基于深度特征一致哈希算法的图像检索方法
本发明属于深度学习技术领域,具体涉及一种基于深度特征一致哈希算法的用于单标签和多标签图像检索方法。
背景技术:
随着多媒体大数据的快速发展,图像的数量呈爆炸性增长,这就需要快速准确的检索方法。精确的最近邻检索(knn)耗时长,不适合大数据检索,而近似最近邻检索(ann)由于兼顾了时间和效率而更受欢迎。
有监督学习是训练神经网络和决策树的常用技术。神经网络和决策树这两种技术高度依赖于预先确定的分类系统给出的信息,对于神经网络,分类系统利用这些信息判断网络误差,然后不断调整网络参数;对于决策树,分类系统使用它来确定哪些属性提供了最多的信息。基于成对标记的代表性方法是最小损失哈希法(mlh)和带核监督哈希法(ksh),监督哈希学习使用人工标记的标签作为监督信息来学习哈希函数,这种方法通常优于无监督方法。近年来,深度学习已经成为一种流行的学习方法,并且已经开发了各种各样的深度哈希学习方法,如lin等人提出了一种无监督的深度学习方法deepbit,它对二进制码实施了三个标准(即最小化量化损失,均匀分布编码和不相关位)学习压缩二进制描述子,从而实现高效的视觉对象匹配。gong等人提出的itq方法使每个二进制位的方差最大化,并且最小化量化损失,从而获得更高的图像检索性能。liong等人提出利用深度神经网络学习哈希码,并通过优化实现了三个目标:(1)最小化实值特征描述子与学习二进制码之间的损失;(2)二进制代码均匀地分布在每个位上;(3)不同的位尽可能独立。
利用未标记数据来学习数据的分布或数据之间的关系称为无监督学习,无监督学习是人工智能网络的一种算法;其目的是对原始数据进行分类,以了解数据的内部结构。lsh是无监督哈希学习的代表之一,它将相似的项映射到同一个桶中。与有监督学习网络不同,无监督学习网络不知道其分类结果是否正确,也就是说,它没有被监督所增强(告诉它什么样的学习是正确的)。近年来,由于有监督哈希学习算法需要人工标注大量标签,耗费大量的人力物力,提出了许多无监督哈希学习算法,自监督哈希学习作为一种新的无监督哈希学习方法,在深度学习领域得到了广泛的应用。许多基于“借口任务”的方法被提出。但这些方法都依赖于预训练模型,其精度明显低于有监督哈希学习方法。
有监督哈希方法的缺点是获取标签需要耗费大量的人力物力,因此提出了无监督哈希方法。无监督哈希方法将图像从原始空间映射到哈希空间,并设置一系列损失函数来保持图像的相似性。通常采用预训练模型得到图像的特征向量,按距离排序后得到语义相似度矩阵,gidaris等人提出了一种基于图像旋转的自监督方法,然而,这导致了特征表示和图像变换之间的协方差。misra等人解决了这个问题,然而,它们并没有将原始空间中相似图像的相似性映射到特征空间。
而无论是监督哈希学习还是非监督哈希学习,现有的大多数方法都将语义相似度矩阵的值设置为1或0(如果至少有一个标签相同,则该值为1,如果没有标签相同,值为0)。对于多标签图像,这种方法不能很好地反映图像的相似度排序。且最近的研究表明,深度神经网络可以根据区域小部分的像素来判断图像的类别,即在训练过程中很容易受到像素的影响。
技术实现要素:
本发明的目的是提供一种基于深度特征一致哈希算法的图像检索方法,以弥补现有技术的不足。
为达到上述目的,本发明采取的具体技术方案为:
一种基于深度特征一致哈希算法的图像检索方法,包括以下步骤:
s1:获取多标签或者单标签图像数据,包括训练集和测试集;
s2:预处理训练集;
s3:利用s2预处理后的训练集,对神经网络进行优化;
s4:将训练集输入到s3优化后的神经网络中得到哈希码;
s5:计算s4得到的哈希码与所述测试集得到哈希码的汉明距离,并按从小到大的距离排序,输出前k个检索结果,k取值为正整数,完成检索。
进一步的,上述方法还包括评估步骤s6:根据s5所得到的前k个检索结果的标签和测试集的标签,计算map(平均精度均值),完成评估。
进一步的,所述s2中:所述预处理包括进行旋转、翻转和添加噪声操作中的一种或者几种,目的是为了使处理后的图像与原图像有不同的像素信息,进而提高检索准确度。
进一步的,所述s3中的神经网络优化具体包括:
s3-1:根据训练集得到改进的语义相似度矩阵;
s3-2:将预处理后的训练集输入到神经网络中;
s3-3:并根据s3-1得到的语义相似度矩阵设置目标函数对神经网络进行训练和优化。
更进一步的,所述s3-1具体为:给定n个训练集图像i={i1,i2,…,in},n取值为正整数。首先,利用标签计算相似度矩阵;如果ii和ij具有任何相同的标签,那么sij=1,否则sij=0;使用百分比来计算s;公式如下:
其中,li和lj表示图像ii和ij的标签向量;<li,lj>表示图像ii和ij的内积;且根据公式(1),将图像分为两类:强相似性和弱相似性;强相似分为完全相似和完全不相似;具体的分类方法为:若两张图像共享至少一个标签,则称它们为弱相似;若两张图片没有相同的标签,则称为强相似中的完全不相似;若两张图片的标签完全相同,则称为强相似中的完全相似。
更进一步的,所述s3-2中:所述神经网络为卷积神经网络,具体使用vgg19作为网络结构;所述vgg19包含19个隐藏层,为16个卷积层和3个完全连接层,vgg19整个网络使用相同大小的卷积核(3x3)和最大池(2x2),用哈希层替换fc8层。当然也可以推广到其他模型,如alexnet和goolenet。
更进一步的,所述s3-3具体为:传统的语义相似度矩阵的值只有1和0,给定所有图像的哈希码b={b1,b2,…bn}(该哈希码b为所有b的总称)和语义相似度矩阵s=sij,条件概率p(sij|b)表示为:
其中,
使用公式(3)来计算具有强相似性的图像的损失;对于部分相似(弱相似)的图像,使用以下公式计算损失:
bi,bj为图像的哈希码,<bi,bj>的范围为[-q,q],结合式(3)和式(4),用wij来标记这两种情况,即wij=1表示这两幅图片是强相似的,wij=0表示这两幅图片是弱相似的;因此,目标函数可以写为:
其中,γ是一个权重参数;
由于哈希码是离散的,直接优化会导致反向传播过程中梯度的消失,采用连续松弛法来解决这个问题;使用连续单元代替离散单元,这样会造成量化损失。因此,设定目标函数以减少损失,并鼓励网络输入准确的二进位码:
其中||·||1是向量的l1范数,|·|是绝对值运算,u为松弛的近似哈希码;
为了更好地表达图像的高层语义信息,通过设置特征损失来调整网络参数,并将图像进行预处理后输入到网络中。图像预处理后像素信息会发生变化,即网络不会根据一小部分像素来确定图像标签,为使网络尽可能地理解相似图像的高层语义信息,并接近深层理解而不是深层学习,使用余弦距离来衡量配对特征的损失:
其中f为神经网络fc7层的输出特征向量;将式(7)与式(5)结合,得到如下目标函数:
结合数量损失和语义损失,最终目标函数如下:
其中,λ是控制量化损失的参数,b为图像的哈希码,u为图像的近似哈希码,f为神经网络fc7层的输出特征向量。
进一步的,所述s4中:
s4-1:使用标准的反向传播和梯度下降法来优化目标函数;通过将哈希码b替换为u,目标函数重写如下:
s4-2:再经过学习过程,得到了近似的哈希码,其值在(-1,1)范围内;
s4-3:为了评估该方法的有效性,使用以下公式来获得精确的哈希码:
最终通过上述一系列公式,最终实现了端到端地学习哈希码。
进一步的,所述s5为:将测试集输入到s4训练好的神经网络中得到其哈希码,并计算与s4中训练集哈希码的汉明距离,按从小到大的顺序排序,输出前k个检索结果。
本发明的优点和技术效果:
本发明在检索过程中,对图像数据进行预处理,且改进了多标签数据集的训练方法,用“强相似性”和“弱相似性”代替传统的“相似性”和“不相似性”。并且改进了神经网络的损失函数,减少了图像像素对神经网络的干扰,极大地提高了检索准确度。
实验表明,本发明在单标签和多标签图像数据集的检索中都具有较好的检索性能,与改进的软相似性深度哈希算法(idhn)相比,本发明在flickr(多标签)数据集的12位、24位、36位和48位的map(平均精度均值)结果分别提高了2.06%、11.62%、2.22%和3.3%。另外,本发明与无监督方法相比,在cifar-10(单标签)数据集的12位、24位、36位和48位的map(平均精度均值)结果分别提高了31.2%、21.5%、21.3%、19.9%,即本发明在单标签和多标签图像数据集的检索中,与现有常用方法相比,在检索精度和时间上都具有明显优势。
附图说明
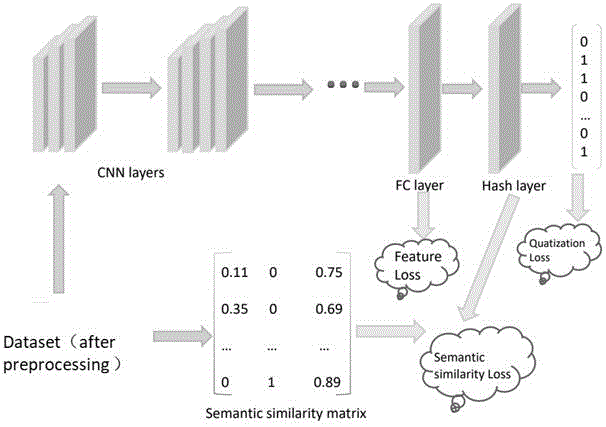
图1为本发明自监督对抗哈希的过程示意图。
图2位本发明训练集预处理时旋转不同角度的对比图。
具体实施方式
以下通过具体实施例并结合附图对本发明进一步解释和说明。
实施例1:
一种基于深度特征一致哈希算法的图像检索方法,包括以下步骤(如图1所示):
s1:首先根据图像数据的标签得到语义相似度矩阵(如图1的semanticsimilaritymatrix(语义相似度矩阵)部分);
给定n个训练集图像i={i1,i2,…,in},n取值为正整数;首先,利用标签计算相似度矩阵。传统的计算方法是,如果ii和ij具有任何相同的标签,那么sij=1,否则sij=0。遵循前人的方法,使用百分比来计算s;公式如下:
其中,li和lj表示图像ii和ij的标签向量;<li,lj>表示图像ii和ij的内积;根据公式(1),将图像分为两类:强相似性和弱相似性。强相似分为完全相似和完全不相似。
s2:将图像进行预处理后输入到神经网络中(如图1的dataset(afterpreprocessing)部分),所述预处理包括进行旋转、翻转和添加噪声操作中的一种或者几种;
所述的神经网络使用vgg19作为网络结构。vgg19包含19个隐藏层(16个卷积层和3个完全连接层)。vgg19结构非常简单,整个网络使用相同大小的卷积核(3x3)和最大池(2x2),使用哈希层替换fc8层。
s3:根据s1得到的相似度矩阵设置目标函数并对神经网络进行优化。
传统的语义相似度矩阵的值只有1和0,给定所有图像的哈希码b和语义相似度矩阵s=sij,条件概率p(sij|b)可以表示为:
其中,
使用公式(3)来计算具有强相似性的图像的损失;对于部分相似(弱相似)的图像,使用以下公式计算损失:
<bi,bj>的范围为[-q,q],结合式(3)和式(4),使用wij来标记这两种情况,即wij=1表示这两幅图片是强相似的,wij=0表示这两幅图片是弱相似的。因此,目标函数可以写为:
其中,γ是一个权重参数。
由于哈希码是离散的,直接优化会导致反向传播过程中梯度的消失,采用连续松弛法来解决这个问题,使用连续单元代替离散单元,这样会造成质量损失。因此,设定目标函数以减少损失,并鼓励网络输入准确的二进位码:
其中||·||1是向量的l1范数。|·|是绝对值运算。
为了更好地表达图像的高层语义信息,通过设置特征损失来调整网络参数,并将图像进行预处理后输入到网络中。图像预处理后像素信息会发生变化,即网络不会根据一小部分像素来确定图像标签,因此目标是使网络尽可能地理解相似图像的高层语义信息,并接近深层理解而不是深层学习;最终使用余弦距离来衡量配对特征的损失:
其中f为神经网络fc7层的输出特征向量;将式(7)与式(5)结合,得到如下目标函数:
结合数量损失和语义损失,最终目标函数如下:
其中,λ是控制量化损失的参数。
使用标准的反向传播和梯度下降法来优化目标函数;通过将哈希码b替换为u,目标函数重写如下:
经过学习过程,得到了近似的哈希码,其值在(-1,1)范围内。为了评估该方法的有效性,使用以下公式来获得准确的哈希码:
通过上述一系列公式,最终可以达到进行端到端地学习哈希代码。
s4:将训练集输入到s3优化后的神经网络中得到训练集哈希码;
s5:将测试集输入到训练好的神经网络中得到其哈希码,并计算与训练集哈希码的汉明距离,按从小到大的顺序排序,输出前k个检索结果,k取值为正整数。
s6:根据所得到的前k个检索结果的标签和测试集的标签,计算map(平均精度均值),完成评估。
实施例2:
为了验证该方法的有效性,在广泛使用的数据集flickr和cifar-10上进行了实验,并与其他先进的方法进行了比较,flickr是一个包含25000幅图像的数据集,每幅图像至少有一个标签。将图像的大小调整为227×227,一个图像可能包含多个标签。cifar-10是更接近通用对象的彩色图像数据集。cifar-10是hinton的学生alexkrizhevsky和ilyasutskever编制的一个小数据集,用于识别宇宙物体。有10种类别:飞机,汽车,鸟,猫,鹿,狗,青蛙,马,船和卡车。每个图像的大小是32×32,每个类别有6000张图片。数据集中有50000个训练图像和10000个测试图像。
对于flickr,随机选择4000张图片作为训练集,1000张图片作为测试集。设置λ=0.1,因为λ会导致更多的离散化,而λ值太小将减少量化损失函数的影响。设置γ=0.1/q来自适应调整均方误差损失梯度。γ值过大或过小都会破坏语义损失和量化损失之间的平衡。对于cifar-10,每类随机抽取1000张图片作为训练集,100张图片作为测试集。
评估指标平均精度均值(map)和平均精度(ap)用于评估本发明的所提供的检索方法(fidh),对于每个查询,平均精度(ap)是前k个结果的平均值,而平均精度均值(map)是所有查询的平均值;平均精度的计算公式如下:
其中n是用于查询的数据库(测试集)中与基本事实相关的实例数。p(k)是前k个实例的精度。当第k个实例与查询相关时(它们至少有一个相同的标签),δ(k)=1,否则δ(k)=0。
本发明提供的方法深度特征一致图像检索方法(fidh)与迭代量化(itq)、局部敏感哈希(lsh)、谱哈希(sh)、压缩二进制码的最小损失哈希(mlh)、核哈希(ksh)、快速图像检索中二进制哈希码的深度学习(dlbhc)、深入学习哈希(hashnet)、基于深度监督哈希的多标签大规模图像检索(dmssph)、基于深度哈希网络的有效相似性检索(dhn)、用于高效图像检索的深度量化网络(dqn)、改进的软相似性深度哈希算法(idhn)在flickr数据集上的性能(表1)和训练时间(表2)如下表所示:
表1图像预处理后,在flickr(多标签)数据集上上的平均精度均值结果
表2dh,bgan和本发明fidh的训练和测试时间对比
表3图像预处理后,在cifar-10(单标签)数据集上上的平均精度均值结果
本发明(fidh)与改进的软相似性深度哈希算法(idhn)相比,在flickr数据集的12位、24位、36位和48位的map(平均精度均值)结果分别提高了2.06%、11.62%、2.22%和3.3%,实验结果如表1所示。其中,在高比特位数上的实验结果是最好的,这表明本发明的高比特位数的哈希码能够更好地表示图像的高级语义信息。
如表2所示,本发明(fidh)在时间性能上具有优势,本发明在训练时间上比dh(深度哈希)和bgan(二进制对抗哈希)分别节省了0.5h和4.5h;测试时间比bgan(二进制对抗哈希)节省了2.5ms。
为了更好地验证我们的方案,我们分别将图像旋转90度、180度和270度,实验结果如图2所示,表明图像的预处理方式并不会对实验结果产生太大的影响。
为了将本发明扩展到单标签数据集,在单标签数据集cifar-10上进行了实验,将几种常用方法与vgg19模型进行了结合,结果如表3所示。与其他深度无监督哈希学习方法相比,本发明(fidh)具有更好的学习效果,与bgan(二进制对抗哈希)相比,在cifar-10数据集的12位、24位、36位和48位的map(平均精度均值)结果分别提高了31.2%、21.5%、21.3%、19.9%。
上述实验结果表明,本发明在多标签数据集和单标签数据集的图像数据检索上均优于现有常用方法,检索精度和时间都有明显优势。
神经网络可以通过一小部分像素信息直接判断图像的类别,这与“人工智能”的字面意义不同。因此,如何使机器了解图像信息是一个值得研究的问题。强迫神经网络学习图像的高级语义信息是一种深刻的理解,利用预处理训练集,破坏原始像素结构,迫使神经网络理解图像的高层语义信息。它是一种从深度学习到深度理解的尝试。如果神经网络能够识别图像预处理前后的标签,就可以理解图像的高层语义信息。
- 还没有人留言评论。精彩留言会获得点赞!