一种基于密度聚类方法的出租车异常订单识别方法与流程
1.本发明涉及交通大数据应用领域,特别是一种基于密度聚类方法的异常订单识别方法。
背景技术:
2.在现实生活中,可能会出现出租车司机为提高收入而进行绕路的现象。此种行为通常通过乘客主动举报发现,但由于可能存在乘客不熟悉路线等情况发生,因此部分异常行为无法被及时处理。随着信息化程度的不断提升,车载gps设备的普及率也越来越高,因此可以通过车辆订单信息,提取相关特征,进而对可能异常订单进行识别,并供相关部门进行进一步的分析处理。
3.现有技术的聚类算法与识别异常算法是分开的,需对订单数据二次判断,其检测效率和精度都不高。
技术实现要素:
4.本发明所要解决的技术问题在于,提供基于密度聚类方法的异常订单识别方法,从而对出租车运营过程中的可能异常订单进行识别,对异常行为进行辨识,进而为相关部门的进一步处理提供数据支撑。
5.为解决上述技术问题,本发明提供一种基于密度聚类方法的异常订单识别方法,包括以下步骤:
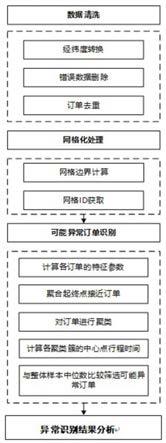
6.步骤1:对原始数据进行预处理,包括数据的坐标系转换以及数据的清洗;
7.步骤2:对预处理后的数据进行网格化处理;
8.步骤3:通过基于密度聚类的方法,对各相似订单簇中的异常样本点进行识别;
9.步骤4:对异常识别结果进行分析,获得可能异常订单的时空分布特征。
10.一种基于密度聚类方法的异常订单识别系统,包括以下模块:
11.数据预处理模块:用于对对原始数据进行预处理,包括数据的坐标系转换以及数据的清洗;
12.网格化模块:用于对预处理后的数据进行网格化处理;
13.异常订单识别模块:用于对各相似订单簇中的异常样本点进行识别;
14.异常订单分析模块:用于对异常识别结果进行分析,获得可能异常订单的时空分布特征。
15.与现有技术相比,其有益效果在于:
16.(1)本发明基于聚类算法,能够实现可能异常订单的自动识别,并通过网格划分对相似订单进行集计,并对结果进行修正,能够显著提升算法的准确性;
17.(2)本发明在对车辆异常订单的识别后进行了结果分析,分析了异常订单的时空分布特征,可为相关部门提供基础的分析结果和执法依据。
18.下面通过具体实施方式和附图对本发明作进一步的说明。
附图说明
19.图1为本发明的方法流程图。
20.图2为本发明实施例中的起终点相似订单样本分布图。
21.图3为本发明实施例中的聚类结果簇分布图。
22.图4为本发明实施例中的可能异常订单识别结果图。
23.图5为本发明实施例中的的不同日可能异常订单分布图。
24.图6为本发明实施例中的的可能异常订单较多的司机信息
25.图7为本发明实施例中的的不同特征日及特征时间的可能异常订单分布。
具体实施方式
26.一种基于密度聚类方法的出租车异常订单识别方法,包括以下步骤:
27.步骤1:原始数据为了存储的方便进行了一定的处理,同时,其中也存在错误数据,因此需要对原始数据进行预处理,包括数据的坐标系转换以及数据的清洗,具体为:
28.步骤1
‑
1:原始数据中,经纬度以字符串形式存储,并且将小数点省去。因此根据研究区域的特征,对经纬度进行还原,转换为数值类型;
29.将原始数据中以字符串形式存储的经纬度转换为数值;
30.步骤1
‑
2:剔除错误数据和重复数据,所述错误数据包括经纬度缺失的数据和经纬度超出目标研究区域的数据,所述重复数据即同一出行订单反复出现的数据。
31.步骤2:原始订单数据包含订单的起终点poi信息,但由于poi粒度小,因此考虑通过网格化处理手段,将订单根据起终点所处的网格进行集计,获得更大粒度的具有统计意义的信息,同时通过合理设置网格大小,保证结果的合理性;
32.因此,对预处理后的数据进行网格化处理,具体为:
33.步骤2
‑
1:由于wgs
‑
84大地坐标系属于球面坐标系,直接对wgs
‑
84坐标系进行线性偏移加载网格会造成非线性的偏移,与实际状况不同;
34.本方法采取utm平面坐标,将wgs
‑
84大地坐标投影到utm平面上,对网格进行线性偏移以完成网格加载;
35.步骤2
‑
2:根据选择区域的边界,确定数据中各订单起终点的网格编号:
[0036][0037][0038]
其中x
i
和y
i
表示订单起点或者终点的坐标,y
up
和x
left
表示选择区域的北边界纬度及南边界经度,gridsize表示网格大小。
[0039]
步骤3:通过基于密度聚类的方法,对各相似订单簇中的异常样本点进行识别,具体包括以下步骤:
[0040]
步骤3
‑
1:提取订单特征,包括:
[0041]
行程时间:根据订单的起始时间,获得该订单的耗费时间;
[0042]
起终点距离:在网格划分后,同一网格下实际的上下车坐标可能并不相同,因此增
加此参数对不同订单进行更精细化的区分;
[0043]
欧几里得速度:根据订单起终点的直线距离,以及订单的行程时间,获得该订单的欧几里得速度,此速度并不表示真实的行程车速,但能对车辆速度进行一定程度的表征;
[0044]
订单是否处于高峰时段,由于高峰时段的路况与平峰时段显著不同,因此对订单花费时间也有较大影响,也属于需要考虑的因素;
[0045]
订单时段为工作日或休息日,对于相同时段,工作日与休息日的路况可能也存在较大区别,故而也需要考虑此因素。
[0046]
步骤3
‑
2:聚合订单,基于网格划分的方法,将目标区域内起终点网格编号相同的订单进行聚合,对于起终点直线距离接近的订单(用起终点直线距离进行表征),其订单时长接近,因此样本分布存在聚集性;
[0047]
步骤3
‑
3:基于密度聚类方法(dbscan)和步骤3
‑
1提取的特征对订单进行聚类,具体为:
[0048]
基于密度聚类方法,根据步骤3
‑
1提取的参数,对订单进行聚类,将不同区域的样本点进行分离;
[0049]
由于异常订单距离正常的样本点较远,根据订单时长再对识别得到的不同聚类簇进行区分;
[0050]
对于各聚类簇,通过其订单时长的中位数与设定的阈值进行判断,如下式:
[0051][0052]
其中,l
i
为聚类簇i的标签值,1表示正常样本,
‑
1表示异常样本,t
m,i
为聚类簇i的订单时长中位数,t
m
为所有样本的订单时长中位数;
[0053]
由于有些正常样本也会距样本空间内密度大的区域较远(如不常见的上下车点),因此经过dbscan算法后,其聚类簇标记为
‑
1;对于聚类簇标记为
‑
1的订单,逐个对其订单时长与设定阈值进行比较。
[0054]
步骤4:对异常识别结果进行分析,获得可能异常订单的时空分布特征,分析指标具体为:
[0055]
订单总体比例:指可能异常订单占总体订单数的比例;
[0056]
不同日期分布:用于对不同日期的异常订单的绝对数量及所占比例进行监控,进而在指标发生异常波动时进行探因;
[0057]
不同司机可能异常订单数量:统计不同司机的可能异常订单数量,进而对数量较高的司机进行进一步的调查;
[0058]
不同特征日及不同特征时段异常订单分布:通过统计不同特征日及不同特征时段异常订单。
[0059]
一种基于密度聚类方法的异常订单识别系统,包括以下模块:
[0060]
数据预处理模块:用于对对原始数据进行预处理,包括数据的坐标系转换以及数据的清洗;
[0061]
网格化模块:用于对预处理后的数据进行网格化处理;
[0062]
异常订单识别模块:用于对各相似订单簇中的异常样本点进行识别;
[0063]
异常订单分析模块:用于对异常识别结果进行分析,获得可能异常订单的时空分
布特征。
[0064]
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
[0065]
步骤1:对原始数据进行预处理,包括数据的坐标系转换以及数据的清洗;
[0066]
步骤2:对预处理后的数据进行网格化处理;
[0067]
步骤3:通过基于密度聚类的方法,对各相似订单簇中的异常样本点进行识别;
[0068]
步骤4:对异常识别结果进行分析,获得可能异常订单的时空分布特征。
[0069]
一种计算机可存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
[0070]
步骤1:对原始数据进行预处理,包括数据的坐标系转换以及数据的清洗;
[0071]
步骤2:对预处理后的数据进行网格化处理;
[0072]
步骤3:通过基于密度聚类的方法,对各相似订单簇中的异常样本点进行识别;
[0073]
步骤4:对异常识别结果进行分析,获得可能异常订单的时空分布特征。
[0074]
下面通过实施例对本发明做进一步的说明。
[0075]
实施例
[0076]
结合图1,一种基于密度聚类方法的出租车异常订单识别方法,包括以下步骤:
[0077]
步骤1:原始数据为了存储的方便进行了一定的处理,同时,其中也存在错误数据,因此需要对原始数据进行预处理,包括数据的坐标系转换以及数据的清洗,具体为:
[0078]
步骤1
‑
1:原始数据中,经纬度以字符串形式存储,并且将小数点省去。因此根据研究区域的特征,对经纬度进行还原,转换为数值类型;
[0079]
将原始数据中以字符串形式存储的经纬度转换为数值;
[0080]
步骤1
‑
2:剔除错误数据和重复数据,所述错误数据包括经纬度缺失的数据和经纬度超出目标研究区域的数据,所述重复数据即同一出行订单反复出现的数据。
[0081]
步骤2:原始订单数据包含订单的起终点poi信息,但由于poi粒度小,因此考虑通过网格化处理手段,将订单根据起终点所处的网格进行集计,获得更大粒度的具有统计意义的信息,同时通过合理设置网格大小,保证结果的合理性;
[0082]
因此,对预处理后的数据进行网格化处理,具体为:
[0083]
步骤2
‑
1:由于wgs
‑
84大地坐标系属于球面坐标系,直接对wgs
‑
84坐标系进行线性偏移加载网格会造成非线性的偏移,与实际状况不同;
[0084]
本方法采取utm平面坐标,将wgs
‑
84大地坐标投影到utm平面上,对网格进行线性偏移以完成网格加载;
[0085]
步骤2
‑
2:根据选择区域的边界,确定数据中各订单起终点的网格编号:
[0086][0087][0088]
其中x
i
和y
i
表示订单起点或者终点的坐标,y
up
和x
left
表示选择区域的北边界纬度及南边界经度,gridsize表示网格大小。
[0089]
步骤3:通过基于密度聚类的方法,对各相似订单簇中的异常样本点进行识别,具体包括以下步骤:
[0090]
步骤3
‑
1:提取订单特征,包括:
[0091]
行程时间:根据订单的起始时间,获得该订单的耗费时间;
[0092]
起终点距离:在网格划分后,同一网格下实际的上下车坐标可能并不相同,因此增加此参数对不同订单进行更精细化的区分;
[0093]
欧几里得速度:根据订单起终点的直线距离,以及订单的行程时间,获得该订单的欧几里得速度,此速度并不表示真实的行程车速,但能对车辆速度进行一定程度的表征;
[0094]
订单是否处于高峰时段,由于高峰时段的路况与平峰时段显著不同,因此对订单花费时间也有较大影响,也属于需要考虑的因素;
[0095]
订单时段为工作日或休息日,对于相同时段,工作日与休息日的路况可能也存在较大区别,故而也需要考虑此因素。
[0096]
步骤3
‑
2:聚合订单,基于网格划分的方法,将目标区域内起终点网格编号相同的订单进行聚合,对于起终点直线距离接近的订单(用起终点直线距离进行表征),其订单时长接近,因此样本分布存在聚集性,如图2所示,为起终点相似的部分订单的样本点分布,具备明显的簇状分布特征。
[0097]
步骤3
‑
3:基于密度聚类方法(dbscan)和步骤3
‑
1提取的特征对订单进行聚类,具体为:
[0098]
基于密度聚类方法,根据步骤3
‑
1提取的参数,对订单进行聚类,将不同区域的样本点进行分离;
[0099]
图3为聚类结果,圆圈内不同大小的点表示不同的聚类簇。
[0100]
由于异常订单距离正常的样本点较远,根据订单时长再对识别得到的不同聚类簇进行区分;
[0101]
对于各聚类簇,通过其订单时长的中位数与设定的阈值进行判断,如下式:
[0102][0103]
其中,l
i
为聚类簇i的标签值,1表示正常样本,
‑
1表示异常样本,t
m,i
为聚类簇i的订单时长中位数,t
m
为所有样本的订单时长中位数;
[0104]
由于有些正常样本也会距样本空间内密度大的区域较远(如不常见的上下车点),因此经过dbscan算法后,其聚类簇标记为
‑
1;对于聚类簇标记为
‑
1的订单,逐个对其订单时长与设定阈值进行比较。
[0105]
如图4所示,圆圈内的点为可能的异常订单识别结果。
[0106]
步骤4:对异常识别结果进行分析,获得可能异常订单的时空分布特征,分析指标具体为:
[0107]
订单总体比例:指可能异常订单占总体订单数的比例;
[0108]
现取2019年12月,前100个热点od进行分析,共190855个订单,其中识别得到9198个可能异常订单,占比约5%,这也表明异常订单的产生为小概率事件。同时,此部分异常订单也可能存在多种产生原因,需要有关部门进一步的调查。
[0109]
不同日期分布:用于对不同日期的异常订单的绝对数量及所占比例进行监控,进
而在指标发生异常波动时进行探因;如图5所示为2019年12月可能异常订单数量及可能异常订单比例,绝对数量波动较大,而可能异常订单占比则比较稳定。其中,2019年11月29日异常波动为数据问题,该日数据较少。
[0110]
不同司机可能异常订单数量:统计不同司机的可能异常订单数量,进而对数量较高的司机进行进一步的调查;图6展示了可能异常订单数量前十位的司机,由于订单时长也会受驾驶员驾驶习惯,道路拥堵状况等的影响,因此可根据此初步结果,对车辆进行进一步调查。
[0111]
不同特征日及不同特征时段异常订单分布:通过统计不同特征日及不同特征时段异常订单。
[0112]
图7展示了不同特征日及特征时段的异常订单占比无显著区别,因此可判定异常订单的发生率与时间特征相关性较小。
[0113]
本发明基于聚类算法,能够实现可能异常订单的自动识别,并通过网格划分对相似订单进行集计,并对结果进行修正,能够显著提升算法的准确性;在对车辆异常订单的识别后进行了结果分析,分析了异常订单的时空分布特征,可为相关部门提供基础的分析结果和执法依据。
[0114]
上述实施例仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和等同替换,这些对本发明权利要求进行改进和等同替换后的技术方案,均落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1