一种基于类别信息对齐的图像文本跨模态检索方法
本发明属于图像文本跨模态检索技术领域,更为具体地讲,涉及一种基于类别信息对齐的图像文本跨模态检索方法。
背景技术:
跨模态检索是指不同模态的数据相互检索的过程。现有的跨模态检索的主流方法分为三种。
第一种是基本子空间学习的跨模态检索方法,该方法主要是将具有相同语义信息的成对数据集学习投影矩阵,将不同模态的特征投影到一个共同潜在子空间,然后在子空间中度量不同模态的相似性。如基于典型相关分析的方法和基于核的方法,通过最大化两组异构的不同模态数据之间的成对相关性来学习线性投影或选择合适的核函数来生成公共表示。
基于深度学习的跨模态检索方法更多还是关注底层特征学习和高层网络相关性,忽视了不同模态的数据内部结构和不同模态间语义关联。
第二种是基于深度学习的跨模态检索方法,该方法利用深度学习的特征表示能力将不同模态的特征抽取出来,然后在高层建立不同模态的语义关联。现有的深度学习的跨模态检索方法,无论是无监督的还是有监督的,通常只注重保持耦合跨模态项的成对相似性(例如图像和文本)共享语义标签并作为模型学习过程的输入。一些研究者建议使用标签信息来学习样本之间内部的区别信息。此外,通过强制每个图像-文本对的表示在公共空间中彼此接近来保持跨模态相似性。同时由于生成对抗网络强大的生成能力,使用标签信息和一个模态信息来生成相应的模态数据来改进跨模态检索精度也是现有的方法之一。
尽管标签信息已用于这些方法中,分类信息仅用于学习每个模态内或模态间的区别特征。这些跨模态学习方法没有充分利用语义信息
第三种方法是基于哈希变换的跨模态检索方法,该方法利用成对的样本数据信息,学习不同模态的哈希变换,将不同模态的特征映射到汉明空间实现快速的跨模态检索。但该跨模态检索方法检索精度还不够高。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于类别信息对齐的图像文本跨模态检索方法,以保持不同语义类别图像文本之间的区分,消除异构性差异,同时,尽可能充分利用图像-文本耦合项的成对相似性语义信息,保证所学习的表示既具有语义结构的区分性,又具有跨模态的不变性。
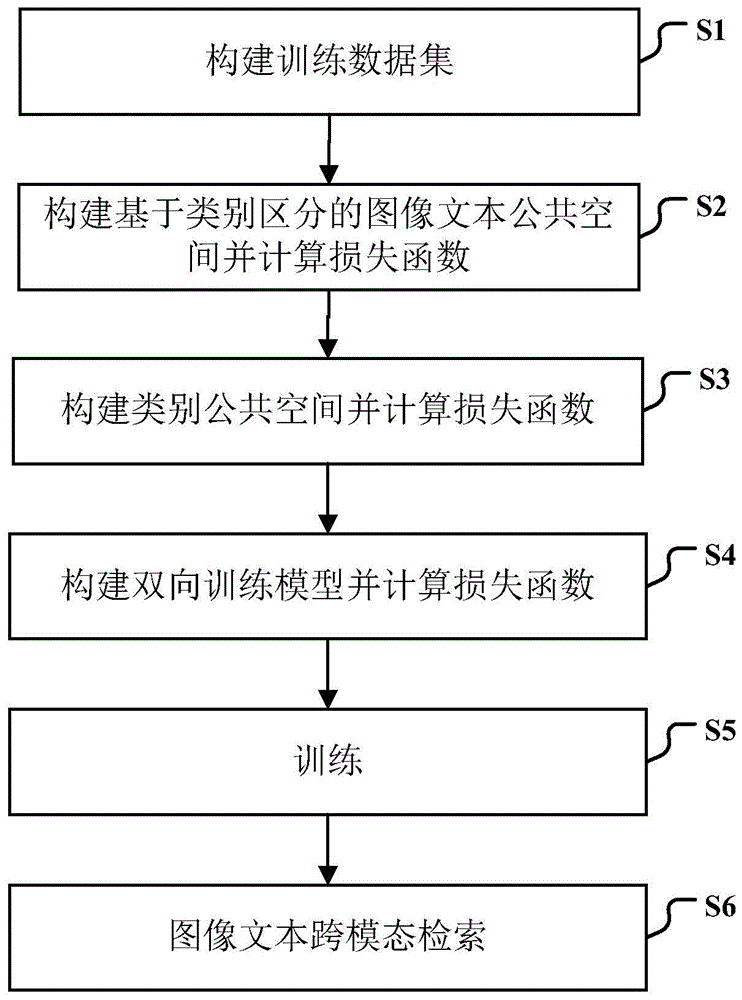
为实现上述发明目的,本发明基于类别信息对齐的图像文本跨模态检索方法,其特征在于,包括以下步骤:
(1)、构建训练数据集
将一张图像i以及对应文本t、类别信息c作为一个图像文本对实例存入训练数据集中,这样,n个图像文本对实例构成训练数据集;
(2)、构建基于类别区分的图像文本公共空间并计算损失函数
2.1)、构建真图像空间
对于图像i,提取其图像特征向量作为真图像特征
2.2)、构建真文本空间
对于图像i对应的文本t,将其转换为文本特征向量,并作为真文本特征
2.3)、构建真图像类别判别器
真图像类别判别器
真文本类别判别器
模态间判别器dimd对真图像嵌入
真图像空间、真文本空间以及图像类别判别器
2.4)、计算真图像空间的损失函数
将真图像编码器
定义编码器的生成损失函数
其中,mk为最大平均差异函数;
定义循环一致性损失函数为
其中,l2为求两个向量的二范数;
定义图像与文本之间的模态不变性损失函数
其中,α为系数,
定义判别器对抗损失函数
这样,得到图像文本公共空间的损失函数lcd:
(3)、构建类别公共空间并计算损失函数
对于图像i对应的类别信息c,将其转换为类别特征向量,并作为类别信息嵌入zc;
将真图像嵌入
将类别信息嵌入zc与文本图像嵌入
定义生成损失函数
定义循环一致性损失
定义判别器损失函数
计算类别公共空间的损失函数lcg:
(4)、构建双向训练模型并计算损失函数
将伪图像特征
将伪文本特征
计算双向训练模型的判别器损失函数
(5)、训练
计算总的损失函数ltotal:
将训练数据集的n个图像文本对实例,每个图像文本对实例送入图像文本公共空间、类别公共空间以及双向训练模型,依据总的损失函数ltotal对图像文本公共空间、类别公共空间以及双向训练模型进行训练;
(6)、图像文本跨模态检索
对于一张图像,经过特征提取、映射后得到视频/图片编码,然后计算与文本检索库中文本编码之间的余弦距离,进而根据余弦距离的大小顺序,依次输出视频/图片-文本检索结果;
对于一个文本,词转向量、映射,得到的文本编码,然后计算与图片检索库中视频/图片编码之间的余弦距离,进而根据余弦距离的大小顺序,依次输出文本-视频/图片检索结果。
本发明的目的是这样实现的。
本发明基于类别信息对齐的图像文本跨模态检索方法,其目的是保持不同语义类别实例(图像文本)之间的区分,同时消除异构性差异。为了实现这一目的,本发明创新性地在公共表示空间即图像文本公共空间中引入类别信息来最小化区分损失,并引入跨模态损失来对齐不同的模态信息。此外,本发明还采用类别信息嵌入的方法来生成假特征,而不是像其他基于dnn(deepneutralnet,即深度神经网络)的方法那样标记信息,同时,本发明在类别公共空间中最小化模态不变性损失来学习模态不变性特征。在这种学习策略的指导下,本发明尽可能充分利用图像-文本耦合项的成对相似性语义信息,保证了所学习的表示既具有语义结构的区分性,又具有跨模态的不变性。
附图说明
图1是本发明基于类别信息对齐的图像文本跨模态检索方法一种具体实施方式流程图;
图2是本发明基于类别信息对齐的图像文本跨模态检索方法一种具体实施方式原理示意图。
具体实施方式
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
基于深度学习的跨模态检索中,最常用的跨模态检索为图像和文本。在本发明中,图像i以及对应文本t、类别信息c作为一个图像文本对实例存入训练数据集中,这样,n个图像文本对实例构成训练数据集。对应的真实的图像特征(简称真图像特征)、真实的文本特征(简称真文本特征)可以表示为
本发明的目的是学习两个专有的图像和文本编码器即真图像编码器
本发明的具体流程以及原理示意图如图1、2所示。对于训练数据集中的每个成对样本,提取出的真图像特征
在本实施例中,如图1所示,本发明基于类别信息对齐的图像文本跨模态检索方法包括以下步骤:
步骤s1:构建训练数据集
将一张图像i以及对应文本t、类别信息c作为一个图像文本对实例存入训练数据集中,这样,n个图像文本对实例构成训练数据集。
步骤s2:构建基于类别区分的图像文本公共空间并计算损失函数
本步骤的目的是获得两种模态即图像文本的嵌入即真图像嵌入
步骤s2.1:构建真图像空间
如图2所示,对于图像i,采用图像cnn(具体为vgg19网络)提取其图像特征向量作为真图像特征
步骤s2.2:构建真文本空间
如图2所示,对于图像i对应的文本t,采用doc2vec将其转换为文本特征向量,并作为真文本特征
步骤s2.3:构建真图像类别判别器
真图像类别判别器
真文本类别判别器
模态间判别器dimd对真图像嵌入
真图像空间、真文本空间以及真图像类别判别器
步骤s2.4:计算真图像空间的损失函数
将真图像编码器
在训练生成对抗网络的时候,本发明使用具有最大平均差异(maximummeandiscrepancy,简称mmd)损失函数构建。
定义编码器的生成损失函数
其中,mk为最大平均差异函数。
在本发明种,引入了循环一致性(cycle-consistency)损失,循环一致性旨在通过使错误最小化来强制合成语义特征重建其原始语义特征,这有助于增强原始数据空间中的多模式表示与公共语义空间中的语义特征之间的相互关系。
在本发明种,定义循环一致性损失函数为
其中,l2为求两个向量的二范数。
定义图像与文本之间的模态不变性损失函数
其中,α为系数,
定义判别器对抗损失函数
这样,得到图像文本公共空间的损失函数lcd:
步骤s3:构建类别公共空间并计算损失函数
仅使用步骤s2中提到的两个编码器网络即真图像编码器
对于图像i对应的类别信息c,将其转换为类别特征向量,并作为类别信息嵌入zc。
将真图像嵌入
将类别信息嵌入zc与文本图像嵌入
至此,一真一假两个编码器网络共同训练,有助于公共空间的增强。
定义生成损失函数
定义循环一致性损失
定义判别器损失函数
计算类别公共空间的损失函数lcg:
步骤s4:构建双向训练模型并计算损失函数
大多数现有的方法都没有考虑学习逆映射,也就是将生成的嵌入投影回原始特征空间,事实证明,学习到的特征表示对于监督识别任务很有用。这部分的可解释性始于bigan框架,bigan框架是判断双射函数(g,e)的联合判别器。将bigan的过程表示为:
然后,在bigan中应用联合判别器来确定数据对(x,z),
将伪图像特征
将伪文本特征
计算双向训练模型的判别器损失函数
步骤s5:训练
计算总的损失函数ltotal:
将训练数据集的n个图像文本对实例,每个图像文本对实例送入图像文本公共空间、类别公共空间以及双向训练模型,依据总的损失函数ltotal对图像文本公共空间、类别公共空间以及双向训练模型进行训练;
步骤s6:图像文本跨模态检索
对于一张图像,经过特征提取、映射后得到视频/图片编码,然后计算与文本检索库中文本编码之间的余弦距离,进而根据余弦距离的大小顺序,依次输出视频/图片-文本检索结果;
对于一个文本,词转向量、映射,得到的文本编码,然后计算与图片检索库中视频/图片编码之间的余弦距离,进而根据余弦距离的大小顺序,依次输出文本-视频/图片检索结果。
对比
采用map(meanaverageprecision)指标来评估本发明。在四个广泛使用的跨模态数据集上进行了的详细定量实验(wikipedia数据集、pascal数据集、pkuxmedia数据集和mir-flickr数据集)。这四个多模态数据集可以分为单标签数据集和多标签数据集。对于前三个数据集,每个图像-文本对通过单个类标签链接,文本模态由离散标签组成。对于mir-flickr数据集,每个图像文本对都与多个类标签关联,并且文本模态由句子组成。
单标签数据集实验结果如表1所示:
表1
多标签数据集结果如表2所示:
表2
从表1、2可以看出,相比现有的方法,本发明达到了最佳性能,大大优于传统的和基于dnn的交叉模式检索方法。特别是,与两个最新方法dscmr和sdml相比,本发明在三个单标签数据集上分别平均增加了2.8%,4.9%,3.6%,3.9%和4.3%,2.3%。
mir-flickr是一个多标签数据集,某些方法无法处理这种情况。但是本发明也获得了最佳性能。在图像和文本查询检索任务中,本发明分别比现有最佳方法高出3%和2.8%。这表明本发明可有效处理多标签案件,是一种有效的多模式表示学习方法,可用于跨图像和文本的跨模态检索。
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
- 还没有人留言评论。精彩留言会获得点赞!