人证校验方法与流程
1.本发明涉及图像处理技术领域,具体地说,涉及一种人证校验方法。
背景技术:
2.人证比对技术可广泛应用于对人员身份一致性要求较高的场所,可在银行、公安、政府、电力、酒店、医疗、火车站、机场安检、证券交易、住建监管、教育及众多企事业单位等领域中应用。
3.然而,现有的人证验证过程需要人工借助图像处理工具处理目标对象人脸的原始图像生成标准的人脸信息进行存储,人证验证系统之后才可以判别人脸的真实身份,现有的人证验证过程无法实现计算机自动处理,依赖于大量的人工标注数据,这通常是高成本的。
4.针对处理目标对象人脸的原始图像方面的改进,专利cn109685018a提供了一种人证校验方法、系统及相关设备,先对待检测的视频流中提取到的原始图像进行校正,生成校正图像,并根据预设的筛选条件筛选出符合预设条件的目标图像,然后根据目标图像判断待检测的视频流中的人脸是否为活体人脸。该专利对视频流中提取到的原始图像进行了校正和筛选,剔除了不符合要求的图像,提高了校验的效率,同时,增加了活体人脸识别过程,提高了校验的安全性。但是专利cn109685018a仅是针对原始图像进行校正提取目标人脸图像才能判别摄像头前的人脸图像是来自合法用户还是非法用户,并不能实现计算机自动处理发型、服饰等因素的干扰,而且这种识别过程中存在对原始图像进行校正生成校正图像时的失真情况,且无法多视角角度自行判断人脸图像。
5.专利cn108564049a公开了一种基于深度学习的快速人脸检测识别方法,该方法包括离线网络搭建部分和在线流程设计部分。对于离线网络搭建部分,本发明设计的网络结构针对不同的尺度人脸分别训练检测器,区别于现有方法中在进行人脸检测时采用单一尺度的模板网络,并采用构建图像金字塔以多任务的方式训练和运行尺度特定的检测器。对于在线流程设计部分,设计使用fifo的list的数据结构思想建立实时人脸特征缓冲池结构,将过程中最耗时的实时特征提取部分移到整个过程的最前端,以身份证读卡器对于身份证的检测作为触发点,并提出建立结果匹配映射表的方法,在三个方面进行创新,有效节省整个过程的时间,实现快速的人脸检测识别,得出人证是否合一的准确判断。其中专利cn108564049a设计的网络结构分为三个基本核心模块,即快速人脸检测模块、面部关键点定位模块和人脸特征提取模块,并不能实现计算机自动处理发型、服饰等因素的干扰,而且这种快速人脸识别过程中仅是克服了不同的尺度人脸识别的问题,并无法多视角角度自行判断人脸图像。
6.因此,需要提出一种用于人证校验的人证校验方法,以减少大量校正图像工作,达到减少成本的目的。
技术实现要素:
7.本发明的目的在于,提供一种人证校验方法,以解决现有人工智能方法中无法对人证校验不能实现计算机自动处理,且存在发型、服饰等因素的干扰,并无法多视角角度自行判断人脸图像,通常依赖于大量的人工标注数据,所花费的成本较高的技术问题。
8.为实现上述目的,本发明提供一种人证校验方法,以下步骤:
9.获取待检测目标对象人脸图像步骤,从待检测的视频流中提取待检测目标对象人脸的原始图像;
10.生成目标图像集合及目标特征向量集合步骤,基于双重一致性自集成学习的半监督分类模块对所述目标对象人脸的原始图像处理生成目标图像集合及目标特征向量集合;所述目标特征向量集合包括人脸特征向量、发型特征向量和服饰特征向量;以及
11.人脸验证步骤,采用双重一致性自集成学习的半监督分类模块提取待鉴定人脸图像的特征向量集合;所述待鉴定人脸图像的特征向量集合包括人脸特征向量、发型特征向量和服饰特征向量;若所述待鉴定人脸图像的特征向量集合与所述目标特征向量集合之间的向量相似度大于一阈值,则判定人证校验成功;
12.其中,在所述双重一致性自集成学习的半监督分类模块生成目标特征向量集合或提取待鉴定人脸图像的特征向量时,包括步骤:
13.构建双重一致性平均教师框架模块步骤,构建一双重一致性平均教师框架模块,所述双重一致性平均教师框架模块包含具有相同网络结构的学生模型和教师模型;所述学生模型和所述教师模型用于输入一人脸图像并输出对应的分类结果和相应的向量相似度对比结果;通过监督损失和非监督损失对学生网络进行优化,并通过指数移动平均更新教师模型;
14.设置注意力损失函数模块步骤,设置一注意力损失函数模块,与所述双重一致性平均教师框架模块连接,用于识别并定位人脸所在区域、发型所在区域和服饰所在区域;
15.设置注意力一致性损失函数模块步骤,设置一注意力一致性损失函数模块,与所述学生模型和所述教师模型连接,所述注意力一致性损失函数模块包括注意力一致性损失函数,用于控制所述学生模型和所述教师模型同时输出对应所述人脸图像的人脸特征向量、发型特征向量和服饰特征向量。
16.进一步地,在所述生成目标图像集合及目标特征向量集合步骤中,以及在所述人脸验证步骤提取待鉴定人脸图像的特征向量集合具体包括:人脸检测步骤,根据所述目标图像集合判断所述待检测的视频流中的图像是否存在人脸;以及特征提取步骤,若存在人脸,则提取该人脸所在中心第一半径区域范围的人脸特征向量、发型特征向量和服饰特征向量。
17.进一步地,在所述人脸验证步骤中,当所述待鉴定人脸图像的特征向量集合的人脸特征向量与所述目标特征向量集合的人脸特征向量之间的向量相似度大于第一阈值时,则判定人证校验成功。
18.进一步地,所述目标特征向量集合的向量为a,其包括的人脸特征向量为a1,其包括的发型特征向量为a2,其包括的服饰特征向量为a3;a=λ1*a1+λ2*a2+λ3*a3,其中λ1、λ2、λ3分别为a1、a2、a3的权重因子,λ1+λ2+λ3=1;所述待鉴定人脸图像的特征向量集合的向量为b,其包括的人脸特征向量为b1,其包括的发型特征向量为b2,其包括的服饰特征向量为
b3;b=ε1*b1+ε2*b2+ε3*b3,其中ε1、ε2、ε3分别为b1、b2、b3的权重因子,ε1+ε2+ε3=1;当|a
‑
b|大于一阈值c时,则判定人证校验成功。
19.进一步地,利用欧式距离、余弦相似和sobe l算法进行计算获得人脸特征向量、发型特征向量和服饰特征向量。
20.进一步地,在所述人脸验证步骤之前还包括:活体检测步骤,检测所述待检测的视频流中的图像是否为活体人脸,若是活体人脸,则进行下一步。
21.进一步地,所述监督损失的方式包括采用交叉熵损失函数和均方误差损失函数的方式进行计算。
22.进一步地,所述非监督损失的方式包括采用分类一致性损失函数和注意力一致性损失函数的方式进行计算。
23.进一步地,所述注意力损失函数模块中包括注意力损失函数,所述注意力损失函数中具有正则化项;所述注意力损失函数为其中,f
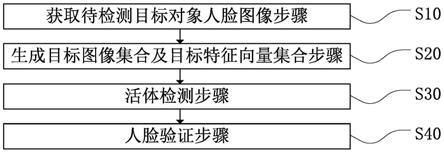
θ
(x
i
)
k
表示由学生模型的输入人脸图像x
i
生成的目标图像集合在第i处时k个像素,s(x
i
)
k
表示相应的区域分割结果,λ
a
和λ
r
是注意力损失和正则化项的权重因子,注意力损失和正则化项之和为1。
24.进一步地,所述注意力一致性损失函数模块包括注意力一致性损失函数,所述注意力一致性损失函数为所述学生模型和所述教师模型的分类结果输出的均方误差,或者为所述目标图像集合输出的均方误差。
25.进一步地,所述注意力一致性损失函数为所述学生模型和所述教师模型的分类结果输出的均方误差时,所述注意力一致性损失函数为其中,p
θ
(x
i
)和p
θ
′
(x
i
)是所述教师模型和所述学生模型相对于输入的分类结果的概率;θ和θ’分别表示所述教师模型和所述学生模型的参数;n表示分类类别的数量。
26.进一步地,所述注意力一致性损失函数为所述目标图像集合输出的均方误差时,所述注意力一致性损失函数为其中,f
θ
(x
i
)
k
表示由学生模型的输入人脸图像x
i
生成的目标图像集合在第i处时k个像素,θ和θ’分别表示所述教师模型和所述学生模型的参数。
27.本发明的有益效果在于,提供一种人证校验方法,设计了一个自集成学习框架,该框架由具有相同结构的学生网络和教师网络组成;并且设计了一种新的基于注意力机制的损失函数,以获得准确的注意力区域结果;通过在人脸图像分类和在人脸所在区域对注意力定位进行双重一致性约束,这两个网络可以逐渐优化注意力分布并提高彼此的性能,而训练仅依赖于部分标记的数据并遵循半监督训练的方式,并不需要大量带有分类标注的数据,所花费的成本低。尤其是还兼顾了发型所在区域和服饰所在区域的特征向量,使得识别准确性提升。而且可基于人证校验方法的自主学习功能,实现基于现有的目标图像集合通过多视角角度自行判断人脸图像,而不仅仅局限于所述目标图像集合的信息进行判断。
附图说明
28.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
29.图1为本发明实施例中所述人证校验方法的流程图。
30.图2为本发明实施例中在所述双重一致性自集成学习的半监督分类模块生成目标特征向量集合或提取待鉴定人脸图像的特征向量时的流程图。
31.图3为本发明实施例中所述双重一致性自集成学习的半监督分类模块的结构示意图。
具体实施方式
32.以下参考说明书附图完整介绍本发明的优选实施例,使其技术内容更加清楚和便于理解。本发明可以通过许多不同形式的实施例来得以体现,其保护范围并非仅限于文中提到的实施例。
33.如图1所示,本发明实施例中提供一种人证校验方法,以下步骤s10
‑
s40:
34.s10、获取待检测目标对象人脸图像步骤,从待检测的视频流中提取待检测目标对象人脸的原始图像;
35.s20、生成目标图像集合及目标特征向量集合步骤,基于双重一致性自集成学习的半监督分类模块对所述目标对象人脸的原始图像处理生成目标图像集合及目标特征向量集合;所述目标特征向量集合包括人脸特征向量、发型特征向量和服饰特征向量;以及
36.s30、活体检测步骤,检测所述待检测的视频流中的图像是否为活体人脸,若是活体人脸,则进行下一步;
37.s40、人脸验证步骤,采用双重一致性自集成学习的半监督分类模块提取待鉴定人脸图像的特征向量集合;所述待鉴定人脸图像的特征向量集合包括人脸特征向量、发型特征向量和服饰特征向量;若所述待鉴定人脸图像的特征向量集合与所述目标特征向量集合之间的向量相似度大于一阈值,则判定人证校验成功。
38.如图2所示,其中,在所述双重一致性自集成学习的半监督分类模块生成目标特征向量集合或提取待鉴定人脸图像的特征向量时,包括步骤s1
‑
s3:
39.s1、构建双重一致性平均教师框架模块步骤,构建一双重一致性平均教师框架模块,所述双重一致性平均教师框架模块包含具有相同网络结构的学生模型和教师模型;所述学生模型和所述教师模型用于输入一人脸图像并输出对应的分类结果和相应的向量相似度对比结果;通过监督损失和非监督损失对学生网络进行优化,并通过指数移动平均更新教师模型;
40.s2、设置注意力损失函数模块步骤,设置一注意力损失函数模块,与所述双重一致性平均教师框架模块连接,用于识别并定位人脸所在区域、发型所在区域和服饰所在区域;
41.s3、设置注意力一致性损失函数模块步骤,设置一注意力一致性损失函数模块,与所述学生模型和所述教师模型连接,所述注意力一致性损失函数模块包括注意力一致性损失函数,用于控制所述学生模型和所述教师模型同时输出对应所述人脸图像的人脸特征向
量、发型特征向量和服饰特征向量。
42.本实施例中,在所述生成目标图像集合及目标特征向量集合步骤中,以及在所述人脸验证步骤提取待鉴定人脸图像的特征向量集合具体包括:人脸检测步骤,根据所述目标图像集合判断所述待检测的视频流中的图像是否存在人脸;以及特征提取步骤,若存在人脸,则提取该人脸所在中心第一半径区域范围的人脸特征向量、发型特征向量和服饰特征向量。
43.本实施例中,在所述人脸验证步骤中,当所述待鉴定人脸图像的特征向量集合的人脸特征向量与所述目标特征向量集合的人脸特征向量之间的向量相似度大于第一阈值时,则判定人证校验成功。
44.本实施例中,所述目标特征向量集合的向量为a,其包括的人脸特征向量为a1,其包括的发型特征向量为a2,其包括的服饰特征向量为a3;a=λ1*a1+λ2*a2+λ3*a3,其中λ1、λ2、λ3分别为a1、a2、a3的权重因子,λ1+λ2+λ3=1;所述待鉴定人脸图像的特征向量集合的向量为b,其包括的人脸特征向量为b1,其包括的发型特征向量为b2,其包括的服饰特征向量为b3;b=ε1*b1+ε2*b2+ε3*b3,其中ε1、ε2、ε3分别为b1、b2、b3的权重因子,ε1+ε2+ε3=1;当|a
‑
b|大于一阈值c时,则判定人证校验成功。通过所述目标特征向量集合的向量a与所述待鉴定人脸图像的特征向量集合的向量b的对比,可综合考虑人脸所在区域、发型所在区域和服饰所在区域的特性信息,并将注意力用于人脸所在区域的监控。由于人脸图像通常位于人脸中心区域,因此我们的人脸区域分割结果可以帮助完善注意面罩遮挡以及发型或服饰的改变信息。
45.本实施例中,利用欧式距离、余弦相似和sobel算法进行计算获得人脸特征向量、发型特征向量和服饰特征向量。
46.如图3所示,所述双重一致性自集成学习的半监督分类模块100,包括双重一致性平均教师框架(dual consistency mean teacher)模块10、注意力损失函数模块20以及注意力一致性损失函数模块30。
47.所述双重一致性平均教师框架模块10,包含具有相同网络结构的学生模型和教师模型;所述学生模型和所述教师模型用于输入一人脸图像并输出对应的分类结果和相应的向量相似度对比结果;所述学生模型和所述教师模型输出的分类结果为对应所述人脸图像是否为目标对象人脸的分类结果;通过监督损失和非监督损失对学生网络进行优化,并通过指数移动平均更新教师模型。
48.所述注意力损失函数模块20与所述双重一致性平均教师框架模块10连接,用于识别并定位人脸图像通常所在区域,以约束所述目标图像集合的生成。注意挖掘基于引导注意力推理网络上。它表明,如果添加目标的分割结果作为监督,则生成的目标图像集合将更加准确。在这里,我们使用基于u
‑
net的模型首先分割人脸所在区域、发型所在区域和服饰所在区域,并将其用于注意力监控。由于人脸图像通常位于人脸中心区域,因此表明我们的人脸区域分割结果可以帮助完善注意面罩遮挡以及发型或服饰的改变信息。通过这种方式,我们增加了注意力损失,以约束目标图像集合的生成。
49.所述注意力一致性损失函数模块30与所述学生模型和所述教师模型连接,用于控制所述学生模型和所述教师模型同时输出所述分类结果和相应的向量相似度。当将一批图像作为输入时,这两个模型将分别给出概率和目标图像集合。通过监督损失函数和双重一
致性损失函数对学生模型进行优化,使整个框架具有更好的性能。尤为重要的是,本技术的所述学生模型和所述教师模型构成的所述双重一致性平均教师框架模块10是与注意力损失函数模块20以及注意力一致性损失函数模块30密不可分的,只有其相互结合才能实现人证校验方法的功能,而且还能达到自主学习功能,实现基于现有的目标图像集合通过多视角角度自行判断人脸图像,而不仅仅局限于所述目标图像集合的信息进行判断。
50.本实施例中,所述监督损失的方式包括采用交叉熵损失函数和均方误差损失函数的方式进行计算。
51.本实施例中,所述非监督损失的方式包括采用分类一致性损失函数和注意力一致性损失函数的方式进行计算。
52.本实施例中,所述注意力损失函数模块20中包括注意力损失函数,所述注意力损失函数中具有正则化项,使得在软骨分割区域内的目标图像集合输出结果也可以被接受;因此,整个所述注意力损失函数为其中,f
θ
(x
i
)
k
表示由学生模型的输入人脸图像x
i
生成的目标图像集合在第i处时k个像素,s(x
i
)
k
表示相应的区域分割结果,λ
a
和λ
r
是注意力损失和正则化项的权重因子,注意力损失和正则化项之和为1。借助我们设计的注意力损失函数,网络可以生成更准确的目标图像集合,从而有助于进一步提高分类性能。
53.本实施例中,所述注意力一致性损失函数模块30包括注意力一致性损失函数,所述注意力一致性损失函数为所述学生模型和所述教师模型的分类结果输出的均方误差,或者为所述目标图像集合输出的均方误差。
54.本实施例中,所述注意力一致性损失函数为所述学生模型和所述教师模型的分类结果输出的均方误差时,所述注意力一致性损失函数为其中,p
θ
(x
i
)和p
θ
′
(x
i
)是所述教师模型和所述学生模型相对于输入的分类结果的概率;θ和θ’分别表示所述教师模型和所述学生模型的参数;n表示分类类别的数量。
55.本实施例中,所述注意力一致性损失函数为所述目标图像集合输出的均方误差时,所述注意力一致性损失函数为其中,f
θ
(x
i
)
k
表示由学生模型的输入人脸图像x
i
生成的目标图像集合在第i处时k个像素,θ和θ’分别表示所述教师模型和所述学生模型的参数。
56.本发明的有益效果在于,提供一种人证校验方法,设计了一个自集成学习框架,该框架由具有相同结构的学生网络和教师网络组成;并且设计了一种新的基于注意力机制的损失函数,以获得准确的注意力区域结果;通过在人脸图像分类和在人脸所在区域对注意力定位进行双重一致性约束,这两个网络可以逐渐优化注意力分布并提高彼此的性能,而训练仅依赖于部分标记的数据并遵循半监督训练的方式,并不需要大量带有分类标注的数据,所花费的成本低。尤其是还兼顾了发型所在区域和服饰所在区域的特征向量,使得识别准确性提升。而且可基于人证校验方法的自主学习功能,实现基于现有的目标图像集合通过多视角角度自行判断人脸图像,而不仅仅局限于所述目标图像集合的信息进行判断。
57.以上所述仅是本发明的优选实施方式,使本领域的技术人员更清楚地理解如何实践本发明,这些实施方案并不是限制本发明的范围。对于本技术领域的普通技术人员,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1