具有强化学习功能的问答语料学习方法与流程
1.本发明涉及一种具有强化学习功能的问答语料学习方法。
背景技术:
2.现阶段在智能问答领域,核心方法是通过人工从大规模聊天语料中标注少量样本,并构建模型进行学习。该方法需要耗费大量的人工劳动力,并且泛化性低,不能与热点时效保持一致。
技术实现要素:
3.本发明提供了一种具有强化学习功能的问答语料学习方法,采用如下的技术方案:
4.一种具有强化学习功能的问答语料学习方法,包括以下步骤:
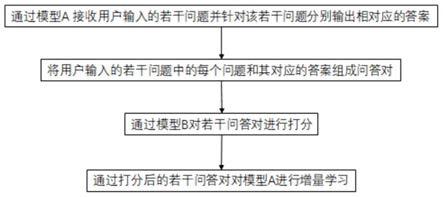
5.通过模型a接收用户输入的若干问题并针对该若干问题分别输出相对应的答案;
6.将用户输入的若干问题中的每个问题和其对应的答案组成问答对;
7.通过模型b对若干问答对进行打分;
8.通过打分后的若干问答对对模型a进行增量学习。
9.进一步地,通过打分后的若干问答对对模型a进行增量学习的具体方法为:
10.将若干问答对中打分值高于第一预设值的问答对作伪标签直接参与到模型a的增量学习中;
11.将若干问答对中打分值低于第二预设值的问答对置为负样本参与到模型a的增量学习中。
12.进一步地,模型b对若干问答对进行打分的分值区间为0至1。
13.进一步地,第一预设值为0.8;第二预设值为0.2。
14.进一步地,模型a在增量学习过程中,模型a对该若干问题分别重新输出相对应的答案以组成新问答对;模型b对新问答对进行评分并得到平均分score1;根据如下公式得到惩罚系数w,并将惩罚系数w作用于模型a的损失函数loss
a
上,得到新损失函数loss
new
以指导模型a进行梯度回传,更新模型a的参数:
15.w=
‑
ln(score1),
16.loss
new
=loss
a
*w。
17.进一步地,在通过模型a接收用户输入的若干问题并针对该若干问题分别输出相对应的答案之前,具有强化学习功能的问答语料学习方法还包括:
18.训练一个用于识别用户意图并反馈答案的模型a;
19.训练一个用于对模型a的输出进行打分的模型b。
20.进一步地,模型a的增量学习时间设置为每日零点至五点执行。
21.进一步地,模型a的增量学习时间设置为每日两点至四点执行。
22.进一步地,模型a的增量学习周期小于7天。
23.进一步地,模型a的增量学习周期为1天。
24.本发明的有益之处还在于所提供的具有强化学习功能的问答语料学习方法根据线上大规模语料的问答数据的输入,针对这些问答数据能够实现模型a的自我学习和更新,从而能够持续自动地优化问题的匹配答案。也就是说,该方法能够通过强化学习自动训练调整更新模型a,实现模型a的持续性自我微调、自我完善以及自我学习,这样既能够优化针对问题输出的答案,有能够节省大量人工标注,节省劳动力成本。
附图说明
25.图1是本发明的具有强化学习功能的问答语料学习方法的示意图。
具体实施方式
26.以下结合附图和具体实施例对本发明作具体的介绍。
27.如图1所示,本发明揭示一种具有强化学习功能的问答语料学习方法,包括以下步骤:通过模型a接收用户输入的若干问题并针对该若干问题分别输出相对应的答案;将用户输入的若干问题中的每个问题和其对应的答案组成问答对;通过模型b对若干问答对进行打分;通过打分后的若干问答对对模型a进行增量学习。
28.上述的具有强化学习功能的问答语料学习方法根据线上大规模语料的问答数据的输入,针对这些问答数据能够实现模型a的自我学习和更新,从而能够持续自动地优化问题的匹配答案。也就是说,该方法能够通过强化学习自动训练调整更新模型a自身,实现模型a的持续性自我微调、自我完善以及自我学习,这样既能够优化针对问题输出的答案,有能够节省大量人工标注,节省劳动力成本。
29.通过模型a接收用户输入的若干问题并针对该若干问题分别输出相对应的答案,也就是说:在用户输入问题后,模型a接收该输入的问题,并针对该问题找到相应的答案,然后将该答案输出以反馈给用户。
30.将用户输入的若干问题中的每个问题和其对应的答案组成问答对,也就是说:当模型a针对一个问题找到相应的答案后,将该答案与该问题组成一个问答对。在以后的问题输入过程中,如果再接收到同样的问题时,便通过相应的问答对直接输出与该问题对应的答案。
31.通过模型b对若干问答对进行打分,也就是说:当模型a针对一个问题输出一个答案并组成问答对时,模型b根据用户对这个答案的反应来给这个问答对进行打分,以判别该问答对中的答案是否是用户所需要的。
32.通过打分后的若干问答对对模型a进行增量学习,也就是说:模型a在接收到模型b的打分后,根据这个分数进行自我更新学习,优化一个问答对中的针对其问题的答案。
33.进一步地,通过打分后的若干问答对对模型a进行增量学习的具体方法为:
34.将若干问答对中打分值高于第一预设值的问答对作伪标签直接参与到模型a的增量学习中。也就是说,经过模型b打分后的问答对中取得分值高于第一预设值的问答对被定义为伪标签,然后直接作为训练模型a的预料参与到模型a的增量学习中,这样就不用人工进行标注,实现了自动化更新模型a,提高模型a的学习效率。
35.将若干问答对中打分值低于第二预设值的问答对置为负样本参与到模型a的增量
学习中。也就是说,经过模型b打分后的问答对中取得分值低于第二预设值的问答对被定义为负样本,然后直接作为训练模型a的预料参与到模型a的增量学习中。这样就不用人工进行标注,模型b直接将分数低的问答对作为负样本,以训练模型a在以后遇到同一问题时,避免输出该问答对中的答案,而是优化答案后再反馈给用户。这样有助于自动化更新模型a,提高模型a的学习效率。
36.作为具体的方法,模型a在增量学习过程中,模型a对该若干问题分别重新输出相对应的答案以组成新问答对。模型b对新问答对进行评分并得到平均分score1;根据如下公式得到惩罚系数w,并将惩罚系数w作用于模型a的损失函数loss
a
上,得到新损失函数loss
new
以指导模型a进行梯度回传,更新模型a的参数:
37.w=
‑
ln(score1),
38.loss
new
=loss
a
*w。
39.进一步地,在通过模型a接收用户输入的若干问题并针对该若干问题分别输出相对应的答案之前,具有强化学习功能的问答语料学习方法还包括:
40.训练一个用于识别用户意图并反馈答案的模型a;
41.训练一个用于对模型a的输出进行打分的模型b。
42.作为具体的实施方式,模型b对若干问答对进行打分的分值区间为0至1。
43.进一步地,第一预设值为0.8。将若干问答对中打分值高于0.8的问答对作伪标签直接参与到模型a的增量学习中。第二预设值为0.2。将若干问答对中打分值低于0.2的问答对置为负样本参与到模型a的增量学习中。
44.作为一种具体的实施方式,模型a的增量学习时间设置为每日零点至五点执行。每日零点至五点的平台的访问流量较小,便于模型a的自我学习和更新。
45.具体地,初始模型a的增量学习时间设置为每日两点至四点执行。这个时间段内平台的访问流量最小。
46.作为一种具体的实施方式,模型a的增量学习周期小于7天。这样的周期设置有助于模型a保持较好的时效性。
47.具体地,模型a的增量学习周期设置为1天。这样能够充分地保证模型a输出答案的时效性。
48.作为一种具体的实施方式,模型b的评价标准包括:对用户的情感识别和对用户的意图识别。针对用户提出的一个问题,在模型a输出答案后,模型b根据用户反馈的答案识别用户的情感或者目的。若模型b识别出用户的情感是负面的,则给与模型a输出的问答对的分数就会较低,以期在后续模型a的增量学习中避免类似情况的发生,也就是用户再输入这一问题时,模型a便不会再输出该问答对中的答案。
49.作为一种优选的实施方式,用户数据包含电商领域的订单数据、问答数据和推荐数据。
50.以上显示和描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,上述实施例不以任何形式限制本发明,凡采用等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1