一种基于深度学习的大肠空腔区及肠内容物标注方法
本发明涉及图像处理领域,尤其涉及一种基于深度学习的大肠空腔区及肠内容物标注方法。
背景技术:
现阶段对于肠内容物以及大肠区的标记,以及大肠区的标记,只能通过专业人员进行手动标注,这样费时费力,并且长时间工作之后有标记失误的风险。近年来人工智能技术得到快速发展,尤其是深度学习方法在医学图像处理领域中得到广泛应用,但是目前常用于医学图像处理的网络因为没有顾及到上下文信息导致分割效果并不好,极容易出现错判和漏判的情况。
技术实现要素:
为了解决上述技术问题,本发明的目的是提供一种基于深度学习的大肠空腔区及肠内容物标注方法,自动对输入的ct腹腔图像的大肠空腔区及肠内容物区域进行标注。
本发明所采用的第一技术方案是:一种基于深度学习的大肠空腔区及肠内容物标注方法,包括以下步骤:
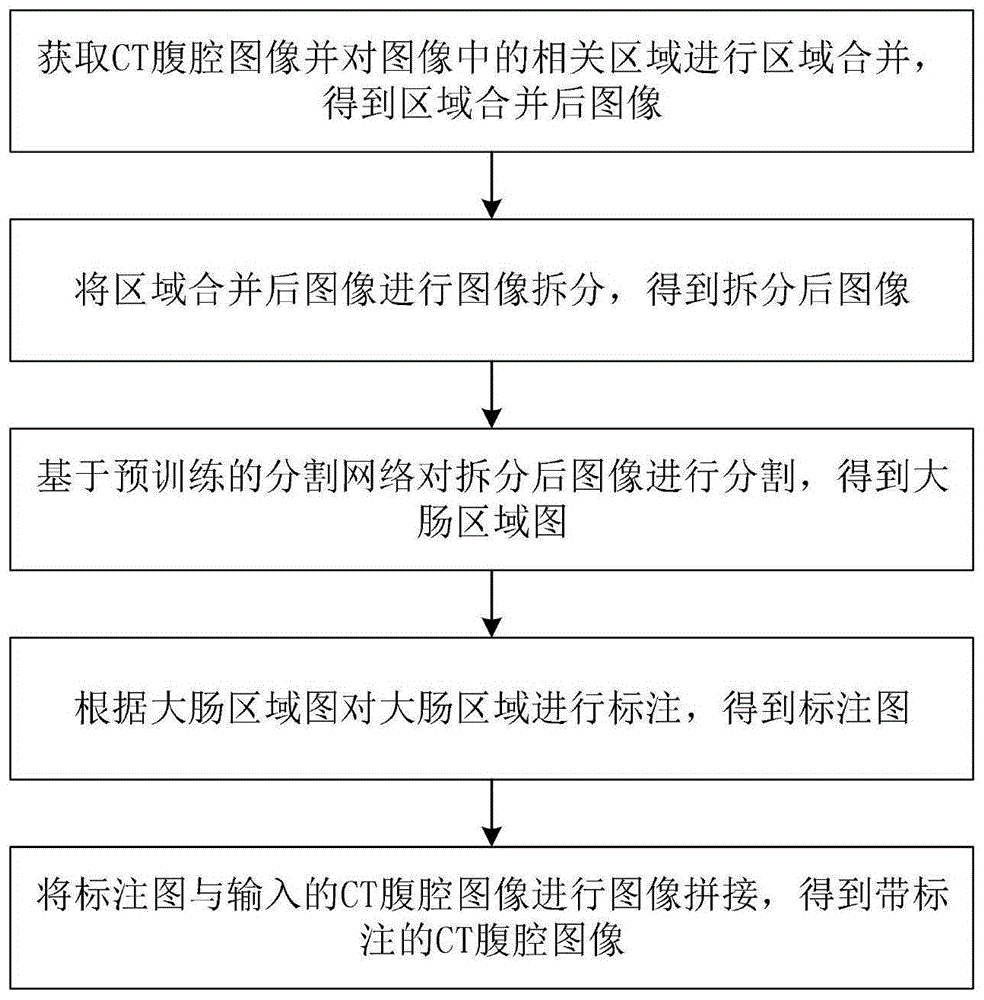
获取ct腹腔图像并对图像中的相关区域进行区域合并,得到区域合并后图像;
将区域合并后图像进行图像拆分,得到拆分后图像;
基于预训练的分割网络对拆分后图像进行分割,得到大肠区域图;
根据大肠区域图和输入的ct腹腔图,分别对大肠空腔区及肠内容物进行标注,得到标注图;
将标注图与输入的ct腹腔图像进行图像拼接,得到带标注的ct腹腔图像。
进一步,所述获取ct腹腔图像并对图像中的相关区域进行区域合并,得到区域合并后图像这一步骤,其具体包括:
获取ct腹腔图像;
将ct腹腔图像内与肠内容物颜色接近的像素点进行去除;
将去除部分像素点后的ct腹腔图像中的肠内容物区域和大肠空腔区域进行合并,得到区域合并后图像。
进一步,所述将区域合并后图像进行图像拆分,得到拆分后图像这一步骤,其具体包括:
将区域合并后图像等比率分割成3*3的图像块,并将相邻图层的同一对应位置的图像块组成一个五张图片形成的图像组,得到拆分后图像。
进一步,所述预训练的分割网络的训练步骤包括:
获取训练用ct腹腔图像并对训练用ct腹腔图像进行数据增强,得到增强训练图像;
将增强训练图像结合图像对应的真实标签,构建训练集;
基于训练集中的ct腹腔图像对预构建的分割网络进行训练,得到预测标签;
基于预测标签与对应的真实标签计算误差损失;
根据误差损失对预构建的分割网络进行参数更新,得到训练完成的分割网络。
进一步,所述预构建的分割网络包括编码器、带注意力机制的解码器、convlstm模块、和分类模块。
进一步,所述数据增强包括对图像平移、图像旋转和对图像进行gamma变换。
进一步,所述基于预训练的分割网络对拆分后图像进行分割,得到大肠区域图这一步骤,其具体包括:
基于编码器对输入的拆分后图像进行特征提取,得到特征信息;
基于convlstm模块连接各层编码器的特征信息并进行特征拼接,得到拼接后的特征信息;
基于带注意力机制的解码器将拼接后的特征信息还原;
基于分类模块输出属于大肠区域的像素点的概率值并将像素点整合,得到大肠区域图。
进一步,所述根据大肠区域图和输入的ct腹腔图,对大肠空腔区及肠内容物分别标注,得到标注图这一步骤,其具体包括:
根据大肠区域图在输入的ct腹腔图上确定大肠区域,并根据输入的ct腹腔图上大肠区域中的颜色差异分别对大肠空腔区和肠内容物进行标注,得到标注图。
本发明方法的有益效果是:本发明能够自动对输入的ct腹腔成像图像中的大肠区域及肠内容物区域进行标注,由于不需要手工标注,避免了人为失误,同时具有计算速度快,所占参数少的优点。
附图说明
图1是本发明一种基于深度学习的大肠空腔区及肠内容物标注方法的步骤流程图;
图2是本发明一种基于深度学习的大肠空腔区及肠内容物标注系统的结构框图;
图3是本发明具体实施例分割网络的示意图;
图4是本发明具体实施例ct腹腔图像原图;
图5是本发明具体实施例经过前处理模块后输出的图像;
图6是本发明具体实施例经过分割模块后输出的图像;
图7是本发明具体实施例拆分模块的数据处理示意图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步的详细说明。对于以下实施例中的步骤编号,其仅为了便于阐述说明而设置,对步骤之间的顺序不做任何限定,实施例中的各步骤的执行顺序均可根据本领域技术人员的理解来进行适应性调整。
参照图1,本发明提供了一种基于深度学习的大肠空腔区及肠内容物标注方法,该方法包括以下步骤:
获取ct腹腔图像并对图像中的相关区域进行区域合并,得到区域合并后图像;
将区域合并后图像进行图像拆分,得到拆分后图像;
基于预训练的分割网络对拆分后图像进行分割,得到大肠区域图;
根据大肠区域图和输入的ct腹腔图,分别对大肠空腔区及肠内容物进行标注,得到标注图;
具体地,标注阶段中,根据原图像的颜色差异进一步分辨出大肠空腔区域及肠内容物区域,即:
其中s表示分割网络所得结果中,标记为1的像素区域,image表示原图像,result表示最终的标记结果。
将标注图与输入的ct腹腔图像进行图像拼接,得到带标注的ct腹腔图像。
具体地,由于标记模块的result还只是原图像标记的一部分,即之前步骤进行了图像分块,因此还需要进行图像拼接,即:
r=concat(concat(result,axis=-1),axis=-1)
其中r为最终结果,concat()为拼接函数,参数一为需要拼接的图像,axis代表需要拼接的维度-1代表最后一个维度。
进一步作为本方法的优选实施例,所述获取ct腹腔图像并对图像中的相关区域进行区域合并,得到区域合并后图像这一步骤,其具体包括:
获取ct腹腔图像;
将ct腹腔图像内与肠内容物颜色接近的像素点进行去除;
将去除部分像素点后的ct腹腔图像中的肠内容物区域和大肠空腔区域进行合并,得到区域合并后图像。
具体地,ct腹腔图像原图参照图4,肠内容物形态差异极大,即各种肠内容物形状及其不规律而且没有特征,若直接以肠内容物或者大肠内空腔为分割目标,难以实现,因此这种前处理的操作可以将问题简化,即:
其中,f(x,y)表示原图片(x,y)处的灰度值,p(x,y)为转变后的图片(x,y)处的灰度值,0为空气的灰度值。经过该前处理后输出的图像参照图5.
另外,训练时带标签的ct腹腔图像经过前处理模块的过程如下所示:
其中,new_m(x,y)表示新得到的标注(x,y)处的hsv值,m(x,y)为原标注(x,y)处的hsv值,(l_rhsv,h_rhsv)为红色的hsv值所处范围,(l_ghsv,h_ghsv)为绿色的hsv值所处范围。经该前处理后输出的训练所用真实标签参照图6。
进一步作为本方法的优选实施例,所述将区域合并后图像进行图像拆分,得到拆分后图像这一步骤,其具体包括:
将区域合并后图像等比率分割成3*3的图像块,并将相邻图层的同一对应位置的图像块组成一个五张图片形成的图像组,得到拆分后图像。
具体地,由于需要进行处理的图片尺寸过大,无法接收多张原始图片的输入。因此需要先将图片等比率拆分成3*3小块。并将记录其所处的层数占总层数的比值(及该图层处于人体膈顶到耻骨联合的相对位置),以及它属于本张图片分割中的那个小块,即:
images(n,w,h)=>data(n-slices+1,slices,dx,dy)
其中,括号内为数据的维度,n张w宽h高的数据,转化为n-slices+1组slices张dx宽dy高的上下序列相邻图片组。
data=(images[k,i*dx:(i+1)dx,j*dy:(j+1)*dy],(i+1)*(j+1),k)
mark=(label[k,i*dx:(i+1)dx,j*dy:(j+1)*dy],(i+1)*(j+1),k)
其中,data为图片经拆分模块处理后的图片,images为经前处理模块得到图片,mark为标注经拆分模块处理后的结果,label为经前处理模块得到的标注,k为图片所处的层号,i为小块行号,j为小块列号,dx为每个小块的宽度,dy为每个小块的高度,(i+1)*(j+1)为该改组图片或标注所处对应层的块号,具体参照图7。
进一步作为本方法优选实施例,所述预训练的分割网络的训练步骤包括:
获取训练用ct腹腔图像并对训练用ct腹腔图像进行数据增强,得到增强训练图像;
将增强训练图像结合图像对应的真实标签,构建训练集;
基于训练集中的ct腹腔图像对预构建的分割网络进行训练,得到预测标签;
基于预测标签与对应的真实标签计算误差损失;
根据误差损失对预构建的分割网络进行参数更新,得到训练完成的分割网络。
进一步作为本方法优选实施例,所述预构建的分割网络包括编码器、带注意力机制的解码器、convlstm模块、和分类模块。
进一步作为本方法的优选实施例,所述数据增强包括对图像平移、图像旋转和对图像进行gamma变换。
具体地,为了提高模型的鲁棒性,将对输入数据采用上述任意一种方式进行数据增强处理。
进一步作为本方法的优选实施例,所述基于预训练的分割网络对拆分后图像进行分割,得到大肠区域图这一步骤,其具体包括:
基于编码器对输入的拆分后图像进行特征提取,得到特征信息;
基于convlstm模块连接各层编码器的特征信息并进行特征拼接,得到拼接后的特征信息;
基于带注意力机制的解码器将拼接后的特征信息还原;
基于分类模块输出属于大肠区域的像素点的概率值并将像素点整合,得到大肠区域图。
具体地,分割网络参照图3,编码器部分通过卷积网络和下采样进行图像的高层次特征提取,最终将得到只有原图1/16的特征图,此处处理输入的多张图片的编码器采用权值共享的策略;解码器部分通过卷积网络以及上采样编码将高层次特征还原为对于原始图片尺寸相同的特征图,此处处理输入的多张特征图的编码器采用权值共享的策略;注意力机制部分在进行解码器上采样编码的同时,在每个层次引入注意力机制,以该尺寸特征以及数据所属的层数占总层数的比值,数据块处于当前图层的位置作为输入值,进行注意力权值分配,调整解码器上采样解码重构信息;convlstm模块跳跃连接部分,将编码器编码所得的相邻图层各级特征进行层次间的信息挖掘,使得每个图层的特征不只是依照当前图层的各种特征信息,也取决于邻近图层的特征信息,最终处理好的特征信息与解码器每层上采样得到的特征进行特征拼接;分类模块部分通过全连接神经网络,将解码器的最后输出转化为每个像素点是否属于目标区域的概率值,经过分割网络后的输出图亦参照图6。
进一步作为本方法优选实施例,所述根据大肠区域图和输入的ct腹腔图,分别对大肠空腔区及肠内容物进行标注,得到标注图这一步骤,其具体包括:
根据大肠区域图在输入的ct腹腔图上确定大肠区域,并根据输入的ct腹腔图上大肠区域中的颜色差异分别对大肠空腔区和肠内容物进行标注,得到标注图。
参照图2,一种基于深度学习的大肠空腔区及肠内容物标注系统,包括以下模块:
前处理模块,用于获取ct腹腔图像并对图像中的相关区域进行区域合并,得到区域合并后图像;
拆分模块,用于将区域合并后图像进行图像拆分,得到拆分后图像;
分割模块,用于基于预训练的分割网络对拆分后图像进行分割,得到大肠区域图;
标注模块,用于根据大肠区域图和输入的ct腹腔图,对大肠空腔区及肠内容物分别标注,得到标注图;
图像拼接模块,用于将标注图与输入的ct腹腔图像进行图像拼接,得到带标注的ct腹腔图像。
一种基于深度学习的大肠空腔区及肠内容物标注装置:
至少一个处理器;
至少一个存储器,用于存储至少一个程序;
当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现如上所述一种基于深度学习的大肠空腔区及肠内容物标注方法。
上述方法实施例中的内容均适用于本装置实施例中,本装置实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法实施例所达到的有益效果也相同。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!