一种通过图像算法精准获取双向人流量的方法与流程
本发明涉及图像识别技术,尤其是一种通过图像算法精准获取双向人流量的方法。
背景技术:
获取商场出入口、园区出入口的人流量信息对于管理者而言是具有重要价值的信息,现有的人流量统计方法有很多种,但是检测精度都普遍不高,而且大部分只能在一个方向上进行检测,无法同时应对双向人流检测,而能够同时检测双向人流量的技术一般实现成本很高,如申请号为:201510066231.7的中国发明专利申请,公开了一种基于激光检测线的视觉分析人流量统计方法及设备,该方法通过网络摄像头从头顶采集包括两条激光线在内的某一出入口的人出入视频,提取出左右两条激光线作为左右两条检测线,生成高度轮廓线,判断是否为人经过,在匹配确定完成了一次人的进出后,就可以对进出的人流量统计,记录当前时间,可以统计出某段时间内某一出入口的进出人数,及通过两者之差得出场所内的已有人数,该设备由多个探测单元构成,每个探测单元包括视频采集设备、激光设备、还包括网络设备、计算机或嵌入式处理设备,上述方法虽然实现了人流量的检测,但是设备成本高,而且人流量大时统计的精确度也较低,无法满足使用需要。
目前随着人工智能技术的发展,针对目标检测的算法也日趋完善,近些年目标检测算法也从基于手工特征的传统算法转向了基于深度神经网络的检测技术。从最初2013年提出的r-cnn、overfeat,到后面的fast/fasterr-cnn,ssd,yolo系列,其中yolov5是2020年发布的yolo系列的最新版本,是现今最先进的对象检测技术,具有检测速度快,而且准确度高、漏检率低的优点。
过往技术往往通过检测后再加一个行人再识别跟踪器的两阶段方法实现行人的跟踪,其中行人再识别跟踪器需要将检测出的行人从画面中抠出送入特征提取神经网络进一步获得同人判别依据。在实际应用中,行人再识别跟踪器的算力需求随人员数量线性增长,人流量大时很难做到实时处理效果,从而间接提高了对硬件的要求,提高了生产成本。
鉴于此提出本发明。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种通过图像算法精准获取双向人流量的方法,通过该方法可以提高人流检测的准确度,实现双向人流量统计,并且本方法对芯片算力要求低,可以部署到边缘计算设备上使用。
为了实现该目的,本发明采用如下技术方案:
一种通过图像算法精准获取双向人流量的方法,包括以下步骤:
步骤一、获取开源的yolov5网络,并修改yolov5网络结构,增加4个输入通道和6个输出通道;
步骤二、采集并标注训练和测试数据集,对修改后的网络模型进行训练;
步骤三、将训练后的网络模型部署到fpga芯片上,并对网络结构进行计算图优化和算子级运算优化;
步骤四、通过摄像头读入实时视频,并输入网络模型推理获得检测框和每个检测框下一帧位置的预测值,通过跟踪器获取检测框对应的人员id;
步骤五、根据人员id和检测框的移动坐标队列生成相应的人员移动轨迹;
步骤六、根据生成的人员移动轨迹,判定人员移动方向,并统计双向人流量;
所述步骤一中,增加的4个通道用于输入上一帧的图像和其对应的heatmap渲染图,增加的6个输出通道用于输出当前帧图像相对上一帧图像的x、y方向的偏移向量。
进一步,所述heatmap渲染图通过计算每个检测框的中心点和检测框的尺寸后套入公式得到,所述公式为:
进一步,所述步骤二中,所述数据集由采集于目标场景下的多段视频组成,每段视频不少于20秒,并按照25帧每秒的速度提取为图片,训练集和测试集以视频段为单位进行划分,其对应比例为8:2。
进一步,所述标注过程为,按照人员出现的时间顺序分配id编号,对于被遮挡的人员在标注时需要标注可见比例。
进一步,所述步骤三中,先将训练好的网络模型转换为onnx模型,再用tvm读入onnx模型后进行图优化操作,最后使用vta模块在fpga芯片上进行部署和调优。
进一步,所述步骤四中的摄像头为广角摄像头,输入网络模型的图像分别率为960*544。
采用本发明所述的技术方案后,带来以下有益效果:
本发明通过在yolov5网络中添加对下一帧中对应检测框位置预测的方法,减少跟踪器的工作难度,从而省略掉跟踪器对行人再次提取特征值的步骤,大大降低算法对算力的需求,并且本发明可以实现较高的检测精度,能够同时统计双向人流量,且不需要复杂的硬件支撑。另一方面,本发明部署方法简单,对硬件性能要求不高,而且可以部署在边缘计算设备上,降低了服务器配置的成本,可以方便灵活的部署在需要的地方进行人流量检测。
附图说明
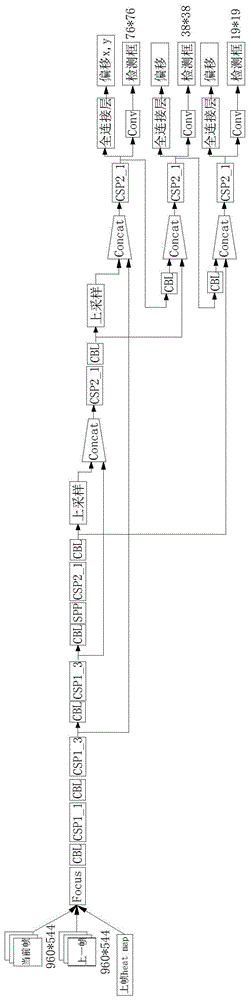
图1:本发明使用的yolov5网络结构图;
图2:本发明的流程图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步详细的描述。
如图1和图2所示,一种通过图像算法精准获取双向人流量的方法,包括以下步骤:
步骤一、获取开源的yolov5网络,并修改yolov5网络结构,增加4个输入通道和6个输出通道。其中,增加的4个通道用于输入上一帧的图像和其对应的heatmap渲染图,增加的6个输出通道用于输出当前帧图像相对上一帧图像的x、y方向的偏移向量。由于yolov5网络是分3个不同的分辨率输入图像,因此,在增加的4个输入通道中,3个用于输入不同分辨率的上一帧的图像,另一通道用于输入对应的heatmap渲染图。所述的6个输出通道分别为3个不同的分辨率输出对应的x、y方向的偏移向量,偏移向量的预测输出分别添加在三个csp模块处。所述heatmap渲染图通过计算每个检测框的中心点和检测框的尺寸后套入公式得到,所述公式为:
步骤二、采集并标注训练和测试数据集,对修改后的网络模型进行训练。具体地,所述数据集由采集于目标场景下的多段视频组成,每段视频不少于20秒,并按照25帧每秒的速度提取为图片,训练集和测试集以视频段为单位进行划分,其对应比例为8:2。优选地,所述标注工具为darklabel,导入视频后在每一帧图像标注检测框,按照人员出现的时间顺序分配id编号,对于被遮挡的人员在标注时需要标注可见比例,标注工具可以自动预测下一帧图像中对应框的位置和大小,一定程度上可以减少标注工作量,但仍需手动调整框的位置和大小。
具体地,训练的参数设置如下:
(1)输入分辨率宽960,高544(因网络结构下采样3次,需要是8的倍数);
(2)热力图输入扰动参数设置为0.05;
(3)检测框丢失扰动参数设置为0.2;
(4)检测框误检扰动参数设置为0.05;
(5)训练总迭代次数为70epochs;
(6)学习率为1.25×e-4。
步骤三、将训练后的网络模型部署到fpga芯片上,并对网络结构进行计算图优化和算子级运算优化,具体地部署方法为:先将训练好的网络模型转换为onnx模型,再用tvm读入onnx模型后进行图优化操作,最后使用vta模块在fpga芯片上进行部署和调优。目前深度学习框架众多,很多大公司都有自己开发的框架,如google的tensorflow、facebook的pytorch、亚马逊的mxnet、百度的padlepadle等。不同的框架下都会有开发者公开一些开源的深度学习模型,性能表现也各有所长,在项目落地时根据用户场景进行模型选型时,可能会涉及到多个不同框架下的模型。在部署算法的时候,如果不能统一框架将造成大量的算力浪费。tvm技术将不同框架下底层算子指令转换为统一的中间表达,解决了框架统一问题。另外tvm提供了大量专业人士做好的模型并行加速优化策略和基于强化学习的全自动优化策略,可以在模型转换为tvm统一中间表达后进一步优化模型运行性能。最后tvm实现了大量设备的代码自动生成方法,可以基于训练好的模型自动生成在不同设备上可部署的高效代码。
步骤四、通过摄像头读入实时视频,并输入网络模型推理获得检测框和每个检测框下一帧位置的预测值,通过跟踪器获取检测框对应的人员id,优选地,所述摄像头选用广角摄像头,所述跟踪器选用sklearn库的贪心算法跟踪器。
步骤五、根据人员id和检测框的移动坐标队列生成相应的人员移动轨迹,所述检测框的移动坐标队列优选为检测框的中心移动坐标队列。
步骤六、根据生成的人员移动轨迹,判定人员移动方向,并统计双向人流量,具体地,先指定设备安装方向(沿图像x轴或y轴),利用三角函数求解移动方向与指定方向的夹角,将夹角小于90度的方向定义为正方向,大于90度的方向定义为反方向,分别进行统计计数。
以上所述为本发明的实施方式,应当指出,对于本领域的普通技术人员而言,在不脱离本发明原理前提下,还可以做出多种变形和改进,这也应该视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!