一种基于KPLSR模型的污水处理出水总氮浓度软测量方法
本发明涉及一种污水出水总氮浓度的软测量方法,特别涉及一种基于kplsr模型的污水处理出水总氮浓度软测量方法。
背景技术:
近年来,随着经济的发展,越来越多含氮污染物的任意排放给环境造成了极大的危害。氮在污水中以有机态氮、氨态氮(nh4+-n)、硝态氮(no3--n)以及亚硝态氮(no2--n)等多种形式存在,而氨态氮是最主要的存在形式之一,污水中的总氮浓度就是这些含氮有机化合物的浓度总和。污水中的氨氮是指以游离氨和离子铵形式存在的氮,主要来源于生活污水中含氮有机物的分解,焦化、合成氨等工业废水等。氨氮污染源多,并且还会散发出恶臭味,会直接影响人们的工作与生活。随着对环境问题的愈发重视,已经相应的规章制度规定经过污水处理后的出水总氮浓度的上限。
污水处理厂或污水处理系统为了降低污水出水口的总氮含量,通常是在曝气池氧化沟中进行投料,通过生物和化学反应将污水中的含氮成分转化为可利用的其他物质,比如:农作物的肥料。由于污水的来源众多,且总氮浓度波动较大,需要实时测量出水口总氮含量,从而及时调控曝气池中的投料量,从而使排放的污水中总氮浓度符合相应法律法规的要求。然而,现阶段能直接快速测量污水中总氮浓度的仪器仪表购置价格高昂,后期使用与维护成分同样是一笔不小的开支。在当前自动化程度普遍较低的污水处理厂中,通常不会采购高价格的仪器仪表设备。取而代之的是,通过人工取样的手段,进行总氮浓度的测量。虽然这种技术手段精确度较高,但是主要依赖人工操作,实时性较差。
在这种背景下,利用历史数据实施出水总氮浓度的软测量就被提上议程了。出水总氮浓度软测量的基本思想是利用其它测量数据,包括:入水流量、污水温度、悬浮物固体浓度、投料量等等,实时预测出水口的总氮浓度。然而,软测量技术实施成功与否关键在于,如何选择用于预测出水总氮浓度的辅助变量。虽然,污水处理厂可每天需要测量的数据很多,但是只有部分变量在建立软测量模型时能起到关键的作用。考虑到污水处理过程的生化反应复杂性,依靠经验选择辅助变量通常是不可靠。若是经验不可用或经验有误,则会导致出水总氮浓度测量精度达不到要求。
技术实现要素:
本发明所要解决的主要技术问题是:如何选择有益的辅助变量以及如何确定核偏最小二乘回归(kernelpartialleastsqaureregression,缩写:kplsr)模型的参数,从而提升出水总氮浓度软测量模型的精度。具体来讲,本发明方法首先通过差分进化算法优化求解近邻成分分析的目标函数,从而实施不依赖于经验的辅助变量选择;其次,本发明方法通过融合利用不同核函数的kplsr模型,来避免kplsr模型参数的选择问题;最后,利用选择的辅助变量实施基于kplsr模型的出水总氮浓度实时软测量。
本发明方法解决上述问题所采用的技术方案为:一种基于kplsr模型的污水处理出水总氮浓度软测量方法,包括以下所示步骤:
步骤(1):确定污水处理厂每天可测量的变量;其中,污水处理厂入水处可测量的变量依次包括:入水流量,入水温度,入水色度,入水氯离子浓度,入水悬浮物固体浓度,入水ph值;曝气池中可测量的变量依次包括:投料量,污水色度,污水悬浮物固体浓度,污水ph值,污水氯离子浓度,生化需氧量;沉淀池中可测量的变量依次是:污水色度,污水悬浮物固体浓度,污水ph值,污水氯离子浓度,污泥量;污水处理厂出水处可测量的变量具体包括:出水色度,出水ph值,出水悬浮物固体浓度,和出水总氮浓度。
步骤(2):连续采集n天的数据,并将每天的数据存储为一个m×1维的数据向量xi;其中,第i天的数据向量xi中的元素是按照步骤(1)中所述变量的先后顺序排列,m等于步骤(1)中可测量的变量总数,i∈{1,2,…,n}。
步骤(3):将n天的数据向量x1,x2,…,xn组建成一个数据矩阵x=[x1,x2,…,xn]t后,对x∈rn×m中的各个列向量分别实施标准化处理,得到标准化后的数据矩阵
步骤(4):将
步骤(4.1):初始化迭代次数g=1并确定差分进化优化算法的参数,具体包括:种群个数n,缩放因子zf,交叉概率cp,最大迭代次数g。
步骤(4.2):随机产生n个(m-1)×1维的种群向量w1,w2,…,wn,每个种群向量中的元素都按照均匀分布随机取值于区间[-1,1]。
步骤(4.3):计算种群向量w1,w2,…,wn分别对应的目标函数值f1,f2,…,fn;其中,计算第c个种群向量wc对应的目标函数值fc的具体实施过程如步骤(4.3-1)至步骤(4.3-4)所示。
步骤(4.3-1):根据如下所示公式计算矩阵
其中,i∈{1,2,…,n},j∈{1,2,…,n},diag{wc}表示将种群向量wc转变为一个对角矩阵,符号||||表示计算向量的长度,c∈{1,2,…,n}。
步骤(4.3-2):根据如下所示公式计算
上式中,exp()表示以自然常数e为底数的指数函数。
步骤(4.3-3):根据如下所示公式计算输出概率误差f1,f2,…,fn:
上式中,
步骤(4.3-4):计算第c个种群向量wc对应的目标函数值fc=f1+f2+…+fn。
步骤(4.4):将f1,f2,…,fn中的最大值及其对应的种群向量分别记录为fbest和wbest后,执行差分进化算法的种群更新操作,得到更新后的n个种群向量w1,w2,…,wn,具体的实施过程如步骤(4.4-1)至步骤(4.4-4)所示。
步骤(4.4-1):根据如下所示公式为每个种群向量产生一个对应的变异向量vc:
vc=wc+zf×(wbest-wc)+zf×(wa-wb)④
上式中,下标号a与b是从区间[1,n]中随机产生的2个互不相等的整数。
步骤(4.4-2):按照如下所示公式对变异向量vc进行修正:
上式中,vc(k)表示变异向量vc中的第k个元素,k∈{1,2,…,m-1}。
步骤(4.4-3):根据如下所示公式产生n个尝试向量u1,u2,…,un:
其中,uc(k)与wc(k)分别为uc与wc中的第k个元素,表示0至1之间的随机数。
步骤(4.4-4):依据如下所示公式更新种群向量w1,w2,…,wn:
上式中,
步骤(4.5):判断是否满足条件g>g;若否,则设置g=g+1后返回步骤(4.3);若是,则得到最优的种群向量wbest。
步骤(4.6):按照如下所示公式确定出选择向量v∈r1×(m-1)中的各个元素:
上式中,v(k)和wbest(k)分别表示v和wbest中的第k个元素,η为阈值,其建议取值范围是0.01≤η≤0.1。
步骤(5):根据选择向量v中等于1的元素所在的列,对应的将
步骤(6):分别根据如下所示的三个核函数g1(ε1,ε2),g2(ε1,ε2),和g3(ε1,ε2),建立三个不同的kplsr模型后,计算得到输出估计向量
其中,ε1和ε2表示核函数的两个输入行向量,α和β为核函数的参数。
步骤(6.1):根据公式kd(i,j)=gd(zi,zj)计算核矩阵kd∈rn×n中的第i行第j列元素kd(i,j);其中,d∈{1,2,3},zi和zj分别表示输入矩阵z中的第i行和第j行的行向量。
步骤(6.2):根据如下所示公式对核矩阵k1,k2,k3进行中心化处理,对应得到中心化处理后的核矩阵
其中,方阵θ∈rn×n中所有元素都等于1。
步骤(6.3):依次设置d=1,2和3,并执行如下所示步骤(6.3-1)至步骤(6.3-4),从而得到kplsr模型的核回归系数向量θ1,θ2,θ3。
步骤(6.3-1):初始化γ=1,
步骤(6.3-2):根据公式sγ=k0q与
步骤(6.3-3):判断是否满足条件:
步骤(6.3-4):根据公式
步骤(6.4):根据公式
步骤(7):根据公式
步骤(8):采集污水处理厂新一天的测量数据,并将其存储为一个1×(m-1)维的数据向量xt;其中,数据向量xt中的元素是按照步骤(1)中所述的前m-1个变量的先后顺序依次排列,下标号t表示最新的一天。
步骤(9):对数据向量xt中各列的元素实施与步骤(3)中相同的标准化处理,得到标准化后的数据向量
步骤(10):调用步骤(4)中辅助变量的选择向量v∈r1×(m-1),并根据v中等于1的元素所在的列,对应的将xt中相同列的元素组成输入向量zt。
步骤(11):根据公式kd(i)=gd(zt,zi)计算核向量kd∈r1×n中的第i个元素kd(i),重复本步骤直至得到三个核向量k1,k2,k3。
步骤(12):根据如下所示步骤(12.1)至步骤(12.3)计算得到出水总氮浓度的软测量值yt。
步骤(12.1):根据如下所示公式分别对k1,k2,k3实施中心化处理,对应得到
其中,φ∈r1×n中所有元素都等于1。
步骤(12.2):根据公式
步骤(12.3):根据公式
通过以上所述实施步骤,本发明方法的优势介绍如下。
本发明方法的最大优势在于:不依赖于污水处理过程的机理知识以及技术人员的主观经验,直接通过数据驱动的角度实现了特征变量的优选。此外,充分利用三类经典的核函数,分别建立三个不同的kplsr模型,避免了核函数的选择问题。最后,进一步通过最小二乘回归将三个不同kplsr模型的输出进行合并,对于预测结果的精度能有较充分的保障。
附图说明
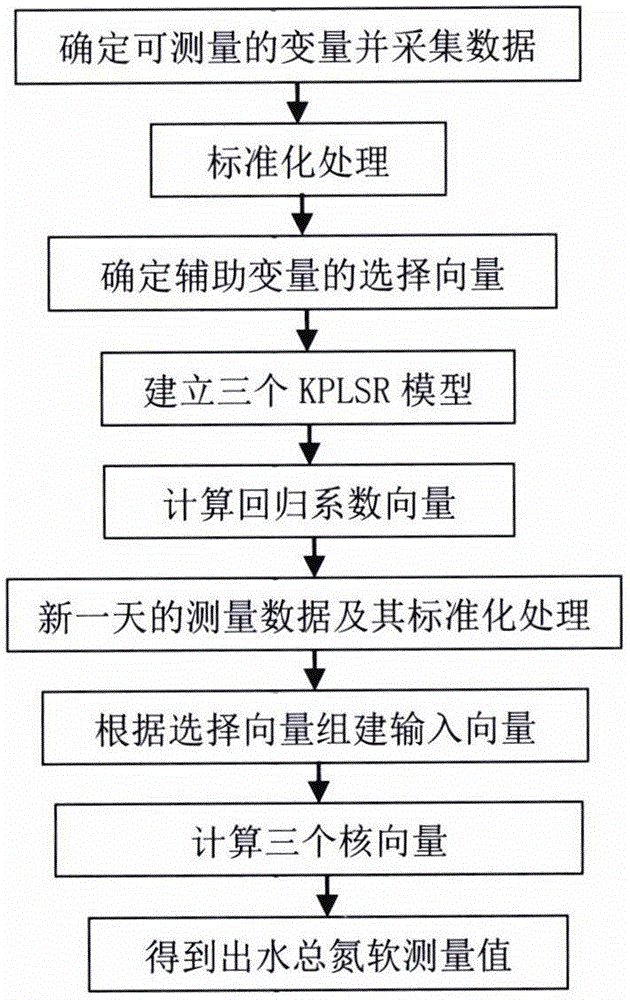
图1为本发明方法的实施流程示意图。
图2为污水处理厂的流程示意图。
图3为出水总氮浓度的软测量与实测值之间的误差对比图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
如图1所示,本发明公开了一种基于kplsr模型的污水处理出水总氮浓度软测量方法,下面结合一个具体应用实例来说明本发明方法的具体实施方式。
本实施案例中的污水处理厂的流程如图2所示。在本实施案例中,共连续采集了212天的数据;其中,将前112天的数据向量用于软测量模型的离线建模阶段,后100天的数据向量分别被当成新一天采样的数据向量,用于验证出水总氮的软测量精度。首先,实施如下所示步骤(1)至步骤(7),从而建立出水总氮的软测量模型。
步骤(1):确定污水处理厂每天可测量的变量:污水处理厂入水处可测量的变量具体包括:入水流量qin,入水温度tin,入水色度cin,入水氯离子浓度clin,入水悬浮物固体浓度din,入水ph值pin;曝气池中可测量的变量具体包括:投料量qa,污水色度ca,污水悬浮物固体浓度da,污水ph值pa,污水氯离子浓度cla,生化需氧量oa;沉淀池中可测量的变量具体包括:污水色度cs,污水悬浮物固体浓度ds,污水ph值ps,污水氯离子浓度cls,污泥量vs;污水处理厂出水处可测量的变量具体包括:出水色度co,出水ph值po,出水悬浮物固体浓度do,和出水总氮浓度tn。
步骤(2):连续采集n天的数据,并将每天的数据存储为一个m×1维的数据向量xi;其中,m表示步骤(1)中可测量的变量总数。
步骤(3):将n天的数据向量x1,x2,…,xn组建成一个数据矩阵x=[x1,x2,…,xn]t后,对x∈rn×m中的各个列向量分别实施标准化处理,得到标准化后的数据矩阵
步骤(4):将
步骤(5):根据选择向量v中等于1的元素所在的列,对应的将
步骤(6):分别根据如下所示的三个核函数g1(ε1,ε2),g2(ε1,ε2),和g3(ε1,ε2),建立三个不同的kplsr模型后,计算得到输出估计向量
步骤(7):根据公式
完成上述步骤(1)至步骤(7)后,即可实施出水总氮浓度的软测量,即实施如下所示步骤(8)至步骤(12)。
步骤(8):采集污水处理厂新一天的m-1个测量数据,并将其存储为一个1×(m-1)维的数据向量xt;其中,下标号t表示最新的一天,数据向量xt中的元素的先后排列顺序依次为:入水流量qin,入水温度tin,入水色度cin,入水氯离子浓度clin,入水悬浮物固体浓度din,入水ph值pin;曝气池中可测量的变量具体包括:投料量qa,污水色度ca,污水悬浮物固体浓度da,污水ph值pa,污水氯离子浓度cla,生化需氧量oa;沉淀池中可测量的变量具体包括:污水色度cs,污水悬浮物固体浓度ds,污水ph值ps,污水氯离子浓度cls,污泥量vs;污水处理厂出水处可测量的变量具体包括:出水色度co,出水ph值po,出水悬浮物固体浓度do。
步骤(9):对数据向量xt中各列元素实施与步骤(3)中相同的标准化处理,得到标准化后的数据向量
步骤(10):根据选择向量v∈r1×(m-1)中等于1的元素所在列,对应的将xt中相同列的元素组建成输入向量zt。
步骤(11):根据公式kd(i)=gd(zt,zi)计算核向量kd∈r1×n中的第i个元素kd(i),重复本步骤直至得到三个核向量k1,k2,k3。
步骤(12):通过步骤(6)中的三个kplsr模型以及步骤(7)中的回归系数向量θo,计算得到出水总氮浓度的软测量值yt,具体的实施过程如步骤(12.1)至步骤(12.3)所示。
通过对比步骤(12)中的出水总氮浓度的软测量值与实际通过化学手段测量得到的出水总氮浓度测量值进行对比,相应的对比结果展示于图3中。从图3中可以看出,本发明方法具备较强的软测量精度,误差变化在可接受变化范围内。
- 还没有人留言评论。精彩留言会获得点赞!