一种教室空座查询系统、实时视频分析系统及方法与流程
本发明涉及视频分析技术领域,特别涉及一种教室空座查询系统、实时视频分析系统及方法。
背景技术:
目前,随着大学生数量增多,高校的教室资源越来越紧张,大学生上自习而找不到合适的教室,是目前普遍存在的问题,尤其是期末复习的时候,自习室的空座很难找,可能跑了几个教室都找不到合适的位置,浪费了时间还影响学习心情,对学生来说是极大的不方便。
现有的自习室空座系统,大多采用软硬件结合的方式,需要每个座位安装传感器,通过物理传压的方式感知座位是否有人,然后通过单片机与显示器相连,传输结果。或者在座位上安装校园读卡器计数传给数据显示中心。这些方式一是耗费资源,大范围推广也不方便,二是从学生角度使用起来也不方便。
随着深度学习的发展日趋成熟,很多深度学习的算法可以用于工业生产,因此,如何提出了一种基于实时视频分析的教室空座查询方法及系统,不需要安装各种硬件系统,是目前亟待解决的问题。
技术实现要素:
本发明实施例提供了一种教室空座查询系统,以解决现有技术中需要软硬件结合检测自习室空座的问题。为了对披露的实施例的一些方面有一个基本的理解,下面给出了简单的概括。该概括部分不是泛泛评述,也不是要确定关键/重要组成元素或描绘这些实施例的保护范围。其唯一目的是用简单的形式呈现一些概念,以此作为后面的详细说明的序言。
根据本发明实施例的第一方面,提供了一种实时视频分析系统。
在一些可选实施例中,实时视频分析系统采用yolov4-tiny网络对多路视频流数据进行实时分析,yolov4-tiny网络包括cspdarknet53-tiny网络、fpn网络和yolov3网络;首先通过cspdarknet53-tiny网络提取输入图片的特征,得到两个不同大小的特征图,然后通过fpn网络进行特征融合和处理,最后连接yolov3网络输出结果。
可选地,输入到yolov4-tiny网络的图像经过卷积层、正则化和激活层操作,得到第一特征图;
将第一特征图再经过卷积层、正则化和激活层操作,得到第二特征图;将第二特征图经过残差块的操作后得到第三特征图,接着经过残差块的操作后变换成第四特征图,然后分成两路,第一路直接进入fpn模块,通过卷积层进行候选框的选取;第二路继续经过一个残差块的操作后得到第五特征图,再经过卷积层、正则化和激活层的操作后得到第六特征图,然进入fpn模块的卷积层进行候选框的选择,然后又分成两路,一路直接进入yolov3网络预测结果,另一路通过卷积和上采样操作,与第一路直接进入fpn的第四特征图进行张量拼接,扩充张量的维度,拼接后获得的第七特征图再进行卷积操作,最后进入yolov3网络预测结果。
可选地,所述yolov3网络将未经过张量拼接处理的特征图分成13*13个gridcells,如果groundtruth中某个目标的中心坐标落在某个gridcell中,那么就由该gridcell来预测该目标;每个gridccell都会预测3个固定数量的边界框,13*13特征图的感受野最大,因此其anchorbox的尺寸最大,分别为116*90,156*198,373*326,适合检测较大的目标;对经过张量拼接处理的特征图应用较小的anchorbox,分别为30*61,62*45,59*119,适合检测小目标。
可选地,对于训练图片中的groundtruth,若其中心点落在某个cell内,那么该cell内的3个anchorbox负责预测该groundtruth,由与groundtruth的iou最大的anchorbox预测该groundtruth,而剩余的2个anchorbox不与该groundtruth匹配。
可选地,所述yolov3网络假定每个cell至多含有一个groundtruth,与groundtruth匹配的anchorbox计算坐标误差、置信度误差以及分类误差,而其它的anchorbox只计算置信度误差。
可选地,所述yolov3网络使用逻辑回归预测每个先验边界框的目标性得分,通过计算先验边界框与groundtruth的重叠面积来进行目标评分;通过阈值来筛选先验边界框,对于重叠面积小于阈值的先验边界框直接去掉,如果先验边界框与groundtruth目标比其他目标重叠多,则相应的目标性得分应为1。
根据本发明实施例的第二方面,提供了一种实时视频分析方法。
在一些可选实施例中,所述实时视频分析方法,基于deepstreamsdk开发,运行在jetsonnano平台上,jetsonnano平台内置cuda、opencv和tensorrt模块,包括以下步骤:
步骤(1),捕获视频流数据;
步骤(2),解码视频流数据;
步骤(3),解码之后,对视频流数据进行预处理;
步骤(4),将多路视频流数据组合到一起进行批处理;
步骤(5),采用yolov4-tiny网络对多路视频流数据进行实时分析,执行目标检测,将推理结果沿管道传递到下一个插件;
步骤(6),将推理结果对应的文字等信息附加到元数据上,可显示在屏幕上;
步骤(7),获取最终的推理结果。
可选地,输入到yolov4-tiny网络的图像经过卷积层、正则化和激活层操作,得到第一特征图;
将第一特征图再经过卷积层、正则化和激活层操作,得到第二特征图;
将第二特征图经过残差块的操作后得到第三特征图,接着经过残差块的操作后变换成第四特征图,然后分成两路,第一路直接进入fpn模块,通过卷积层进行候选框的选取;第二路继续经过一个残差块的操作后得到第五特征图,再经过卷积层、正则化和激活层的操作后得到第六特征图,然进入fpn模块的卷积层进行候选框的选择,然后又分成两路,一路直接进入yolov3网络预测结果,另一路通过卷积和上采样操作,与第一路直接进入fpn的第四特征图进行张量拼接,扩充张量的维度,拼接后获得的第七特征图再进行卷积操作,最后进入yolov3网络预测结果。
根据本发明实施例的第三方面,提供了一种教室空座查询系统。
在一些可选实施例中,教室空座查询系统,包括上述的实时视频分析系统,还包括后台管理系统和微信小程序;
所述实时视频分析系统通过yolov4-tiny网络得到的检测结果,存放在数据库中,在后台管理系统进行可视化展示;
后台管理系统包括用户管理模块、校区管理模块、教室管理模块、摄像头管理模块和用户反馈管理模块;
微信小程序展示教室的名称和相对应的分布图,每隔固定时间实时更新一次数据。
可选地,所述后台管理系统接口采用java语言进行编写,使用maven技术进行项目系统构建,系统整体框架基于springboot框架进行接口开发,所有接口完成与前端进行数据交互任务,数据均采用json结构;利用反向代理nginx技术将接口系统部署到云服务器上与前端进行交互;利用git技术进行代码管理。
本发明实施例提供的技术方案可以包括以下有益效果:
(1)不需要在座位上安装任何复杂的硬性设备,只需要获取每个教室的摄像头信息,然后传入实时视频分析系统进行分析,获得教室空位信息;
(2)开发了方便用户使用的小程序平台和后台管理系统,可以实时查询教室情况。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。
图1是根据一示例性实施例示出的yolov4-tiny网络结构的示意图;
图2是根据一示例性实施例示出的视频分析方法的流程示意图。
具体实施方式
以下描述和附图充分地示出本文的具体实施方案,以使本领域的技术人员能够实践它们。一些实施方案的部分和特征可以被包括在或替换其他实施方案的部分和特征。本文的实施方案的范围包括权利要求书的整个范围,以及权利要求书的所有可获得的等同物。本文中,术语“第一”、“第二”等仅被用来将一个元素与另一个元素区分开来,而不要求或者暗示这些元素之间存在任何实际的关系或者顺序。实际上第一元素也能够被称为第二元素,反之亦然。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的结构、装置或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种结构、装置或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的结构、装置或者设备中还存在另外的相同要素。本文中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
本文中的术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本文和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。在本文的描述中,除非另有规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是机械连接或电连接,也可以是两个元件内部的连通,可以是直接相连,也可以通过中间媒介间接相连,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
本文中,除非另有说明,术语“多个”表示两个或两个以上。
本文中,字符“/”表示前后对象是一种“或”的关系。例如,a/b表示:a或b。
本文中,术语“和/或”是一种描述对象的关联关系,表示可以存在三种关系。例如,a和/或b,表示:a或b,或,a和b这三种关系。
本发明提出了一种实时视频分析系统,解决了目前教室空座查询方法的复杂性、不便捷性,不需要在座位上安装任何复杂的硬性设备,只需要获取每个教室的摄像头信息,然后传入实时视频分析系统进行分析,获得教室空位信息。
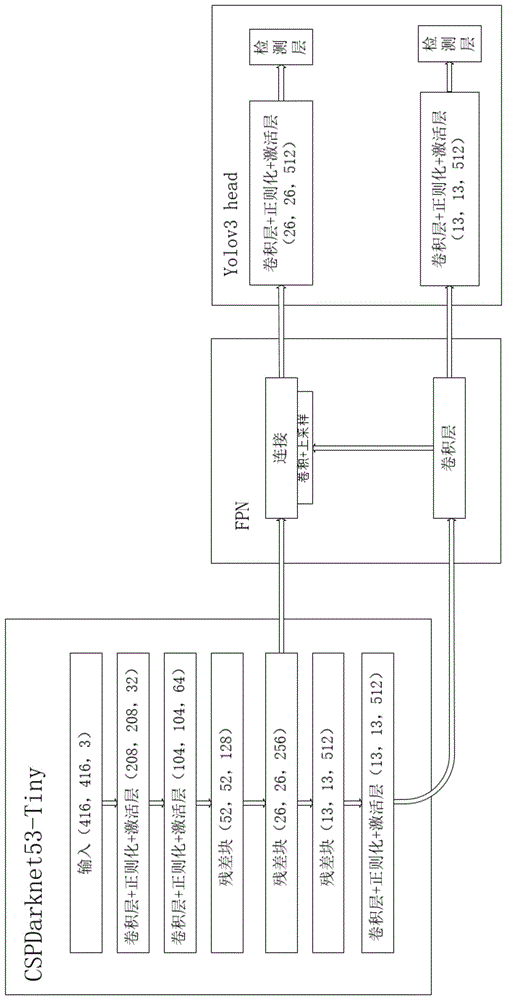
在一些可选实施例中,本发明的实时视频分析系统,其采用yolov4-tiny网络对多路视频流数据进行实时分析,yolov4-tiny网络的精确度更高,其速度也提升了不少,是一个适用于工业开发的深度学习算法。yolov4-tiny网络结构主要包括三部分,cspdarknet53-tiny网络、fpn网络和yolov3网络,首先通过cspdarknet53-tiny网络提取输入图片的特征,得到两个不同大小的特征图,然后通过fpn网络进行特征融合和处理,最后连接yolov3网络输出结果。
图1给出了yolov4-tiny网络结构的一个可选实施例。
如图1所示,输入到yolov4-tiny网络的图像(416*416*3)经过卷积层、正则化和激活层操作,得到第一特征图;将第一特征图再经过卷积层、正则化和激活层操作,得到第二特征图;将第二特征图经过残差块的操作后得到第三特征图,接着经过残差块的操作后变换成第四特征图,然后分成两路,第一路直接进入fpn模块,通过卷积层进行候选框的选取。第二路继续经过一个残差块的操作后得到第五特征图,再经过卷积层、正则化和激活层的操作后得到第六特征图,然后进入fpn模块的卷积层进行候选框的选择,然后又分成两路,一路直接进入yolov3网络预测结果,另一路通过卷积和上采样操作,与第一路直接进入fpn的第四特征图进行张量拼接,这两个特征图具有相同的长宽尺寸,而高度不同,两个特征图拼接在一起,拼接的操作和传统的add操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。拼接后获得的第七特征图再进行卷积操作,最后进入yolov3网络预测结果。
图1所示实施例中,输入到网络的图像(416*416*3)经过卷积层、正则化和激活层操作,得到一个208*208*32的特征图;将此208*208*32的特征图再经过卷积层、正则化和激活层操作,得到一个104*104*64的特征图;将此104*104*64的特征图经过残差块的操作后得到一个52*52*128的特征图,接着经过残差块的操作后变换成26*26*256的特征图,然后分成两路,第一路直接进入fpn模块,通过卷积层进行候选框的选取。第二路继续经过一个残差块的操作后得到一个13*13*512的特征图,再经过卷积层正则化激活层的操作后得到一个13*13*512的特征图,然进入fpn模块卷积层进行候选框的选择,结果又分成两路,一路直接进入yolov3网络预测结果,另一路通过卷积和上采样操作,与第一路直接进入fpn的特征图进行张量拼接,拼接后的特征图再进行卷积操作,最后进入yolov3网络预测结果。yolov3网络预测物体的类别和位置。
yolov3网络用于预测教室内的人和空座,以及人的抬头低头情况。yolov3网络负责对得到的特征图进行预测或训练处理,训练时分别计算坐标损失和分类损失,使用均方差损失函数。
yolov3网络用于预测图片中物体(空座,人,抬头,低头)的位置和类别,每个物体产生一个检测框(boundingbox),用来标注物体的位置,每个检测框包括4个坐标,tx、ty、tw、th,分别对应着检测框的左上角的坐标为(tx,ty)以及检测框的长宽(tw,th)。此外,yolov3网络为每个检测框设置了置信度,物体置信度表示该检测框包含物体的概率,包含物体则置信度为1,否则为0。
yolov3网络采用了yolov3head的结构,输入到yolov3网络的特征图紧接着一个1*1的卷积层,再经过正则化及激活层,然后连接全连接层(检测层)进行分类预测。
图1所示实施例中,对于fpn中输出的特征图,yolov3网络将未经过张量拼接处理的特征图13*13(相当于416*416图片大小),分成13*13个gridcells,接着如果groundtruth中某个目标的中心坐标落在某个gridcell中,那么就由该gridcell来预测该目标。每个gridccell都会预测3个固定数量的边界框,13*13特征图的感受野最大,因此其anchorbox的尺寸最大,分别为116*90,156*198,373*326,适合检测较大的目标。经过张量拼接处理的特征图26*26,由于其感受野较小,故应用较小的anchorbox(30*61),(62*45),(59*119),适合检测小目标。
yolov3网络使用逻辑回归预测每个先验边界框(anchorbox)的目标性得分,即这块位置是目标的可能性有多大,通过计算先验边界框与groundtruth的重叠面积来进行目标评分,本发明实施例提前设置了一定的阈值来筛选先验边界框,一般阈值设置为0.5,对于重叠面积小于阈值0.5的先验边界框直接去掉,如果先验边界框与groundtruth目标比其他目标重叠多,则相应的目标性得分应为1。如果先验边界框不是最佳的结果,即使其超过设定的阈值,还是不会对其进行预测。这样就可以筛选出一个最接近的先验边界框,便于后续步骤的微调。对于训练图片中的groundtruth,若其中心点落在某个cell内,那么该cell内的3个anchorbox负责预测该groundtruth,具体是哪个anchorbox预测它,在学习过程中,这个gridcell会逐渐学会如何选择哪个大小的anchorbox,以及对这个anchorbox进行微调。本发明实施例定义了一个规则来使gridcell选取某个anchorbox,即由那个与groundtruth的iou最大的anchorbox预测该groundtruth,而剩余的2个anchorbox不与该groundtruth匹配。yolov3需要假定每个cell至多含有一个groundtruth,而在实际上基本不会出现多于1个的情况。与groundtruth匹配的anchorbox计算坐标误差、置信度误差(此时置信度为1)以及分类误差,而其它的anchorbox只计算置信度误差(此时置信度为0)。
预测的坐标点tx、ty、tw、th,其中(tx,ty)为平移尺度,(tw,th)为缩放尺度,anchorbox经过平移加尺度缩放进行微调与grandtruth重合。当输入的anchorbox与groundtruth相差较小时,即iou很大时,可以认为这种变换是一种线性变换,那么就可以用线性回归(线性回归就是给定输入的特征向量x,学习一组参数w,使得经过线性回归后的值跟真实值y(groundtruth)非常接近.即y≈wx)来建模对窗口进行微调,否则会导致训练的回归模型不匹配。
最终yolov3网络会输出一个检测框,预测物体的检测框,及物体的类别,包括空座,人,抬头和低头。类别预测使用独立的logistic分类器,非softmax,训练过程中使用binary交叉熵损失。
可选地,所述yolov4-tiny目标检测算法采用多尺度特征图用于检测,即采用大小不同尺度的特征图进行检测,特征图一较大,由于后面逐渐采用卷积和池化降低特征图大小,特征图二通过上采样与前面的特征图结合,因此特征图二较小,大特征图(即特征图一)用来检测相对较小的目标,而小特征图(即特征图二)用来检测相对较大目标。对于监控场景中人物远近不同的特点,采用该实施例中的yolov4-tiny目标检测算法非常适合该场景的检测,即大特征图用来检测相对较小的目标,而小特征图用来检测相对较大目标,对于不同大小的目标都能实现精确检测。
采用该实施例中的yolov4-tiny目标检测算法非常适合教室内物体的检测,大尺度特征图属于底层级特征图,语义含义不够丰富但是精度高。而小尺度特征图属于高层级特征图,语义含义丰富,但是精度低。在特征提取过程,将小尺度特征图经过上采样放大之后与大尺度特征图拼接,输出特征图既有较高的精度,又具有较丰富的语义含义,可以针对场景中物体大小不一的情况,提高检测精度。
分辨率信息直接反映的是构成目标的像素的数量。一个目标的像素数量越多,其对目标的细节表现就越丰富越具体,也就是说分辨率信息越丰富。因此,大尺度特征图提供的是分辨率信息。语义信息在目标检测中指的是让目标区分于背景的信息,即语义信息是让用户知道这个是目标,其余是背景。在不同类别中语义信息并不需要很多细节信息,分辨率信息大,反而会降低语义信息,因此,小尺度特征图在提供必要的分辨率信息下语义信息会提供的更好。而对于小目标,小尺度特征图无法提供必要的分辨率信息,所以还需结合大尺度特征图。本发明实施例中yolov4-tiny更进一步采用了2个不同尺度的特征图来进行对象检测,能够检测到更高细粒度的特征。嫁接网络的最终输出有2个尺度分别为大特征图一,小特征图;这里小尺度特征图的感受野比较大,因此适合检测图像中尺寸比较大的对象。然后这个结果通过上采样与前面的特征图张量拼接,拼接的操作和残差层加的操作是不一样的,拼接会扩充张量的维度,而加只是直接相加不会导致张量维度的改变。大尺度特征图的感受野小,适合检测小尺度的对象,比如小目标摄像头远处的人和桌子在大尺度特征图中的尺寸较大,检测框并不能完全框住物体,而在小尺度特征图中可以较好的检测出人和桌子。同理,大目标在小尺度特征图中较小,检测框会包含背景,而在大特征图中能较好的包围大目标。
在另一些可选实施例中,本发明还提出了一种视频分析方法,将上述yolov4-tiny网络与jetsonnano平台绑定在一起,部署方便,操作灵活,可应用于教室监控场景。图2给出了本发明的结合jetsonnano平台的视频分析方法的一个可选实施例。
在该可选实施例中,所述视频分析方法基于deepstreamsdk开发,运行在jetsonnano平台上,jetsonnano平台内置cuda、opencv和tensorrt模块。
该可选实施例中,视频分析方法包括以下步骤:
步骤(1),捕获视频流数据。可选地,该视频流数据来自摄像机的rtsp流或者usb或csi摄像机;
步骤(2),解码视频流数据。可选地,解码器插件采用nividia的硬件加速解码引擎。
步骤(3),解码之后,对视频流数据进行预处理,例如,图像的放缩、裁剪、格式转换等。
步骤(4),将多路视频流数据组合到一起进行批处理。
步骤(5),采用图1所示yolov4-tiny网络对多路视频流数据进行实时分析,执行目标检测,将推理结果沿管道传递到下一个插件。yolov4-tiny网络对多路视频流数据进行实时分析,在保证检测精度的同时,又能满足视频实时分析的要求。
步骤(6),将推理结果对应的文字等信息附加到元数据上,可显示在屏幕上。
步骤(7),获取最终的推理结果。
tensorrt的5个主要作用:
1、对权重参数类型进行优化。参数类型有fp32,fp16,int8三种类型,使用较低的数据精度会降低内存占用和延迟,使模型体积更小,推理速度会有很大提升。
2、层间融合。在部署模型推理时,每一层的运算由gpu完成,gpu启动不同的cuda(computeunifieddevicearchitecture)核心进行计算,由于cuda进行运算的速度很快,大量的时间浪费在cuda核心的启动和对每一层输入输出的读写操作上,造成了内存宽带的瓶颈和gpu资源的浪费。tensorrt对层间进行横向或纵向融合,大大减少了层的数量。横向合并可以把卷积、偏置和激活层合并成一个cbr结构,只占用一个cuda核心。纵向合并可以把结构相同,但是权值不同的层合并成一个更宽的层,也只占用一个cuda核心。合并之后的计算图的层次更少了,占用的cuda核心数也少了,因此整个模型结构会更小,更快,更高效。
3、多流的执行。gpu擅长并行计算,除了不同的多个线程、block以外,还有不同的stream,多流的执行可以隐藏数据传输的时间。gpu把一大块数据切分成不同的小块进行计算,第一块数据在传输的时候,后面所有任务都在等待,当第一块传输完了之后第二块开始传输。与此同时,第一块数据开始计算,就可以把传输时间隐藏在计算时间里。
4、动态的tensormemory。在每个tensor的使用期间,tensorrt会为其指定显存,这样可以避免显存重复申请,减少内存占用,提高重复使用效率。
5、内核调用。tensorrt可以针对不同的算法、不同的网络模型、不同的gpu平台,进行cuda核的调整,以保证当前模型在特定平台上以最优性能计算。
本发明还提出了一种教室空座查询系统,包括上述实时视频分析系统,还包括后台管理系统和微信小程序,实时视频分析系统通过yolov4-tiny得到的检测结果,存放在数据库中,在后台管理系统进行可视化展示。后台管理系统是相对于管理员而言的,包括用户管理模块、校区管理模块、教室管理模块、摄像头管理模块和用户反馈管理模块。用户一开始使用微信小程序需要进行注册信息和微信绑定,进入小程序,切换不同的教学楼来查看该教学楼空座排名前十的教室,小程序展示教室的名称和相对应的分布图,每隔固定时间实时更新一次数据,例如每2分钟实时更新一次数据。
用户管理模块分为管理员和学生,管理员的权限高于学生,记录用户的学号/工号,姓名,用户权限,所属校区,创建时间等信息。此模块下可以添加,查看,编辑和删除用户,也可以批量导入用户信息。校区管理模块是针对多校区情况做的分类。每个学校分为几个校区,每个校区对应着几个教学楼,都会列出对应关系,也可以修改,删除,新增校区和教学楼信息。教室管理模块包括所属校区、所属教区、教室名称、行、列、空列、摄像头、创建时间等信息,也可以查看、编辑和删除教室信息,每个教室对应着相应的教学楼和校区,同时也可以通过校区名称,教区名称和教室名称查询教室。摄像头管理模块包括所属校区、所属教区、所属教室、自习室位置总数、rtsp地址、停用状态、检测时间段等信息,摄像头与教室对应,也可以查看、编辑、删除和停用摄像头。用户反馈管理模块反映用户提出的意见,包括用户名、创建时间、状态等信息,也可以通过用户名和创建时间进行查询反馈信息。
后台管理系统接口采用java语言进行编写,java版本为java1.8,使用maven技术进行项目系统构建,系统整体框架基于springboot框架进行接口开发,而且使用了springbootjpa、redis、mysql、springmvc等技术,所有接口完成与前端进行数据交互任务,数据均采用json结构。开发完成后利用反向代理nginx技术将接口系统部署到云服务器上与前端进行交互。在开发过程完成后利用git技术进行代码管理。
管理员进行登录时,请求信息与mysql数据库中的数据进行验证,若验证成功则利用jwt协议生成token,之后使用redis系统将用户信息、验证token进行存储,保证接下来的操作可以使用token进行操作(token放于请求头中)。
后台管理系统对后台进行管理时,首先添加校区教学楼,以后根据校区教学楼添加教室,再根据教室配备摄像头,根据此种逻辑关系完成数据管理,均通过被依赖表的主键进行关联。
数据存储在mysql数据库中,用户管理模块、校区管理模块、教室管理模块、摄像头管理模块和用户反馈管理模块中,每个管理模块对应一张表,每个表中均还有主键及其他必要属性,但不涉及外键,依赖关系均在程序代码中实现。在对后台管理系统中数据的添加或修改时,在接口函数中会进行数据库数据实体完整性、数据参照完整性以及用户定义的完整性的验证,不符合要求则不会进行数据库数据添加或修改。删除时,会优先判断是否符合要求,根据实际需求进行级联删除。数据增、删、改、查均基于springbootjpa技术。
用户反馈管理模块用于对小程序中用户反馈信息的管理,其在mysql数据库中对应一张表。在小程序端用户提交反馈,反馈内容存于数据库中,后台管理系统分页显示并进行相关操作。其中反馈的状态为已读、未读,通过标志位进行判断;反馈发布者通过用户主键进行关联。
小程序包括空位查询模块、教室巡查模块。其中,教室巡查模块将教室中的摄像头捕获的照片地址(利用nginx服务器反向代理后的url系统地址)告知前端,通过url系统进行显示。空位查询模块包括分析模块、后端模块、前端模块。后端模块将分析模块分析的结果存于数据库中,并利用相对位置计算对应的空位位置以及空位率。前端调用相关接口时,后端只需要利用springbootjpa将数据进行读取,根据空位率进行排序后将数据传给前端。
微信小程序实现分析数据的展示,采用canvas2d实现虚拟教室的绘制,使用echarts绘制折线图等实现数据的可视化,采用vant作为ui框架。登录采用学号以及手机号短信验证,第一次登录后与微信绑定,在不解除绑定的情况下可免验证登录。
本发明公开了一种教室空座查询系统,基于深度学习网络yolov4-tiny算法实现了实时视频分析,视频图像截取,视频导出的功能。本发明从用户的角度出发,开发了方便用户使用的小程序平台和后台管理系统,可以实时查询教室情况。本系统和jetsonnano平台结合在一起,具有成本低、部署方便,操作灵活的特点,便于推广,从而具有较高的产业使用价值。
本发明并不局限于上面已经描述并在附图中示出的结构,并且可以在不脱离其范围进行各种修改和改变。本发明的范围仅由所附的权利要求来限制。
- 还没有人留言评论。精彩留言会获得点赞!