一种隐私数据的计算方法、装置及计算机设备与流程
本发明涉及隐私数据处理领域,具体涉及一种隐私数据的计算方法、装置及计算机设备。
背景技术:
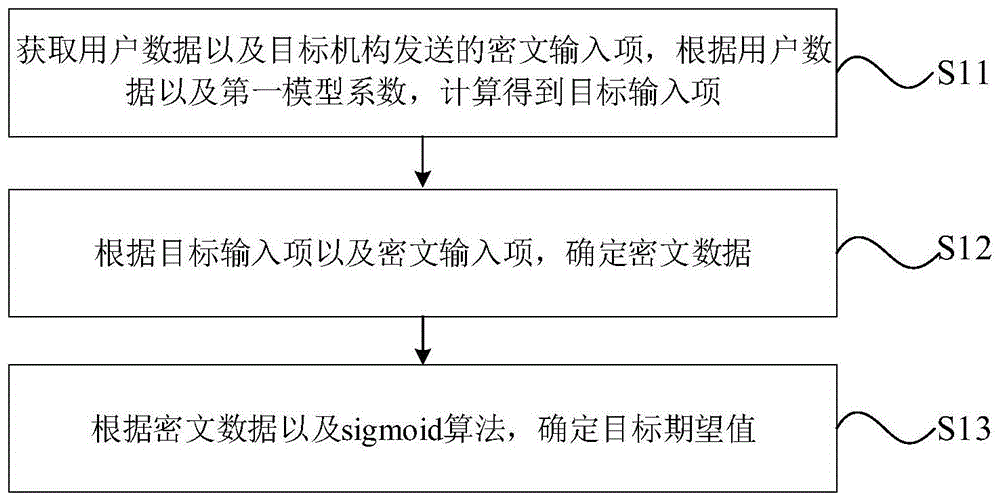
:在当前“人工智能”、“数据科技”的年代,数据做为最重要的生产要素之一有着大量的流通与融合的需要。目前当多家机构展开数据合作时,需要将各方的明文数据归集在一处,例如可以统一归集在其中的某一家机构,也可以归集在某个独立的第三方平台,之后再进行中心化的数量化建模或分析工作。数据有着开放与融合的需要,但是在另外一面,对于数据安全与保护有着越来越严格的要求,而各个机构对于自身商业数据保护的需要也都使得机构明文数据“出库”这样的操作越来越不可行。为了解决数据流通与数据安全保护这一对矛盾,隐私计算技术得到了空前的关注。在实际使用中,隐私计算全称是“保护数据隐私的计算”,或“隐私保护计算”(privacypreservingcomputation),是指在多个参与方进行联合计算的时候,在保证各方数据安全与隐私不泄露的前提下,实现计算与数据价值挖掘的技术体系。但是在隐私计算的环境下,两方机构要进行联合逻辑回归模型训练时,用于sigmoid计算的输入项数据z是一个密文,导致无法进行sigmoid计算,继而导致隐私数据无法被使用。技术实现要素:有鉴于此,本发明实施例提供了一种隐私数据的计算方法、装置及计算机设备,以解决相关技术中由于输入项为密文导致的无法进行sigmoid计算的问题。根据第一方面,本发明实施例提供了一种隐私数据的计算方法,包括:获取用户数据以及目标机构发送的密文输入项,根据所述用户数据以及第一模型系数,计算得到目标输入项,所述密文输入项为目标机构根据所述目标机构的用户数据以及第二模型系数,通过同态加密之后得到的;根据所述目标输入项以及密文输入项,确定密文数据;根据所述密文数据以及sigmoid算法的目标公式,确定目标期望值。可选地,该隐私数据的计算方法还包括:根据所述目标期望值以及预设标签值,计算误差值;根据所述误差值,分别计算所述目标输入项以及所述密文输入项对应的第一梯度以及第二梯度;根据所述第一梯度以及所述第二梯度,更新所述第一模型系数以及所述第二模型系数。可选地,所述根据所述密文数据以及sigmoid算法的目标公式,确定目标期望值,包括:根据第一拟合系数、第二拟合系数以及第三拟合系数,确定所述目标公式;根据所述密文数据以及目标公式,计算得到目标期望值。可选地,通过下述公式确定所述目标期望值:ρz=0.5+0.21625499×z-0.00655313×z3,其中,ρz表示所述目标期望值,0.5为所述第一拟合系数,0.21625499为所述第二拟合系数,0.00655313为所述第三拟合系数,z表示所述密文数据。可选地,通过以下过程,确定所述第一拟合系数、第二拟合系数以及第三拟合系数:根据目标拟合区间,生成散点序列,所述散点序列包括多项密文数据;根据所述散点序列,进行立方计算,得到立方序列;根据所述散点序列以及所述立方序列,计算预测拟合值;根据所述预测拟合值以及真实值,计算得到所述预测拟合值以及真实值的残差平方和;根据预设优化算法以及所述残差平方和,计算得到所述第一拟合系数、第二拟合系数以及第三拟合系数。可选地,通过以下公式,确定所述预测拟合值:其中,表示所述预测拟合值,z表示所述密文数据。通过以下公式,确定所述残差平方和:其中,所述se表示所述残差平方和,yi表示第i个目标期望值;可选地,通过以下公式,确定所述第一拟合系数、第二拟合系数以及第三拟合系数:β=(xtx)-1xty,其中,x表示所述散点序列以及所述立方序列确定的第一目标矩阵,x^t表示第一目标矩阵的转置矩阵,y表示根据x值计算出来的sigmoid的真实值;根据第二方面,本发明实施例提供了一种隐私数据的计算装置,包括:获取模块,用于获取用户数据以及目标机构发送的密文输入项,根据所述用户数据以及第一模型系数,计算得到目标输入项;第一确定模块,用于根据所述目标输入项以及密文输入项,确定密文数据;第二确定模块,用于根据所述密文数据以及sigmoid算法的目标公式,确定目标期望值。根据第三方面,本发明实施例提供了一种计算机设备,包括:至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器执行第一方面或者第一方面的任意一种实施方式中所述的隐私数据的计算方法的步骤。根据第四方面,本发明实施例提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面或者第一方面的任意一种实施方式中所述的隐私数据的计算方法的步骤。本发明技术方案,具有如下优点:本发明提供的一种隐私数据的计算方法、装置以及计算机设备,其中,该方法包括:获取用户数据以及目标机构发送的密文输入项,根据用户数据以及第一模型系数,计算得到目标输入项;根据目标输入项以及密文输入项,确定密文数据;根据密文数据以及sigmoid算法的目标公式,确定目标期望值。通过实施本发明,解决了相关技术中存在的由于输入项为密文导致的无法进行sigmoid计算的问题,结合目标输入项、密文输入项以及sigmoid算法的目标公式,可以快速、准确地确定目标期望值,即在明文数值下进行sigmoid计算结果足够近似的值,拟合误差较小,拟合过程较为简单,实现高拟合精度、低计算复杂度的拟合计算。附图说明为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本发明实施例中隐私数据的计算方法的一个具体示例的流程图;图2为现有技术中当输入项的取值范围为正负2时,通过泰勒展开式计算的拟合误差示意图;图3为现有技术中当输入项的取值范围为正负3时,通过泰勒展开式计算的拟合误差示意图;图4为现有技术中当输入项的取值范围为正负4时,通过泰勒展开式计算的拟合误差示意图;图5为本发明实施例中隐私数据的计算方法中的取值范围为正负2的拟合误差示意图;图6为本发明实施例中隐私数据的计算方法中的取值范围为正负3的拟合误差示意图;图7为本发明实施例中隐私数据的计算方法中的取值范围为正负4的拟合误差示意图;图8为本发明实施例中隐私数据的计算装置的一个具体示例的原理框图;为本发明实施例中隐私数据的计算方法中的示意图;图9为本发明实施例中计算机设备的一个具体示例图。具体实施方式为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。隐私计算全称是“保护数据隐私的计算”,或“隐私保护计算”(privacypreservingcomputation),是指在多个参与方进行联合计算的时候,在保证各方数据安全与隐私不泄露的前提下,实现计算与数据价值挖掘的技术体系。隐私计算并不是一种单一的技术,它是一套包含人工智能、分布式计算、密码与安全、数据科学等众多领域交叉融合的跨学科技术体系。隐私计算能够在各方明文数据无需出库的情况下,完成各方数据的融合计算、联合建模的等数据应用,在满足数据隐私安全的基础上,实现数据“价值”和“知识”的流动与共享,真正做到“数据可用不可见”。在隐私计算的环境下,两方机构要进行联合逻辑回归模型训练时面对的一大挑战是用于sigmoid计算的输入项是一个密文,所以无法进行sigmoid计算,因此,本发明实施例提供了一种隐私数据的计算方法、装置以及计算机设备,目的是计算得到与进行sigmoid计算所得到的的结果足够近似的拟合值,且误差足够小。本发明实施例所述的隐私数据的计算方法,可以应用于在隐私计算的环境下,两方机构要进行联合逻辑回归模型训练的具体应用场景中,具体地,可以应用于接收另一方机构发送的密文数据的机构中,例如,两方机构可以是甲方机构以及乙方机构,乙方机构将加密后的密文数据发送至甲方机构,本发明实施例所述的方法即可应用于甲方机构中,例如,甲方机构可以是银行等支付机构,乙方机构可以是收集并存储海量数据的大数据公司等。本发明实施例提供了一种隐私数据的计算方法,如图1所示,应用于银行等支付机构,即甲方机构中,包括:步骤s11:获取用户数据以及目标机构发送的密文输入项,根据用户数据以及第一模型系数,计算得到目标输入项,密文输入项为目标机构根据目标机构的用户数据以及第二模型系数,通过同态加密之后得到的;在本实施例中,用户数据可以是银行本身存储的数据,可以用xa表示;目标机构可以是收集并存储海量数据的大数据机构等,第一模型系数可以是目标系数,也就是进行联合逻辑回归模型训练完成后,支付机构需要训练成的模型系数,可以用wa表示;可以通过下述公式计算得到目标输入项za:za=xa×wa,具体地,密文输入项可以是在大数据机构通过上述方法计算出的,例如,在大数据机构中,基于大数据机构本身的数据xb、大数据机构需要训练成的第二模型系数wb,经过过矩阵相乘操作,计算得到的输入项zb。当大数据机构计算得到输入项zb后,对zb进行同态加密操作,生成密文输入项[[zb]],继而把密文输入项[[zb]]传输至支付机构。将进行同态加密后的数据进行传输后,可以满足隐私计算的前提,避免双方机构在传输数据时涉及到任何明文数据的交互,从而实现对双方数据的保护。步骤s12:根据目标输入项以及密文输入项,确定密文数据;在本实施例中,目标数据项za可以是支付机构基于本身数据计算出的明文数据;密文输入项可以是在大数据机构中经过类似计算过程,继而在经由同态加密算法后得到的密文数据[[zb]]。具体地,将所述目标输入项与所述密文输入项进行求和操作,计算得到密文数据[[z]]:[z]]=za+[zb]]。步骤s13:根据密文数据以及sigmoid算法的目标公式,确定目标期望值。在本实施例中,当所述密文数据为明文数据时,可以直接进行sigmoid计算,也就是说,可以对明文数据进行非线性计算操作,例如开根号、求log、幂运算、指数运算等,但是由于sigmoid计算是对输入的数据进行以自然对数e为底数的指数运算,当输入的数据为进行同态加密操作后的密文数据时,无法直接进行sigmoid计算,此时可以根据密文数据以及sigmoid算法的目标公式,对sigmoid的计算结果进行拟合,也就是计算求出与上述sigmoid的计算结果(真实期望值)无限接近的拟合值,即目标期望值。本发明提供的一种隐私数据的计算方法,包括:获取用户数据以及目标机构发送的密文输入项,根据用户数据以及第一模型系数,计算得到目标输入项;根据目标输入项以及密文输入项,确定密文数据;根据密文数据以及sigmoid算法的目标公式,确定目标期望值;根据目标期望值以及预设标签值,更新第一模型系数以及第二模型系数。通过实施本发明,解决了相关技术中存在的由于输入项为密文导致的无法进行sigmoid计算的问题,结合目标输入项、密文输入项以及sigmoid算法的目标公式,可以快速、准确地确定目标期望值,即在明文数值下进行sigmoid计算结果足够近似的值,拟合误差较小,拟合过程较为简单,实现高拟合精度、低计算复杂度的拟合计算。在一可选实施例中,该隐私数据的计算方法,还包括:首先,根据目标期望值以及预设标签值,计算误差值;在本实施例中,在本实施例中,预设标签值可以是预设选定的样本数据的真实标签值,根据真实标签值以及计算出的与sigmoid的计算结果(真实期望值)无限接近的拟合值,得到误差值,具体地,可以通过下述公式得到误差值deltaz:deltaz=a-y,其中,a可以表示计算出的与sigmoid的计算结果(真实期望值)无限接近的拟合值,即目标期望值;y可以表示预设选定的样本数据的真实标签值。其次,根据误差值,分别计算目标输入项以及密文输入项对应的第一梯度以及第二梯度;在本实施例中,根据计算出的误差值,分别基于预设限定的样本数据的数量m,确定银行机构的第一梯度以及大数据机构的第二梯度。具体地,可以通过下述公式确定第一梯度dwa以及第二梯度dwb:其中,表示银行本身存储的用户数据对应的转置矩阵,表示大数据机构自身存储的数据对应的转置矩阵,m表示预设限定的样本数据的数量,即训练数据集的样本量。其次,根据第一梯度以及第二梯度,更新第一模型系数以及第二模型系数。在本实施例中,根据第一梯度以及预设学习率,更新所述第一模型系数,根据第二梯度以及预设学习率,更新所述第二模型系数,具体地,可以通过下述公式计算更新后的第一模型系数以及第二模型系数:wa’=wa-α×dwa,wb’=wb-α×dwb,其中,wa’为更新后的第一模型系数,wb’为更新后的第二模型系数,α为预设学习率。当甲方机构与乙方结构联合训练的逻辑回归模型收敛后,可以认为此时得到的更新后的第一模型系数以及第二模型系数为逻辑回归模型的最终系数结果。在一可选实施例中,上述步骤s13,根据密文数据以及sigmoid算法的目标公式,确定目标期望值,包括:首先,根据第一拟合系数、第二拟合系数以及第三拟合系数,确定目标公式;在本实施例中,由于在隐私计算环境中,甲方机构接收到的乙方机构传输的数据为密文信息,继而经过求和操作后得到的结果也为密文数据,此时无法直接进行sigmoid计算在本实施例中可以构造一个线性的多项式对非线性的sigmoid函数进行拟合,以实现在输入数值是一个密文的情况下,得到一个与在明文数值下进行sigmoid计算结果足够近似的值,从而可以进行后续的模型训练步骤。又由于相关技术中可以通过泰勒展开式对sigmoid函数进行拟合。泰勒展开式需要进行多次求导,求导的次数越多则计算越复杂,但是通过泰勒展开式对sigmoid函数进行拟合的方式导致拟合精度较差,例如,如图2、图3以及图4所示,图中无任何标记的实线为sigmoid真实值,带有方块标记的黑线为9次项泰勒展开的计算值:当sigmoid函数通过9次项的泰勒展开时,如图2所示,当sigmoid函数的输入项z的取值范围在正负2之间时,拟合的精度较为准确;但是如图3所示,当sigmoid函数的输入项z的取值范围在正负3之间时,已经出现了非常明显的拟合误差;如图4所示,当sigmoid函数的输入项z的取值范围在正负4之间时,拟合误差较大,而在实际应用场景中,sigmoid函数的输入项z一般均为正负4左右,因此,通过泰勒展开式的方法计算拟合值会导致拟合误差较大,继而导致隐私数据无法进行准确计算。具体地,当通过泰勒展开式的方法计算拟合值时的误差可以是如下表1所示:表1z的取值范围拟合平均误差%[-1,1]0.00004%[-2,2]0.06%[-3,3]3.98%[-4,4]70%[-5,5]617%[-6,6]3533%基于上述背景,可以通过本发明实施例中所述的隐私数据的计算方法确定较为准确的拟合值,具体地,通过第一拟合系数、第二拟合系数以及第三拟合系数,确定目标公式,即拟合公式;其次,根据密文数据以及目标公式,计算得到目标期望值。在本实施例中,密文数据即为表示形式为密文形式的输入项,根据密文数据以及目标公式,计算得到与sigmoid的真实计算结果(真实期望值)无限接近的拟合值,即目标期望值。在一可选实施例中,通过下述公式确定目标期望值:ρz=0.5+0.21625499×z-0.00655313×z3,其中,ρz表示目标期望值,0.5为第一拟合系数,0.21625499为第二拟合系数,0.00655313为第三拟合系数,z表示密文数据。在一可选实施例中,通过以下过程,确定第一拟合系数、第二拟合系数以及第三拟合系数:首先,根据目标拟合区间,生成散点序列,散点序列包括多项密文数据;在本实施例中,目标拟合区间可以是根据实际应用场景确定的你和区间,例如可以是[-4,4];散点序列可以是在目标拟合区间随机取值的序列,例如可以是200项的散点序列,可以用z=np.linspace(-4,4,200)表示上述散点序列。其次,根据散点序列,进行立方计算,得到立方序列;在本实施例中,根据上述散点序列z,可以首先进行sigmoid计算,得到sigmoid序列,可以通过下述公式计算:还可以进行立方计算,得到立方序列z3。其次,根据散点序列以及立方序列,计算预测拟合值;在本实施例中,可以通过公式计算预测拟合值:其中,表示进行sigmoid计算的真实值y的预测拟合值,β0表示第一拟合系数,β1表示第二拟合系数,β2表示第三拟合系数,z表示所述散点序列,z3表示所述立方序列;其次,根据预测拟合值以及真实值,计算得到预测拟合值以及真实值的残差平方和;在本实施例中,可以通过下述公式计算真实值y与预测拟合值之间的残差平方和se:此时,计算目标可以是求解得到β0,β1和β2,且可以使se最小化。步骤s25:根据预设优化算法以及残差平方和,计算得到第一拟合系数、第二拟合系数以及第三拟合系数。在本实施例中,上述实施例所述的计算目标为最小二乘法的优化问题,预设优化算法可以是矩阵法,可以通过矩阵法求解确定β0,β1和β2的解析解,具体地,以β来表示β0,β1和β2这3个标量组成的3维的列向量,用x来表示由一个200维的取值为1的列向量、z和z3组成的一个(200,3)的矩阵,真实值y是一个200维的列向量,则的β解析解为β=(xtx)-1xty;当目标拟合区间为[-4,4]时,且所述散点序列的项数为200项时,代入上述公式中可以得到上述解析解的具体取值,即:即,第一拟合系数为0.5,第二拟合系数为0.21625499,第三拟合系数为0.00655313。在一可选实施例中,通过以下公式,确定预测拟合值:其中,表示预测拟合值,z表示密文数据。通过以下公式,确定残差平方和:通过以下公式,确定第一拟合系数、第二拟合系数以及第三拟合系数:β=(xtx)-1xty,其中,x表示散点序列以及立方序列确定的第一目标矩阵。本发明实施例所提供的一种隐私数据的计算方法,结合目标拟合区间以及散点序列,继而通过矩阵法计算得到的第一拟合系数、第二拟合系数以及第三拟合系数,继而得到的目标拟合公式,可以隐私计算的应用场景中对sigmoid函数进行多项式拟合,且计算量较相关技术减少60%,还可以保证拟合的精度。具体地,本发明实施例所提供的隐私数据的计算方法中,只采用一次项以及三次项进行拟合,即可实现计算准确度以及计算能力的平衡,但是,如果需要进一步得出准确精度,则可以考虑引入5次项甚至7次项来做拟合,可以实现更高精度的拟合。在一可选实施例中,如图5、图6以及图7所示,图中无任何标记的实线为sigmoid真实值,带有方块标记的实线为9次项泰勒展开的计算值,带有星型标记的虚线为通过本发明实施例所提供的隐私数据的计算方法,即拟合方法拟合出的值:如图2所示,当sigmoid函数的输入项z的取值范围在正负2之间时,9次项的泰勒展开式以及本发明实施例所提供的拟合方法,拟合精度均较为准确;但是如图3所示,当sigmoid函数的输入项z的取值范围在正负3之间时,9次项的泰勒展开式的拟合值已经出现了非常明显的拟合误差,但本发明实施例所提供的拟合方法,拟合精度还是较为准确;如图4所示,当sigmoid函数的输入项z的取值范围在正负4之间时,9次项的泰勒展开式的拟合值的拟合误差较大,出现“拟合误差爆炸”的现象,而但本发明实施例所提供的拟合方法,拟合精度还是较为准确,没有出现明显误差,因此,本发明实施例所提供拟合方法所提供的拟合值可以实现进行准确计算。本发明实施例提供一种隐私数据的计算装置,如图8所示,包括:获取模块21,用于获取用户数据以及目标机构发送的密文输入项,根据用户数据以及第一模型系数,计算得到目标输入项;详细实施内容可参见上述方法实施例中步骤s11的相关描述。第一确定模块22,用于根据目标输入项以及密文输入项,确定密文数据;详细实施内容可参见上述方法实施例中步骤s12的相关描述。第二确定模块23,用于根据密文数据以及sigmoid算法的目标公式,确定目标期望值;详细实施内容可参见上述方法实施例中步骤s13的相关描述。更新模块24,用于根据目标期望值以及预设标签值,更新第一模型系数以及第二模型系数。详细实施内容可参见上述方法实施例中步骤s14的相关描述。本发明提供的一种隐私数据的计算装置,包括:获取模块21,用于获取用户数据以及目标机构发送的密文输入项,根据用户数据以及第一模型系数,计算得到目标输入项;第一确定模块22,用于根据目标输入项以及密文输入项,确定密文数据;第二确定模块23,用于根据密文数据以及sigmoid算法的目标公式,确定目标期望值;更新模块24,用于根据目标期望值以及预设标签值,更新第一模型系数以及第二模型系数。通过实施本发明,解决了相关技术中存在的由于输入项为密文导致的无法进行sigmoid计算的问题,结合目标输入项、密文输入项以及sigmoid算法的目标公式,可以快速、准确地确定目标期望值,即在明文数值下进行sigmoid计算结果足够近似的值,拟合误差较小,拟合过程较为简单,实现高拟合精度、低计算复杂度的拟合计算。本发明实施例还提供了一种计算机设备,如图9所示,该计算机设备可以包括处理器31和存储器32,其中处理器31和存储器32可以通过总线30或者其他方式连接,图9中以通过总线30连接为例。处理器31可以为中央处理器(centralprocessingunit,cpu)。处理器31还可以为其他通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(applicationspecificintegratedcircuit,asic)、现场可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等芯片,或者上述各类芯片的组合。存储器32作为一种非暂态计算机可读存储介质,可用于存储非暂态软件程序、非暂态计算机可执行程序以及模块,如本发明实施例中的隐私数据的计算方法对应的程序指令/模块。处理器31通过运行存储在存储器32中的非暂态软件程序、指令以及模块,从而执行处理器的各种功能应用以及数据处理,即实现上述方法实施例中的隐私数据的计算方法。存储器32可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储处理器31所创建的数据等。此外,存储器32可以包括高速随机存取存储器,还可以包括非暂态存储器,例如至少一个磁盘存储器件、闪存器件、或其他非暂态固态存储器件。在一些实施例中,存储器32可选包括相对于处理器31远程设置的存储器,这些远程存储器可以通过网络连接至处理器31。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。所述一个或者多个模块存储在所述存储器32中,当被所述处理器31执行时,执行如图1所示实施例中的隐私数据的计算方法。上述计算机设备具体细节可以对应参阅图1所示的实施例中对应的相关描述和效果进行理解,此处不再赘述。本发明实施例还提供了一种非暂态计算机可读介质,非暂态计算机可读存储介质存储计算机指令,计算机指令用于使计算机执行如上述实施例中任意一项描述的隐私数据的计算方法,其中,存储介质可为磁碟、光盘、只读存储记忆体(read-onlymemory,rom)、随机存储记忆体(randomaccessmemory,ram)、快闪存储器(flashmemory)、硬盘(harddiskdrive,缩写:hdd)或固态硬盘(solid-statedrive,ssd)等;存储介质还可以包括上述种类的存储器的组合。显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引伸出的显而易见的变化或变动仍处于本发明创造的保护范围之中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1