一种针对CPU和GPU设备搜索神经网络结构的方法与流程
一种针对cpu和gpu设备搜索神经网络结构的方法
技术领域
1.本发明涉及一种神经网络结构搜索方法,具体为一种针对cpu和gpu设备搜索神经网络结构的方法。
背景技术:
2.近年来,机器学习,尤其是以神经网络为代表的深度学习技术不断发展,在语音、图像和自然语言处理等领域的诸多任务上取得了令人瞩目的成就。以神经机器翻译为例,最近几年的神经网络结构经历了巨大的变化,从循环神经网络、卷积神经网络到以自注意力机制为基础的神经网络,不断刷新机器翻译任务的分数。然而,与之相对应的神经网络结构也越来越复杂,一个趋势是网络的参数量愈发庞大、神经元连接愈发复杂,而设计和实现这些神经网络也越来越依赖于专业人员对相关技术的了解。目前神经网络的设计几乎都是与硬件结构无关的,即专家设计这些神经网络时很少考虑具体运行环境和硬件约束。然而在实际部署时,不同硬件的计算资源不同,例如一些参数量上亿的神经机器翻译模型在并行计算效率高的显卡设备上的运行速度能够满足在线翻译的需求,然而在计算资源有限的移动设备上就无法满足用户实时翻译的需求。
3.目前神经网络结构的设计趋势是为不同的硬件平台设计不同的神经网络结构,然而这些神经网络的设计需要大量从业经验,而且这些经验都仅限于专门化的硬件平台,无法适用于广泛的硬件平台。例如,针对显卡设备并行计算效率高的特点设计的浅而宽的神经机器翻译网络结构就不适合在并行计算效率低的cpu设备上面运行,后者更加适合部署较深但每层神经元数量较少的网络。因此,针对cpu和gpu设备进行神经网络结构自动化设计具有很高的应用价值。
技术实现要素:
4.针对现有的针对cpu和gpu设备的神经网络结构设计方法存在的依赖专家经验、cpu和gpu设备上的神经网络结构设计经验难以相互迁移、验证神经网络结构效果的成本高昂等问题,本发明提出一种针对cpu和gpu设备搜索神经网络结构的方式,能够自动化特定硬件环境下的神经网络结构设计过程。
5.为解决上述技术问题,本发明采用的技术方案是:
6.本发明提供一种针对cpu和gpu设备搜索神经网络结构的方法,包括以下步骤:
7.1)设计并确定cpu和gpu设备网络结构的表示空间,包括需要搜索的网络结构的层数、每层的神经元数量和连接方式,使用字符串编码的形式对这些信息进行表示;
8.2)通过权重共享的方式训练一个全连接的超网,其中不同的子网络共享所有的权重,在每个训练步骤通过均匀采样的方式选择一个子网络进行训练,根据梯度下降的方式对共享的权重进行优化;
9.3)在不同的硬件平台,包括cpu、gpu设备上运行步骤2)采样得到的子网络,统计其执行一次计算所需的运行时间;
10.4)利用步骤3)收集的子网络结构和在不同硬件平台上对应的运行时间,训练一个额外的预测器,用于预测不同网络结构在不同硬件平台上对应的运行时间;
11.5)在全连接的超网上执行进化算法,根据不同硬件平台上的运行时间限制以及不同网络结构在校验集数据上对应的损失搜索出最优网络结构;
12.6)初始化步骤5)得到的最优网络结构的参数,在训练集数据上重新进行训练直到该神经网络收敛。
13.步骤1)中,使用字符串的形式对离散化的网络结构的组合进行表示,该字符串包含神经网络的层数、每层的神经元数量以及不同层的连接方式。
14.步骤2)中,通过权重共享的方式训练一个全连接的超网,其中不同的子网络共享所有的权重,在每个训练步骤通过均匀采样的方式选择一个子网络进行训练,根据梯度下降的方式对共享的权重进行优化,具体为:
15.201)选择固定的超网的层数和每层的神经元数量,其数值等于步骤1)中最大的超网的层数和每层的神经元数量,对超网的参数进行随机初始化;
16.202)训练时,每次在全部的子网络中选择一个子网络进行训练,即只利用超网中的部分层、每层中的部分神经元和部分连接进行训练,通过反向传播的方式对全部的参数进行更新。
17.步骤3)中,在不同的硬件平台,包括cpu、gpu设备上运行步骤2)采样得到的子网络,收集其执行一次前向计算所需的运行时间,具体为:
18.在cpu、gpu设备上运行步骤2)采样得到的子网络,直接评估其执行一次前向计算所需的运行时间;前向计算只计算得到结果。
19.步骤4)中,利用步骤3)得到的不同子网络在不同硬件平台上的运行时间训练一个预测器,用于预测没有直接评估的子网络所需的运行时间,具体为:
20.使用循环神经网络作为预测器,其输入为网络结构的编码,输出为预测的该结构在不同硬件上的运行时间,在搜索前对其进行随机初始化,在搜索时使用步骤3)统计的数据进行训练。
21.步骤5)中,在全连接的超网上执行进化算法,根据不同硬件平台上的运行时间限制以及不同网络结构在校验集数据上对应的损失搜索出最优网络结构,具体为:
22.501)根据搜索过程中收集的运行时间数据,选择100
‑
200个在不同硬件上运行时间最短的网络结构作为初始化种群;
23.502)通过进化算法,随机交叉、替换或删除种群中的网络结构,使用预测器来预测剩下的网络结构,仅保留时间小于规定阈值的网络结构;
24.503)检查种群中时间小于规定阈值的网络结构,如果其运行时间达到预设的目标,则停止搜索,否则回到502)步骤。
25.步骤6)中,初始化步骤5)得到的最优网络结构的参数,在训练集数据上重新进行训练直到该神经网络收敛,具体为:
26.选择步骤5)得到的最优网络结构,对其进行随机初始化,在训练数据集上进行训练直至收敛,保存其参数。
27.超网指的是在执行搜索步骤前,搜索空间中层数、神经元数和神经连接数最多的网络结构,而子网络指的是超网中的一个子模块。
28.本发明具有以下有益效果及优点:
29.1.本发明解决了传统的为不同硬件定制化神经网络结构存在的过程繁琐、可迁移性差等问题,可以在同一框架下为cpu、gpu设备搜索不同的神经网络结构。
30.2.此外,本发明提出的方法可以有效地提升神经网络结构的准确度和运行效率,相较于在cpu和gpu设备上使用固定的神经网络结构,本发明能够有效地根据不同硬件的特点自动化地搜索得到最优的结构。
附图说明
31.图1为本发明中对超网中的子网络结构采样示意图;
32.图2为本发明中神经网络结构搜索方法示意图。
具体实施方式
33.针对现有的针对cpu和gpu设备的神经网络结构设计方法存在的依赖专家经验、cpu和gpu设备上的神经网络结构设计经验难以相互迁移、验证神经网络结构效果的成本高昂等问题,本发明提出一种针对cpu和gpu设备搜索神经网络结构的方式,能够自动化特定硬件环境下的神经网络结构设计过程。
34.本发明方法包括以下步骤:
35.1)设计并确定cpu和gpu设备网络结构的表示空间,包括需要搜索的网络结构的层数、每层的神经元数量和连接方式,使用字符串编码的形式对这些信息进行表示;
36.2)如图1所示,通过权重共享的方式训练一个全连接的超网,其中不同的子网络共享所有的权重,在每个训练步骤通过均匀采样的方式选择一个子网络进行训练,即图1中实线范围内的神经网络结构,根据梯度下降的方式对共享的权重进行优化;
37.3)如图2所示,在不同的硬件平台,包括cpu、gpu设备上运行步骤2)采样得到的子网络,收集其执行一次前向计算所需的运行时间;
38.4)如图2所示,利用步骤3)收集的子网络结构和在不同硬件平台上对应的运行时间,训练一个额外的预测器,用于预测不同网络结构在不同硬件平台上对应的运行时间;
39.5)如图2所示,在全连接的超网上执行进化算法,根据不同硬件平台上的运行时间限制以及不同网络结构在校验集数据上对应的损失搜索出最优网络结构;
40.6)初始化步骤5)得到的最优网络结构的参数,在训练集数据上重新进行训练直到该神经网络收敛。
41.步骤1)中,使用字符串的形式对离散化的网络结构的组合进行表示,该字符串包含神经网络的层数、每层的神经元数量以及不同层的连接方式。
42.步骤2)中,通过权重共享的方式训练一个全连接的超网,其中不同的子网络共享所有的权重,在每个训练步骤通过均匀采样的方式选择一个子网络进行训练,根据梯度下降的方式对共享的权重进行优化,具体为:
43.201)选择固定的超网的层数和每层的神经元数量,其数值等于步骤1)中最大的数量,对超网的参数进行随机初始化;
44.202)训练时,每次在全部的子网络中选择一个进行训练,即只利用超网中的部分层、每层中部分的神经元和部分的连接进行训练,而通过反向传播的方式对全部的参数进
行更新。
45.步骤3)中,在不同的硬件平台,包括cpu、gpu设备上运行步骤2)采样得到的子网络,收集其执行一次前向计算所需的运行时间,具体为:
46.301)在cpu、gpu设备上运行步骤2)采样得到的子网络,直接评估其执行一次前向计算所需的运行时间;前向计算与训练网络的不同之处仅在于只计算得到结果,而不计算参数的梯度,因此其速度得到了大幅提升。
47.步骤4)中,利用步骤3)得到的不同子网络在不同硬件平台上的运行时间训练一个预测器,用于预测没有直接评估的子网络所需的运行时间,具体为:
48.401)使用循环神经网络作为预测器,其输入为网络结构的编码,输出为预测的该结构在不同硬件上的运行时间,在搜索前对其进行随机初始化,在搜索时使用步骤3)收集的数据进行训练,该预测器的作用是用来快速评估新的子网络结构,而不需要在硬件平台上进行计算。
49.步骤5)中,在全连接的超网上执行进化算法,根据不同硬件平台上的运行时间限制以及不同网络结构在校验集数据上对应的损失搜索出最优网络结构,具体为:
50.501)根据搜索过程中收集的运行时间数据,选择100~200个在不同硬件上运行时间最短的网络结构作为初始化种群;
51.502)通过进化算法,随机交叉、替换或删除种群中的网络结构,使用预测器来预测剩下的网络结构,仅保留时间小于规定阈值(本实施例为100)的网络结构;
52.503)检查种群中时间小于规定阈值的网络结构,如果其运行时间达到预设的目标,则停止搜索,否则回到502)步骤。
53.步骤6)中,初始化步骤5)得到的最优网络结构的参数,在训练集数据上重新进行训练直到该神经网络收敛,具体为:
54.601)选择步骤5)得到的最优网络结构,对其进行随机初始化,在训练数据集上进行训练直至收敛,保存其参数。
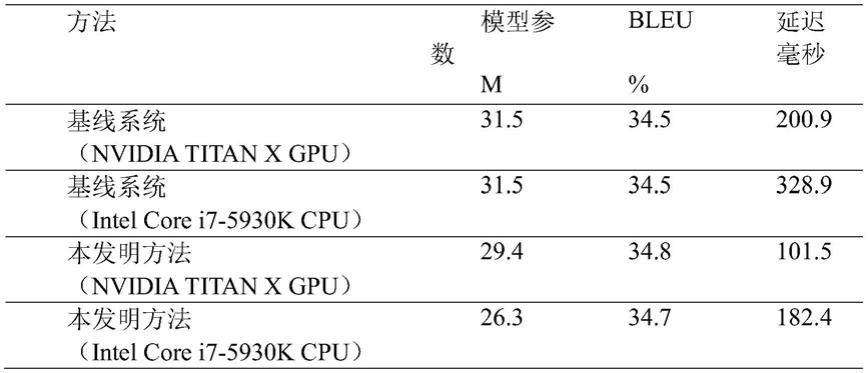
55.为验证方法的有效性,将本发明提出的针对不同设备搜索神经网络结构的方法在机器翻译任务上进行实验。具体来说在iwslt 2014德到英翻译任务上进行实验,该任务训练数据约为16万条双语句对,实验基线使用标准的transformer模型,包括6个编码器层和6个解码器层,模型隐藏层单元为512,分别在nvidia titan x gpu和intel core i7
‑
5930k cpu上进行测试。其中模型参数单位为百万,缩写为m,越小越好;bleu代表在测试集上机器翻译系统的品质,越高越好;延迟通过翻译长度为20的德语句子统计出,越小越好,实验结果如下表所示。
[0056][0057]
实验表明,本发明提出的针对不同设备搜索神经网络结构的方法能够在gpu和cpu设备上有效减少模型参数,显著降低系统延迟,同时不损失翻译品质。该方法在cpu设备上能够降低16.5%的参数量、减少44.5%的延迟;在gpu设备上能够减少49.5%的延迟。
[0058]
总之,本发明提出了一种针对不同设备搜索神经网络结构的方法,能够在无需针对不同设备和运行环境对系统和模型结构进行修改的前提下,有效地减少模型的参数,降低翻译系统的延迟,节约计算资源。同时,本发明能够在不影响神经机器翻译系统翻译效果的前提下,明显地提升系统的运行速度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1