一种针对深度神经网络模型训练的数据集约简方法及系统
本发明涉及深度神经网络模型领域,提出一种利用互信息的数据集约简方法及系统。
背景技术:
以神经网络为代表的深度学习技术带来了人工智能发展的第三次浪潮,显著提升了图像分类,语音识别,自然语言处理的能力,为人们的生产生活方式带来了巨大的便利。训练一个高准确率和高可靠性的模型,往往需要依赖大量的训练数据。为了从这些海量数据中学习到更本质和重要的特征,神经网络需要花费大量的算力进行长时间的迭代训练,获得最终的深度学习模型。但数据中存在大量的信息冗余,这些信息冗余不仅无法帮助显著提升目标模型的精度,往往还增加了用于模型训练的资源和预算。因此,如何降低训练集中的信息冗余,发掘更具代表性和关键特征的数据点对模型的训练有重要的现实意义:首先能够保证在资源受限的场景下训练一个较高性能的神经网络模型,节省训练时间和算力成本;另外在现实世界中的黑盒模型测试场景里,能够降低与黑盒模型的交互成本,从而训练更有效地生成替代模型,进而实现最终的模型安全测试,如对抗性能评估。
技术实现要素:
针对上述问题,本发明提出了一种基于互信息的针对深度神经网络模型训练的数据集约简方法及系统,帮助模型训练者大幅缩减了训练数据量,降低了训练依赖的时间和算力,并获得与原模型性能接近的替代模型。
本发明的技术方案为:
一种针对深度神经网络模型训练的数据集约简方法,其步骤包括:
1)将初始训练数据集合d中的训练样本映射到一图中,每一个数据样本作为图中的一个顶点,计算两个数据样本之间的信息冗余度并作为对应两顶点之间的边权值,初始化最小信息冗余度为r(一般为数据的理论最大数值),设置最小信息冗余度总和对应的精简数据集s为空集;
2)枚举d中的每个顶点,作为初始顶点t,设置临时精简集p并初始化,即p={t};
3)计算非精简集d\p(d\p表示集合之间的差运算)中的所有顶点到p中顶点的最短距离(最小边权值),即d\p中的所有顶点对应的数据样本与p中顶点对应的数据样本之间的最小信息冗余度,将具有该最小信息冗余度的顶点加入到p中;重复该步骤直到p具有k个元素个数,k为要筛选出的高质量数据个数;
4)计算p中两两顶点之间边权值的总和l,即两两顶点对应的数据样本之间信息冗余度的总和r(p);
5)对p中的元素进行调整,调整规则为:若d\p中存在顶点u,p内存在顶点v,满足u到集合p\{v}(p\{v}表示集合p与数据v的集合{v}的差运算)的边权值之和小于v到p\{v}的边权值之和,则将v从p中移出,将u加入到p中(这会降低p中两两顶点之间的边权值总和l),更新p和l;重复该步骤直到不存在可被调整的顶点u和v(即u和v不再满足以上的u到集合p\{v}的边权值之和小于v到p\{v}的边权值之和的条件),得到p中的最小边权值总和lmin;
6)将lmin与r进行对比,若lmin<r,则令p更新s,令lmin更新r,即s=p,r=lmin,否则不更新s和r;
7)重复步骤3)至7),直到d中每个顶点都作过一次初始顶点,得到最终的精简数据集sfinal,将sfinal中的数据作为深度神经网络模型训练用的数据。
一种针对深度神经网络模型训练的数据集约简系统,包括存储器和处理器,在该存储器上存储有计算机程序,该处理器执行该程序时实现上述方法的步骤。
一种计算机可读存储介质,存储有计算机程序,该程序被处理器执行时实现上述方法的步骤。
本发明通过引入两两查询之间的互信息量,提出使用互信息来测量两个数据样本之间的数据冗余度,两个数据越相似,互信息值越大。本发明方法可以获得一个互信息值总和最小的精简数据集,利用互信息指标筛选出来的子集包含更独立、更多样、更有代表性的样例,从而去除了冗余的查询,进行高效的目标模型查询,以更少的代价训练替代模型。本发明包含了图片之间的互信息计算、联合概率分布、图论知识、计算复杂度分析、贪心算法、启发式迭代策略等多种技术,从原始数据中筛选出更独立、更多样、更有代表性的样例,提升了训练数据的质量和降低信息的冗余度,加强模型训练的效率并降低训练成本。
附图说明
图1为数据约简示例图。
图2为本发明的针对深度神经网络模型训练的数据集约简方法流程图。
图3为数据集约简的迭代优化示意图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面通过具体实例,对本发明做进一步详细说明。
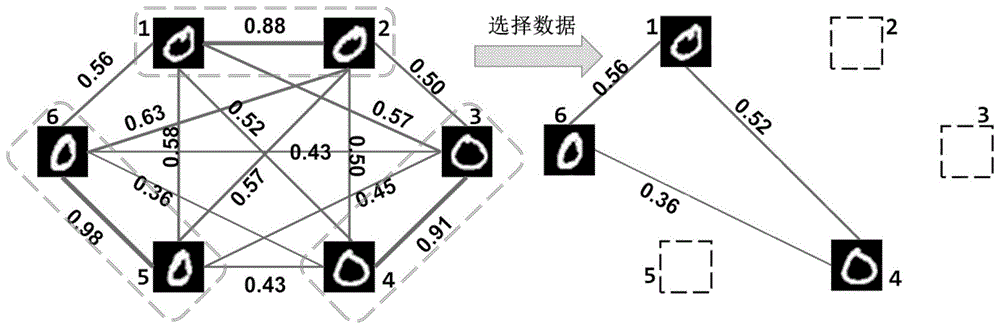
本发明主要针对的场景是由于深度神经网络模型的训练数据包括大量的冗余信息,导致模型训练成本的大量浪费,因此为解决模型训练过程的算力浪费,提升模型的训练效果,研究在在深度神经网络模型的信息冗余的度量方法,并研究如何从海量数据中进行高效的冗余清除,获得更具代表性的数据点。如图1所示,原训练数据集包含六张内容为“0”的图片,通过计算这些图片之间的信息冗余度(即边上的数值),选择其中的三张图片作为精简的训练数据集,该精简数据集中的图片的信息冗余度之和最低,这些数据即为代表性的数据点。
本发明围绕上述研究内容和具体需求场景,形成了完整的数据约简方法,并对百万级规模的数据集(如imagenet)进行数据约简。在约简后的数据集进行训练获得的模型,在准确率及模型迁移性指标上均高于现有水平,本发明的具体实施过程如图2所示,具体说明如下:
1)数据集的信息冗余度量。
本发明采用适合神经网络训练集的信息冗余度量方法。针对两个数据样本u和v,其中u和v是对数据样本的向量表示,由若干个向量元素组成,即<c1,c2,…,cn>,。那么两个数据样本之间的冗余度可以由其互信息m(u,v)来表征如下:
其中,r为向量表示中的向量元素的最大值,即max{c1,c2,…,cn},边际概率值pu(i)表示值为i的向量元素c在向量u中的占比,pv(j)表示值为j的向量元素c在向量v中的占比;puv(i,j)表示两个数据样本u和v的联合概率分布,具体是指在数据样本u中值为i的向量元素和向量v中值为j的向量元素所占两个数据样本所有元素的比例值。另外,对于puv(i,j)=0的情况,认定
式中,r(u,v)是指两个数据样本u和v的信息冗余度。
以图像数据为例,有两张图片u和v,那么两张图片之间的冗余度可以由其互信息m(u,v)来表征如下:
其中,r为像素的最大灰度值255,边际概率值pu(i)表示灰度值为i的像素在图像u中的占比,pv(j)表示灰度值为j的像素在图像v中的占比;puv(i,j)表示图片u和v的联合概率分布,具体是指在图像u中灰度值为i的像素和图像j中灰度值为j的像素所占两张图像所有像素点的比例值。另外,对于puv(i,j)=0的情况,认定
式中,r(u,v)是指两张图像u和v的信息冗余度。
那么给定约简数据集的大小,该问题可以刻画为寻找最优的数据组合,使其中的数据冗余度最低。
2)数据集约简的迭代优化。
为了使约简数据集中的信息冗余度最低,本发明提出一种多项式时间内即可解决的数据集优化方法。如图3所示,实现的具体思路为双层迭代过程:(1)精简数据集初始数据点的随机选取,通过随机选取一个数据点来初始化精简数据集。(2)基于初始点的贪心扩充,即将所有与该初始点冗余度最低的数据点加入到集合中(见发明内容部分的本发明方法的步骤3))。(3)对该约简数据集进行单步替换(见发明内容部分的本发明方法的步骤5)),使新替换的数据点能够降低原约简数据集的冗余度,直到数据集的冗余度不再降低。
最终可以将原始数据集中的冗余数据去除掉,保留有代表性的、多样的高质量简化数据集。该简化数据集可以用来进行替代模型的训练,该替代模型具有与原模型相匹配的模型准确率和迁移性,该方法能够应用于计算资源受限的模型训练场景中。另外,该方法能够有效促进在黑盒场景下的替代模型训练,进而实现对黑盒模型的鲁棒性的测试。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,本发明的保护范围以权利要求所述为准。
- 还没有人留言评论。精彩留言会获得点赞!