增益的机器阅读理解模型中,还可以具有这样的特征:其中,预定阈值为0.4。
[0010]
在本发明提供的基于知识图谱增益的机器阅读理解模型中,还可以具有这样的特征:其中,语料库由来自两个百科数据集的20万条自然语句构成,且该语料库和文本数据集无交集。
[0011]
发明的作用与效果
[0012]
根据本发明所涉及的一种基于知识图谱增益的机器阅读理解模型,因为设有命名实体识别模块来对文本数据集进行命名实体识别处理,能够将大部分原本的未知词汇通过实体识别后分别用其对应的种类标签替代,有效地降低了未知词汇在文档中的出现频率;并且设有两个外部知识库,能够利用外部知识库对文本文档与问题中的实体所蕴含的关系进行挖掘,快速建立问题与文档内容之间的联系,得到更为精准的答案;同时在输出结果时还具有答案优选机制,能够通过判断语句困惑度来避免输出的答案由于缺少或有冗余的代词、语气助词等造成的精度损失。因此,本发明的一种基于知识图谱增益的机器阅读理解模型通过双外部知识库结构,配合命名实体识别及答案优选机制,可以较大幅度改善机器阅读理解模型的表现并提升其健壮性,能够在改善搜索引擎及问答系统上加以应用,尤其在改善搜索引擎方面,可以直接对互联网文档进行分析,返回用户待查询的关键句,从而避免了用户需要人工访问每个文档来获取所需信息,可以极大地提升搜索引擎的工作效率。
附图说明
[0013]
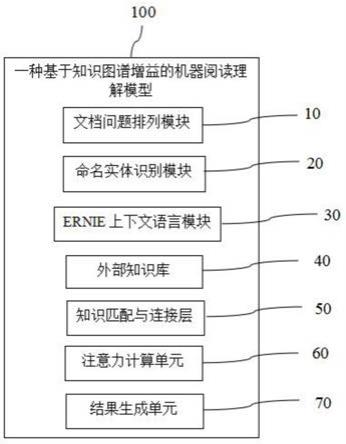
图1是本发明的实施例中一种基于知识图谱增益的机器阅读理解模型的结构框图;
[0014]
图2是本发明的实施例中基于知识图谱增益的机器阅读理解模型的流程示意图;
[0015]
图3是本发明的实施例中词汇knowledge在conceptnet知识库的关系示意图。
具体实施方式
[0016]
为了使本发明实现的技术手段与功效易于明白了解,以下结合实施例及附图对本发明作具体阐述。
[0017]
<实施例>
[0018]
图1是本发明的实施例中一种基于知识图谱增益的机器阅读理解模型的结构框图,图2是本发明的实施例中基于知识图谱增益的机器阅读理解模型的流程示意图。
[0019]
如图1和图2所示,本实施例的一种基于知识图谱增益的机器阅读理解模型100,用于接收包括文本文档与问题在内的文本数据集以及根据文本数据集自行生成的词汇表,并根据文本文档的内容得到问题的答案,包括:文档问题排列模块10、命名实体识别模块20、ernie上下文语言模块30、外部知识库40、知识匹配与连接层50、注意力计算单元60以及结果生成单元70。
[0020]
文档问题排列模块10用于对文本数据集进行文本预处理与分离,使得文本数据集中的内容格式规范化,并将文本数据集中的每个文本文档与对应问题作为一个组合进行排列,得到文档问题排列数据。
[0021]
文档问题排列模块将文本数据集中的每个文本文档与对应问题作为一个组合进行排列时,按照g={[p0,q0],[p1,q1]...[p
n,
q
n
]}的格式排列,g为当前批次的文档数据集,p为文本文档,q为问题。
[0022]
命名实体识别模块20用于对文本数据集进行命名实体识别处理,在识别到实体后分别用对应的种族标签替代实体。
[0023]
本实施例中,命名实体识别模块20的工作示例如表1:
[0024]
表1命名实体识别处理与无预处理的对比
[0025][0026]
如表1,在对该段原文的处理中,在不进行命名实体识别处理的情况下,文中的实体均通过unk来表示未知词汇,而本发明在识别到实体后通过person、misc等种族标签来替换对应的实体,其中,misc表示专有名词,用来表示特殊地点或企业、机构名称等,本发明将命名实体识别加入到数据预处理环节,将大部分原本的未知词汇通过实体识别后分别用其
对应的种类标签替代,有效地降低了未知词汇在文档中的出现频率。
[0027]
ernie上下文语言模块30与文档问题排列模块10连接,用于接收文档问题排列数据并生成对应的词向量。
[0028]
外部知识库40包括wordnet知识库和conceptnet知识库,用于根据词汇表在各自库中检索对应的外部知识信息,并将外部知识信息通过rotate算法固定为既定长度的向量,对应生成wordnet知识特征向量和conceptnet知识特征向量。
[0029]
图3是本发明的实施例中词汇knowledge在conceptnet知识库的关系示意图。
[0030]
如图3所示,conceptnet知识库中收录了关于词汇的同义词、近义词、不同语态、多语言以及关联词,并以图的形式进行保存。
[0031]
知识匹配与连接层50与ernie上下文语言模块30、命名实体识别模块20和外部知识库40连接,用于接收词向量、wordnet知识特征向量、conceptnet知识特征向量,并对于文本文档与问题中匹配成功的实体,将对应的词向量与wordnet知识特征向量或conceptnet知识特征向量进行连接。
[0032]
注意力计算单元60用于读取连接后的词向量、wordnet知识特征向量以及conceptnet知识特征向量,并为每个向量分配一个tensor进行存储和计算,将词向量分别与每个wordnet知识特征向量和conceptnet知识特征向量进行双向注意力运算,再将词向量与每个经过双向注意力运算的wordnet知识特征向量和conceptnet知识特征向量进行连接,并用新的tensor进行保存,再将新的tensor进行自注意力运算后得到答案。
[0033]
结果生成单元70用于接收答案,并对答案的置信度进行判定,当答案中的最佳置信度高于预定阈值时,将答案输出,当答案中的最佳置信度低于预定阈值时,启用答案优选机制,首先将置信度排名前五的答案均作为备选答案,之后将每一个备选答案放入语料库中进行语句困惑度的计算,并将语句困惑度最低的备选答案进行输出。
[0034]
预定阈值为0.4。
[0035]
语料库由来自两个百科数据集的20万条自然语句构成,且该语料库和文本数据集无交集。
[0036]
在使用本实施例的基于知识图谱增益的机器阅读理解模型进行的实验中,通过该答案优选机制能够平均提交模型精度分数0.25。
[0037]
本实施例中,不包含外部知识的传统语言模型和本发明的基于知识图谱增益的机器阅读理解模型在同样输入下的模型预测结果如表2:
[0038]
表2 seq2seq模型与本发明在同样输入下的的输出对比
[0039][0040]
如表2所示,对于上述文档信息,本发明可以根据文档和问题间注意力运算结果准确识别出关键字“tesla”,之后在外部知识库和命名实体识别模块中对文档中的实体所蕴含的关系进行挖掘,以文档第一句为例,外部知识库可提供的信息有:
[0041]
united states(文档中)<
‑‑
relatedto
‑‑
>us(问题中)。
[0042]
age(文档中)<
‑‑
symptom
‑‑
>old(问题中)。
[0043]
tesla
‑‑
>人物名字。
[0044]
通过外部信息库中的信息可以帮助模型快速建立问题与文档内容之间的关系,从而准确定位出正确答案“35”。
[0045]
本实施例中还分别使用squad1.1数据集、addsent
‑
squad数据集以及record数据集,将本发明的基于知识图谱增益的机器阅读理解模型与其余阅读理解模型进行对比实验,实验结果如表3
‑
表5:
[0046]
表3 squad1.1数据集对比实验结果
[0047][0048][0049]
如表3所示,该对比测试中使用的squad数据集是机器阅读理解最经典的数据集之一,squad数据集的文档多来源于维基百科,包含几乎所有类别的文档。squad是一个抽取型
的阅读理解数据集,它要求机器从文档中提取出一段连续的文字作为所给问题的答案。本发明在此数据集上的表现可超过大部分现有的阅读理解模型,并且在精确度方面可领先人工阅读水平5.6个百分点。
[0050]
表4 addsent
‑
squad数据集对比实验结果
[0051][0052]
如表4所示,该对比测试中使用的addsent
‑
squad数据集是squad数据集的一个强化版本,其主要目的是为了检测机器阅读理解的健壮性。此数据集有多干扰项和单干扰项两个版本,其中多干扰项是指在原有的squad数据集的基础上,人为在每个文档内添加了多个与正确答案在文字上较为相近,但意义不同的干扰句;单干扰项版本则仅添加一句干扰句。从表3与表4中的实验结果可以看出,对于qa
‑
net等基于传统循环神经网络结构的模型,其抗干扰能力很弱,在addsent
‑
squad上的表现相比squad数据集出现了超过40个百分点的骤降。而本发明在注意力机制和外部知识库辅助下仍能保持在多干扰项下得到80分以上的精度,具有较强的健壮性。
[0053]
表5 record数据集对比实验结果
[0054]
模型名称精确度f1分数bert
‑
大型模型56.459.1xlnet
‑
大型模型61.163.8skg
‑
bert72.272.8kt
‑
net73.074.8本发明78.480.6人工阅读表现91.391.6
[0055]
如表5所示,该对比测试中使用的record数据集不同于其他普通抽取型阅读理解数据集,record数据集对模型的推理能力提出了较高的要求。在此数据集中,文档和对应问题之间的描述往往不使用相同的词汇,而是以其近义词,或是用其他描述方式。因此需要模型拥有较强的推理能力和外部知识的辅助,来建立问题和答案之间的联系。
[0056]
在对record数据集的对比实验中,kar和kt
‑
net这两个对照组同样拥有外部知识库。对比而言,本发明拥有双外部知识库配合额外的命名实体识别模块,此外还拥有答案优选机制,在答案置信度较低通过困惑度算法来帮助模型确定答案。因此本发明较单一知识库模型而言拥有较大的领先幅度。
[0057]
实施例的作用与效果
[0058]
根据本实施例所涉及的一种基于知识图谱增益的机器阅读理解模型,因为设有命名实体识别模块来对文本数据集进行命名实体识别处理,能够将大部分原本的未知词汇通过实体识别后分别用其对应的种类标签替代,有效地降低了未知词汇在文档中的出现频率;并且设有两个外部知识库,能够利用外部知识库对文本文档与问题中的实体所蕴含的关系进行挖掘,快速建立问题与文档内容之间的联系,能够得到更为精准的答案;同时在输出结果时还具有答案优选机制,能够通过判断语句困惑度来避免输出的答案由于缺少或有冗余的代词、语气助词等造成的精度损失。因此,本实施例的一种基于知识图谱增益的机器阅读理解模型通过双外部知识库结构,配合命名实体识别及答案优选机制,可以较大幅度改善机器阅读理解模型的表现并提升其健壮性,能够在改善搜索引擎及问答系统上加以应用,尤其在改善搜索引擎方面,可以直接对互联网文档进行分析,返回用户待查询的关键句,从而避免了用户需要人工访问每个文档来获取所需信息,可以极大地提升搜索引擎的工作效率。
[0059]
上述实施方式为本发明的优选案例,并不用来限制本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1