一种带有超节点以及超节点控制器的众核处理器
本发明涉及嵌入式数字信号处理器,具体涉及一种带有超节点以及超节点控制器的众核处理器。
背景技术:
自20世纪90年代,斯坦福大学的研究人员提出所谓的“单片多处理器”,也称为“多核处理器”以来,多核结构逐渐成为通用处理器的主流,并按照摩尔定律发展,进入所谓的“众核时代”,即片内核心数量达到32以上,甚至数百核心。目前,众核处理器的主流结构是“通用中央处理器(cpu)核心+应用专用核心”的异构融合结构,应用专有核心又分为同构众核和异构众核两种结构。同构众核结构中核心的数量在32核以上,核间互连采用片上互连网络。随着核心数目的增多,内核与片上网络之间的互连结构(数据通道结构)的复杂度将会成倍的增加,这将导致互连线面积的急速增加,从而增加了长线延迟,降低了时钟频率。
技术实现要素:
本发明要解决的技术问题:针对现有众核处理器核心数目增加导致互连线面积的急速增加,从而增加了长线延迟,降低了时钟频率的问题,提供一种带有超节点以及超节点控制器的众核处理器,本发明提出一种超节点控制器(snc)结构,由几个内核组成一个超节点,且通过超节点控制器来实现几个内核与片上网络之间的数据交互,从而减少互连线的面积,避免长线延迟的影响,有利于减少处理器设计和验证的复杂性。
为了解决上述技术问题,本发明采用的技术方案为:
一种带有超节点以及超节点控制器的众核处理器,包括片上网络和至少一个与片上网络相连的超节点,所述超节点包括超节点控制器和多个内核,所述超节点控制器分别与片上网络以及各个内核相连,所述多个内核通过超节点控制器实现与片上网络之间的数据交互,所述超节点控制器中设有fifo以及数据仲裁器。
可选地,所述超节点控制器通过axi总线与片上网络相连,所述超节点控制器通过axi总线与各个内核相连。
可选地,所述超节点控制器中的fifo为读写同步fifo,所述读写同步fifo的组成包括地址控制部分和存储数据的ram部分。
可选地,所述片上网络中的数据传输通道包括读地址通道、读数据通道、写地址通道、写数据通道和写响应通道共五条数据传输通道,所述超节点控制器中的数据传输通道包括读地址通道、读数据通道、写通道和写响应通道四条数据传输通道,所述超节点控制器中的写通道同时与片上网络的写地址通道、写数据通道两者对接、其它的三条数据传输通道与片上网络的同名数据传输通道一一对接。
此外,本发明还提供一种前述带有超节点以及超节点控制器的众核处理器的应用方法,包括所述超节点控制器通过写通道执行数据交互的下述步骤:接收作为主机的内核向片上网络发送的写请求,写请求包括写地址和写数据;将写请求打包、存储、与读数据通道转发过来的数据一起进行仲裁、分发后发送到作为从机的片上网络;包括所述超节点控制器通过读数据通道执行数据交互的下述步骤:接收作为主机的片上网络向内核发送的读返回数据,根据读返回数据的控制信息选择处理方式,处理方式为转发或单播、广播两者中的一种,若处理方式为转发,则将读返回数据打包存储并将其输出给写通道进行仲裁,退出;否则,确定处理方式具体为单播还是广播,将读返回数据通过单播或广播、分发后发送到作为从机的内核;包括所述超节点控制器通过写响应通道执行数据交互的下述步骤:收到作为主机的片上网络发送写响应,将片上网络发送的写响应数据打包存储,然后向指定的内核进行单播操作、分发后发送到作为从机的内核;包括所述超节点控制器通过读地址通道执行数据交互的下述步骤:接收作为主机的内核向片上网络发送的读请求,将读请求打包、存储、仲裁、分发后发送到作为从机的片上网络。
可选地,所述单播的步骤包括:首先根据转换表将单播操作转换为对一个内核的广播操作,所述转换表中记录了内核的id、内核选择矢量、内核编号之间的映射关系;然后将待单播的数据按照内核数量复制多份,并根据内核选择矢量判定需要广播的目标内核,判断目标内核是否满足广播同步接收条件,若满足同步接收条件则进行广播操作,否则暂停广播操作并延后重试,直至完成广播操作;所述广播的步骤包括:后将待广播的数据按照内核数量复制多份,并根据内核选择矢量判定需要广播的目标内核,判断目标内核是否满足广播同步接收条件,若满足同步接收条件则进行广播操作,否则暂停广播操作并延后重试,直至完成广播操作。
可选地,所述读写同步fifo中存储数据的ram部分包括一个或多个堆栈,且所述堆栈的写方法包括:当一个堆栈为空时,读数据指针和写数据指针都指向堆栈中的第一个存储单元;当写入一个数据时,写数据指针将指向下一个存储单元;经过连续n-1个存储单元的写数据操作后,写指针将指向最后一个数据单元,经过连续n个存储单元的写数据操作后,写指针将回到首单元并且显示堆栈状态为满;当读出一个数据时,读数据指针将指向下一个存储单元,经过连续n-1个存储单元的读数据操作后,读指针将指向最后一个数据单元,经过连续n个存储单元的读数据操作后,此时读指针回到首单元,堆栈状态显示为空,其中n为堆栈中的存储单元数量。
可选地,所述数据仲裁器基于采用轮转的优先级来调整不同内核对应的输出通道的优先级,且针对任意当前优先级来进行数据仲裁的步骤包括:首先判断当前优先级对应的内核的输出通道的数据是否有效,如果数据有效,则直接输出当前优先级对应的内核的输出通道的数据;否则,按照指定的顺序判断其余内核的输出通道的数据是否有效,并选择输出第一个有效的数据。
可选地,所述将读返回数据打包存储并将其输出给写通道进行仲裁时,还包括对非对齐地址的数据进行处理的步骤:将读返回数据按照首地址的偏移分成两个数据,且将两个数据中的缺失部分用0填补以表示无效,然后把这两个数据转发到写通道进行仲裁。
可选地,还包括片外到片外传输的下述步骤:当内核dma从片外存储空间搬移到片外存储空间时,读返回的数据不用返回到dsp内核再从内核写入到片外,而是在超节点控制器中就将读返回数据转换成写请求并通过网络写入到片外存储空间中。
和现有技术相比,本发明具有下述优点:本发明包括片上网络和至少一个与片上网络相连的超节点,所述超节点包括超节点控制器和多个内核,所述超节点控制器分别与片上网络以及各个内核相连,所述多个内核通过超节点控制器实现与片上网络之间的数据交互,所述超节点控制器中设有fifo以及数据仲裁器,针对现有众核处理器核心数目增加导致互连线面积的急速增加,从而增加了长线延迟,降低了时钟频率的问题,提供一种带有超节点以及超节点控制器的众核处理器,本发明提出一种超节点控制器(snc)结构,由几个内核组成一个超节点,且通过超节点控制器来实现几个内核与片上网络之间的数据交互,从而减少互连线的面积,避免长线延迟的影响,有利于减少处理器设计和验证的复杂性。
附图说明
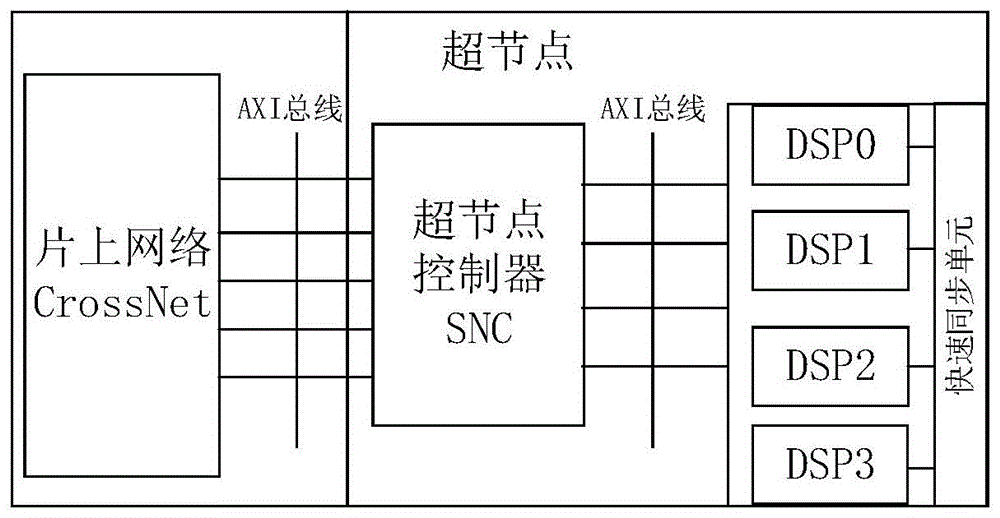
图1为本发明实施例中众核处理器的超节点结构示意图。
图2为本发明实施例中超节点的数据传输通道结构示意图。
图3为本发明实施例中超节点的数据传输通道的交互流程示意图。
图4为本发明实施例中读写fifo的过程示意图。
图5为本发明实施例中优先级为00时输出数据的流程示意图。
图6为本发明实施例中的数据广播过程图。
图7为本发明实施例中的非对齐数据的写入图。
图8为本发明实施例中的id、vector与dsp内核对应关系表。
具体实施方式
如图1所示,本实施例带有超节点以及超节点控制器的众核处理器包括片上网络和至少一个与片上网络相连的超节点,超节点包括超节点控制器和多个内核(本实施例中以4个dsp内核dsp0~dsp3进行示例),超节点控制器分别与片上网络以及各个内核相连,多个内核通过超节点控制器实现与片上网络之间的数据交互,超节点控制器中设有fifo以及数据仲裁器。本实施例带有超节点以及超节点控制器的众核处理器考虑到过多的内核数量,采用超节点结构,通过超节点控制器实现内核与片上网络之间的数据交互。本发明通过在超节点控制器加入从片外到片外的传输通路,大大缓解了读返回数据通过内核转换到片外导致的内核网络拥塞,这种方式在多个内核与片上网络之间建立了单独的中转控制中心,能够在超节点控制器中实现交互数据的存储、仲裁、转发、分发和广播等操作,减少设计的复杂度,降低长线延迟的影响,极大地提高数据吞吐能力。此外,参见图1,本实施例中还包括1个快速同步单元,用于实现4个dsp内核之间的数据快速同步。需要说明的是,本实施例带有超节点以及超节点控制器的众核处理器中的内核并不局限于dsp内核,还可以适用于包括cpu内核、gpu内核在内的各类通用或专用内核。
如图1所示,超节点控制器通过axi总线与片上网络相连,超节点控制器通过axi总线与各个内核相连。在采用超节点结构的基础上,本实施例中根据众核处理器的整体结构,基于高级可拓展接口(axi)协议,设计了snc作为内核与片上网络之间进行数据交换的中转控制中心,实现内核与片上网络之间的数据交互。片上网络与snc都采用了axi总线协议。axi总线协议是arm公司推出的一种面向高性能、高带宽、低延迟的片内总线,得到了整个半导体行业的广泛认可和采用,这是因为axi协议具备以下技术优势:(1)分离的地址/控制和数据通道;(2)采用字节选通的方式支持不对齐数据的传输;(3)通道支持多项数据交换,通过并行执行的burst猝发操作,极大地提高数据吞吐能力;(4)增强的灵活性。这些技术特点使得axi总线协议可以运行在更好的时钟频率,在相同的时钟频率下可以提供更高的数据吞吐量。同时axi协议具有更高的数据总线带宽、支持乱序访问和非对齐操作等优势,基于axi总线协议的芯片硬件设计也具有更好的灵活性和可移植性。
作为一种可选的实施方式,本实施例中超节点控制器中的fifo为读写同步fifo,读写同步fifo的组成包括地址控制部分和存储数据的ram部分,片上网络中的数据传输通道里每一个通道都包含一个同步fifo。读写同步fifo只能顺序写入数据和顺序读出数据,其数据地址由内部读写指针自动加1完成,不能像普通存储器那样可以由地址线决定读取或写入某个制定的地址。读写同步fifo有两个地址指针,一个用于将数据写入下一个可用的存储单元,一个用于读取下一个未读存储单元。读写数据必须一次进行。
如图1所示,片上网络中的数据传输通道包括读地址通道、读数据通道、写地址通道、写数据通道和写响应通道共五条数据传输通道,所述超节点控制器中的数据传输通道包括读地址通道、读数据通道、写通道和写响应通道四条数据传输通道,所述超节点控制器中的写通道同时与片上网络的写地址通道、写数据通道两者对接、其它的三条数据传输通道与片上网络的同名数据传输通道一一对接。超节点控制器和4个dsp内核dsp0~dsp3之间的交互,是通过超节点控制器中的读地址通道、读数据通道、写通道和写响应通道四条数据传输通道完成的。
此外,本实施例还提供一种前述带有超节点以及超节点控制器的众核处理器的应用方法包括读地址通道、读数据通道、写通道和写响应通道四条数据传输通道的实现方法。
如图3中子图(a)所示,包括所述超节点控制器通过写通道执行数据交互的下述步骤:接收作为主机的内核向片上网络发送的写请求,写请求包括写地址和写数据;将写请求打包、存储、与读数据通道转发过来的数据一起进行仲裁、分发后发送到作为从机的片上网络;在写通道中,4个dsp内核作为主机,负责向片上网络发送写地址和写数据,然后超节点控制器通过对4个dsp内核发送的地址、数据和控制信息进行打包、存储、仲裁(仲裁还包括读数据通道转发过来的数据)和分发等操作,发送到片上网络,也就是从机。如图3中子图(b)所示,包括超节点控制器通过读数据通道执行数据交互的下述步骤:接收作为主机的片上网络向内核发送的读返回数据,根据读返回数据的控制信息选择处理方式,处理方式为转发或单播、广播两者中的一种,若处理方式为转发,则将读返回数据打包存储并将其输出给写通道进行仲裁,退出;否则,确定处理方式具体为单播还是广播,将读返回数据通过单播或广播、分发后发送到作为从机的内核;在读数据通道中,片上网络作为超节点控制器的主机,dsp内核作为超节点控制器的从机。如果读请求被响应,读返回数据就会经由片上网络,再在超节点控制器经过打包、转发、单播/广播、分发等操作,发送到对应的dsp内核或者转发到网络中。如图3中子图(c)所示,包括超节点控制器通过写响应通道执行数据交互的下述步骤:收到作为主机的片上网络发送写响应,将片上网络发送的写响应数据打包存储,然后向指定的内核进行单播操作、分发后发送到作为从机的内核;在写响应通道中,片上网络作为超节点控制器的主机,负责向超节点控制器发送写交易响应信息,然后超节点控制器通过对写交易响应数据的打包、存储、单播、分发等操作,发送到对应的dsp内核。如图3中子图(d)所示,包括超节点控制器通过读地址通道执行数据交互的下述步骤:接收作为主机的内核向片上网络发送的读请求,将读请求打包、存储、仲裁、分发后发送到作为从机的片上网络。在读地址通道中,4个dsp内核作为主机,负责向片上网络发送读请求,然后超节点控制器通过对4个dsp内核发送的地址和控制信息进行打包、存储、仲裁和分发等操作,发送到片上网络,也就是从机。
本实施例中,单播的步骤包括:首先根据转换表(如图8所示)将单播操作转换为对一个内核的广播操作,所述转换表中记录了内核的id、内核选择矢量、内核编号之间的映射关系;然后将待单播的数据按照内核数量复制多份,并根据内核选择矢量判定需要广播的目标内核,判断目标内核是否满足广播同步接收条件,若满足同步接收条件则进行广播操作,否则暂停广播操作并延后重试,直至完成广播操作;广播的步骤包括:后将待广播的数据按照内核数量复制多份,并根据内核选择矢量判定需要广播的目标内核,判断目标内核是否满足广播同步接收条件,若满足同步接收条件则进行广播操作,否则暂停广播操作并延后重试,直至完成广播操作。本实施例中读返回数据通过超节点控制器发送到4个dsp内核的过程,经过了单播或广播操作。单播操作就是根据读返回的id信号,把读返回数据发送到具体的dsp内核;广播操作就是根据读返回的4位内核选择矢量(vector,如图8所示,每一位对应一个dsp内核),把读返回数据发送到对应的1、2、3、4个dsp内核。例如,按要求的对齐地址的低六位应为0×000_000,若传输数据中的地址低六位为0×001_000(或0×002_000、0×003_000),则称之为非对齐地址数据。图6是本实施例中数据广播过程图。本实施例中,单播/广播的实现分为两个阶段:第一阶段就是单播向广播的转换,在vector信号无效时,单播操作其实就是对一个dsp内核的广播操作。按照图8所示的对应关系,当进行单播操作时,就转换为对一个dsp内核的广播操作。第二阶段就是广播操作的实现,具体过程如图7所示,首先把广播的data,复制为四个数据data0、data1、data2、data3;然后根据vector信号判定需要广播的dsp内核;最后判断需要接收广播数据的dsp内核是否满足广播同步接收条件。如果满足条件,则进行广播操作;如果不满足条件,则广播操作暂停。
本实施例中,所述读写同步fifo中存储数据的ram部分包括一个或多个堆栈,且所述堆栈的写方法包括:当一个堆栈为空时,读数据指针和写数据指针都指向堆栈中的第一个存储单元;当写入一个数据时,写数据指针将指向下一个存储单元;经过连续n-1个存储单元的写数据操作后,写指针将指向最后一个数据单元,经过连续n个存储单元的写数据操作后,写指针将回到首单元并且显示堆栈状态为满;当读出一个数据时,读数据指针将指向下一个存储单元,经过连续n-1个存储单元的读数据操作后,读指针将指向最后一个数据单元,经过连续n个存储单元的读数据操作后,此时读指针回到首单元,堆栈状态显示为空,其中n为堆栈中的存储单元数量。图4是本发明读写fifo过程示意图,其中堆栈中的存储单元数量为4:当一个堆栈为空时,读数据指针和写数据指针都指向第一个存储单元;当写入一个数据时,写数据指针将指向下一个存储单元;经过三次写数据操作后,写指针将指向最后一个数据单元;当经过连续四次写操作之后写指针将回到首单元并且显示堆栈状态为满。数据的读操作和写操作相似,当读出一个数据时,读数据指针将移向下一个存储单元,直到读出全部的数据,此时读指针回到首单元,堆栈状态显示为空。
本实施例中,数据仲裁器基于采用轮转的优先级来调整不同内核对应的输出通道的优先级,且针对任意当前优先级来进行数据仲裁的步骤包括:首先判断当前优先级对应的内核的输出通道的数据是否有效,如果数据有效,则直接输出当前优先级对应的内核的输出通道的数据;否则,按照指定的顺序判断其余内核的输出通道的数据是否有效,并选择输出第一个有效的数据。本实施例中轮转仲裁的方式进行数据仲裁,如图3(中数据仲裁,分为两个阶段:优先级(pri)信号的循环和输出数据的循环。在4选1的数据仲裁中,使用2位的pri信号来控制4条通道的优先级,pri=00时,0通道输出数据的优先级最高;pri=1时,1通道输出数据的优先级最高;pri=2时,2通道输出数据的优先级最高;pri=3时,3通道输出数据的优先级最高。图5是本发明优先级为00时输出数据的示例,当pri=00时,0通道中输出数据的优先级最高,所以先判断0通道中数据是否有效,如果数据有效,就输出0通道中的数据,然后依次判断1、2、3通道中的数据是否有效;如果0通道中的数据无效,就依次判断1、2、3通道中的数据是否有效。
本实施例中,将读返回数据打包存储并将其输出给写通道进行仲裁时,还包括对非对齐地址的数据进行处理的步骤:将读返回数据按照首地址的偏移分成两个数据,且将两个数据中的缺失部分用0填补以表示无效,然后把这两个数据转发到写通道进行仲裁。本实施例中非对齐地址的数据传输为在超节点控制器的读数据通道中,读返回数据在满足转发条件时,会转发到写通道,并写入存储空间ddr或gsm(全局共享存储空间),而读返回数据中的地址不符合对齐地址要求,则称此数据为非对齐地址的数据。图7是本实施例中的非对齐数据的写入原理示意图,在超节点控制器的读数据通道中,读返回数据在满足转发条件时,会转发到写通道,并写入存储空间(ddr或gsm)。在读数据通道转发到写通道的过程中,要对非对齐地址的数据进行处理。把传输的数据按照首地址的偏移分成两个数据,虚线左边数据fedc和虚线右边数据ba98,两个数据中的缺失部分用0填补(表示无效),然后把这两个数据转发到写通道。
本实施例中,还包括片外到片外传输的下述步骤:当内核dma从片外存储空间(ddr或gsm)搬移到片外存储空间(ddr或gsm)时,读返回的数据不用返回到dsp内核再从内核写入到片外,而是在超节点控制器中就将读返回数据转换成写请求并通过网络写入到片外存储空间中,这种传输方式能够大大减少数据对内核带宽和存储空间的占用,减少传输的延迟并且具有较小的硬件开销。
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!